
并行计算架构与技术详解
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
B站1:UID:3546863642871878
B站2:UID: 3546955410049087
摘要
本文系统性地阐述了现代并行计算体系结构的基本原理、分类方法与实现技术。基于Flynn分类法,深入分析了指令级并行(ILP)与线程级并行(TLP)的机制与特性。通过对中央处理器(CPU)与图形处理器(GPU)架构差异的比较,揭示了不同架构的设计哲学与应用场景。最后详细介绍了CUDA编程模型及其在流多处理器(SM)上的执行原理,包括内存层次结构、线程调度机制和性能优化策略。
目录
-
1. 并行计算架构概述
-
2. Flynn并行架构分类法
-
3. 并行计算类型 3.1. 时间并行(流水线技术) 3.2. 空间并行
-
4. 处理单元类型 4.1. 标量处理单元 4.2. 向量处理单元 4.3. 超标量处理单元
-
5. 指令级并行(ILP)技术 5.1. ILP基本概念 5.2. ILP与IPC关系 5.3. ILP计算方法 5.4. 数据冒险与依赖关系 5.5. ILP的技术价值
-
6. 线程级并行(TLP)技术 6.1. TLP的产生背景 6.2. TLP实现方式 6.3. 多线程中的TLP应用 6.4. Flynn分类法的再审视 6.5. ILP与TLP的协同
-
7. 图形处理器(GPU)架构 7.1. GPU与CPU架构对比 7.2. GPU vs CPU: 术语对比 7.3. SIMD与SIMT执行模型 7.4. 线程束执行原理
-
8. CUDA并行编程模型 8.1. CUDA执行模型 8.2. 细粒度多线程机制 8.3. 流多处理器架构
1. 并行计算架构概述
并行架构是指采用多个处理单元协同工作的计算机系统设计方法。这种架构通过同时执行多个计算任务来提高系统整体性能、效率和可扩展性。现代计算系统在多个层次上实现并行性,以应对复杂应用和海量数据处理的需求。
并行计算是指将计算任务分解为多个子任务,并由不同的处理单元同时执行这些子任务的计算模式。这种计算模式能够显著提升计算效率,特别是在处理大规模数据密集型应用时表现出明显优势。
2. Flynn并行架构分类法
Flynn分类法是计算机体系结构的一种分类标准,根据指令流和数据流的数量关系将计算机架构分为四类。
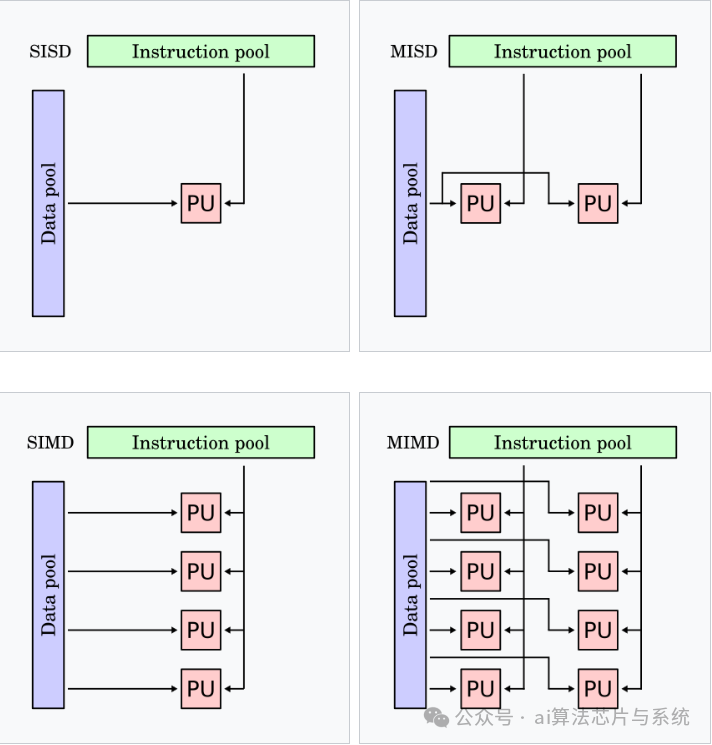
Flynn分类法图示
MISD实际中很少被使用
现代计算系统通常采用混合架构设计,结合SIMD和MIMD的特性,以在不同工作负载下实现性能最优。例如,现代GPU同时集成了数据级并行和线程级并行处理能力。
3. 并行计算类型
并行计算从时间维度和空间维度可分为两种基本类型:
3.1. 时间并行(流水线技术)
时间并行通过重叠执行任务的各个阶段来提高吞吐率。以工业生产流水线为例:
-
• 无流水线:阶段A(5分钟) → 阶段B(15分钟) → 每批次20分钟
-
• 有流水线:阶段A处理新批次时,阶段B处理上一批次 → 吞吐率提高,延迟不变
在处理器设计中,指令流水线将指令执行分为取指、译码、执行、访存、写回等阶段,通过重叠执行提高指令吞吐率。
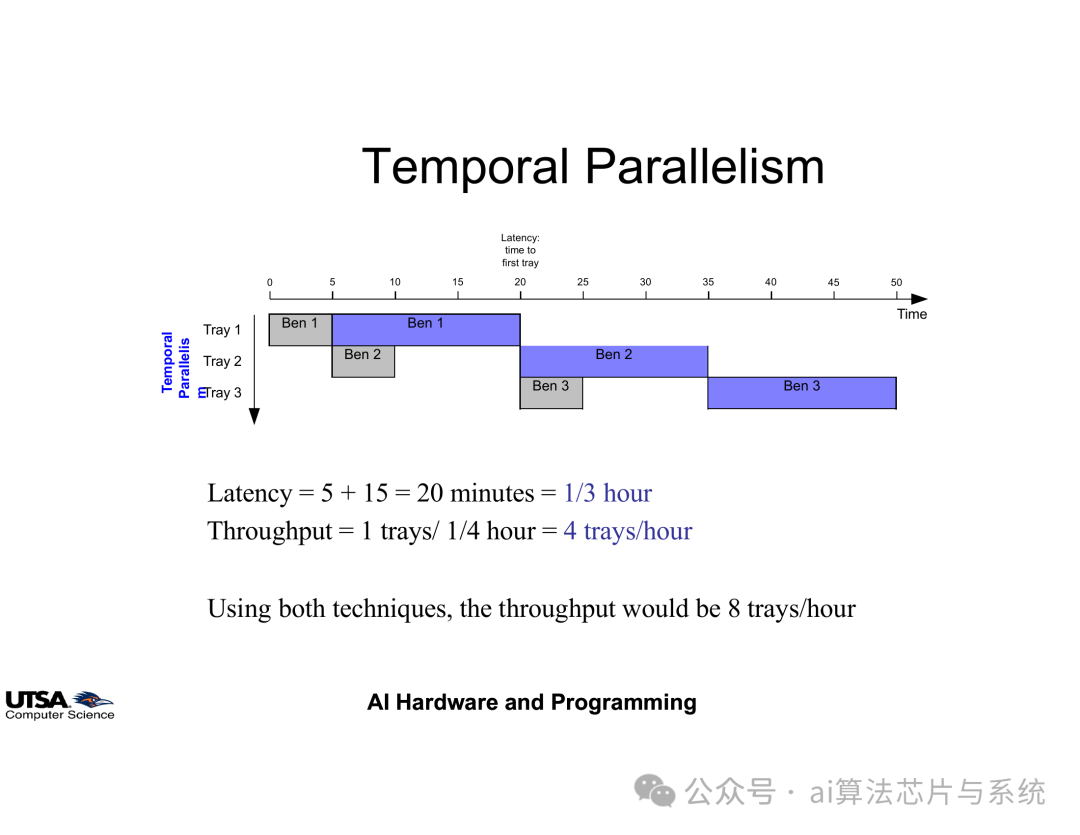
时间并行原理示意图
处理器使用流水线寄存器在各级流水线之间传递中间结果,确保指令执行的正确性:
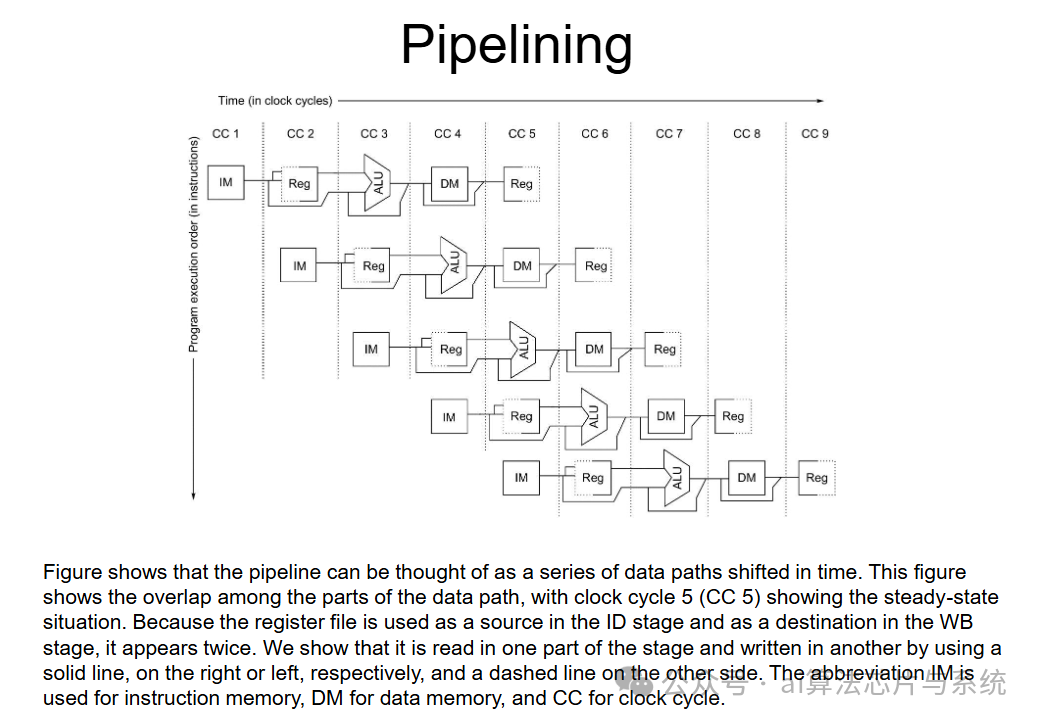
处理器指令流水线结构
3.2. 空间并行
空间并行通过增加处理单元数量来实现真正的并发执行。继续以工业生产力例,增加生产线和设备:
-
• 两条生产线同时运行
-
• 处理延迟保持不变
-
• 系统吞吐率成倍提高
这正是多线程 CPU 与 GPU(SIMT 模型)所采用的并行方式,其中多个操作真正实现同时并发执行。
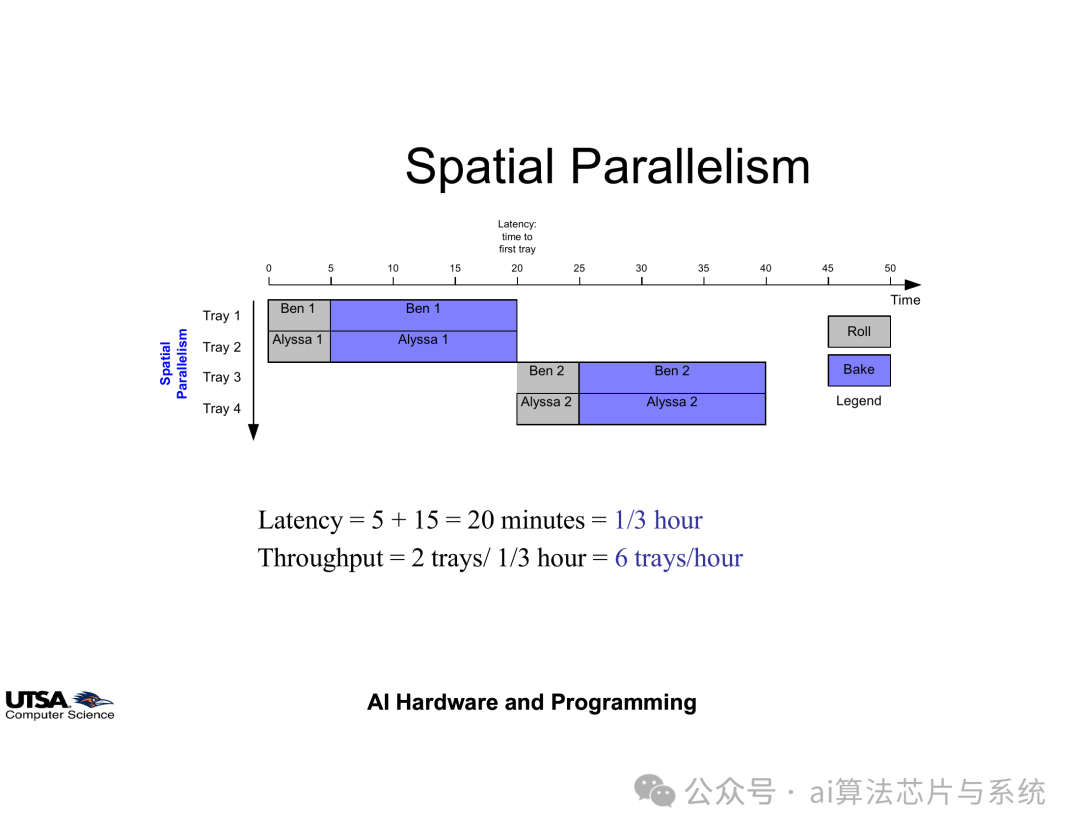
空间并行原理示意图
4. 处理单元类型
4.1. 标量处理单元
标量处理单元每次处理一条指令和一个数据元素。现代标量处理器通常采用流水线设计提高指令吞吐率,但本质上每个周期仍处理一个基本操作。标量处理适用于通用计算任务,具有较好的灵活性。
4.2. 向量处理单元
向量处理单元同样一次只发射一条指令,但它操作的是向量数据,而非单个标量值。借助这种方式,处理器能够同时对多个元素进行计算。例如,指令
X[0:7] + Y[0:7]
可在一次操作中完成两个各含八个元素的向量的逐元素加法。而在标量处理器上,实现相同结果需要八条独立指令。
4.3. 超标量处理单元
超标量处理单元能够同时执行多条互不相关的指令。它通过集成多个可同时工作的执行单元来实现这一点。举例来说,超标量处理器可以并发执行下面两条指令:
ADD X + Y MUL W * Z
这种并行性大幅提升了指令吞吐率和整体效率,使超标量处理单元非常适合高性能计算应用。
5. 指令级并行(ILP)技术
5.1. ILP基本概念
指令级并行是指程序指令间存在的可并行执行的可能性。ILP程度取决于程序特性、指令集架构设计和编译器优化能力。较高的ILP意味着程序中有更多指令可以同时执行。
5.2. ILP与IPC关系
ILP 描述的是程序内部潜在的并行度,而每周期指令数(IPC)衡量的是处理器实际的指令吞吐能力。二者的关键区别如下:
-
• ILP:理论并行度,表示程序可挖掘的最大并行潜力
-
• IPC:实际每周期指令吞吐,受硬件实现与运行时因素影响
-
• ILP 为 IPC 设定上限,但真实 IPC 受指令延迟、缓存行为、执行资源等限制
5.3. ILP计算方法

ILP计算示意图
指令级并行度计算公式:
指令总数关键路径长度
5.4. 数据冒险与依赖关系
实现ILP需要解决指令间的三种依赖关系:
5.4.1. 数据依赖
数据依赖发生在一条指令需要用到前一条指令结果的情况下,共可分为三种类型:
-
• 真数据依赖(读后写,RAW): 后指令需要前指令结果
ADD R1, R2, R3 # R1 = R2 + R3 SUB R4, R1, R5 # R4 = R1 - R5 (依赖 ADD 的结果)
-
• 反依赖(写后读,WAR): 后指令覆盖前指令源操作数
SUB R1, R2, R3 # 读取 R2 ADD R2, R4, R5 # 在 SUB 读取之前写入 R2
-
• 输出依赖(写后写,WAW): 多条指令写入同一目标
MUL R1, R2, R3 # 写入 R1 ADD R1, R4, R5 # 再次写入 R1,产生冲突
5.4.2. 控制依赖
控制依赖发生在一条指令的执行与否取决于前一条分支指令的结果时。
分支指令导致的条件执行依赖:
BEQ R1, R2, LABEL # 若 R1 == R2,则跳转到 LABEL ADD R3, R4, R5 # 仅当分支未发生时才执行
处理器通过分支预测和推测执行来缓解控制依赖,但一旦预测错误,就会导致流水线被冲刷,从而带来性能损失。
5.4.3. 内存依赖
内存依赖出现在多条指令访问存储器并可能引发冲突的情况下:
-
• 读后写(RAW:Load After Store)
STORE R1, 0(R2) # 把 R1 的值写入 R2 指向的地址 LOAD R3, 0(R2) # 从同一地址读取数据
处理器必须保证先完成写入,再执行读取。
-
• 写后读(WAR:Store After Load)
LOAD R1, 0(R2) # 从 R2 指向的地址加载数据到 R1 STORE R3, 0(R2) # 向同一地址写入新值
若两指令被错误地重排,写入可能在使用该值之前将其覆盖。
-
• 写后写(WAW:Store After Store)
STORE R1, 0(R2) # 向 R2 指向的地址写入一个值 STORE R3, 0(R2) # 再次向同一地址写入不同值
第二条写入必须按正确顺序执行,以确保程序结果正确。
5.5. ILP的技术价值
指令级并行(ILP)是现代处理器设计的基石,它能在不提高时钟频率的情况下带来更高性能。高效挖掘 ILP,可以显著提升吞吐率、能效与执行速度。然而,实际执行受到硬件限制以及数据、控制、存储器等多种依赖冒险的约束。
深入理解 ILP,也关联到超标量架构、乱序执行、推测执行和多线程等更广泛的主题。寄存器重命名、分支预测、推测执行等技术能够缓解依赖问题、提高 IPC,从而使处理器更加高效。
在计算技术的发展过程中,ILP 一直是性能提升的关键驱动力。传统单核处理器专注于在单线程内 最大化 ILP,而现代计算则通常将 ILP 与线程级并行(TLP)和数据级并行(DLP)相结合,以实现更大的性能扩展潜力。
6. 线程级并行(TLP)技术
6.1. TLP的产生背景
随着单线程ILP提取趋于极限,处理器设计转向线程级并行。TLP通过同时执行多个线程来提高处理器利用率和系统吞吐率,特别适合多任务环境和多线程应用。
6.2. TLP实现方式
-
• 多道程序设计: 处理器通过在不同独立程序之间切换来执行它们,从而减少 CPU 空闲时间、提高利用率。这适用于需要同时处理多个用户应用程序的操作系统,例如同时运行网页浏览器、音乐播放器和后台系统任务
-
• 多线程应用: 单个程序被划分为多个并发线程,每个线程同时执行一部分任务。这能显著提升对高响应性或重计算需求应用的性能,如视频处理、游戏引擎、同时处理多个客户端请求的 Web 服务器,以及并行数据库事务
6.3. 多线程中的TLP应用
多线程技术使处理器能够并行执行多个线程,有效隐藏内存访问延迟,提高资源利用率。
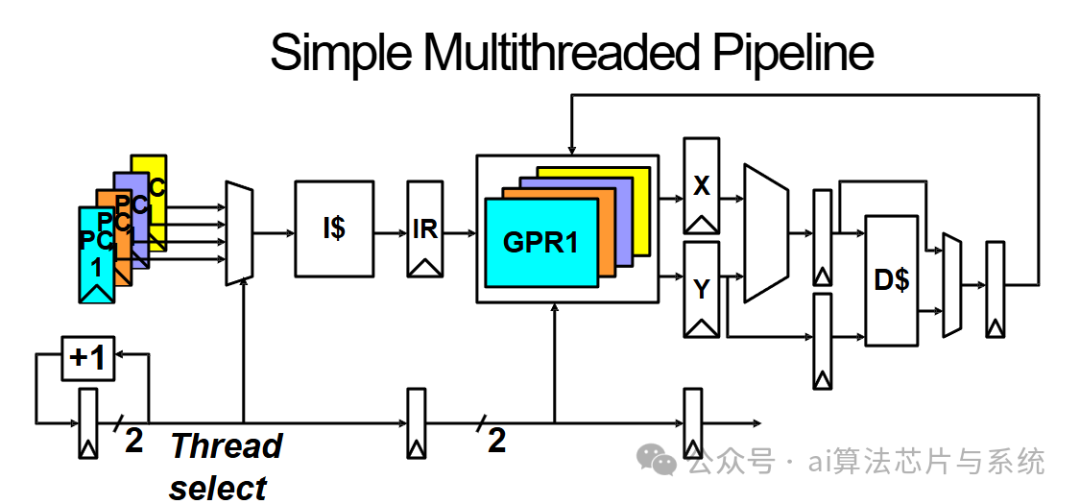
多线程处理器流水线结构
每个线程维护独立的执行状态:
-
• 程序计数器(PC)
-
• 通用寄存器组
-
• 栈和内存空间
6.4. Flynn分类法的再审视
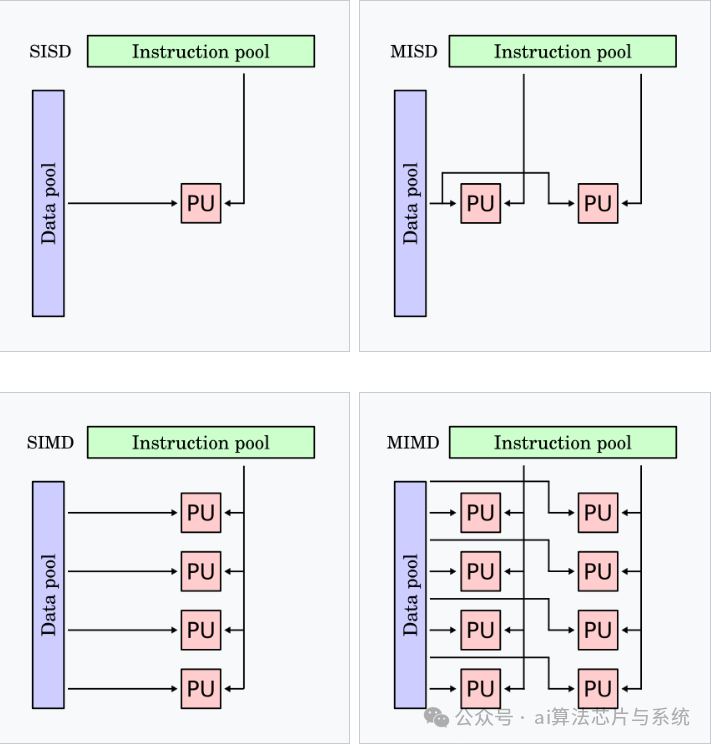
Flynn分类法
现代计算架构通常融合多种Flynn分类模型:
-
• CPU: 主要采用MIMD模型
-
• GPU: 结合SIMD和SIMT模型
-
• 异构计算: CPU与GPU协同工作
6.5. ILP与TLP的协同
ILP和TLP是现代处理器架构中两个互补的并行层次:
-
• ILP: 细粒度指令级并行
-
• TLP: 粗粒度线程级并行
ILP 与 TLP 是提升计算性能的两条互补途径:ILP 专注于在单一线程内部挖掘细粒度的并行性,而 TLP 则利用跨多个线程的粗粒度并行。现代架构同时融合 ILP 和 TLP,以在从单线程应用到大规模并行计算的多样化工作负载中实现最佳性能。 后续讨论将进一步探讨现代硬件——如多核处理器、同时多线程(SMT)以及异构计算——如何进一步强化并行执行。
7. 图形处理器(GPU)架构
7.1. GPU与CPU架构对比
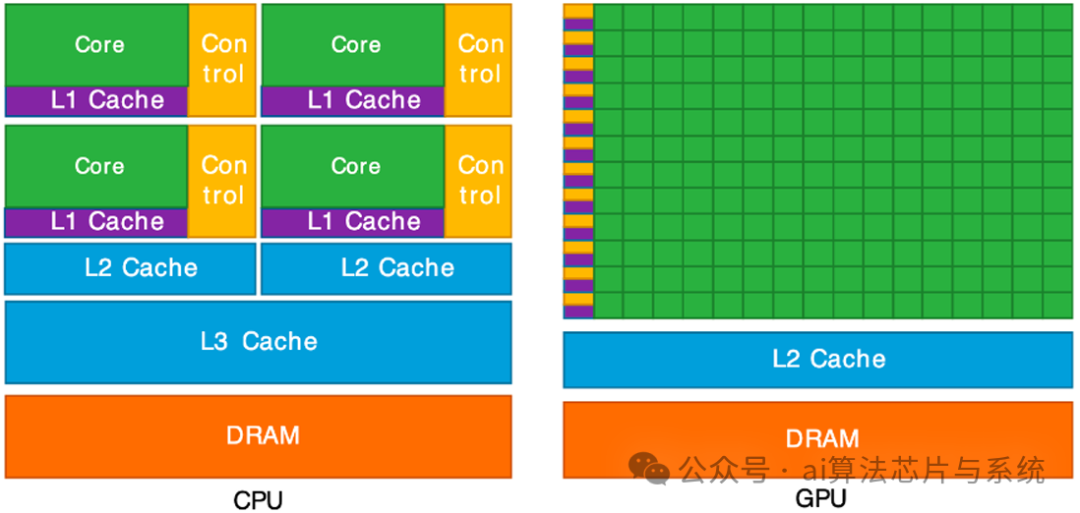
GPU与CPU架构对比
CPU 针对低延迟的顺序处理进行了优化,而 GPU 则面向高吞吐的大规模并行计算设计。这一根本差异源于它们各自的设计目标:
-
• CPU:优先保证少量任务的快速执行,配备深层缓存层级和复杂的分支预测机制。
-
• GPU:专为并行执行成千上万个轻量级线程而优化,拥有大量结构简单的计算核心和极小的缓存。
7.2. GPU vs CPU: 术语对比
7.3. SIMD与SIMT执行模型
GPU 利用单指令多数据(SIMD)与单指令多线程(SIMT)架构来实现并行计算 :
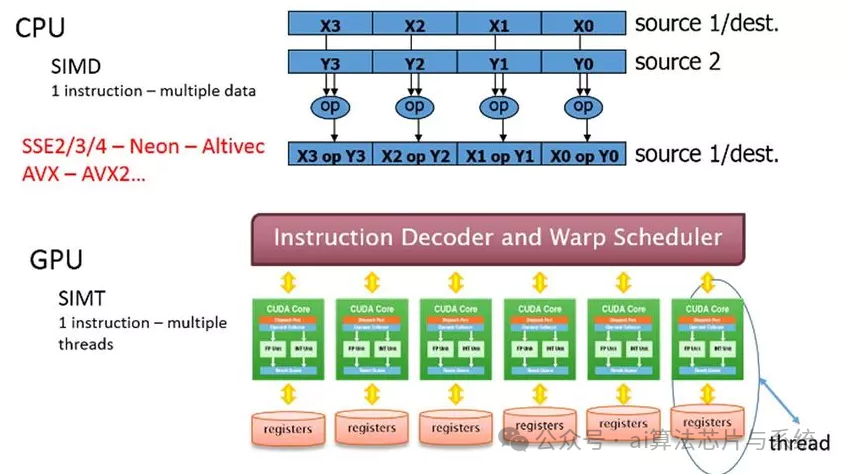
SIMD与SIMT执行模型
-
• SIMD: 一条指令同时作用于多个数据元素,在执行矩阵运算和图像处理等任务时效率极高
-
• SIMT: 在 SIMD 基础上扩展,将线程组织为 warp,warp 内所有线程执行同一条指令,但各线程处理的数据元素不同
7.4. 线程束执行原理
Warp 是一组线程的集合,这些线程在同一时刻执行同一条指令,但各自处理不同的数据元素。Warp 是 GPU 流式多处理器(SM)中最基本的执行单元。在现代 NVIDIA GPU 上,一个 warp 通常由 32 个线程组成,不过具体数量可能随架构而异。
-
• Warp 调度:GPU 会动态地调度 warp,以最大化计算吞吐量。当某个 warp 因等待内存而停顿时,另一个 warp 可以立即投入执行,从而充分利用处理资源。
-
• 分支发散处理:若 warp 内的不同线程因条件分支而走向不同的执行路径,warp 将被迫串行执行这些路径,导致效率下降。 通过设计能够最大限度减少 warp 分支发散的工作负载,开发者可以优化 GPU 性能,充分发挥其并行执行能力。
8. CUDA并行编程模型
CUDA(Compute Unified Device Architecture,统一计算设备架构)是 NVIDIA 推出的并行计算平台与编程模型,旨在让软件开发者充分利用 GPU 的加速能力。CUDA 提供对 GPU 执行的细粒度控制,因而适用于科学计算、深度学习以及实时渲染等高性能应用。
8.1. CUDA执行模型
CUDA采用分层编程模型:
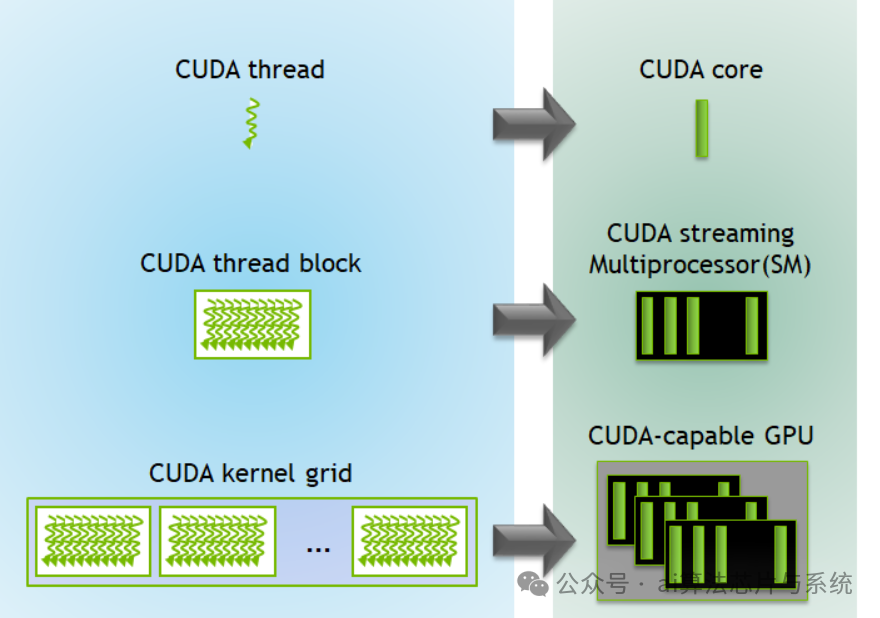
CUDA网格-块-线程层次结构
网格-线程块-线程层级:CUDA 将并行执行组织成三级层次结构:
-
• 一个网格(Grid)由多个线程块(Block)组成。
-
• 一个线程块由多个线程(Thread)组成。
-
• 每个线程独立执行一个 CUDA 核函数(kernel)。
Warp 执行:线程块内的线程进一步以 32 个为一组划分为 warp,这些线程以锁步(lockstep)方式执行。
存储模型:CUDA 提供多种存储器类型:
-
• 全局内存(Global Memory):所有线程均可访问,但延迟较高。
-
• 共享内存(Shared Memory):速度更快,但仅由同一线程块内的线程共享。
-
• 寄存器(Registers ):供单个线程专用,访问速度最快。
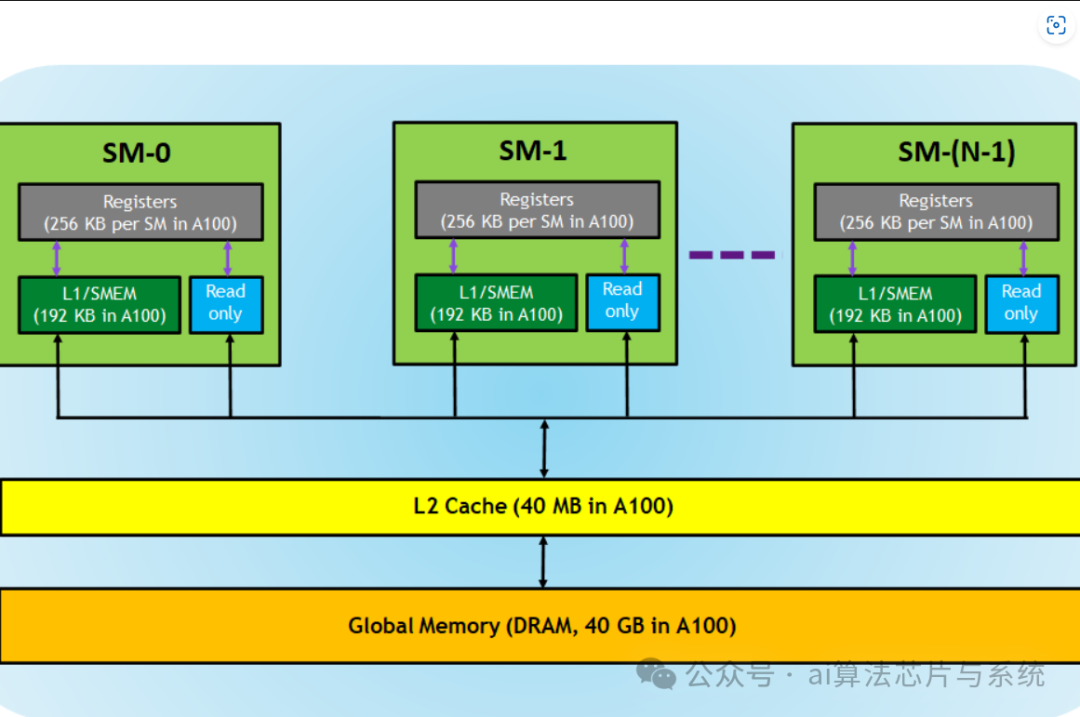
CUDA内存层次结构
8.2. 细粒度多线程机制
细粒度多线程是 CUDA 架构中的关键机制,它让 GPU 即便面对高内存延迟也能保持高利用率。通过在活跃 warp 之间快速切换,确保 GPU 的计算资源始终处于忙碌状态。
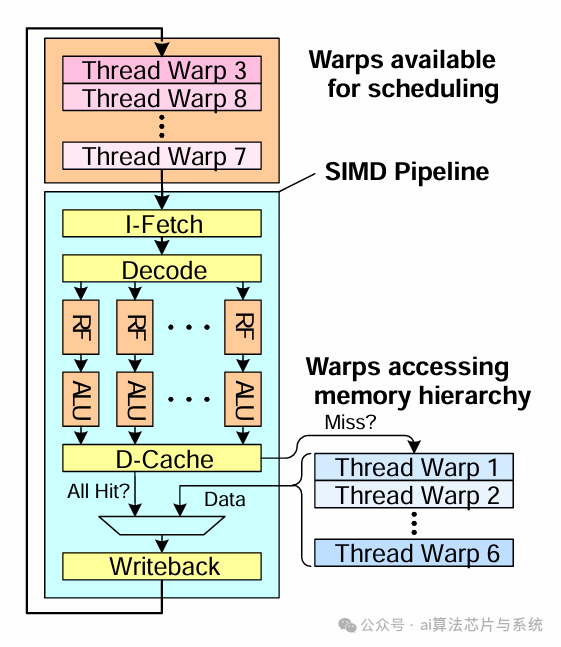
细粒度线程束调度
-
• 线程级并行(TLP):每个流式多处理器(SM)可同时管理多个 warp,当某个 warp 因等待内存访问而停顿时,另一个 warp 可立即执行。
-
• 指令级并行(ILP):在一个 warp 内部,相互独立的指令可被并行发射,以优化执行吞吐率。
-
• 占用率(Occupancy):每个 SM 上活跃 warp 的数量直接影响整体性能。提高占用率有助于更好地隐藏延迟并提升计算效率。 通过设计能够同时提升 TLP 与 ILP 的 CUDA kernel,开发者可以充分利用细粒度多线程,减少空闲周期并显著提升性能。
8.3. 流多处理器架构
流式多处理器(SM)是 NVIDIA GPU 的基本处理单元。每个 SM 包含大量 CUDA 核心、warp 调度器和执行管线,从而能够高效并行地执行 CUDA 线程。
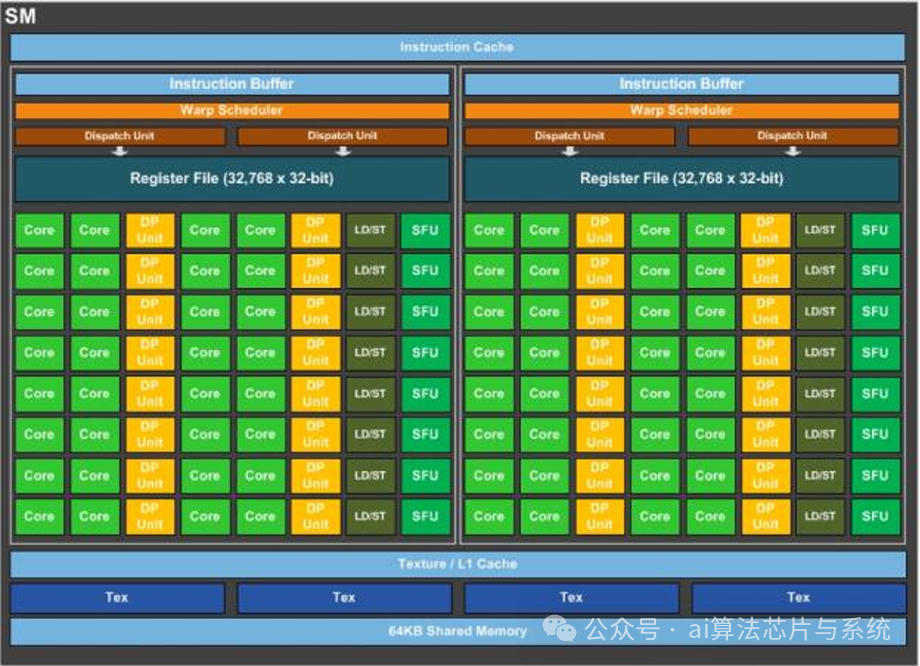
流多处理器内部结构
-
• Warp 调度:每个 SM 同时调度和执行多个 warp,确保持续的高吞吐。
-
• 执行单元:SM 内部包含 CUDA 核心、用于数学运算的特殊功能单元(SFU)以及负责内存访问的加载/存储单元(LD/ST)。
-
• SM 内部存储层级:
-
• 共享内存:低延迟,供同一线程块内的所有线程共享。
-
• 寄存器:速度最快,按线程独立分配。
-
• L1 缓存:提升数据局部性,降低对全局内存的访问延迟。
优化 CUDA 程序需要在多个 SM 之间均衡负载、高效管理各类存储器并减少 warp 分支发散。
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
B站1:UID:3546863642871878
B站2:UID: 3546955410049087
参考文献链接
人工智能芯片与自动驾驶

 浙公网安备 33010602011771号
浙公网安备 33010602011771号