
NPU架构设计介绍
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
B站1:UID:3546863642871878
B站2:UID: 3546955410049087
1. NPU Cluster介绍
首先为什么要有簇?
一个AI计算任务,例如人脸识别需要大量的数据运算,那么要并行处理就需要对任务进行切片并行处理,那么一个子任务对应硬件的处理就是cluster,可以理解为多个cluster并行工作。
那就要保证cluster有足够的资源可以应对子任务,NPU的Core就是PE集成了计算单元,但是单个PE可能应对不了一个子任务,并且相关配套的SRAM和调度以及低频率的运算需要CPU的参与。这就需要cluster是一个最小的战斗单元,例如行军打仗,这个单元需要有做饭的,有后勤,有医疗,各种兵种都有才可以。
先举几个簇的例子:
1.1 壁仞科技
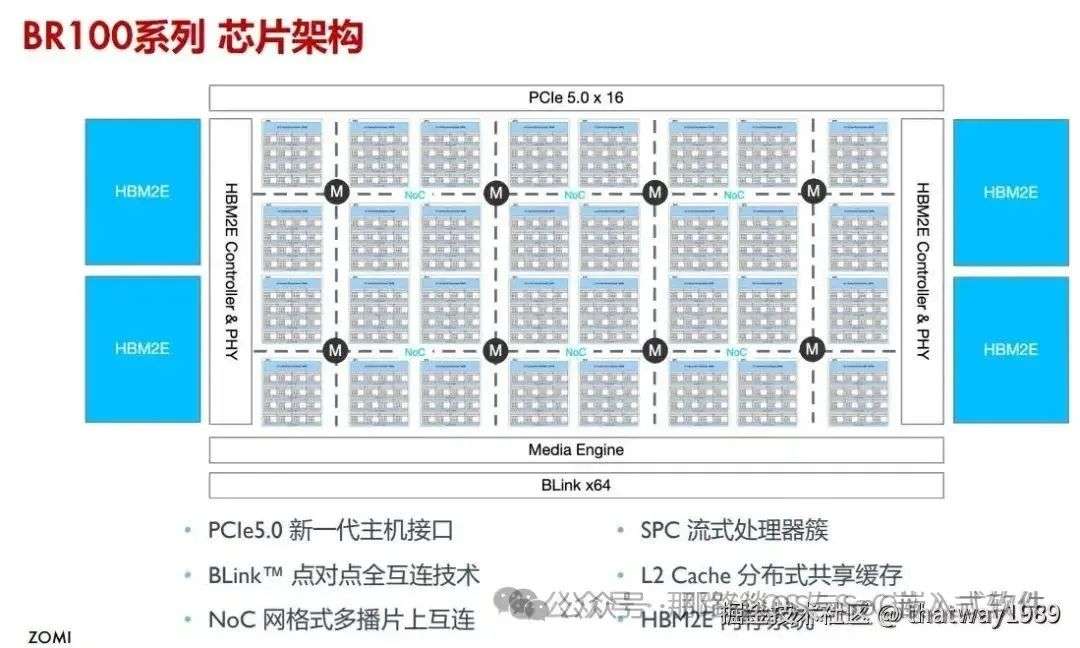
添加图片注释,不超过 140 字(可选)
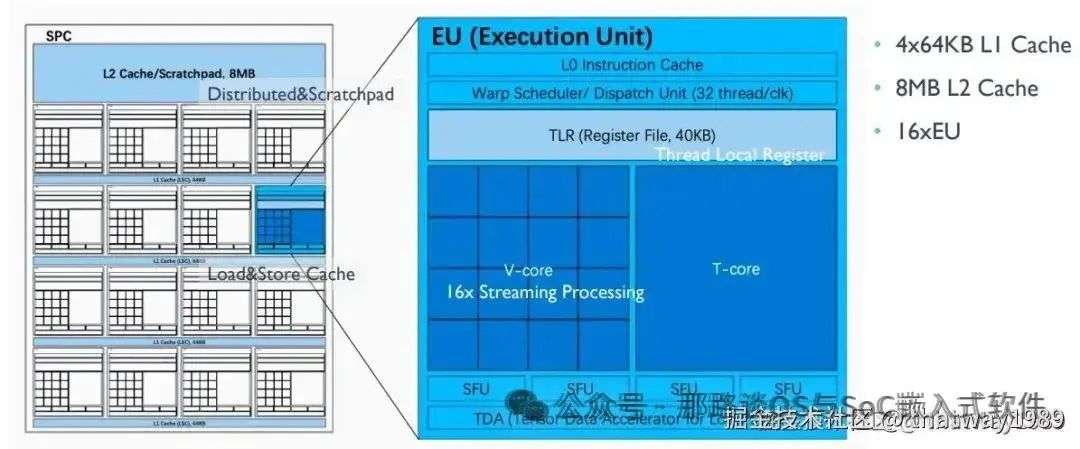
添加图片注释,不超过 140 字(可选)
可以看到簇之间使用NoC高速互联,簇内的Core则使用低速一点的通信就可以满足,这样二级的设计,让组织效率更加的有效。
同样cache在簇中有一级L1,PE有一级L0,这样两级的设计也让系统更加的有效。
这就是为什么说NPU的组织更像是一个公司,老板CPU发话说要干一个事情,NPU部门就对任务进行分解给各个子部门簇,子部门内部就去捯饬,不行跟相邻子部门借资源干。而不是CPU发话干一个事,没有组织的所有员工直接往上扑,就造成很多的资源浪费。
可以看到一个cluster里面有16个PE,具体多少个由业务去决定。然后就是簇里面除了EU还有什么,这个壁仞科技的只有缓存了,可见其偏GPU的设计,并不太纯粹的NPU。只是用GPU的思路,只是把里面的AI算子部分由通用直接变成神经网络深度学习专用的算子了。
1.2 寒武纪
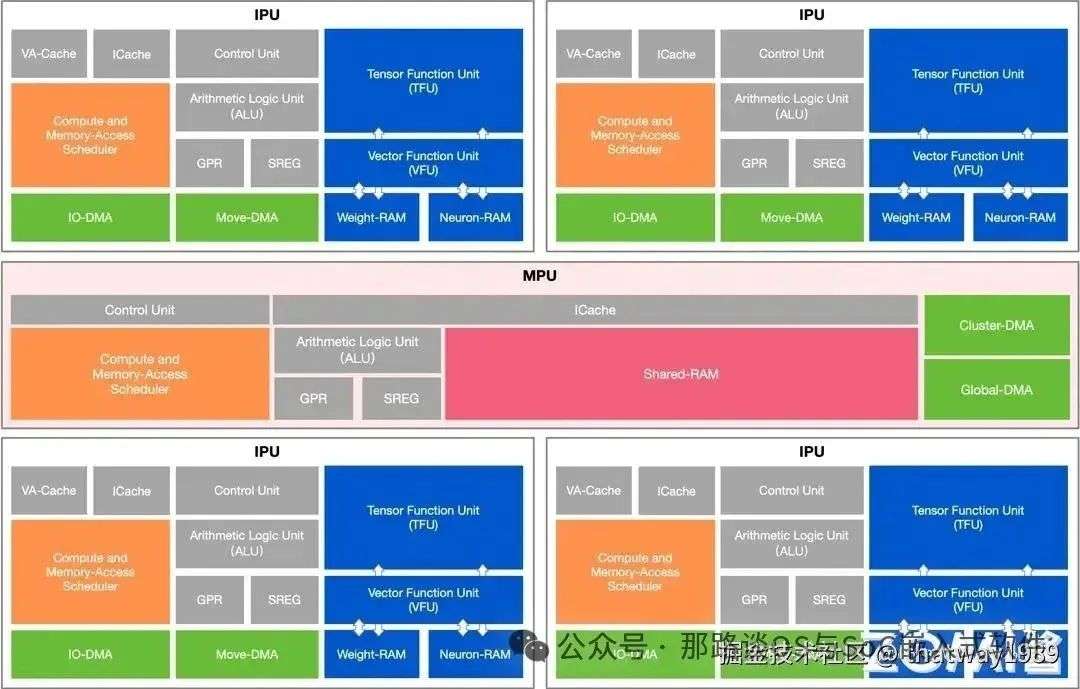
添加图片注释,不超过 140 字(可选)
其IPU就是PE,上图中是一个cluster里面有4个PE。
除了4个PE,又添加了MPU,用于内存处理的协处理器,里面有SRAM共享内存,还有DMA、针对cluster基本的调度控制,里面的东西还挺不少。但是感觉不够简洁和精细化,估计设计时间短直接堆出来的。
1.3 华为达芬奇
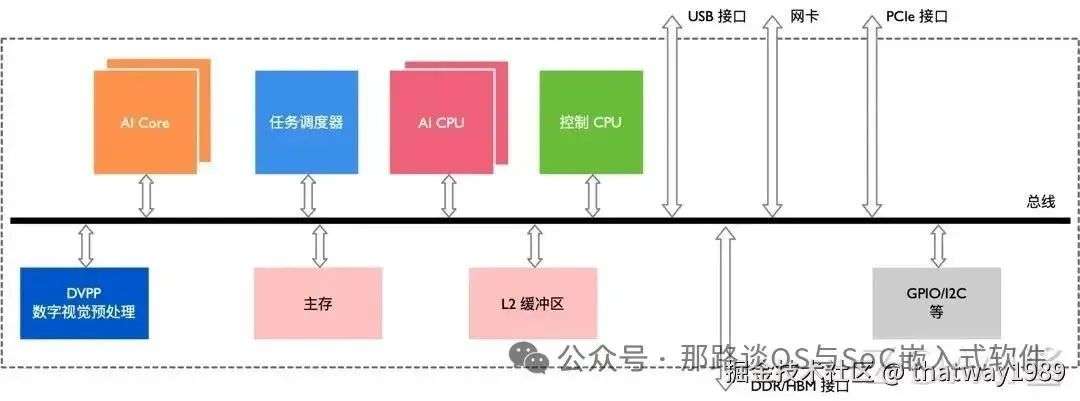
添加图片注释,不超过 140 字(可选)
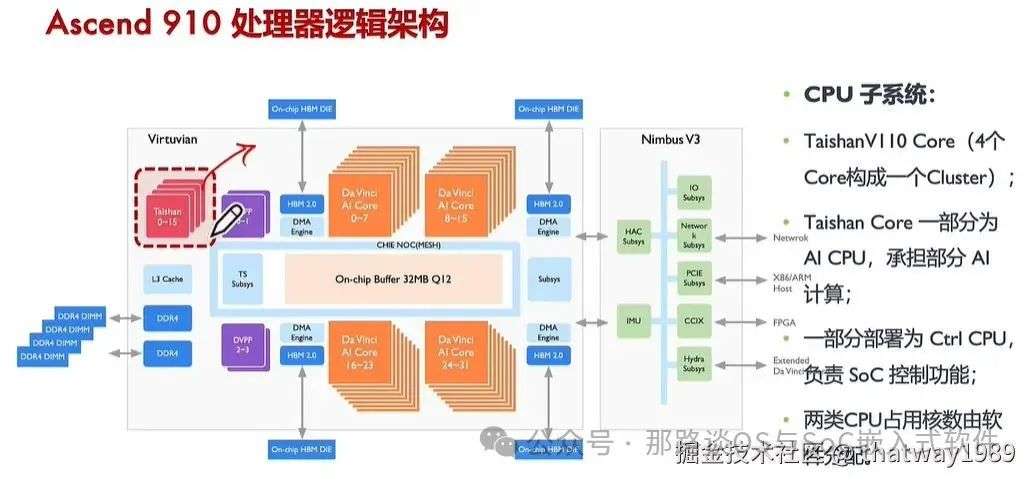
添加图片注释,不超过 140 字(可选)
没有用簇的概念,但是其有一个任务调度器,这里面感觉是隐形的把一些Core灵活的组织成了一个Cluster,另外其Core里面有强大的功能,更像是一个core一个cluster的感觉,例如里面有协处理器、缓存等。
添加图片注释,不超过 140 字(可选)
本文后续都按华为的一个Core就是一个cluster来介绍,因为其实现了cluster的功能,除了PE(计算单元外又集成了存储、控制等功能)。如果这个架构扩展一个cluster4个PE,那就把计算单元给分成4份就可以了。这里根据华为的场景子任务应该不需要那么多的Core,一份就够用了,这个就是一个cluster使用几个PE的权衡。
通过对比可能是需要针对不同的产品,或者一个架构对新产品适配的周期进行灵活的调整那些任务由那些硬件完成,特别是存储、通信、调度这些其实放哪里(NPU/cluster/core)都可以,怎么放(功能分配)、放多少,这就是考虑是否组织成簇的意义。
2. NPU整体架构设计
了解完cluster这个NPU中最重要的单位,我们再从NPU整体出发,以AI芯片架构分析五步法进行彻底的剖析:
对于AI芯片的架构,总结有下面5点(AI芯片五步分析法):
-
簇:计算部分有很多的cluster就是簇
-
PE:簇里面有几个PE(处理引擎AI Core),一般是4个,里面有张量、标量等计算硬件算子
-
调度:NPU里面有调度器管理cluster/PE的计算
-
通信:簇之间的通信,一般通过NoC总线
-
存储:SRAM一般有两级,簇有一个小的SRAM,NPU整体有一个大的SRAM
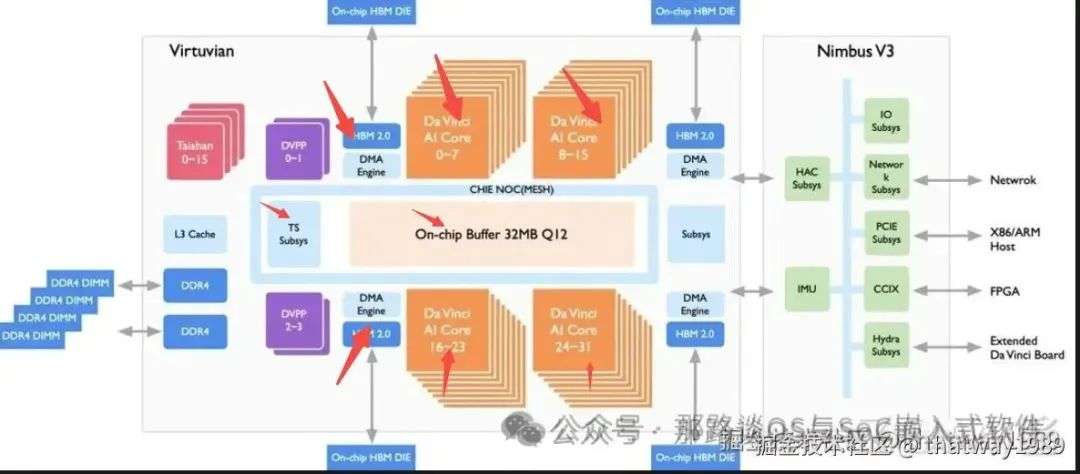
添加图片注释,不超过 140 字(可选)
NPU相关的可以看到:
-
调度器(调度)
-
DMA和SRAM(存储)
-
达芬奇core
-
通信总线
达芬奇core(一个cluster)内部的:
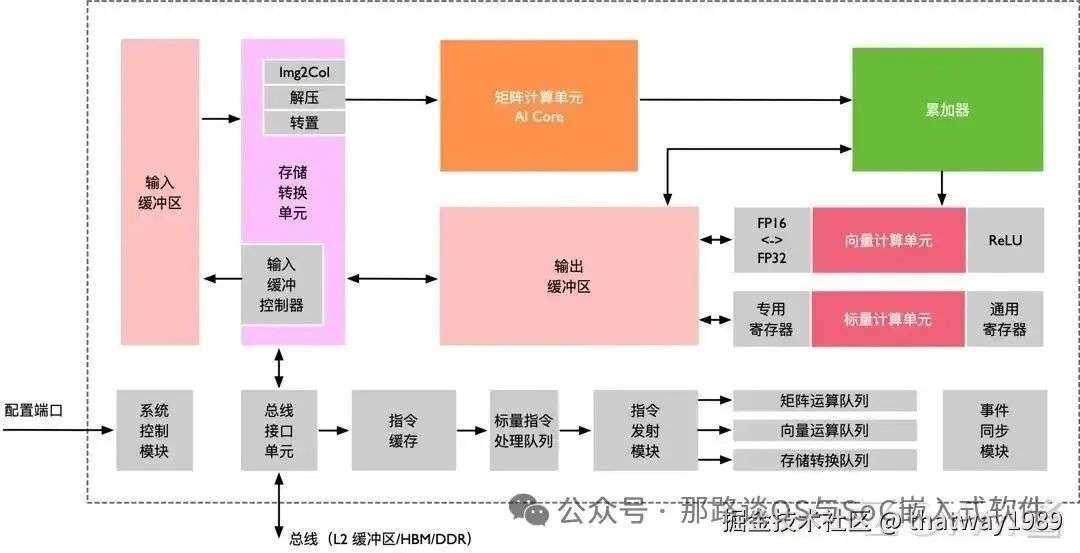
添加图片注释,不超过 140 字(可选)
cluster里面有:
-
计算单元(PE)
-
存储系统
-
控制单元(调度相关)
-
总线(通信)
华为达芬奇按AI芯片架构分析五步法归纳如下:
-
簇:一个达芬奇Cluster就是一个簇,簇里面有PE、存储、控制、通信
-
PE计算:簇里面有1个PE,里面有张量、向量、标量等计算硬件算子
-
调度:两级结构,独立的任务调度器和簇里面的控制器
-
通信:两级结构,簇间通信和簇内通信,通信种类包括数据总线、指令总线、中断、共享内存等。
-
存储:两级结构,簇有一个小的SRAM,NPU整体有一个大的SRAM
!!!重要:上面就是一个典型NPU框架设计,特别是对比上几款NPU的框架,基本也都是这么个套路,这里算是对NPU架构高度概况了下,至于细节的实现,使用什么技术怎么搭配就比较灵活了。
cluster其实是一个功能合集,设计上也最灵活,这里从功能角度介绍剩下的4个,然后再来看cluster设计的一些要点。
2.1 调度相关设计
我们还是以华为达芬奇为例,NPU里面的调度分为两部分:
-
任务调度器,独立的核和固件以及SRAM,专门用于切片后的任务调度
-
Cluster内部的控制单元,里面会有指令流水线,指挥子任务的执行
首先看下调度器的上游就是CPU和DDR,关系如下:
-
调度器接收CPU的任务,并反馈给CPU运行结果
-
获取NPU的一些信息给CPU
-
按照CPU的指示对NPU进行配置
-
对DDR中的AI数据搬运到SRAM更快的进行运算,这个搬运要快就需要数据总线NoC以及DMA 调度器跟CPU的通信其实属于核间通信了,基本依赖Mailbox,也就是中断+共享内存。
调度器跟下游cluster的通信,就是是发射NPU指令。这一条指令就是一行代码,就可以完成一次AI运算,如果没有AI硬件那就需要把这个算子的算法用多行代码进行实现。如下图所示:
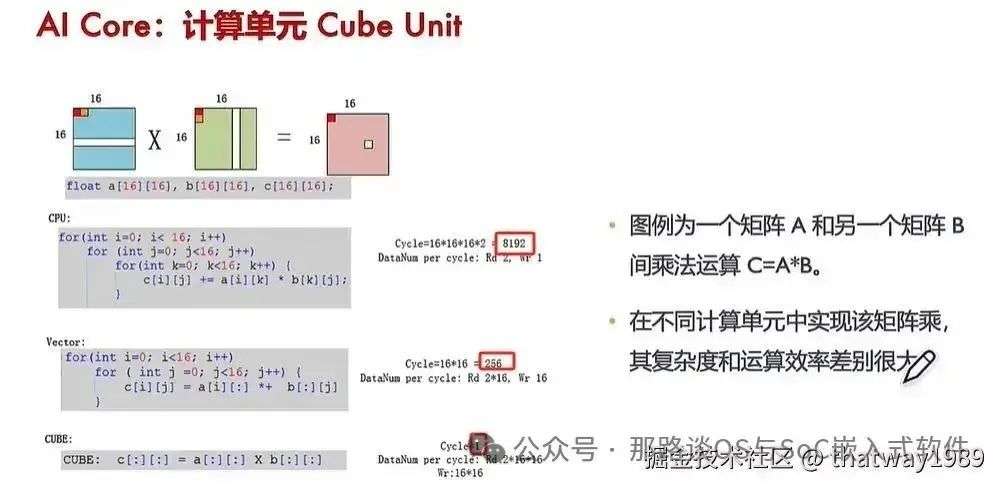
添加图片注释,不超过 140 字(可选)
发射的是如果是存算一体数据,那么就是调度器直接把NPU SRAM的存算一体数据给到Cluster的SRAM,这样Cluster里面的控制单元(有核一般是RISCV)就开始干活了,去取数据运行得到结果再给调度器。这点看华为达芬奇这个架构还没做,即它是指令和数据分离的,统一由调度器去先放数据,然后去发指令,不是一股脑的把存算打包为PE,这样调度器的压力就比较大,还是适合算力小的情况。
但是实现存算一体还有个问题就是对编译器的挑战,存算一体的数据是提前编译器搞好的,里面包含了调度依赖,这样减轻了调度器的压力(把运行时干的活放编译干,等于提前准备,干活时就快,这是计算机的一项重要技术),存算一体对PE来说是好处很多,运算时不用受调度器的指挥,只管对着存算一体数据干活,干完活才汇报,干活过程中不受打扰。
回到华为达芬奇这个调度器,其是一个固件,有核有RTOS,按照目前流行的做法是使用RISC-V+FreeRTOS实现,其作用就是安排好数据和指令给到Cluster。
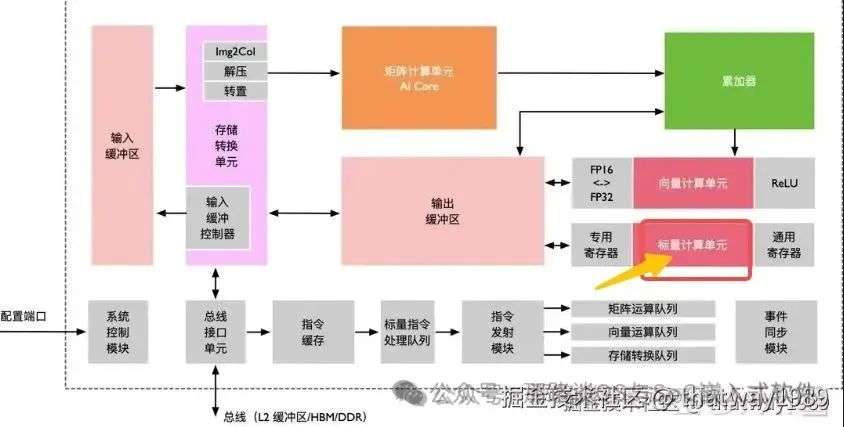
添加图片注释,不超过 140 字(可选)
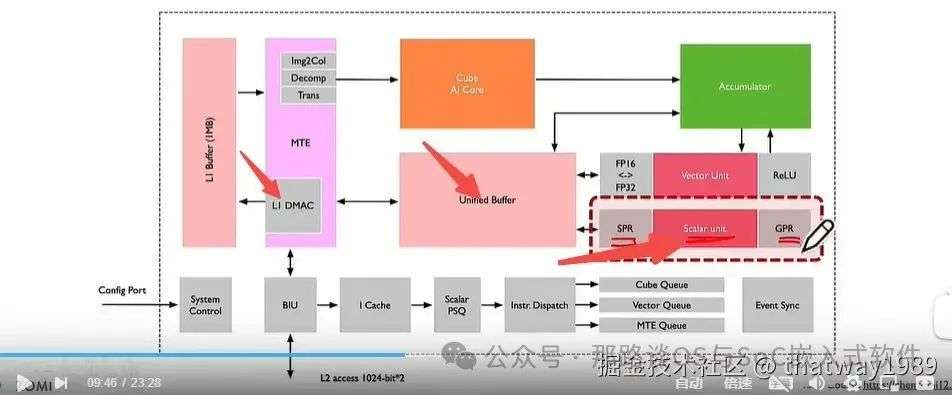
调度的另外一部分就是Cluster内部的控制单元,按ZOMI视频的说法这个标量处理单元其实是一个ARM核,除了进行常规的CPU标量运算,其还可以管理下面的指令队列和同步模块,那就是控制啊!
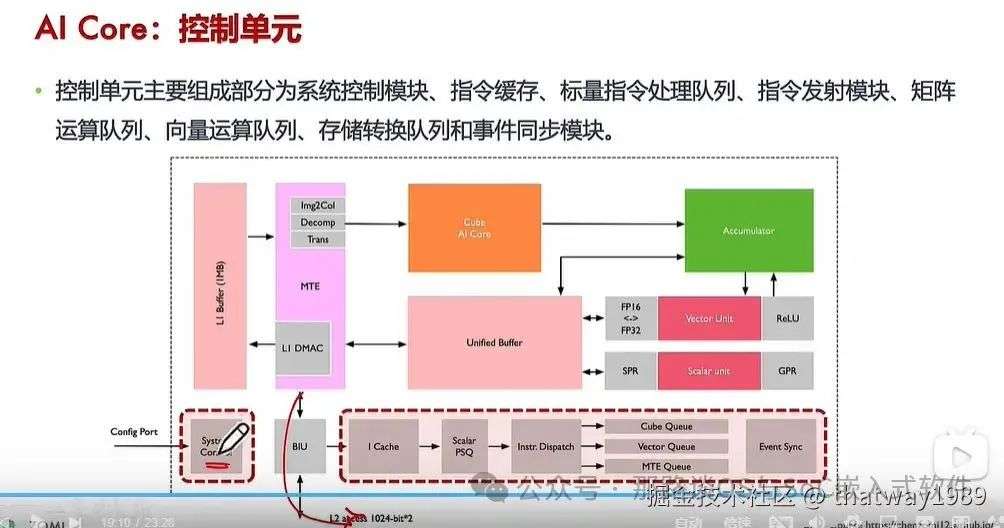
添加图片注释,不超过 140 字(可选)
灰色部分就是控制单元,其可以成为标量核的附属,因为ARM核或者RISC-V核本身就自带一些这样的功能,然后再通过核上运行软件的辅助就可以实现。
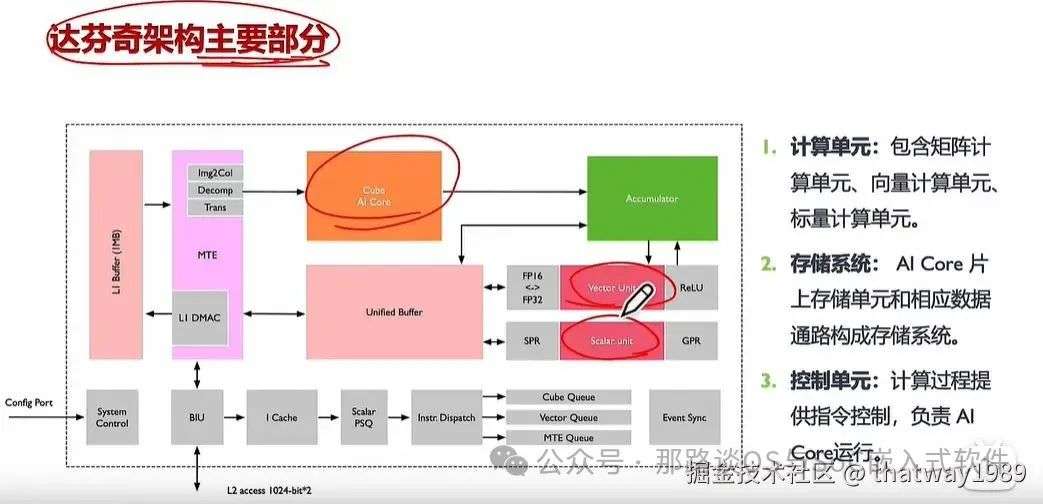
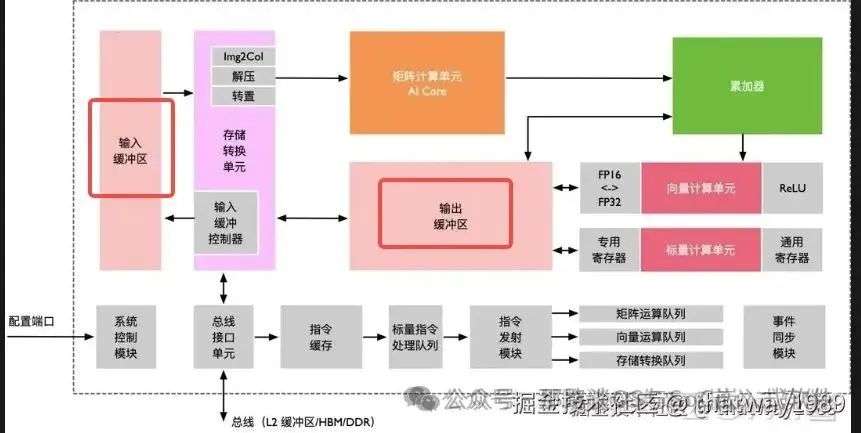
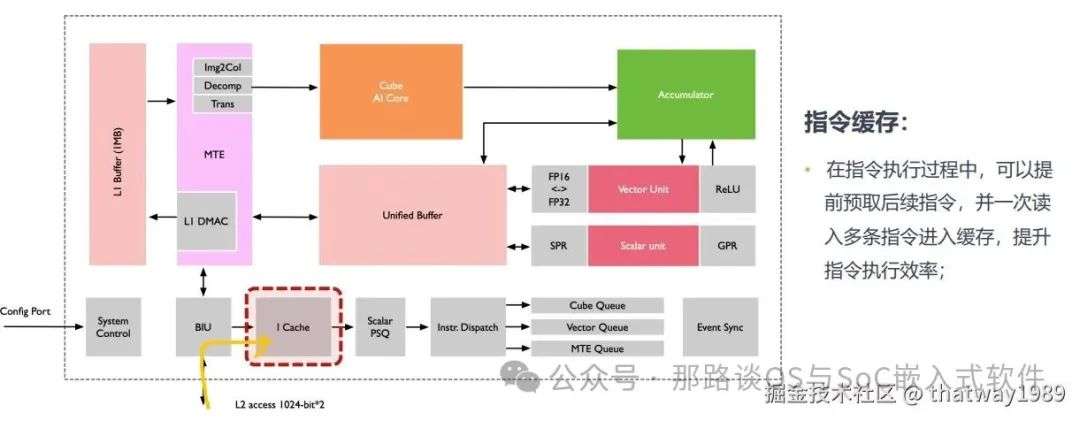
控制单元主要组成部分为系统控制模块、指令缓存、标量指令处理队列、指令发射模块、矩阵运算队列、向量运算队列、存储转换队列和事件同步模块。下面详细介绍下:
-
系统控制模块:控制任务块(AI Core最小任计算务粒度)的执行进程,在任务块执行完成后,系统控制模块会进行中断处理和状态申报。如果执行过程出错,会把执行的错误状态报告给任务调度器;
-
指令缓存:在指令执行过程中,可以提前预取后续指令,并一次读入多条指令进入缓存,提升 指令执行效率;
-
标量指令处理队列:指令被解码后便会被导入标量队列中,实现地址解码与 运算控制,这些指令包括矩 阵计算指令、向量计算指令以及存储转换指令等;
-
指令发射模块:读取标量指令队列中配置好 的指令地址和参数解码,然后根据指令类型分别发送到 对应的指令执行队列中,而 标量指令会驻留在标量指令 处理队列中进行后续执行;
-
指令执行队列:指令执行队列由矩阵运算队 列、向量运算队列和存储转 换队列组成,不同的指令进 入相应的运算队列,队列中的指令按进入顺序执行;
-
事件同步模块:时刻控制每条指令流水线的 执行状态,并分析不同流水 线的依赖关系,从而解决指令流水线之间的数据依赖和同步的问题。

添加图片注释,不超过 140 字(可选)
这个标量处理单元怎么去触发AI矩阵运算单元和向量单元等工作呢?答案就是其可以定制NPU指令集,ARM或者RISCV是支持的,这样就可以在cluster里面做土皇帝了。自己干点标量计算的活,顺带当个工头代班指挥下别人干活。
调度器发射指令就需要用到指令总线,所以指令总线需要把Cluster都串起来,这里华为达芬奇就按1个Core就是1个Cluster来说。
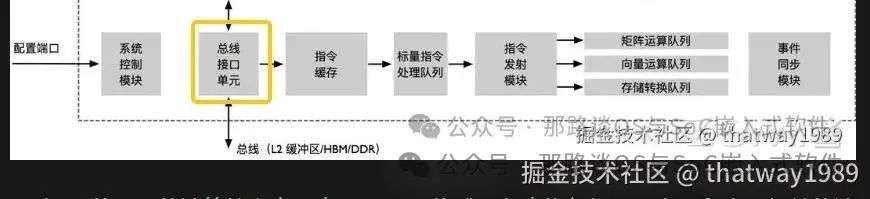
添加图片注释,不超过 140 字(可选)
调度在软件层面非常的核心,甚至决定AI芯片的成败也在这上面,因为实现太难了,这里说的很少的篇幅,但是具体技术代码实现上用到的东西涉及核心的技术算法,研究这个的应该都是顶尖人才了。就是AI编译器静态和调度器动态的协调配合,去盘活整个NPU那么多核的资源利用率。
大家都知道CPU的平均利用率基本10%,这个NPU要想在做业务的时候是核心算子是满负载的状态,软件的确难度很大。这还涉及到NPU中硬件算子的搭配比例,不能有一些类型的算子不够而拖后腿。
2.2 存储相关设计
这里还是以华为达芬奇为例进行介绍:
添加图片注释,不超过 140 字(可选)
上图中cluster内部存储来说主打一个近存计算速度快,也就是说PE(计算单元)要离存储近,而且这个存储必须上快速的SRAM。
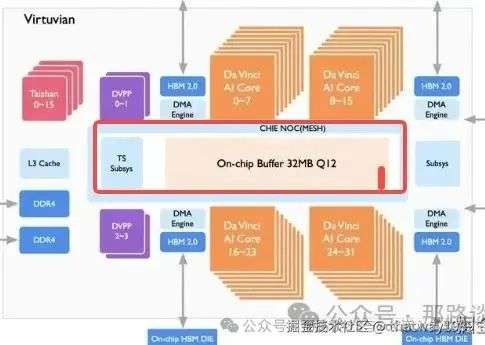
添加图片注释,不超过 140 字(可选)
要处理的AI数据的根源在DDR里面,那直接从DDR搬运到PE的SRAM就又慢了,DDR会拖后腿,那就在NPU里面放一个大的SRAM,从NPU的SRAM往PE的SRAM里面拷贝就ok了,另外这里的搬运需要用到DMA,这样把这种搬运任务从控制系统解放出来,并行操作,等于加了一个人干活。
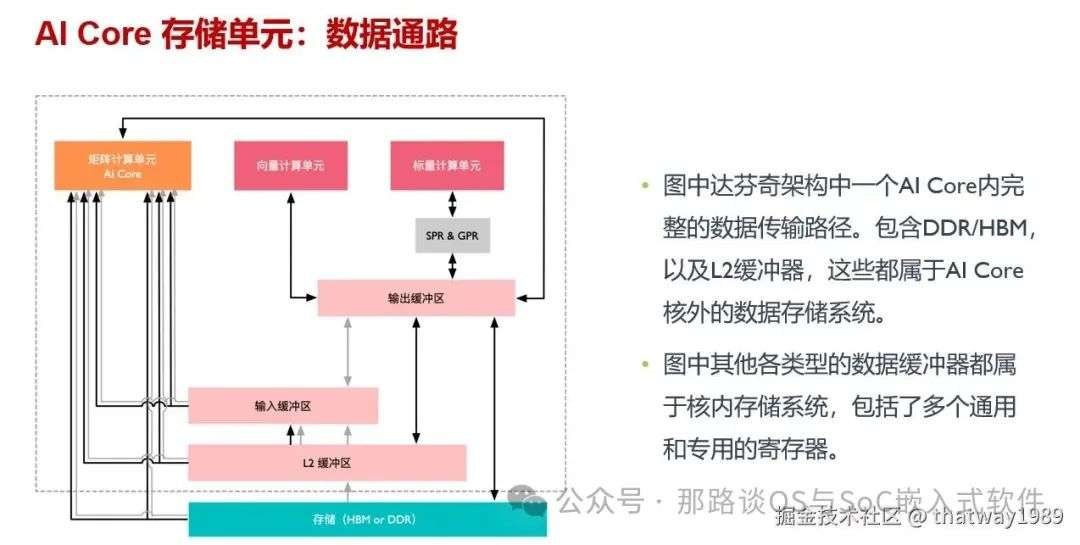
所以,NPU里面使用了两级SRAM进行存储。 对于cluster内部的存储有三部分组成:
-
存储控制单元:通过总线接口直接访问 AI Core 外更低层级缓存,也可直通DDR/HBM 访问内存。另外设置存储转换单元,作为AI Core内部数据通路传输控制器,负责AI Core内部数据在不同缓冲区间读写管理,以及完成一系列的格式转换操作,如补零,Img2Col,转置、解压缩等。跟BIU总线进行通信连接,这样cluster外就可以通过BIU跟这个DMA进行指令通信。
-
输入缓冲区:用于暂存需频繁复用数据,不需要每次都通过总线接口到 AI Core 外部读取;从而减少 BUS 上数据访问频次,同时降低总线数据拥堵风险;实现节省功耗、提高IO、提升性能效果;
-
输出缓冲区:用来存放神经网络中每层计算中间结果,从而在进入下一层计算时方便获取数据。相比较 BUS 读取数据带宽低,延迟大,通过输出缓冲区可以极大提升计算效率;
添加图片注释,不超过 140 字(可选)
2.3 通信相关
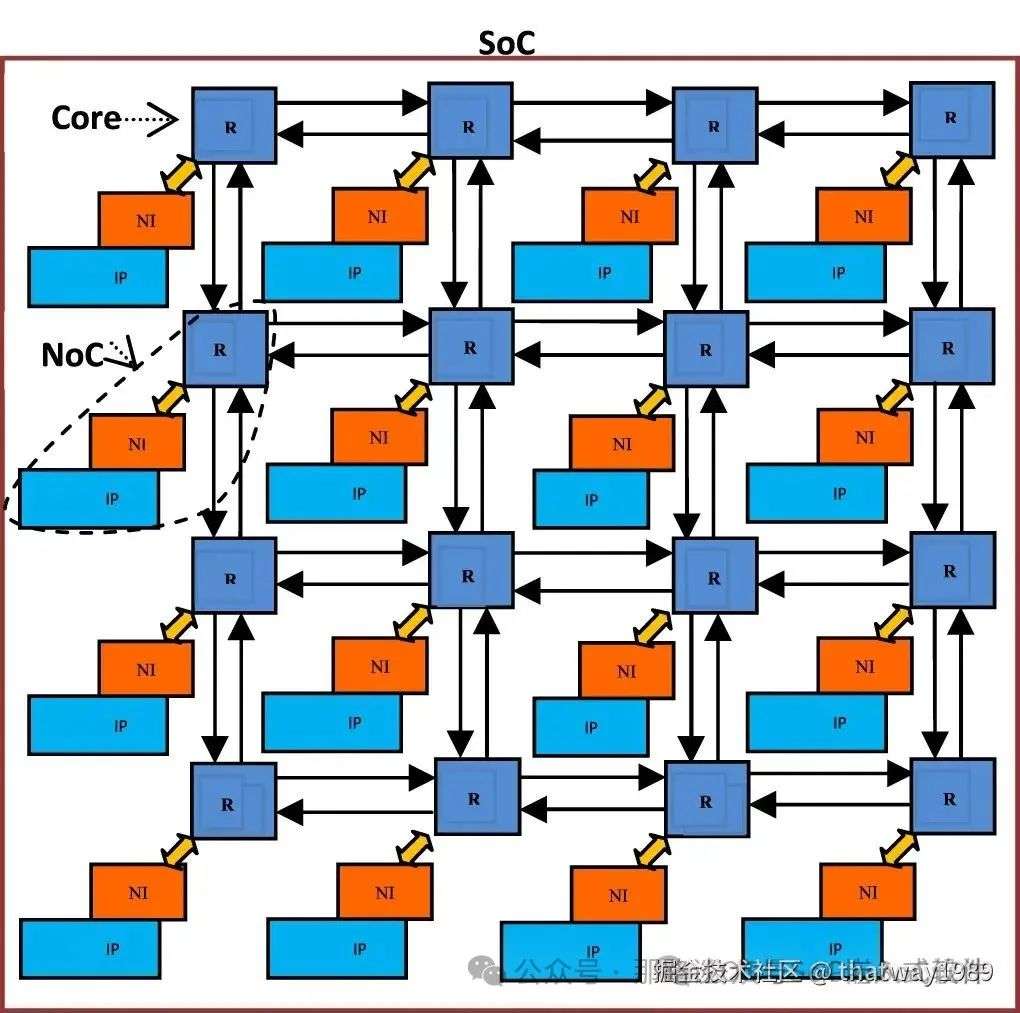
1. 首先就是中断,这个核间通信必备,参考之前文章:SoC软件技术--核间通信。CPU和调度器之间,调度器和Cluster直接都使用中断去触发一些通信。
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
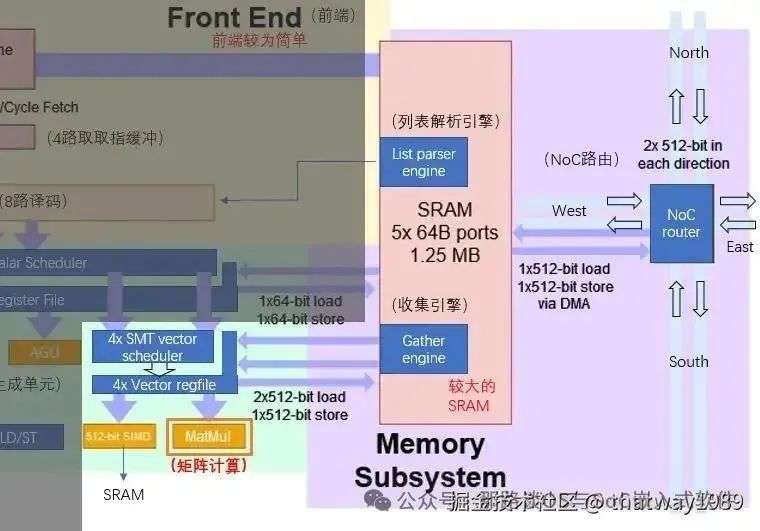
2. 如上图,数据搬运拷贝就用NoC总线配合DMA进行。NoC是Mesh总线,就是擅长点对点的数据传输,算mesh总线。如果需要对数据进行广播的场景,在并行计算中会经常用到,一个数据广播给几个PE同时接收,这样这几个PE协同运算只用广播这一次数据就可以了。那么适用于广播的环形总线也需要安排上,把各个Cluster给串起来。
添加图片注释,不超过 140 字(可选)
3. 其他就是调度器跟Core之间的数据总线和指令总线了。指令总线在华为达芬奇里面就是BIU,数据总线没提,这些硬件根据需求都可以自己设计,例如NoC、APB这些CPU里面常用到的总线技术。
这些都是芯片最基本的技术,每个芯片里面都有这些东西,这里只是把信息提炼了下,入门简单介绍下。
在SoC里面能触发通信的单位需要有核,例如CPU、调度器、标量核。然后对于数据通信来说核都配的有DMA帮手,数据介质就是DDR、NPU SRAM、Cluster SRAM,什么核能访问什么复制什么数据,通过什么总线,都是需要设计的。权限和根据和的MPU来设置,总线的类型有快有慢,按需使用。
-
NoC总线:SoC内速度最高,但是成本也高
-
AXI总线:高速度、高带宽,支持管道化互联、读写并行、乱序传输和非对齐操作,适用于高性能、高带宽的SoC系统。其多通道设计(五个独立通道)和复杂的仲裁机制使其能够高效处理大量数据传输,但实现复杂度和硬件开销较大。
-
APB总线:低速、低功耗,设计简单,主要用于低带宽的外围设备(如UART、I2C等)。其单主设备多从设备的架构和简单的状态机设计使其易于实现,但无法满足高性能需求。
2.4 计算单元PE
PE里面就是算子构成的,算子是指令直接驱动。
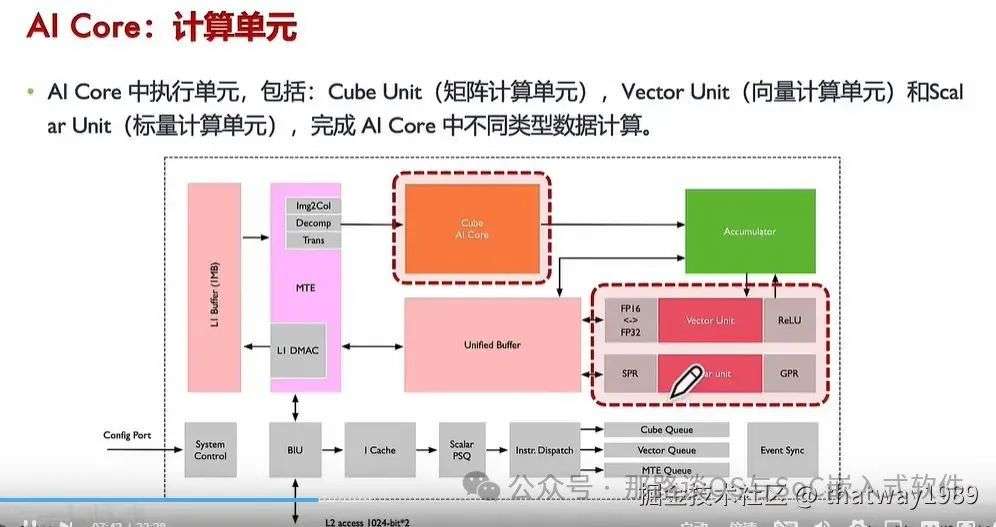
添加图片注释,不超过 140 字(可选)
-
CLube矩阵计算:深度学习算法必备的算子,这类AI算子就是NPU的核心,最后都是为它服务的,干最重的活
-
向量运算:例如平方根、求导运算等,可以完成AI中的softmax、laynorm计算
-
标量运算:普通的运算,通用CPU即可以完成,且负责各类型标量数据运算和程序流程控制:算力最低,功能上类比小核 CPU,完成整个程序循环控制、分支判断、Cube/Vector 等指令地址和参数计算以及基本算术运算等。
-
累加器:把当前矩阵乘结果与上一次计算中间结果相加, 可以用于完成卷积中加 bias 等操作。
-
MTE存储转换单元:例如矩阵的存储是一维的,多维矩阵就需要进行转换,这里也是一个算子
-
同步模块:也是标量核控制的硬件,需要用指令触发
2.5 Cluster相关
NPU的另一种拆分从功能角度就是管理和计算。cluster专注计算,稍微带点基础队列的管理,调度器则主抓管理。所以cluster在管理和计算上有很大的灵活性。
1. Cluster需要用多少个PE? 通常就是寒武纪的4个,具体根据业务,如果是1个那就没有Cluster了,就像华为的。
2. Cluster里面除了PE还可以放什么? 首先一个SRAM供PE近存使用,这样算的快,那配套的DMA和协处理器也需要安排上。协处理器可以用RISCV同时做一些标量运算,弥补PE的缺陷,这个协处理器也可以运行队列组织PE有序的运行。
添加图片注释,不超过 140 字(可选)
例如上图华为达芬奇中的。
3. Cluster之间用什么连接? culster是运作子任务的单位,那么子任务是由调度器去管理的,调度器跟Cluster的数据通信有NoC,还有需要指令总线和数据总线来实现,例如寒武纪的设计。
4. 属于NPU,但是在Cluster之外有什么? 首先就是调度器,然后是NoC总线,以及指令和数据总线。然后有一个NPU使用大的SRAM例如华为达芬奇里面的。这个就需要协调这些存储、通信、调度等资源的颗粒度,那些放NPU里面,那些放Cluster里面,那些放调度器里面。
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
B站1:UID:3546863642871878
B站2:UID: 3546955410049087
参考文献链接
人工智能芯片与自动驾驶

 浙公网安备 33010602011771号
浙公网安备 33010602011771号