
让NCCL性能起飞的NCCL symmetric memory是啥黑科技?— part1
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
本文是 NCCL 2.27 [1]新特性系列的第一部分。在后续的文章中,我们将继续深入解析NCCL 2.27的其他特性亮点功能,敬请期待。
初见symmetric memory,就有种似曾相识的感觉— 它的设计理念似乎与 NVSHMEM 的实现机制有几分相似。目前,symmetric memory 仅支持 intra-node(单节点)通信。据官方透露,未来将会在此机制的基础上,结合 IBGDA 来支持 inter-node(跨节点)通信,以参考 NVIDIA NCCL GitHub Issue #1615。
1. symmetric memory Low-latency kernels 性能起飞
从下图可以看到,当使用symmetric memory low latency kernel时,小数据量通信的性能几乎被“压榨”到了极限。
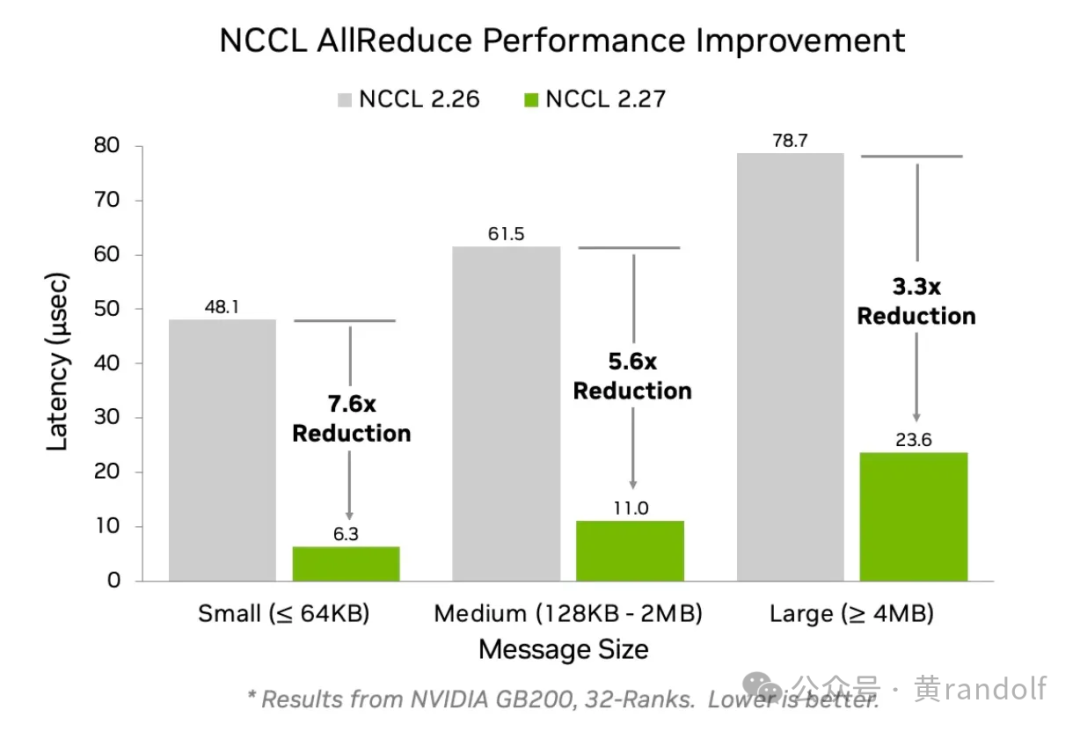
添加图片注释,不超过 140 字(可选)
Symmetric Memory 在一个 NVLink Domain 内提供 NVLink 通信支持。在 NVL72 架构上,它能让节点内通信的带宽和延迟表现出惊人的优势。在 NVL8 架构(如 DGX-H100)上,同样能带来显著的性能提升。
可以用 nccl-tests 进行验证:运行时加上参数 -R 2 即可开启 Symmetric Memory 模式。
2. 从一个case说起
我们先来看一个 Symmetric Memory 的使用示例
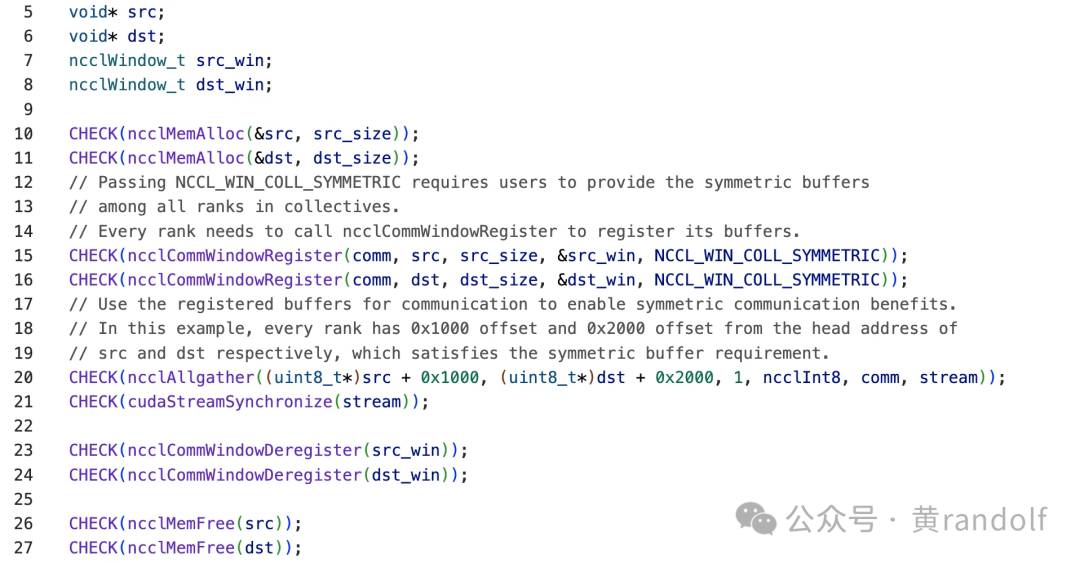
添加图片注释,不超过 140 字(可选)
操作流程:
-
通过ncclMemMalloc调用VMM API分配buffer;
-
通过ncclCommWindowRegister接口注册src/dst buffer;
-
调用集合通信算子进行集合通信,如ncclAllgather;
-
使用 ncclCommWindowDeRegister 释放 Symmetric Memory window;
-
调用ncclMemFree释放VMM API分配的buffer。
要理解 Symmetric Memory 的,必须先熟悉 VMM(Virtual Memory Management) 的一些关键机制。下一节我们会专门用一个章节深入剖析 VMM,然后再回到这个案例,看看它背后的细节。
不过,在这个例子里有一个细节值得提前留意:为什么 Allgather 的 input 和 output buffer 都需要加 offset? 这个问题的答案,我们会在后面详细解答。
3. CUDA 的virtual memory management
在CUDA 10.2(2020年)中引入了virtual memory management,提供了一系列全新的cuda driver api。VMM提供了一种机制,显存的虚拟地址和物理地址解耦(类似mmap的工作机制),允许编程人员分别处理它们。
3.1 cuda内存管理接口
3.1.1 CUDA 10.2 之前的内存分配方式
在此之前,用户主要通过下列 API 分配 GPU 内存(直接返回一个可用的虚拟地址):
// cuda api__
host__ __device__ cudaError_t cudaMalloc(void **devPtr, size_t size);
host__ cudaError_t cudaMallocManaged(void **devPtr, size_t size, unsigned int flags = cudaMemAttachGlobal);__
host__ cudaError_t cudaMallocPitch(void **devPtr, size_t *pitch, size_t width, size_t height);__
host__ __device__ cudaError_t cudaFree(void *devPtr);
// cuda driver api
CUresult cuMemAlloc(CUdeviceptr * dptr, size_t bytesize);
CUresult cuMemFree(CUdeviceptr dptr) ;
这些接口的使用流程大致如下:
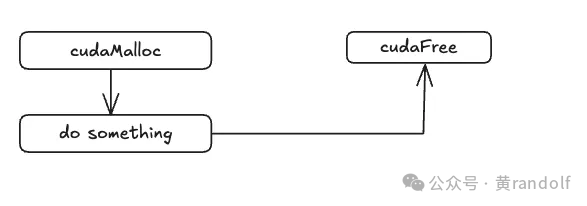
添加图片注释,不超过 140 字(可选)
3.1.2 CUDA 10.2 引入的 VMM 接口
新的 VMM API 让开发者可以先保留一段虚拟地址空间,再单独分配物理内存,并手动将二者映射起来:
CUresult cuMemGetAllocationGranularity(size_t* granularity, const CUmemAllocationProp* prop, CUmemAllocationGranularity_flags option); CUresult cuMemAddressReserve(CUdeviceptr* ptr, size_t size, size_t alignment, CUdeviceptr addr, unsigned long long flags); CUresult cuMemCreate(CUmemGenericAllocationHandle* handle, size_t size, const CUmemAllocationProp* prop, unsigned long long flags); CUresult cuMemMap(CUdeviceptr ptr, size_t size, size_t offset, CUmemGenericAllocationHandle handle, unsigned long long flags); CUresult cuMemSetAccess(CUdeviceptr ptr, size_t size, const CUmemAccessDesc* desc, size_t count); CUresult cuMemUnmap(CUdeviceptr ptr, size_t size); CUresult cuMemAddressFree(CUdeviceptr ptr, size_t size); CUresult cuMemRelease(CUmemGenericAllocationHandle handle);rity_flags option);
整个工作流程如下图所示。
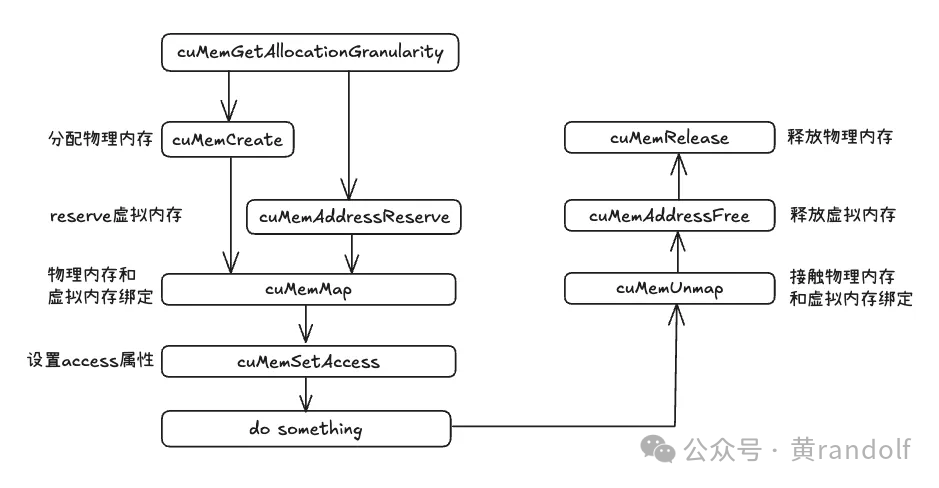
添加图片注释,不超过 140 字(可选)
这里你可能会有疑惑?
VMM API要求granularity(分配粒度)对齐,而cudaMalloc/cuMemAlloc没有这个约束。
实际上cudaMalloc也会与分配粒度对齐,只不过用户不会感知而已。
3.2 CUDA实现Vector面临的问题
NVIDIA 在官方示例中给出了基于 VMM API 实现 vector 的完整案例[3]。这里我们对比两种实现方式——传统 cudaMalloc 和基于 VMM API 的实现——来看看它们的差异。
首先,我们看一下vector类的定义:它使用一个reserve接口用于提前保留出一块memory,grow接口用于当reserve size不够用时,增长分配空间的大小。

添加图片注释,不超过 140 字(可选)
3.2.1 cudaMalloc实现方案
在 cudaMalloc 版本的 reserve 实现中:1)当需要的容量 new_sz 大于当前已保留容量 reserve_sz 时,必须重新分配一块更大的内存(new_sz)。2)然后把原有数据拷贝到新分配的内存中。3)最后释放旧内存,用新指针 new_ptr 作为存储区域。
这种方式的缺点是显而易见的:有额外的数据拷贝开销而且对内存需求更大:例如 reserve_sz 为 1GB、new_sz 为 2GB 时,GPU 上需要同时有 3GB 的空闲显存才能完成扩容,这会造成空间浪费,也可能直接分配失败。
添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
3.2.2 基于VMM API实现方案
VMM提供了虚拟地址与物理内存解耦的能力,我们需要在vector中记录更多的信息。下面代码中为更新后的vector结构。其中
-
chunk_sz:通过 cuMemGetAllocationGranularity 获取的最小分配粒度。
-
handles:存储物理内存句柄(由 cuMemCreate 分配)。
-
handle_sizes:记录每个句柄的分配大小。

添加图片注释,不超过 140 字(可选)
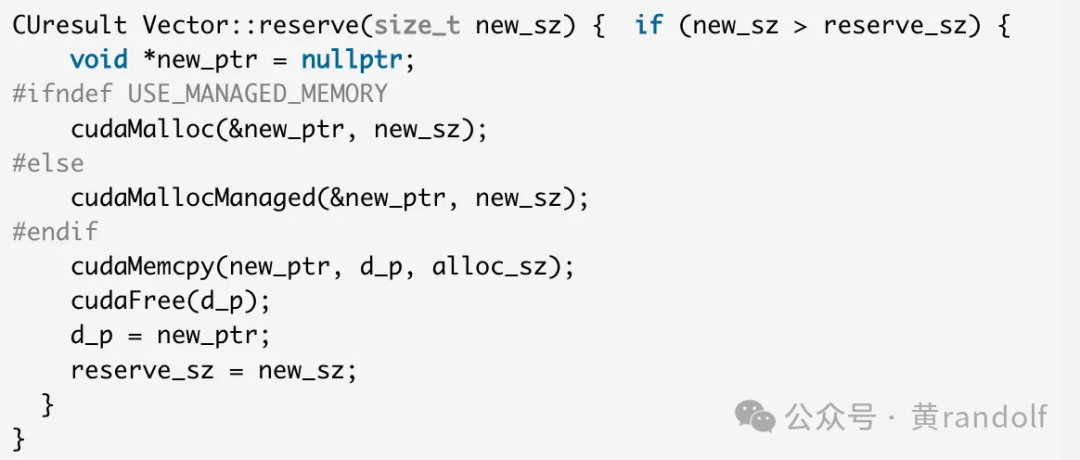
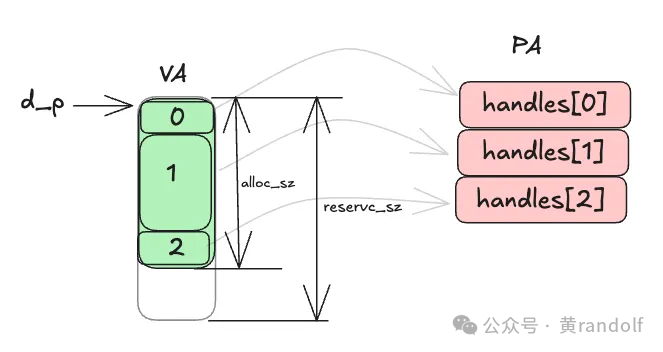
下图展示了VMM vector各个变量的之间的关系。d_p是一段连续的虚拟地址(VA),但它印社的物理内存(PA)可以不连续。例如VA块0→ handles[0],VA块1→handle[1]…
添加图片注释,不超过 140 字(可选)
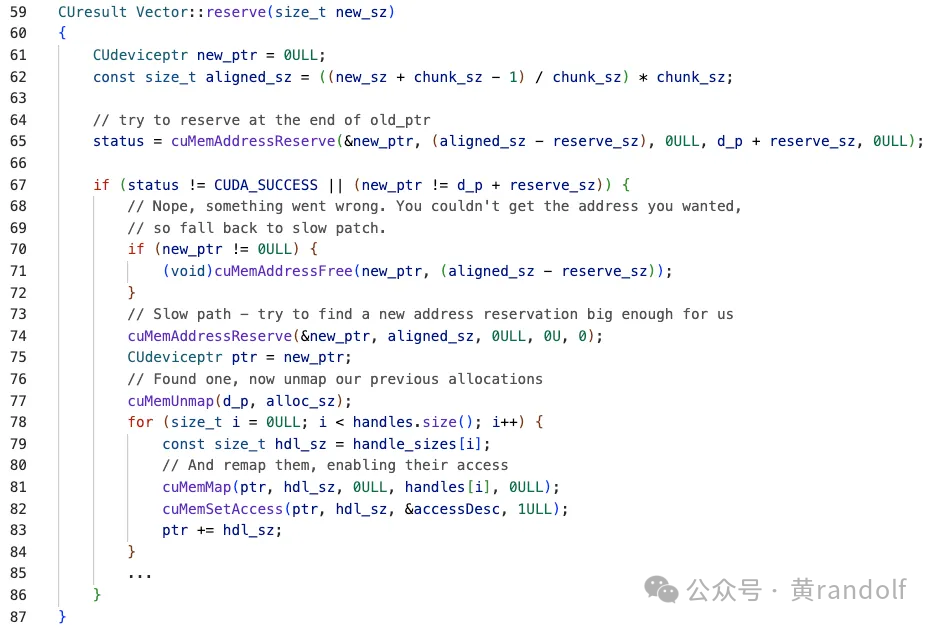
在VMM版的revsere函数中,如果需要的空间比剩余VA 空间大,则调用 cuMemAddressReserve 试图在 d_p + reserve_sz 之后继续保留一段连续 VA 空间。但是如果连续空间被其他应用占用,则会返回一段不连续的 VA(new_ptr ≠ d_p + reserve_sz),这个时候就需要走到slow path,重新分配一段更大的VA空间。并且重新cuMemMap 已有的物理内存到新 VA 空间。当调用到grow函数时,新的物理内存通过 cuMemCreate 分配,并映射到 VA 中剩余的空闲位置中。
添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
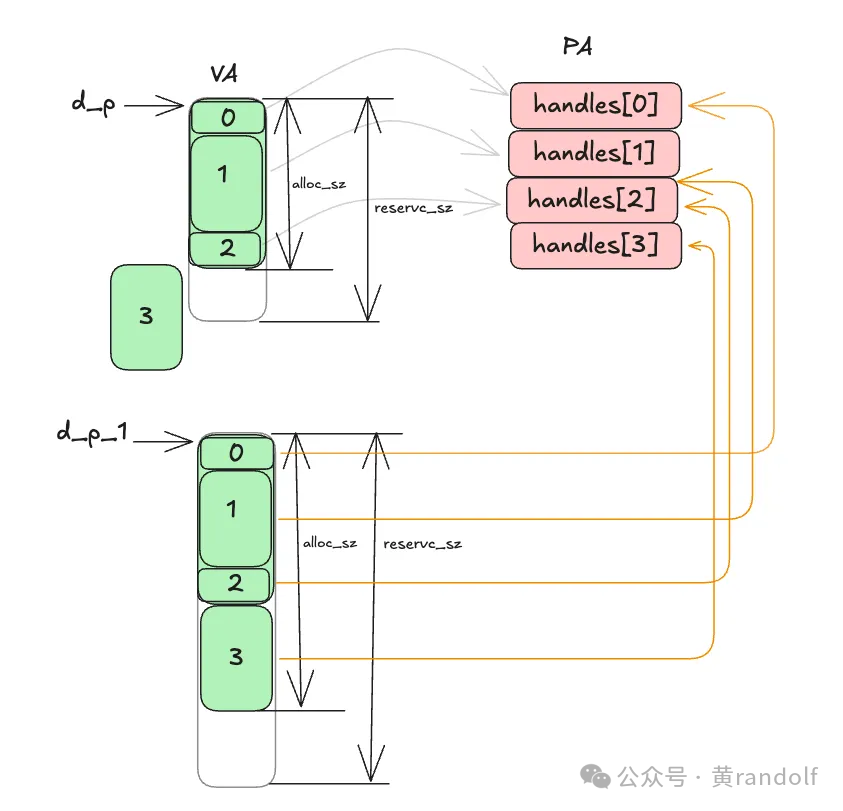
下图详细描述了VMM grow的过程。这里需要分配block3的空间,但是d_p 空间不够,重新分配了一块更大的VA空间 d_p_1,新分配的空间并没有和vector之间的物理内存建立映射关系,需要重新建立,例如 d_p_1 VA 块0→ handles[0]等。原来d_p废弃的映射也需要通过ummap函数释放,d_p reserve的VA在此之后释放。在grow函数中,分配了新的物理空间(handles[3]),将d_p_1 VA的block3映射到这块物理空间上。
添加图片注释,不超过 140 字(可选)
3.2 P2P场景下使用VMM
在传统实现中,如果两个 GPU 之间需要 Peer-to-Peer (P2P) 访问,必须显式调用cudaDeviceEnablePeerAccess API。在使用 VMM(Virtual Memory Management) 后,P2P 访问的控制更加精细化:只需调用一次 cuMemSetAccess,即可为目标内存设置特定的 peer access 权限。可以针对单个内存区域设置访问权限,而不是全局启用。支持更细粒度的安全和性能优化。
CUmemAccessDesc accessDesc = {};
accessDesc.location.type = CU_MEM_LOCATION_TYPE_DEVICE;
accessDesc.location.id = peerDevice;
accessDesc.flags = CU_MEM_ACCESS_FLAGS_PROT_READWRITE; // <-
cuMemSetAccess(ptr, size, &accessDesc, 1);
4. 实现Symmetric Memory - host端准备工作
回到第 2 节的示例,在 步骤 1 中调用的 ncclMemMalloc,本质上是通过 VMM API 分配空间并完成映射,返回 VA 地址。而在 步骤二 中调用的 ncclCommWindowRegister 则注册 src/dst buffer,该 API 是 NCCL 2.27 新增的用户接口。该接口负责完成sysmmetric memory相关注册工作。symmetric主要的机制在该函数函数中实现。
-
/* Register memory window */ncclResult_t ncclCommWindowRegister(
-
ncclComm_t comm,
-
void* buff,
-
size_t size,
-
ncclWindow_t* win,
-
int winFlags);
-
struct ncclWindow {
-
struct ncclReg* handle;
-
};
-
struct ncclReg {
-
...
-
// symmetric reg
-
void* baseSymPtr;
-
// 保存对称映射后的sym地址
-
size_t symSize; // 空间大小 int winFlags;
-
// 窗口标识为,例如 NCCL_WIN_COLL_SYMMETRIC
-
};
4.1 ncclCommWindowRegister 函数执行流程概览
-
定位输入buff对应的物理内存 调用cuMemRetainAllocationHandle,根据输入buffer的VA地址找到对应物理内存的handle(PA handle)。
-
构建注册任务 根据PA信息及size相关信息,构建ncclSymRegTask ,入comm->symRegTaskQueue任务处理队列
-
异步任务处理 异步执行ncclCommGroupRegisterSymmetric处理队列中的任务。步骤4和步骤5是本步骤的具体执行过程
-
初始化symmetric memory以及在symmetric memory上分配内部使用结构(首次调用时) 分配symmetric VA space以及在symmetric memory上分配内部管理结构struct ncclSymDevBase;调用 ncclCommSymmetricRegisterInternal,将ncclSymDevBase结构物理内存映射到所有本地 rank 的对称虚拟地址,实现跨进程共享。
-
注册内存窗口(处理队列中的任务) 处理symRegTaskQueue队列中的任务。调用ncclCommSymmetricRegisterInternal接口,将物理内存映射到所有本地 rank 的对称虚拟地址位置,实现跨进程的内存共享。
注意:异步处理依赖 NCCL 的 group 机制,可同时处理多个通信器任务。本文不展开 group 机制,后续会在独立文章中介绍。
4.2 NCCL中的Symmetric Memory 管理结构
-
struct ncclComm { ...
-
// symmetric buffer uint8_t* baseUCSymPtr;
-
// UC 对称内存基地址 uint8_t* baseMCSymPtr;
-
// MC 对称内存基地址 size_t baseStride;
-
// 每个 rank 的 VA 窗口大小 size_t symAllocHead;
-
// 对称内存分配头指针 CUmemGenericAllocationHandle symMCHandle;
-
// NVLS 多播句柄 struct ncclIntruQueue<struct ncclSymRegTask, &ncclSymRegTask::next> symRegTaskQueue;
-
...
-
};
-
baseUCSymPtr : 通过
cuMemAddressReserve分配,大小为comm->baseStride * comm->*localRanks 。
-
baseMCSymPtr:通过cuMemAddressReserve分配,大小为comm->*baseStride,用于NVLS多播。
-
baseStride:每个rank的VA窗口的大小。如果设置了 WIN_STRIDE 环境变量,直接使用;否则取所有 rank 中最大的显存大小作为窗口大小,例如96GB。
-
symAllocHead:记录当前分配位置。
-
symRegTaskQueue:symmetric memory注册任务的队列。
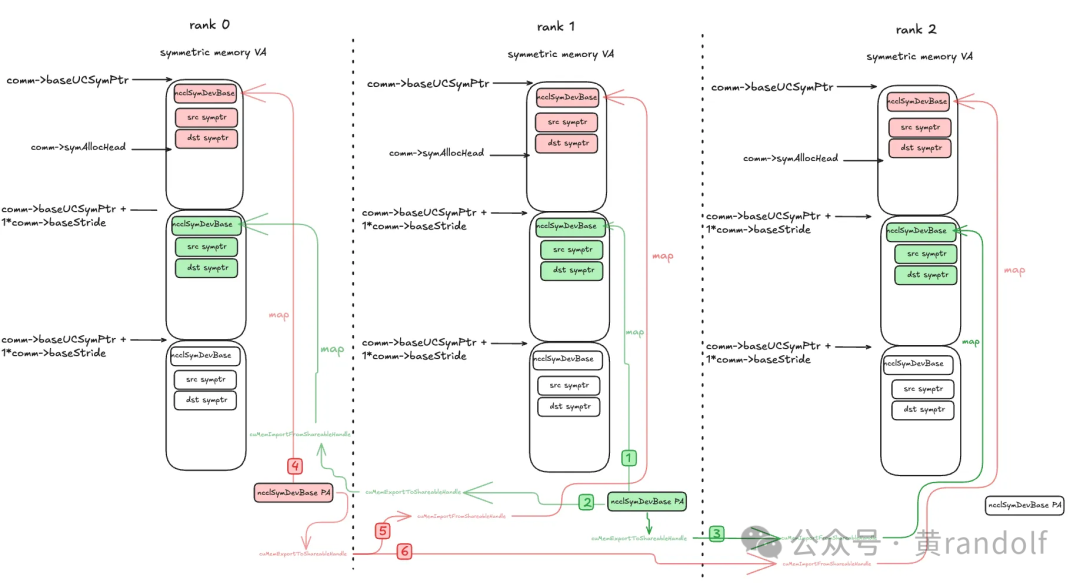
4.3 映射流程示例(3 个 rank)
以 UC 对称内存为例(MC 类似),ncclSymDevBase 是 NCCL Symmetric 内存系统的设备端核心结构,初始化时预分配。在初始化的时候,每个rank reserve的 VA空间大小是一样的。默认VA空间大小为comm->baseStride * comm->*localRanks。comm→symAllocHead初值为0。
步骤:
1. 分配物理内存:每个 rank 调用
cuMemCreate 为 ncclSymDevBase 分配物理内存。
2. 导出shared handle:多进程场景下,每个 rank 调用 cuMemExportToShareableHandle 导出 handle。
3. 交换handle:所有 rank 通过 allgather 获得全部 handle;
Rank 0: [memHandle0, memHandle1, memHandle2] Rank 1: [memHandle0, memHandle1, memHandle2] Rank 2: [memHandle0, memHandle1, memHandle2]
4. 导入shared handle → impHandle:每个 rank 调用
cuMemImportFromShareableHandle 导入其他 rank 的 handle。
5. 映射到本地symmetric memory VA空间:每个impHandle被映射到
baseUCSymPtr + targetRank * baseStride + offset
ncclSymDevBase 结构,这里offset=0 。例如,对于rank 1上分配的 ncclSymDevBase 结构,映射到rank 0的comm->baseUCSymPtr + 1 * comm->baseStride 位置;映射到rank 1的comm->baseUCSymPtr + 1 * comm->baseStride ;映射到rank2相同偏移位置。VA和PA绑定后,每个 rank 都能访问其他 rank 的物理空间。
6. 更新
comm→symAllocHead 指针
添加图片注释,不超过 140 字(可选)
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
B站:UID:3546863642871878
参考文献链接
人工智能芯片与自动驾驶

 浙公网安备 33010602011771号
浙公网安备 33010602011771号