
一文搞懂多模态大模型:视觉-语言模型(VLM)
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
B站1:UID:3546863642871878
B站2:UID: 3546955410049087
人类通过眼睛看世界,通过语言描述世界。当我们看到一朵盛开的玫瑰,大脑会自动将视觉信息转换为"红色"、"花朵"、"美丽"等语言概念。反过来,当听到"夕阳西下"这个词汇时,脑海中会浮现出温暖的橙色天空画面。 视觉与语言在人类认知中是天然融合的,而让机器也具备这种跨模态理解能力,正是视觉-语言模型(VLM)要解决的核心问题。
添加图片注释,不超过 140 字(可选)
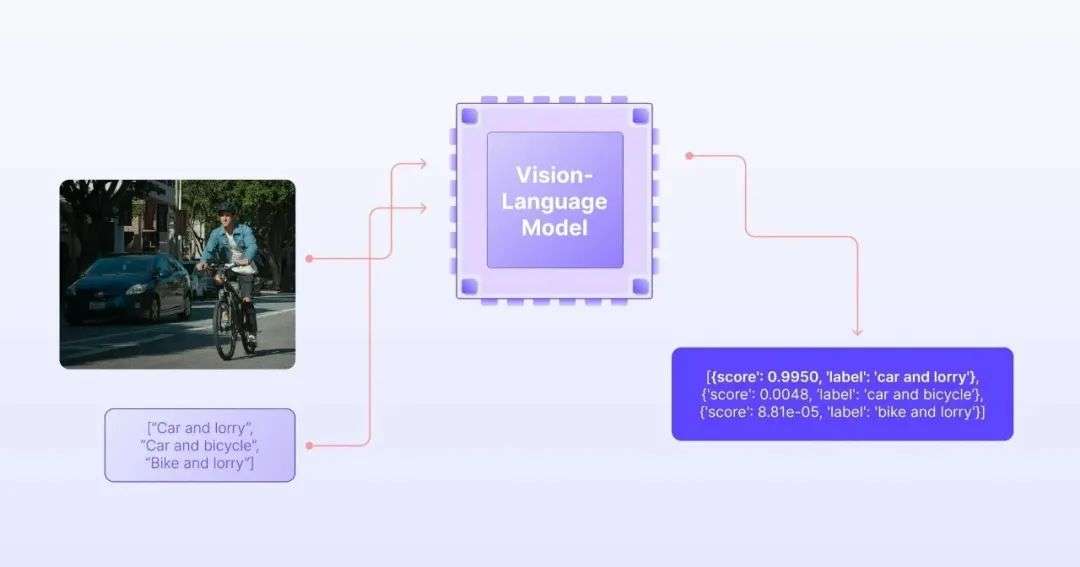
核心挑战:视觉像素与语言符号的鸿沟计算机视觉模型(Computer Vision,CV)只会 "看" 不会 "说" ——它能识别图像中有一只猫,但无法用自然语言描述这只猫的特征;而自然语言处理模型(Natural Language Processing,NLP)只会"说"不会"看"——它理解"猫"这个词的含义,但不知道真实的猫长什么样。传统AI的局限性在于模态割裂,这种割裂导致了一个严重问题:机器无法建立视觉内容与语言描述之间的语义对应关系。

添加图片注释,不超过 140 字(可选)
多模态视觉-语言模型(Vision-Language Model, VLM)则是一种能够同时理解图像(或视频)与文本,并建立两者的关联关系。它突破了传统单一模态(纯文本或纯视觉)模型的局限,实现跨模态的联合推理、生成与分析能力。
添加图片注释,不超过 140 字(可选)
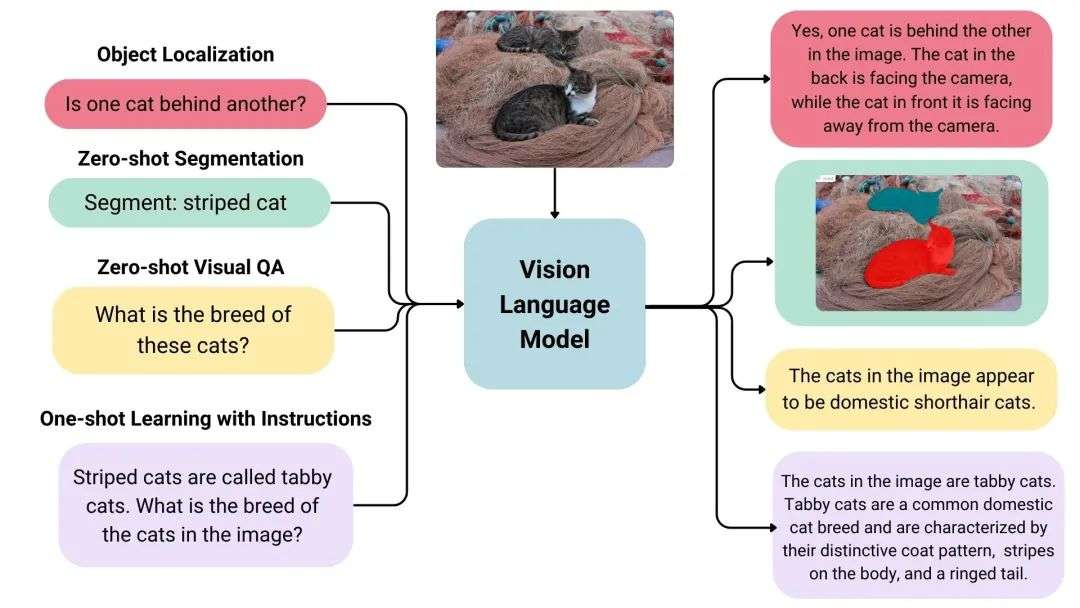
VLM面临的挑战:如何让机器建立起视觉感知与语言理解之间的桥梁?(1)视觉世界:连续的像素宇宙视觉信息是连续、稠密、高维的。一张224×224的RGB图像包含150,528个连续数值,每个像素的RGB值都在0-255之间连续变化。更重要的是,视觉信息具有强烈的空间结构性——相邻像素往往在语义上高度相关,一个物体的轮廓由连续的边缘像素构成,颜色渐变形成了纹理和光影效果。 # 视觉信息的连续性示例import torchimage = torch.randn(3, 224, 224) # RGB图像print(f"图像数据点数量: {image.numel()}") # 150,528个连续值# 相邻像素的语义相关性center_pixel = image[:, 112, 112] # 中心像素neighbor_pixel = image[:, 112, 113] # 相邻像素# 在自然图像中,相邻像素的值通常非常接近
# 视觉信息的连续性示例(2)语言世界:离散的符号空间 语言信息则是离散、稀疏、低维的。文字被分解为有限词汇表中的token序列,每个token对应一个整数ID。与视觉不同,语言具有严格的序列结构性——词汇的顺序直接决定语义,"狗咬人"和"人咬狗"是完全不同的意思。 # 语言信息的离散性示例text = "一只黑色的野狗在马路上咬人"tokens = ["一只", "黑色", "的", "野狗", "在", "马路上", "咬人"]token_ids = [152, 1876, 34, 2741, 78, 3821, 1434] # 离散的整数序列# 词汇顺序的重要性original = "野狗在咬人" # 清晰的语义shuffled = "人在咬野狗" # 语义完全混乱
# 语言信息的离散性示例VLM解决的方法:生成式统一架构 + 万物皆可Token化通过建立统一的多模态表示空间,将不同模态的信息转换为统一的token表示,然后在同一个架构中进行联合建模和推理。既然大语言模型擅长处理token序列,那么就把所有模态的信息都转换成token。
-
视觉token:将图像切分为固定大小的patches(如16×16像素块),每个patch编码为一个视觉token
-
语言token:保持传统的subword tokenization,每个词汇对应一个语言token
-
统一建模:将视觉token和语言token拼接成统一序列,用同一个Transformer架构处理
这种设计让模型能够在token级别建立跨模态的注意力连接,实现真正的视觉-语言理解。 # VLM的统一token化示例defvlm_tokenization(image, text):# 视觉token化:224×224图像 → 196个视觉token vision_patches = divide_image_to_patches(image, patch_size=16) # [196, 256] vision_tokens = embed_patches(vision_patches) # [196, 768]# 语言token化:文本 → N个语言token text_tokens = tokenize_text(text) # [seq_len, 768]# 统一序列:[CLS] + 视觉token + [SEP] + 语言token unified_sequence = concat([ cls_token, # [1, 768] vision_tokens, # [196, 768] sep_token, # [1, 768] text_tokens # [seq_len, 768] ])return unified_sequence # [198+seq_len, 768]
# VLM的统一token化示例架构设计:视觉-语言模型的技术路线经过多年发展,VLM已进入第三代:生成式统一架构。这一阶段的代表性模型包括GPT-4V、LLaVA、Qwen2.5-VL等,它们不仅能理解视觉内容,更能基于视觉输入生成自然语言响应,实现真正的视觉-语言对话。
添加图片注释,不超过 140 字(可选)
(1)GPT-4V:统一架构的技术突破 GPT-4V的核心创新在于彻底打破了模态边界,实现了真正的统一多模态架构。不同于传统的"视觉编码器+语言解码器"拼接方式,GPT-4V将视觉和语言信息在同一个Transformer中进行统一处理。

添加图片注释,不超过 140 字(可选)
核心技术特点:
-
自适应视觉Token:支持任意分辨率和宽高比的图像输入,动态生成合适数量的视觉token
-
统一注意力机制:文本token和视觉token在同一注意力矩阵中交互,实现深度跨模态理解
-
多粒度视觉表示:同时捕捉像素级细节和语义级概念,支持从OCR到场景理解的多层次任务
这种设计让GPT-4V能够根据问题动态关注图像的不同区域,实现真正的"目标导向观察"。例如GPT-4V + TTS能够实现实时的体育赛事解说,通过逐帧分析足球比赛视频,动态识别球员位置、战术变化和关键时刻,生成专业的解说词并转换为自然语音输出,为观众提供沉浸式的观赛体验。
添加图片注释,不超过 140 字(可选)
(2)LLaVA:模块化设计的工程智慧 LLaVA采用了经典的三段式架构:Vision Tower(视觉编码器)+ Vision Projector(视觉投影层)+ LLM Decoder(语言模型解码器)。这种设计的核心价值在于充分利用预训练模型的能力,用最小的训练成本实现强大的多模态能力。

添加图片注释,不超过 140 字(可选)
核心技术特点:
-
分阶段训练策略:第一阶段冻结视觉编码器和语言模型,只训练投影层;第二阶段冻结视觉编码器,微调投影层和语言模型
-
两阶段训练策略:先进行特征对齐预训练,再进行指令微调
-
高效参数利用:新增参数量不到总参数的5%,却能实现完整的视觉对话能力
LLaVA的成功证明了"组合创新"的价值——通过巧妙的工程设计,将成熟组件组合出新的能力。

添加图片注释,不超过 140 字(可选)
(3)Qwen2.5-VL:本土化与推理能力强化Qwen2.5-VL在继承主流技术框架的基础上,针对中文场景和推理任务进行了深度优化。其技术创新主要体现在视觉处理和推理链路两个方面。
添加图片注释,不超过 140 字(可选)
核心技术特点:
-
动态分辨率处理:支持256×256到1280×1280的任意分辨率,采用分块策略处理超高分辨率图像
-
增强推理架构:引入多步推理机制,支持 "观察→分析→推理→结论" 的完整思维链路
-
中文视觉优化:专门优化了对中文文字、标志、文档的理解能力
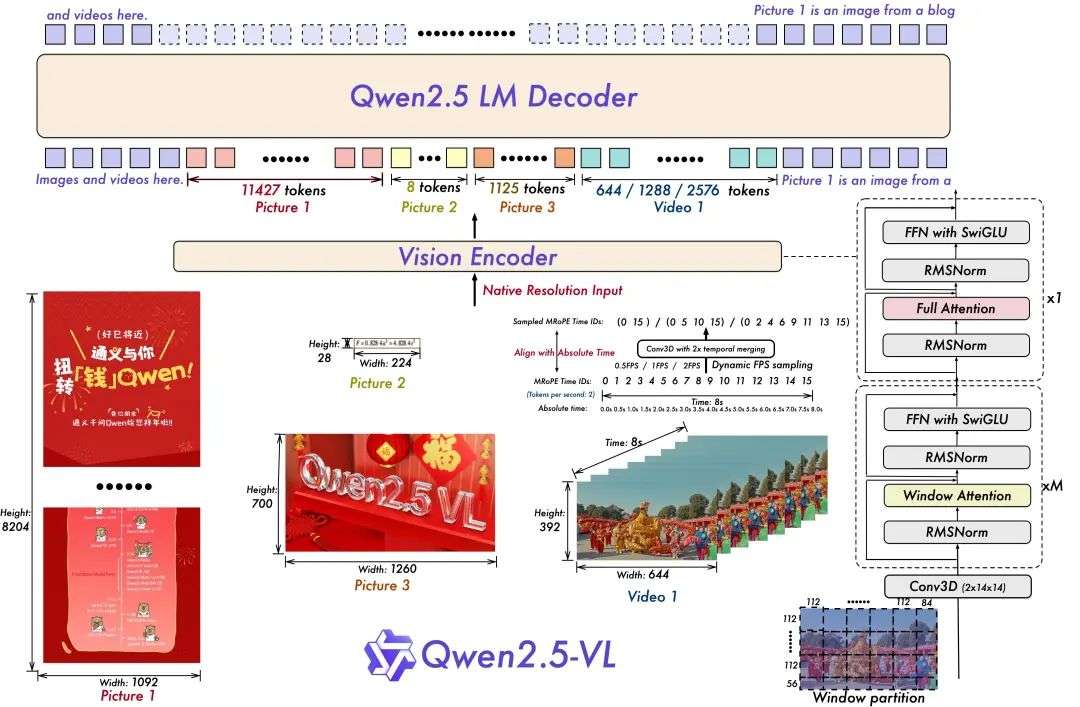
多步推理能力是Qwen2.5-VL的突出特点。模型能够先描述图像内容,再分析关键信息,最后得出推理结论,整个过程逻辑清晰、步骤完整。如图所示:视觉特征输出后,传递到“Qwen2.5 LM Decoder”(基于通义千问语言模型的解码器),完成多模态推理(如图像描述、事件问答)。图中显示了完整的处理流程:视觉编码器提取特征 → 语言模型解码 → 生成文本输出(如结构化数据、时间点定位等)。
添加图片注释,不超过 140 字(可选)
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
B站1:UID:3546863642871878
B站2:UID: 3546955410049087
参考文献链接
人工智能芯片与自动驾驶

 浙公网安备 33010602011771号
浙公网安备 33010602011771号