

国产AI芯片架构之争:GPGPU与ASIC
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
之前一直有消息说华为昇腾要从NPU转向GPGPU架构,不知道是真是假,尤其是CANN开源以后,市场上各种声音就又多了起来,很多之前购买了相关产品的客户也比较担心,如果未来昇腾的产品架构发生根本变化,是否会影响到现有产品的支持与维护。这种担忧并非空穴来风,毕竟许多客户都在基于昇腾的产品进行大规模部署,转向新架构可能意味着重新适配甚至可能面临的技术割裂问题。
说到底,AI芯片市场的竞争,尤其是在GPGPU、NPU等不同架构之间的博弈,最终还是要回到生态建设的竞争上。
以NVIDIA为例,CUDA生态已经牢牢把控了AI训练和推理领域的大部分市场份额。CUDA作为NVIDIA自家推出的并行计算平台,已经成为了AI计算领域的标准,它不仅为GPU硬件提供了强大的支持,还衍生出了无数的深度学习框架、优化库和开发工具。无论是训练大型模型还是进行推理,CUDA几乎是AI领域的“黄金标准”,这也使得NVIDIA在整个AI计算市场中占据了无可撼动的地位。
其他芯片厂商想要在这样的格局中分一杯羹,面临的最大挑战就是如何与CUDA兼容,或者是如何打造出自己的生态,与CUDA分庭抗礼。如果选择兼容CUDA,就意味着必须重新开发适配CUDA的算子、库和工具,这无疑是一个庞大的工程。而如果选择独立开发生态,那么它不仅需要一款能够与CUDA媲美的硬件架构,还需要全方位的开发工具和成熟的应用案例。无论哪条路,都需要巨大的投入和长期的积累。
那么为什么说NPU很难兼容CUDA呢,这还要从芯片架构说起。
CUDA是NVIDIA专为其GPU设计的编程模型,它紧密结合了NVIDIA的GPU架构。要兼容CUDA,硬件需要具备与NVIDIA GPU类似的并行计算架构。而NPU是为特定的任务(如神经网络计算)设计的专用硬件,通常优化了矩阵运算、卷积计算等深度学习操作。这使得NPU的架构与CUDA优化的通用GPU架构差异较大,无法直接支持CUDA的编程模型。
不同的AI芯片架构,决定了计算的效率、能耗和适用场景,其中最具代表性的三类架构是GPGPU、ASIC和FPGA。
这三类芯片不仅在技术路线和设计理念上存在显著差异,在产业生态、市场格局和未来发展方向上也各有千秋。

添加图片注释,不超过 140 字(可选)
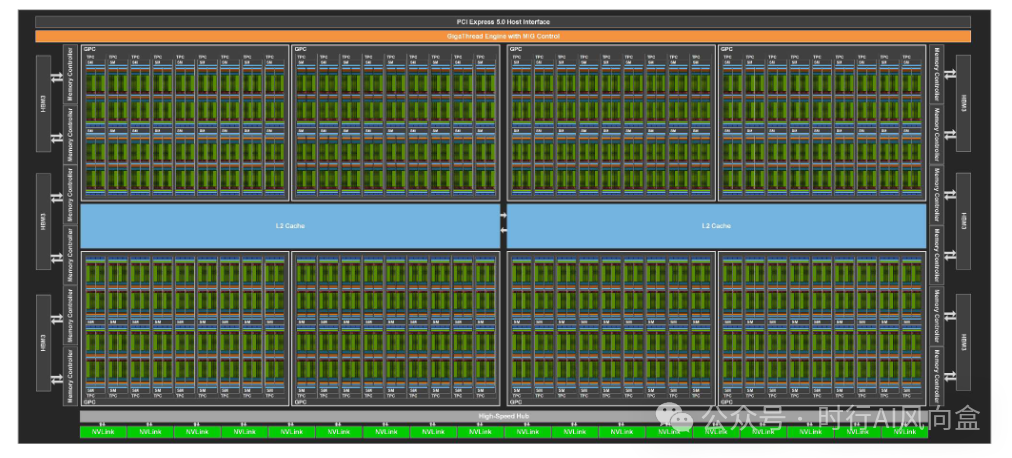
GPGPU,即通用图形处理器(General-Purpose GPU),GPU最初是为图形渲染设计的硬件,但随着CUDA等通用计算平台的出现,GPU逐渐在高性能并行计算领域展现出优势,尤其适合深度学习中的矩阵运算。GPGPU就是弱化了GPU的图形渲染能力,专注于进行大规模并行计算的产品。NVIDIA是全球GPGPU市场的绝对龙头,其H100/A100、H200、H20等产品在AI训练与推理中占据主导地位。国内的GPGPU厂商起步较晚,如海光(DCU系列)、摩尔线程、沐曦(C系列)等,主要客户包括国内云服务提供商、国有企业和地方政府支持的数据中心。GPGPU的优势在于生态成熟、通用性强,尤其在AI训练阶段具备绝对统治力,但其劣势也很明显:功耗高、成本昂贵。
添加图片注释,不超过 140 字(可选)
与之形成对比的是ASIC(专用集成电路,Application-Specific Integrated Circuit),这种芯片为特定任务量身定制,不追求通用性,而是以极致性能和低功耗为目标。ASIC在AI领域的典型代表包括昇腾(Ascend 910系列)、寒武纪(思元系列)、燧原科技等芯片厂商,以及百度昆仑、阿里巴巴平头哥、腾讯紫霄(这个应该是跟燧原合作的)等由CSP自主研发的方案。第三方ASIC厂商的客户主要集中在国有企业、大型互联网公司以及部分科研机构;CSP自研ASIC则多用于其自家数据中心,也会在与政府合作的项目中出现。ASIC的优势在于峰值算力能做到极致,对特定AI模型的推理速度极快,功耗和成本优势明显,非常适合大规模部署推理任务,但劣势是灵活性差,一旦模型架构发生重大变化,芯片可能无法充分适配,生命周期受限。
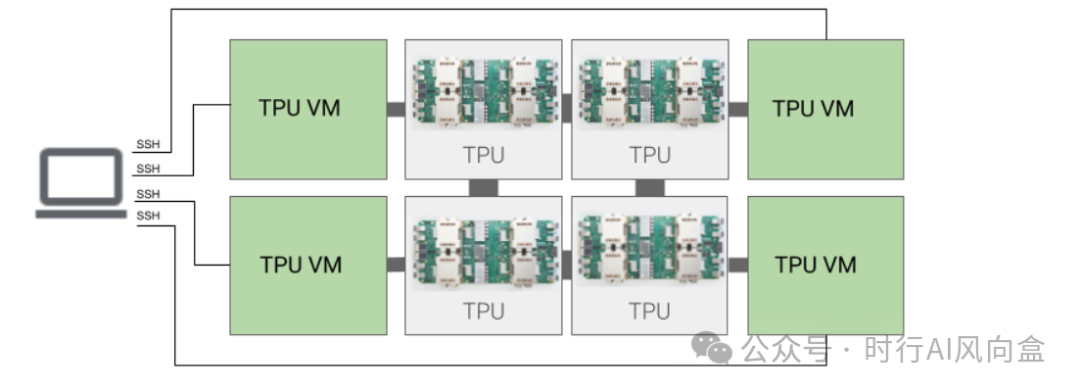
另外,TPU也属于典型的ASIC阵营,谷歌通过定制化的硬件架构,优化了矩阵运算和张量处理,一开始专用于进行翻译任务,如今也大批量用于谷歌自己的数据中心里面。
添加图片注释,不超过 140 字(可选)
最后还有一种FPGA(现场可编程门阵列,Field-Programmable Gate Array)则处于两者之间,AI芯片上用得比较少了。它的硬件结构可在出厂后通过编程进行重构,因此兼具一定的灵活性与硬件加速能力。FPGA在AI早期曾被广泛应用于推理任务,尤其是在延迟敏感的场景中,如金融风控、自动驾驶感知模块、实时视频分析等。Intel(通过收购Altera)和赛灵思(Xilinx,已被AMD收购)是FPGA领域的两大巨头,国内也有如安路科技、紫光同创等厂商切入。FPGA的优势在于可编程性,能够在不同任务之间灵活切换,而且硬件层面的并行性使其在特定推理任务中比CPU更高效。然而,FPGA的成本高,编程门槛高,生态相对较弱,且在大规模AI训练中性能不如GPU,在能效上也很难与ASIC相比,因此其市场定位相对细分化。
其实FPGA在芯片验证阶段用得还是比较多的,同时在一些数据流处理(比如防火墙)这些领域也有用到。
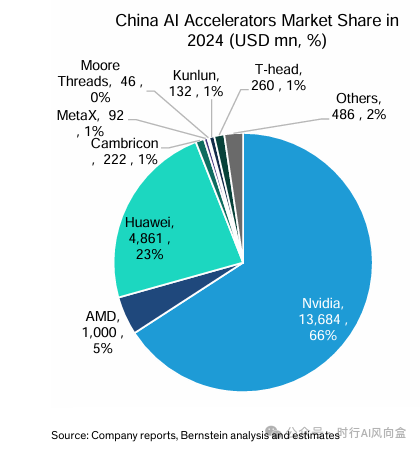
从全球格局来看,GPGPU由NVIDIA长期垄断,AMD和Intel虽有布局,但市场份额有限;ASIC则呈现多元化竞争格局,既有谷歌的TPU,也有中国的昇腾、寒武纪、平头哥等不断迭代升级;FPGA虽然在通用AI领域热度下降,但在边缘计算、工业控制和5G基站等场景中依然不可替代。国内厂商在这三条技术路线上的差距和机会并存。GPGPU方面,受制于上游技术壁垒和生态建设难度,国内厂商在高端产品上与NVIDIA差距明显,但在特定垂直场景和性价比领域具备切入机会。ASIC方面,国内厂商凭借在特定AI推理任务上的本地化优化,已经逐渐在政府项目、运营商和本土互联网巨头中获得稳定订单。FPGA方面,国内厂商正通过自主架构和国产EDA工具链逐步摆脱对海外厂商的依赖。
小编个人认为,AI训练阶段可能长期由GPGPU主导,因为它的通用性和开发生态优势短期难以撼动;推理阶段则将更加多元化,ASIC会在能耗、延迟、成本等维度有更好的表现。同时,随着大模型的推理优化技术(如量化、蒸馏、稀疏化)的发展,对芯片架构的需求也会发生变化,这将进一步推动芯片厂商在架构设计上进行创新,就好像之前炒得比较多的“量子通信”(虽然小编没有了解过,但是听起来还是很厉害的)。
添加图片注释,不超过 140 字(可选)
总的来看,在算力需求持续攀升的今天,谁能在这场架构之争中取得优势,不仅取决于技术本身,更取决于生态构建、供应链布局以及对应用需求变化的敏锐响应。
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
B站:UID:3546863642871878
参考文献链接
人工智能芯片与自动驾驶

 浙公网安备 33010602011771号
浙公网安备 33010602011771号