
异构计算: 谈谈AI的软硬件交付界面, GPGPU or DSA
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
TL;DR
前几天因为盘古的一个事情, 然后又牵扯到某个国产卡NPU难用的问题, 最后逐渐变成了下一代又要走GPGPU的架构. 然后这几天还有一篇文章[1]说苹果也要兼容CUDA放弃其MLX框架. 然后老黄这两天也回应了关于国产卡兼容CUDA生态的问题, 老黄真是语言学大师, 说的挺开放的对兼容CUDA生态好像也没有什么意见, 但是CUDA一些新的版本似乎又开始有很多限制了...
我觉得实质性的问题正如本文标题所讲的: 我们需要构建一个“同构视角下的异构计算”的问题. 不管是NV的路还是H司的路, 两条路本质上是殊途同归的. 可能8年前挑战H厂为什么不去兼容CUDA是对的, 而如今再要说走回GPGPU架构反而有点牵强...
本文目录如下:
1. NV SIMT的演进 2. Ascend的视角 3. 一些分析 4. 谈谈生态和习惯的重要性 5. 再来谈谈DPU和网络处理器 6. 同构视角下的异构计算
讨论这个问题, 我们要从两方的叙事来展开, 先介绍一下两方的陈述.
第一章,我们来看看Nvidia过去三十年的演进, 以及当前NV自己也越来越DSA化, 例如到Blackwell这一代的时候, 同样的芯片面积下SM的数量少了很多, TensorCore和TMEM占用了更大的Die面积. 另外他们前段时间还有一篇论文《Task-Based Tensor Computations on Modern GPUs》也在讨论越来越DSA化后的编程范式和软件抽象.
第二章, 我们来看另一方的观点, 特别是最近看到一个廖恒博士在2021年的演讲《An Outlook for New Homogeneous Computing System》[2], 从构成一个计算机系统的4大支柱: 处理器/内存/互连/软件 四个维度的解析. 而过了4年后正好UB落地才构成一个完整的系统, 当然也伴随着软件有一次重构.
廖博这个Session讲的很好, 特别是标题上的Homogeneous(同构)一词, 其实这个Session的时间和我在思科做NetDAM的时间是相同的, 观点也是基本一致的..
然后第三章, 第四章做一些分析, 然后从生态的视角来谈谈
第五章再来谈谈另一颗DSA,我会补充一些在Network Processor上的一些演进经验
最后再来总结如何在同构视角下构建这样的异构并行计算.
1. NV SIMT的演进
首先我们来回顾一下Nvdia过去30年的发展, 以前写过一个很长的专题来介绍Nvidia GPU架构的演进
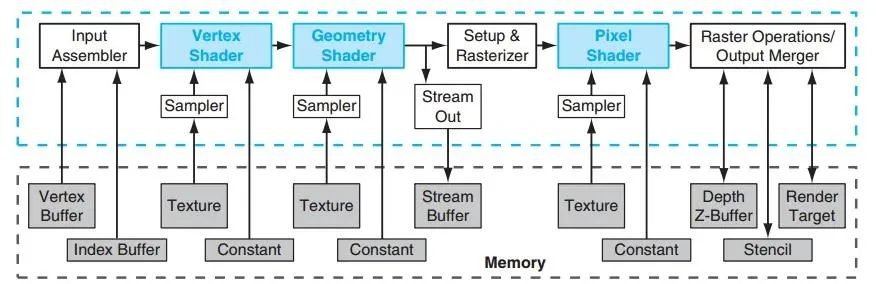
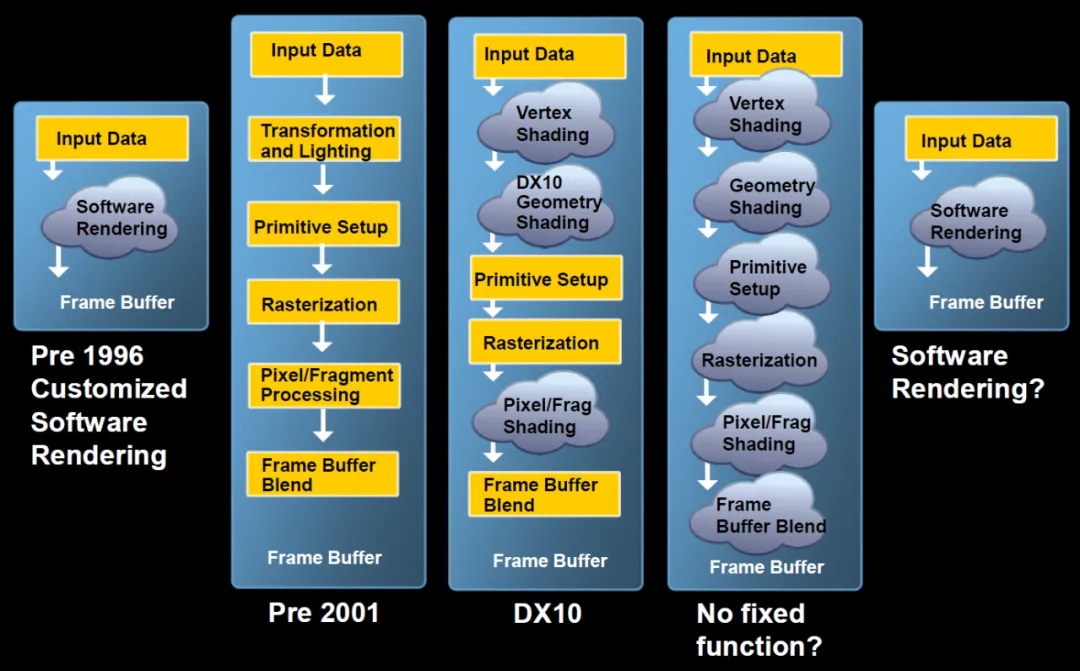
大概几十篇文章, 这里做个简略的介绍. 早期的GPU图形渲染有非常固定的流水线, 从Vertex Shader,到Geometry Shader,再到Pixel Shader, 从一开始它就是一个很确定性的DSA架构. 固定的流水线, 密集的内存访问.
添加图片注释,不超过 140 字(可选)
针对密集型的内存访问从CPU System Memory中逐渐Offload出来, 低价的EDO内存也成就了3Dfx.. 然后紧接着Nvidia把Geometry Stage Offload构建了T&L(Transform & Lightning) Engine.再到后来几年时间构成了完整的Vertex Shader和Pixel Shader的抽象, 软件上Directx和OpenGL也逐渐有了一些标准的接口, 例如GLSL/HLSL, 其实那个年代Nvidia就开始做一些C for graph(Cg)的东西...其实早期的Shader在OpenGL下编程和现在一些国产NPU也差不多的难用...
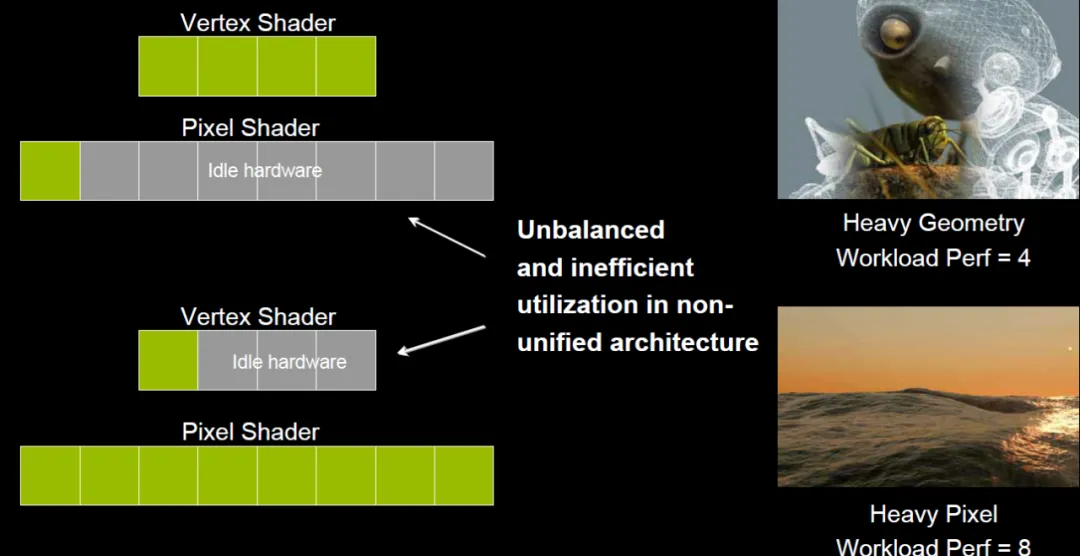
后来是随着不同渲染场景下Pixel Shader和Vertex Shader负载不均衡, 然后逐渐产生了统一Shader的想法
添加图片注释,不超过 140 字(可选)
特别是在DX10时期, Vertex Shader/Geometry Shader和Pixel Shader都可以编程的时候, 是否有一个统一的软件驱动的Rendering处理器呢?
添加图片注释,不超过 140 字(可选)
Stanford的Kayvon有一个关于< From Shader Code to a Teraflop: How Shader Cores Work >的talk讲的非常精彩。他通过3个Idea描述了心目中的最佳GPU. 砍掉通用处理器中的乱序执行/分支预测/预取/缓存等使得单个Die可以放下更多的处理器. 然后就是一些向量SIMD的执行, 最后对于访问内存的延迟通过Context切换来隐藏...这就是GPGPU的雏形. Nvidia恰好把这三颗龙珠凑齐, 并且采用SIMT的抽象, 而很遗憾的是这个时候的ATI在被AMD收购时选择了VLIW...
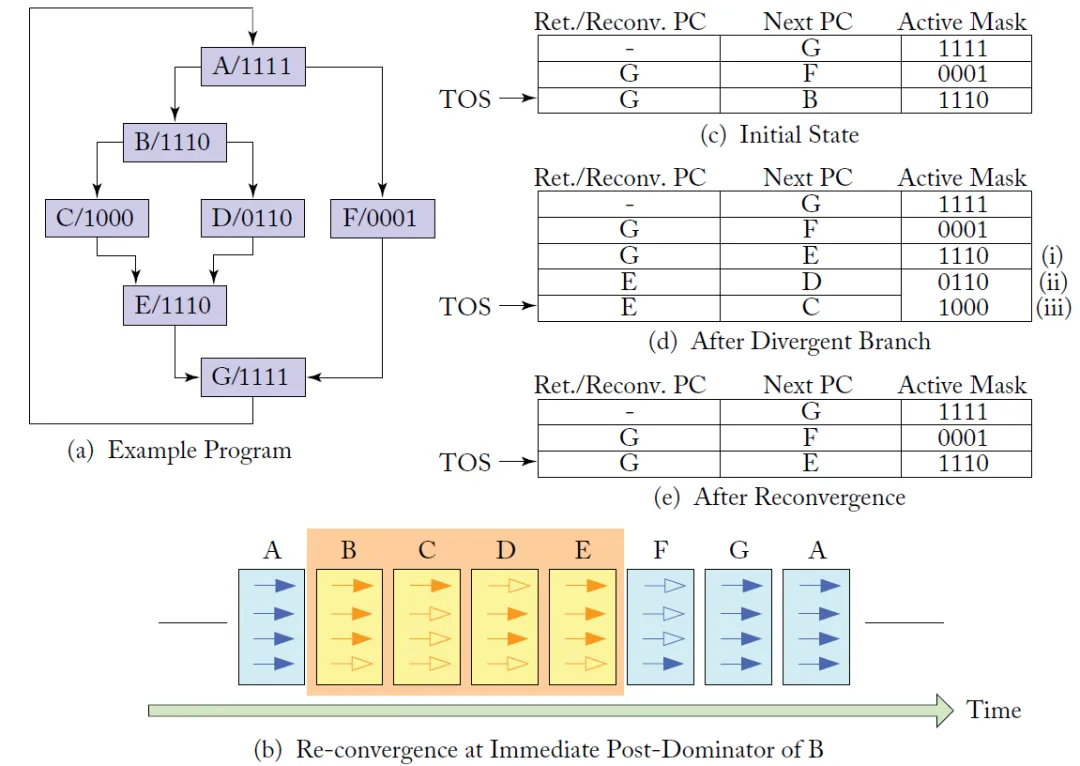
SIMT的抽象使得指令执行时相对于SIMD更灵活
添加图片注释,不超过 140 字(可选)
例如程序运行到A时, 进行判断, 有1个需要跳转到F, 另外三个线程继续走B, 因此系统就会在这个分支时, 将NextPC(B或者F)以及它们最终会汇聚的PC(Reconvergence PC) G的地址加入到表中, 并且每个线程根据自己的分支谓词更新相应的Active Mask, 下一轮调度的时候, GPU采用深度优先的方式并根据Active Mask在前三个thread上执行B, 并产生分支C、D, 然后将CD分支情况压入栈, 并执行, 直到最后汇总到RPC都是G且E后到G无指令时, 执行F, 完成线程执行的汇聚, 接下来继续并行执行.
但是基于这样的SIMT架构也有一些问题, 例如Atomic导致的SIMT死锁问题, ActiveMask的开发其实非常的痛苦
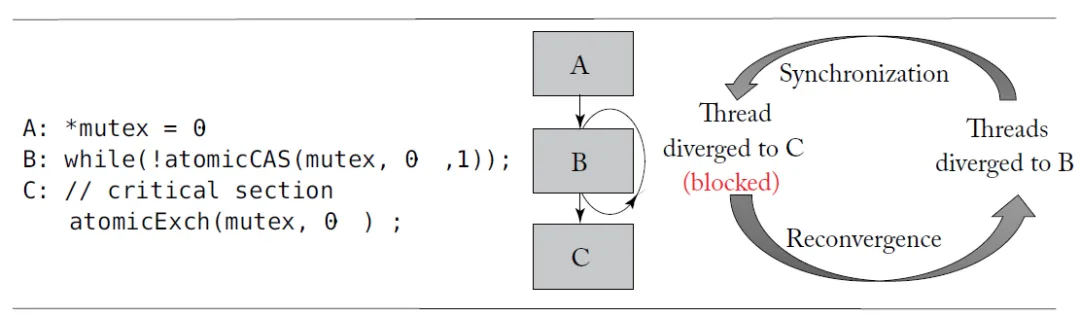
添加图片注释,不超过 140 字(可选)
直到Volta这一代, 有了独立的PC, 并引入了Cooperative Group的概念, 可能才算是一个比较完整的SIMT的架构. 而伴随着AI上和Google TPU的竞争, NV也在这个时候开始了DSA的道路, 引入了TensorCore.. 而另一方面在图形上, 伴随着光追的一些突破在Turing这一代也可以支持基于硬件的实时光追渲染... 整个GPU逐渐的开始了DSA的道路...特别的来看, 在Blackwell这一代同样的DieSize下SM数量相对于Hopper少了很多..
当然针对架构逐渐的又开始DSA化, Nvidia在CUDA生态上做出了很多易用性相关的开发, 例如CUTLASS, 以及最近的CuteDSL等... Cutlass自身的Cute Layout代数和Epilogue的抽象实际上是很不错的
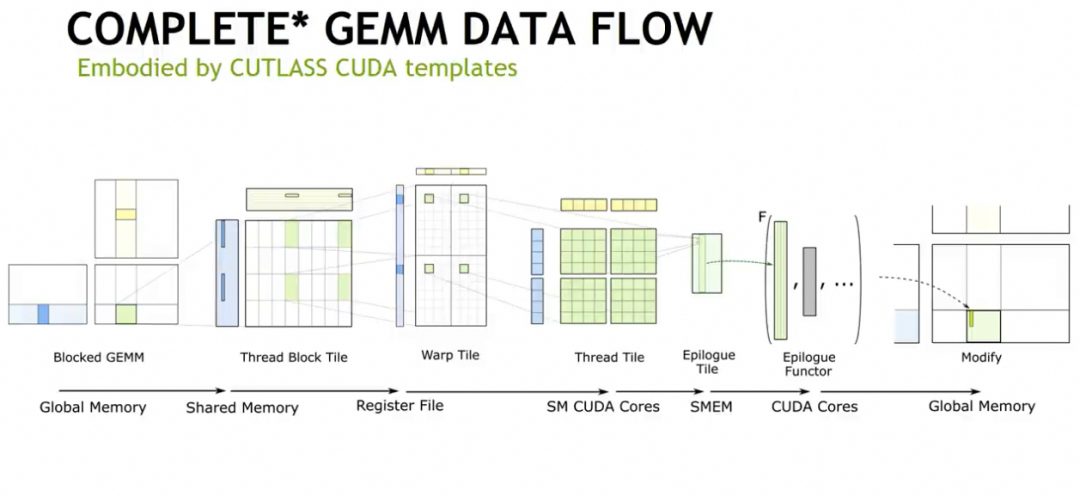
添加图片注释,不超过 140 字(可选)
从算子哥软件开发的角度可以看看下面这个专题
未来针对芯片越来越DSA化, Nvidia也在做一些准备, 例如Task-Based Tensor Computation抽象.
总体来看, 过去的30年,其实它是一个非常明显的牧本摆动周期, 从DSA到可编程再到DSA, 都是在历史上针对硬件PPA和软件workload上的一系列tradeoff. 需要注意的是, 重视和尊重软件的一些习惯, 逐步的进行演进或许才是NV成功的关键, 而同一时期我们注意的AMD/ATI反反复复折腾了好久...维持软件编程模型和接口上的稳定, 并持续的迭代才是成功的一个关键因素.
2. 谈谈Ascend的视角
关于Ascend整个系统架构比较完善的阐述是廖恒博士的一个Session《An Outlook for New Homogeneous Computing System》[3]

添加图片注释,不超过 140 字(可选)
从计算机体系结构的视角来看, 主要来自于四大支柱, 处理器/内存/互连/软件
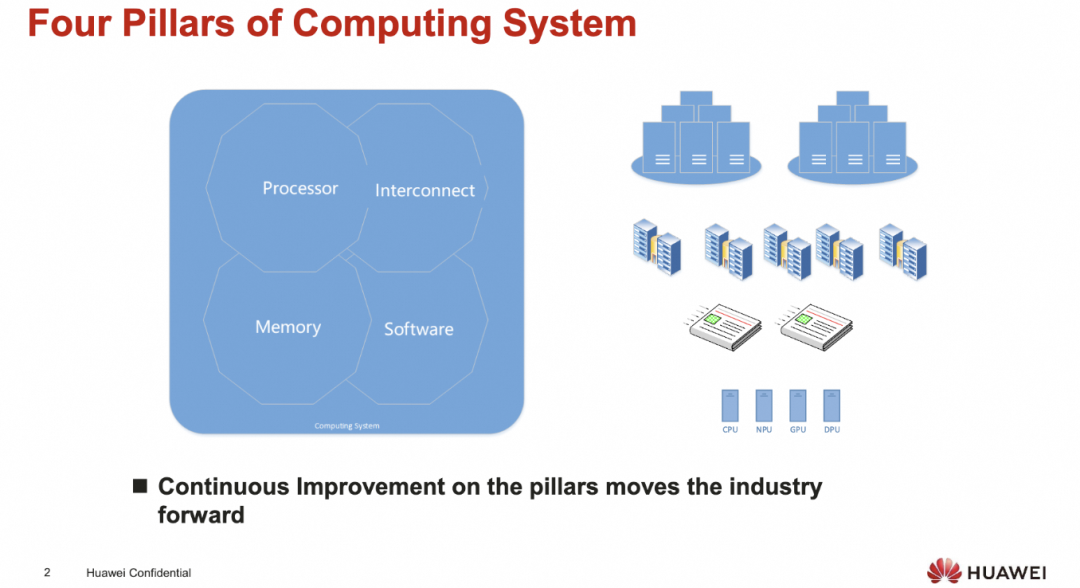
添加图片注释,不超过 140 字(可选)
从处理器和内存的角度来看, 过去20年存在了大量的DSA
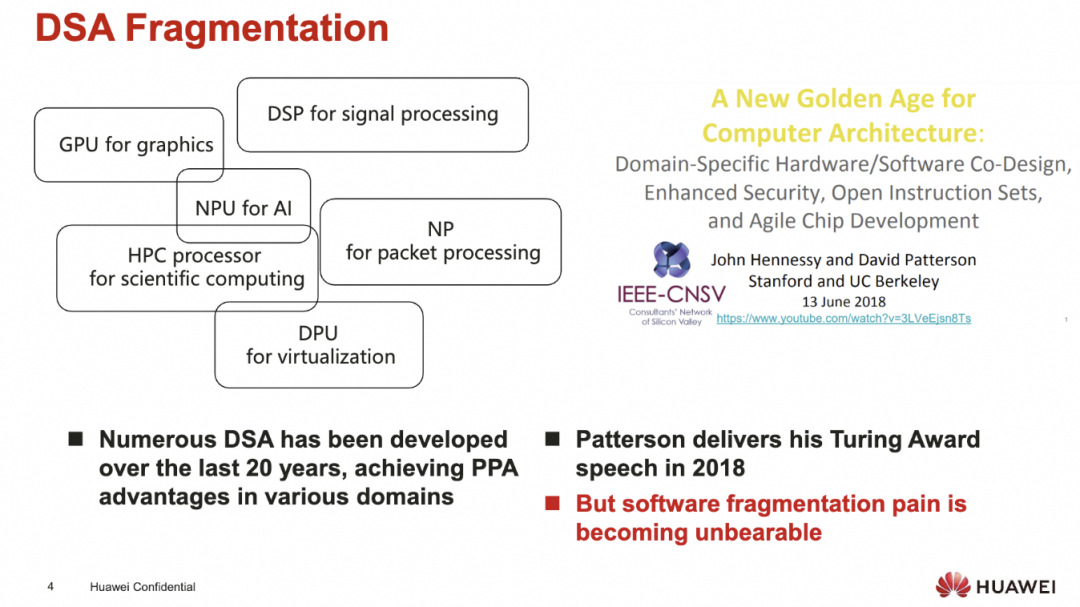
添加图片注释,不超过 140 字(可选)
而这些DSA也带来了各种支离破碎的软件生态.恰逢2019年David Patterson的演讲宣告了DSA的黄金时代到来..
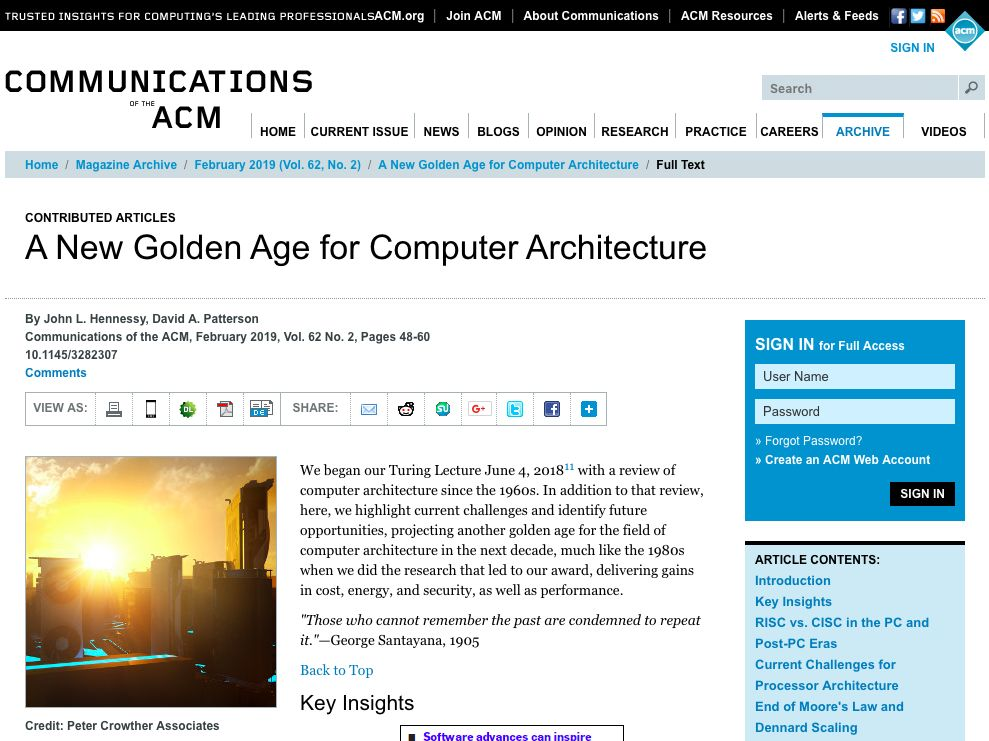
添加图片注释,不超过 140 字(可选)
廖博的观点是对于不同的处理器/DSA通常需要不同的软件架构带来的整个生态的破碎
添加图片注释,不超过 140 字(可选)
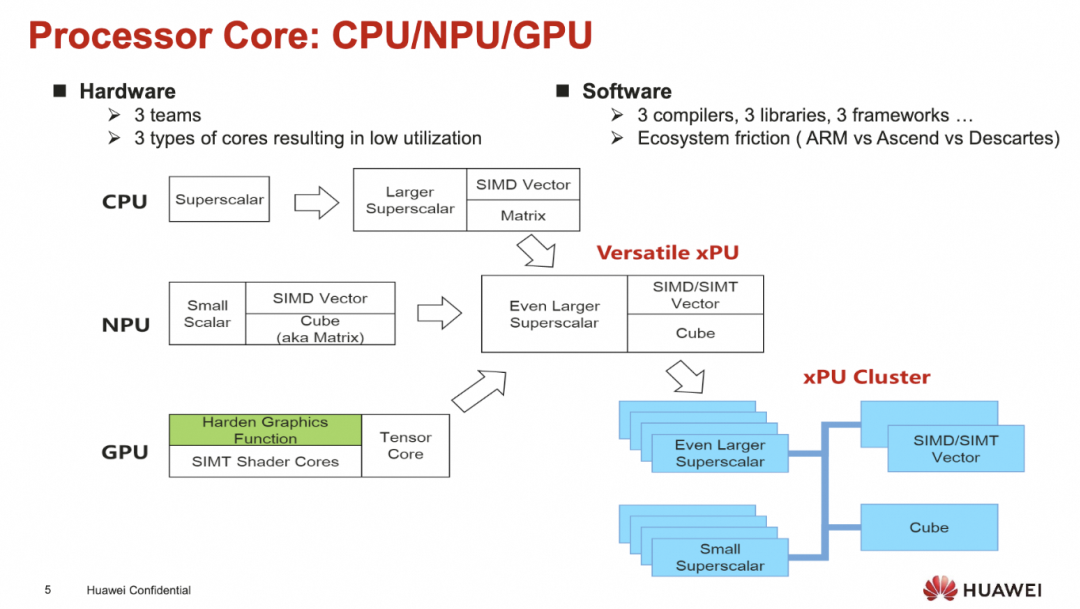
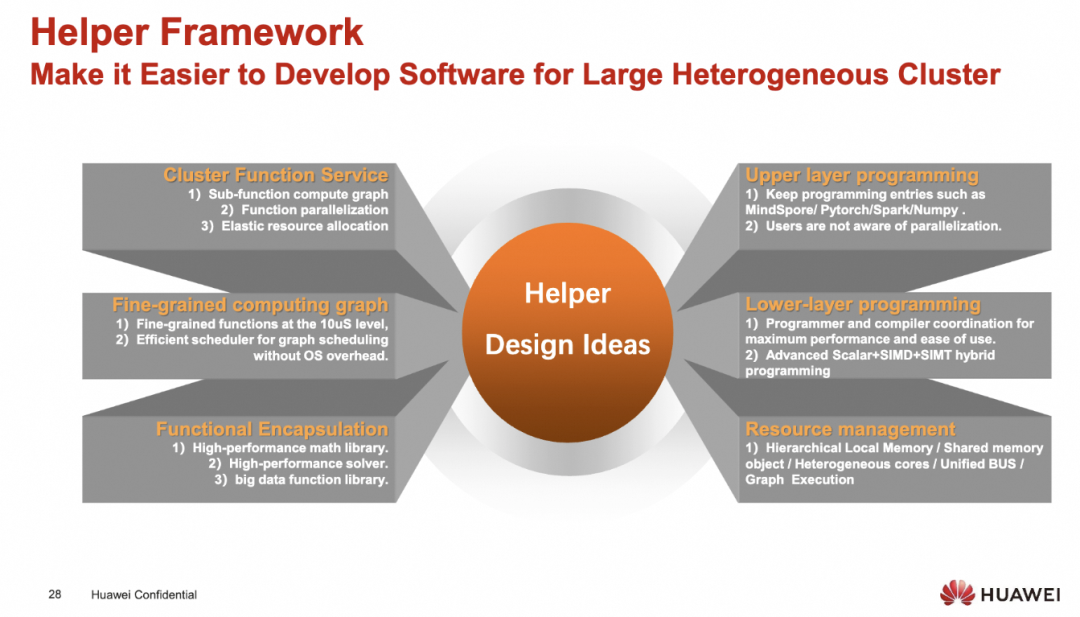
所以实质上需要一个完全同构的ISA来支持不同的CPU/GPU/NPU/DSA, 使得在编程易用性和效率上都取得优势
添加图片注释,不超过 140 字(可选)
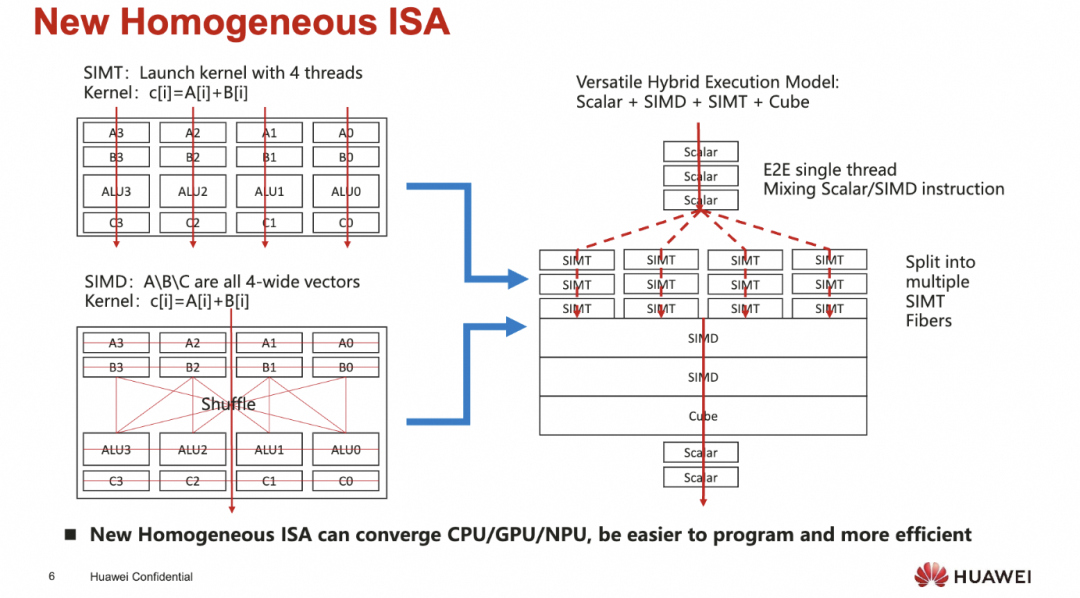
同时对于海思而言, 他们有大量的芯片定制化需求, 从服务器的鲲鹏/Ascend,到5G基站的处理器, 再到网络设备上用的NP, 以及终端的Kirin手机芯片, 因此从工程上希望有一定的Central Engineering的能力, 统一软件栈同时针对不同场景的PPA和功能特性需求构建芯片
添加图片注释,不超过 140 字(可选)
这个同构的ISA看上去是很优雅的, 既可以issue SIMD指令又可以内嵌SIMT.
当然这一个出发点从华为的视角是对的, 但工业界那么大, 通过一个架构去cover多种需求或许还有很多路要走. 另一方面从编译器的角度来获得并行性还是挺难的
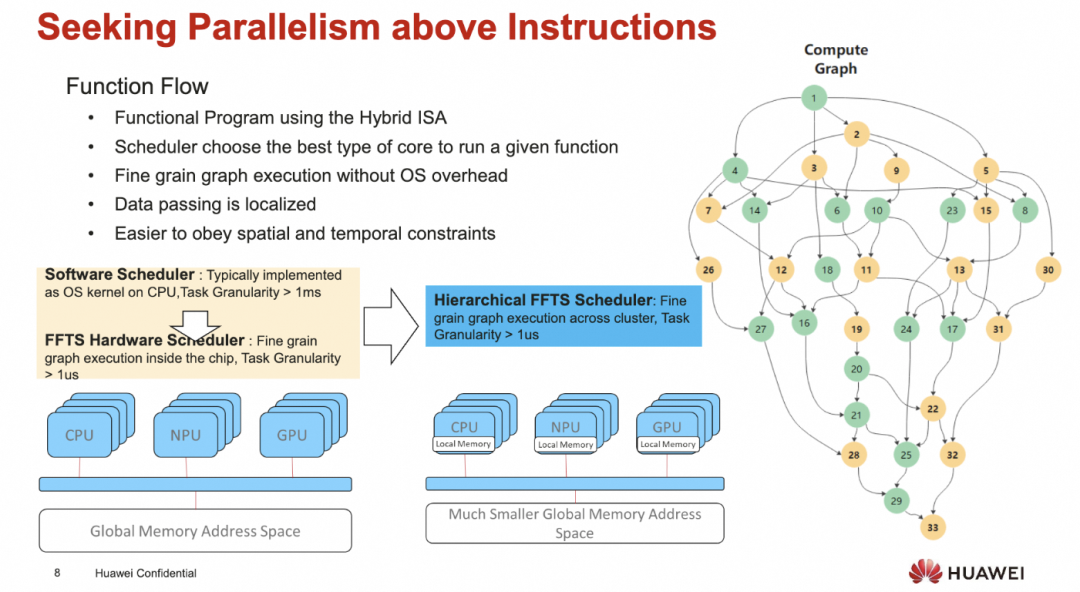
添加图片注释,不超过 140 字(可选)
另外还有一个问题就是在2DMesh架构上的调度可能也有难题
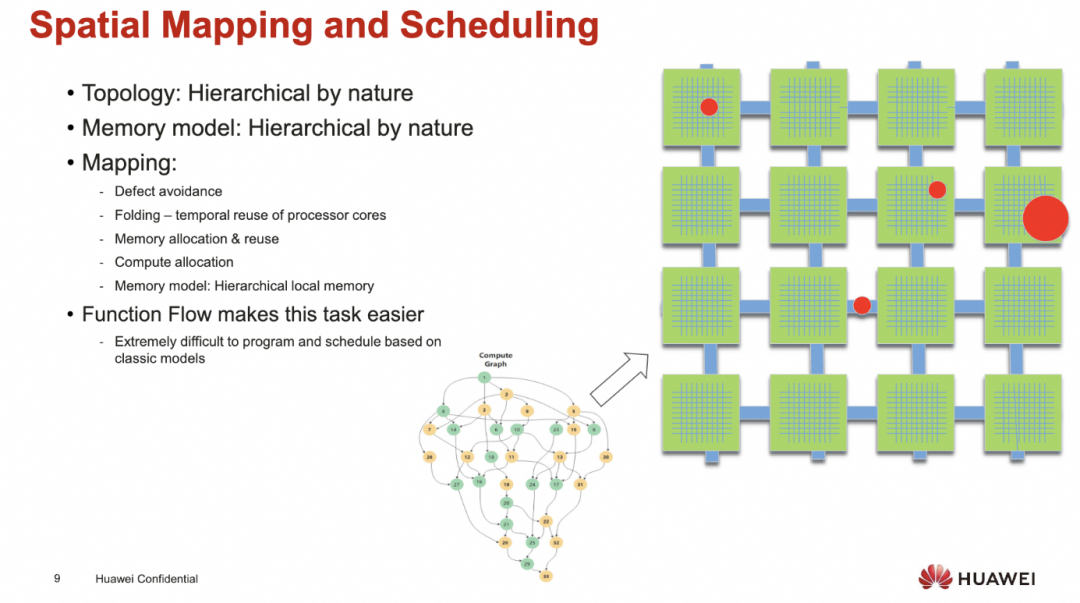
添加图片注释,不超过 140 字(可选)
其实从2019年刚发布的Ascend 910和当时TensorFlow的生态来看, 似乎静态图的做法是对的.但是谁又能够意料到最近几年的发展呢?
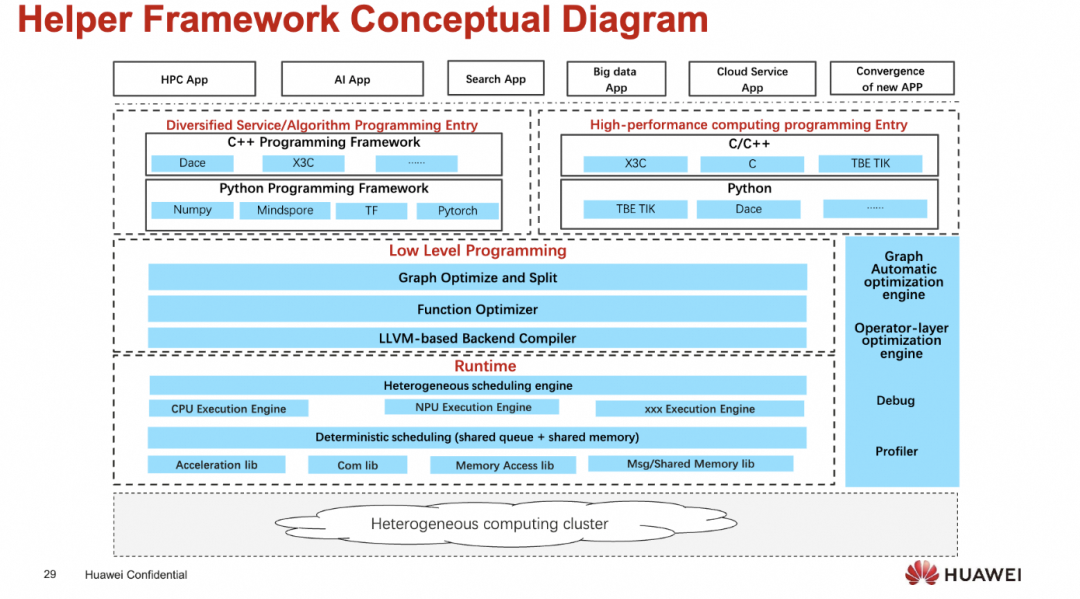
然后关于互连上, 廖博介绍了一下UB.
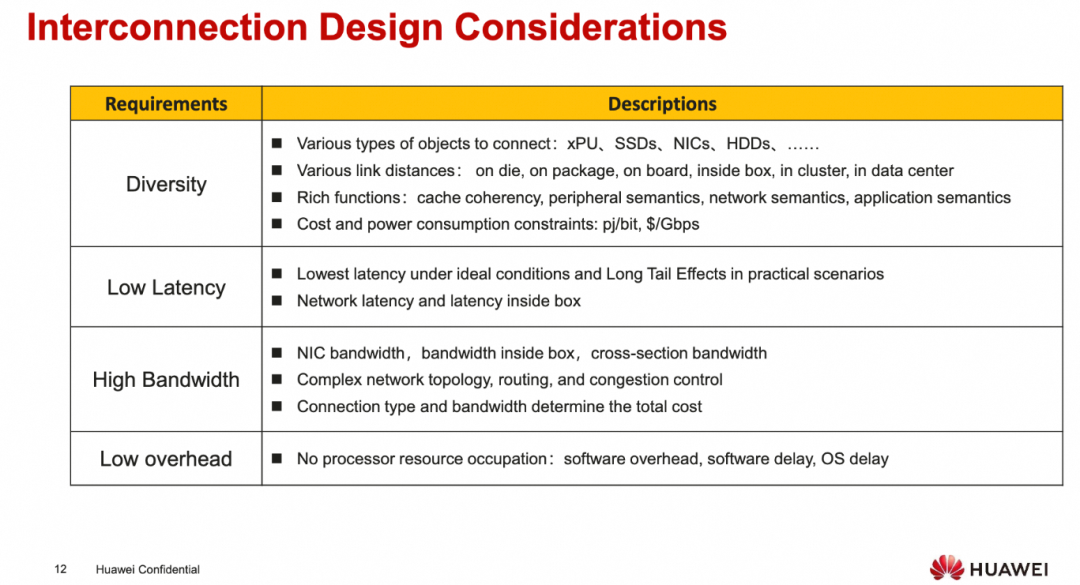
添加图片注释,不超过 140 字(可选)
很核心的一个观点就是PCIe和NIC上的小管道
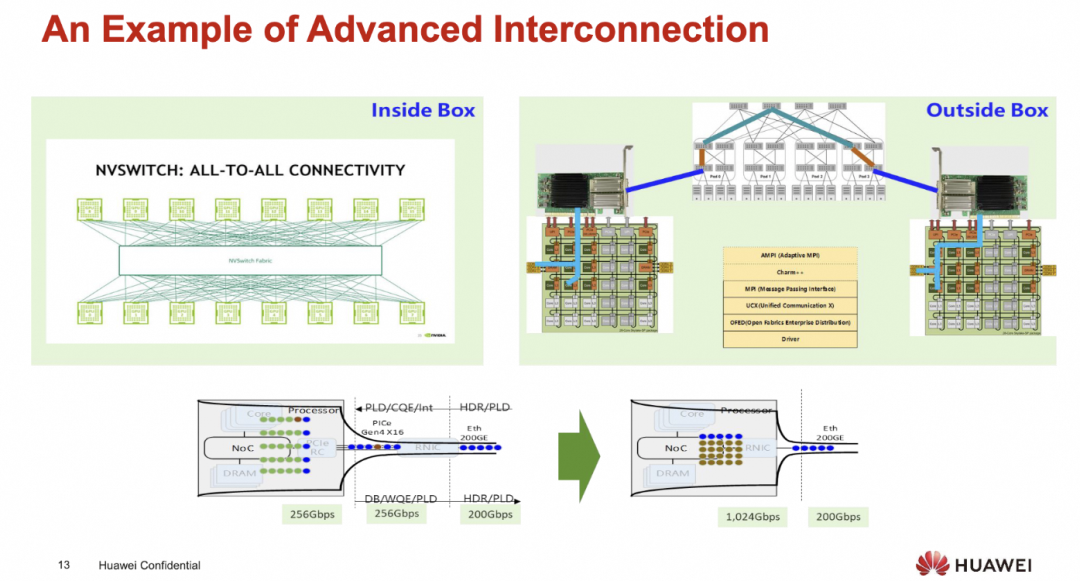
添加图片注释,不超过 140 字(可选)
这里不得不吐槽一下Intel, 在PCIe上折腾的时间太长了, 总是想自己作为Root控制一切... 然后CXL也是不停的延期, 直到现在ScaleUP群魔乱舞...
UB解决的第一个问题就是所有的处理器对等连接, 取消掉Single Master
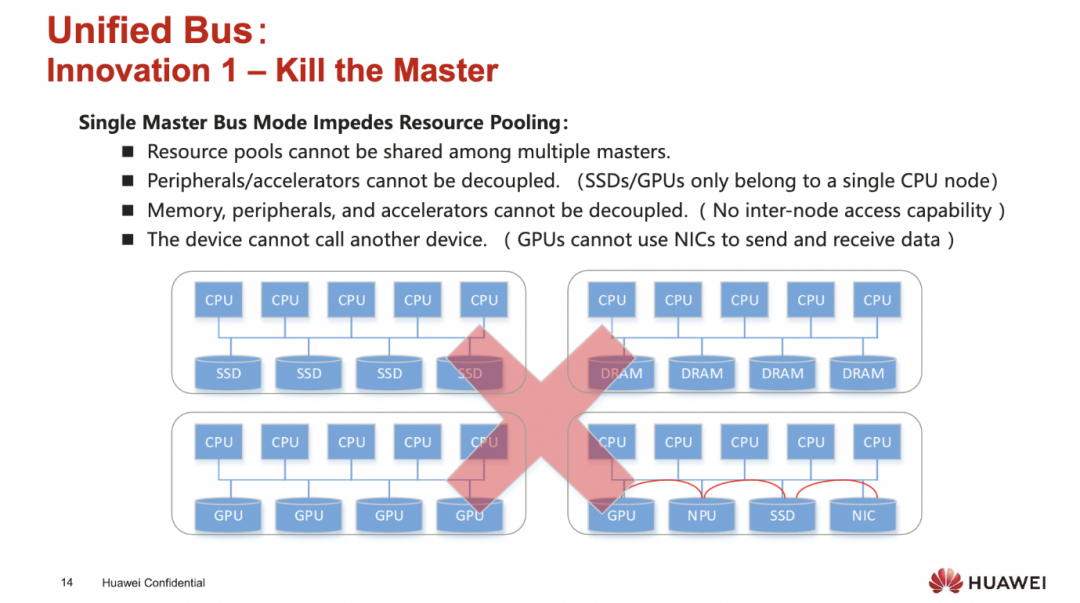
添加图片注释,不超过 140 字(可选)
然后简化掉很多复杂的软件协议栈
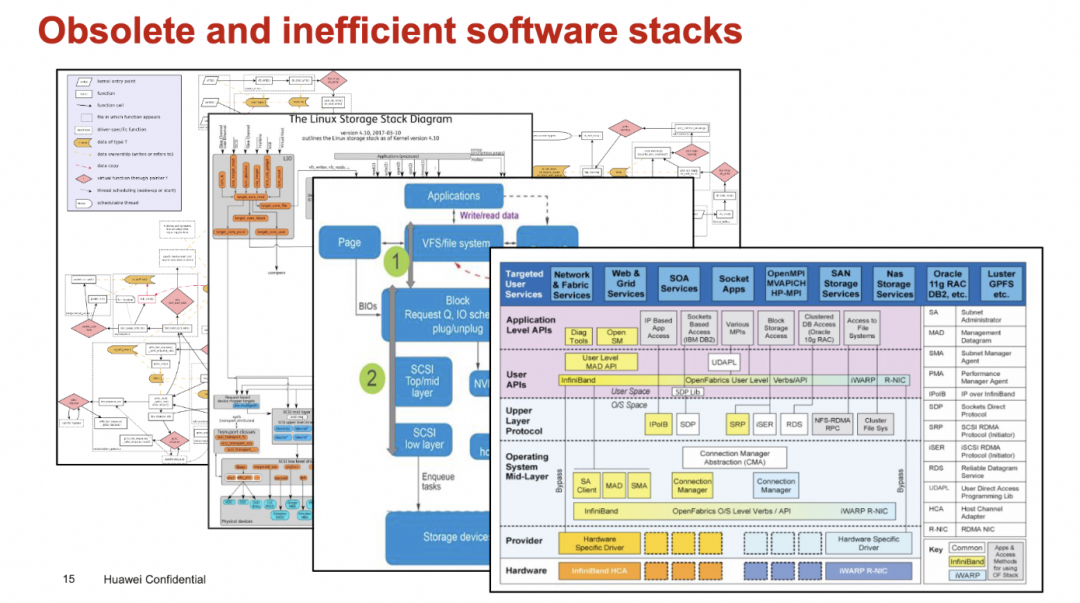
添加图片注释,不超过 140 字(可选)
创建一个新的统一的语义
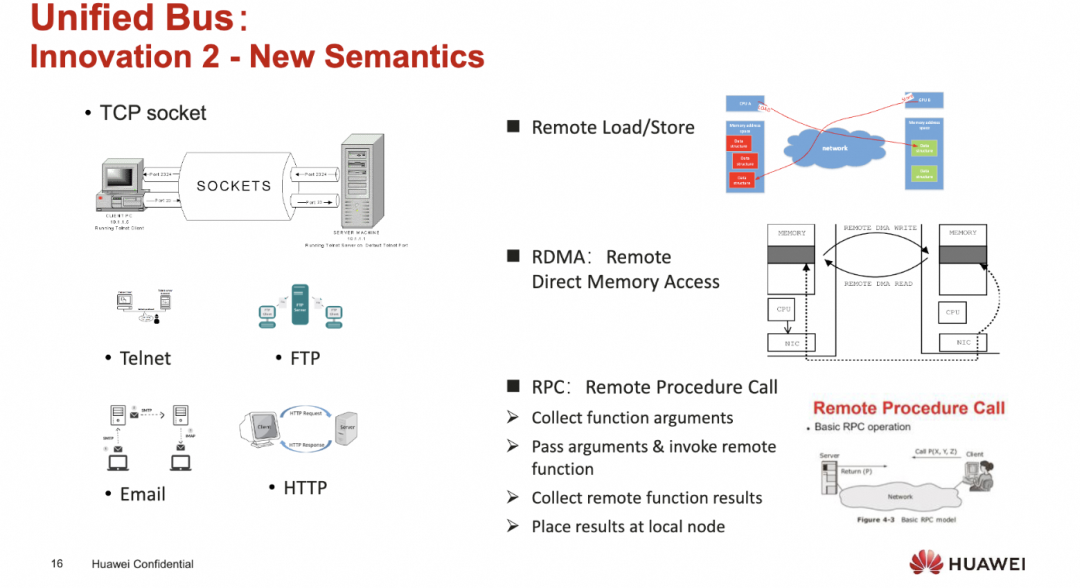
添加图片注释,不超过 140 字(可选)
然后一个单一的协议覆盖广泛的场景
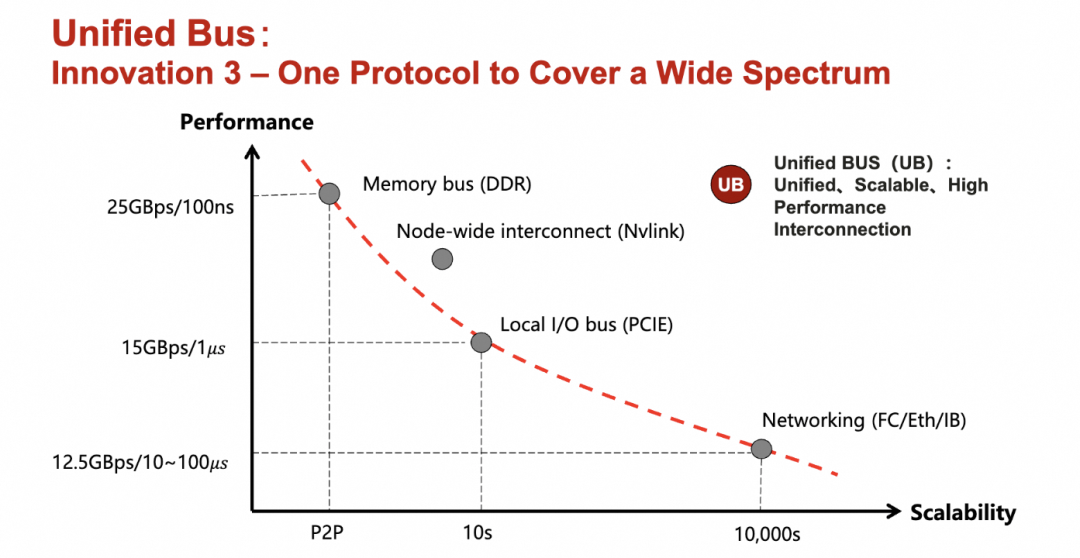
添加图片注释,不超过 140 字(可选)
最后构成一个统一的系统
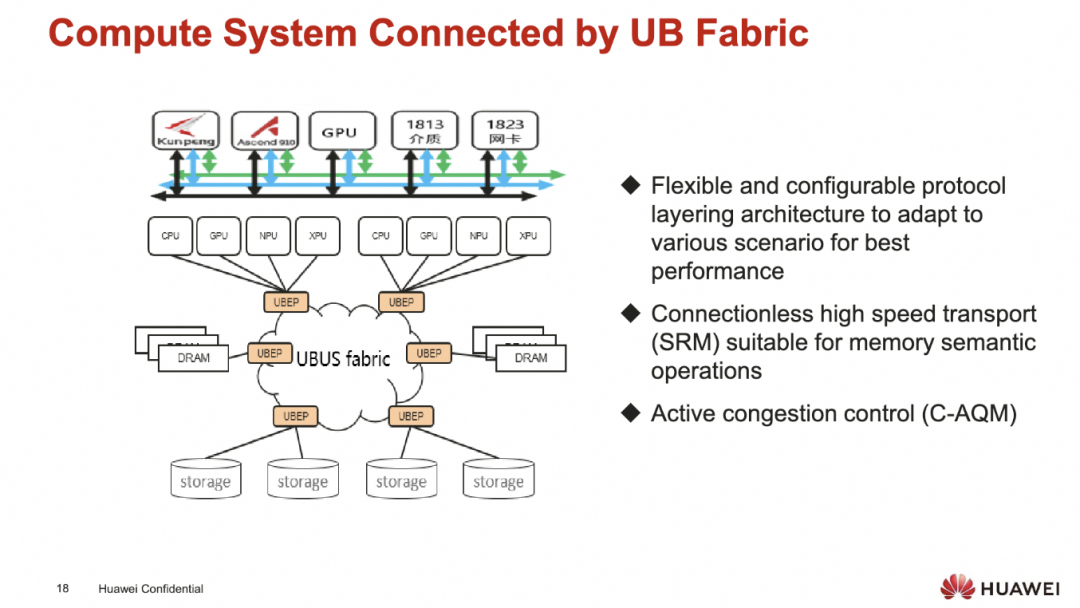
添加图片注释,不超过 140 字(可选)
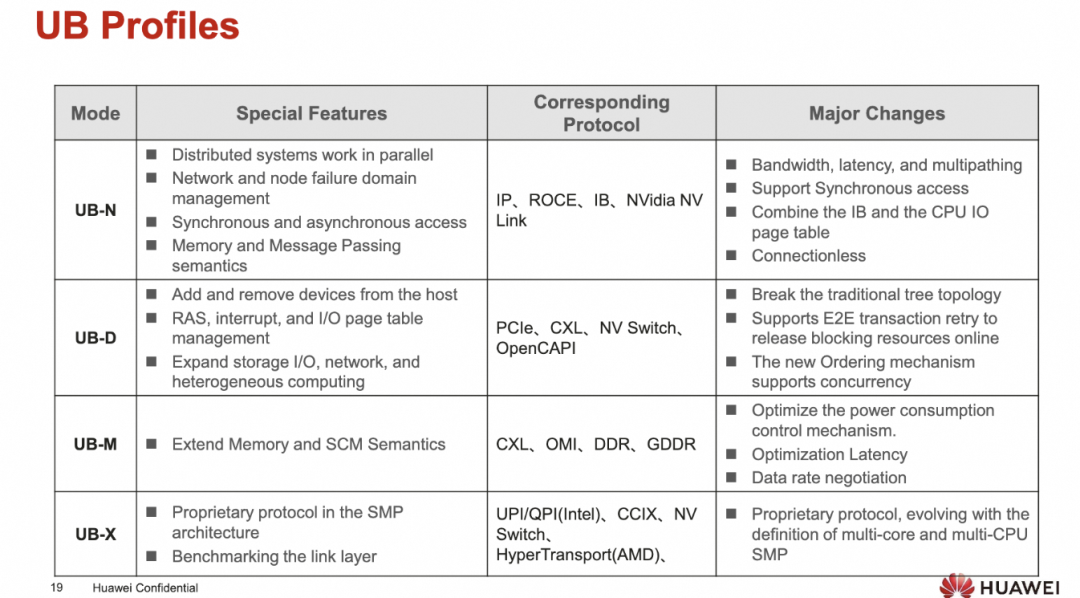
添加图片注释,不超过 140 字(可选)
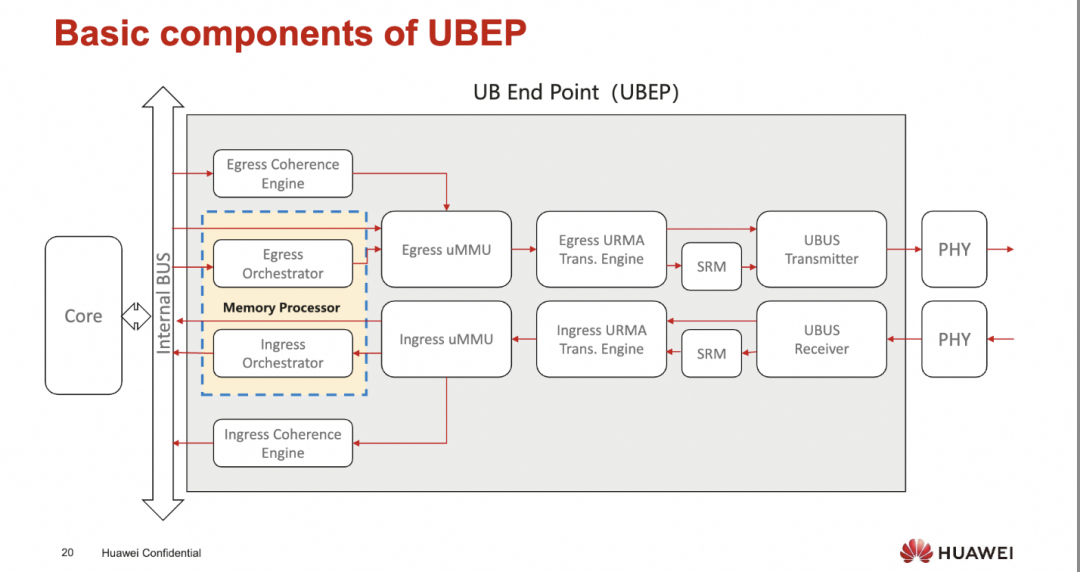
添加图片注释,不超过 140 字(可选)
基于UB构建的DC
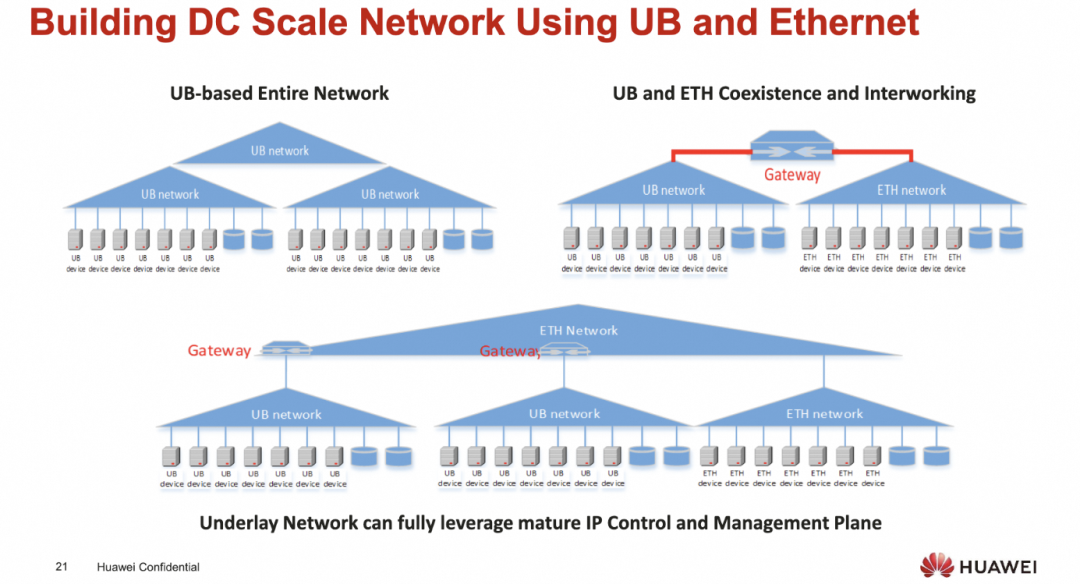
添加图片注释,不超过 140 字(可选)
UB超节点
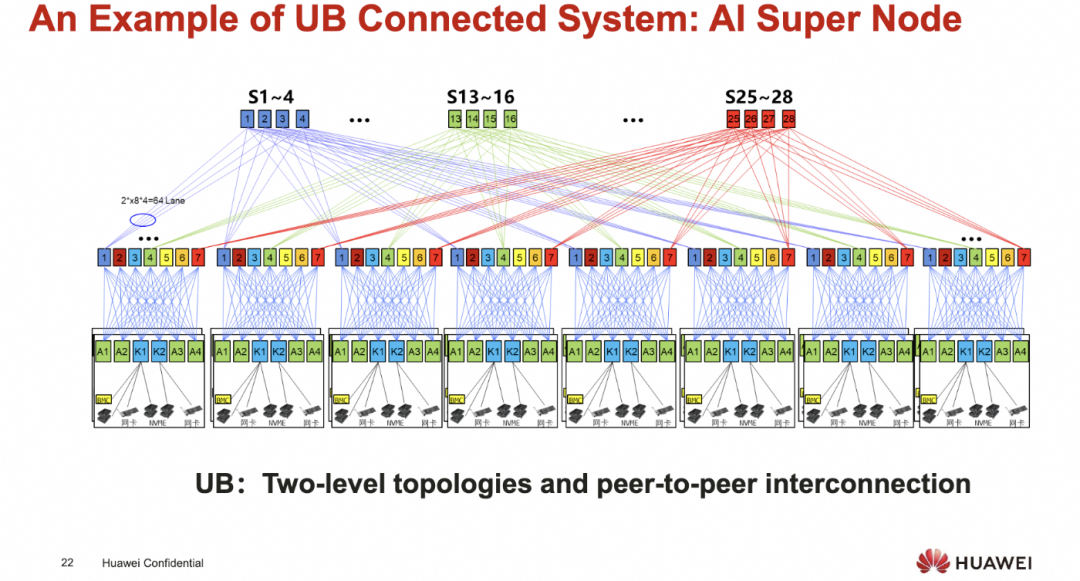
添加图片注释,不超过 140 字(可选)
最后从软件的视角上来介绍了一些并行计算软件编程的挑战和答案

添加图片注释,不超过 140 字(可选)
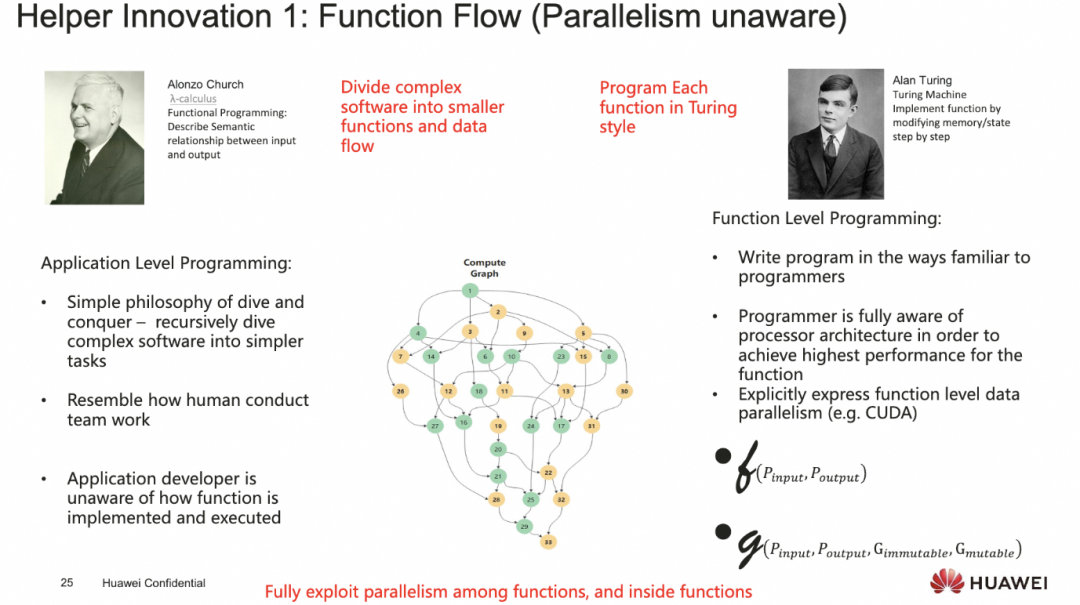
添加图片注释,不超过 140 字(可选)
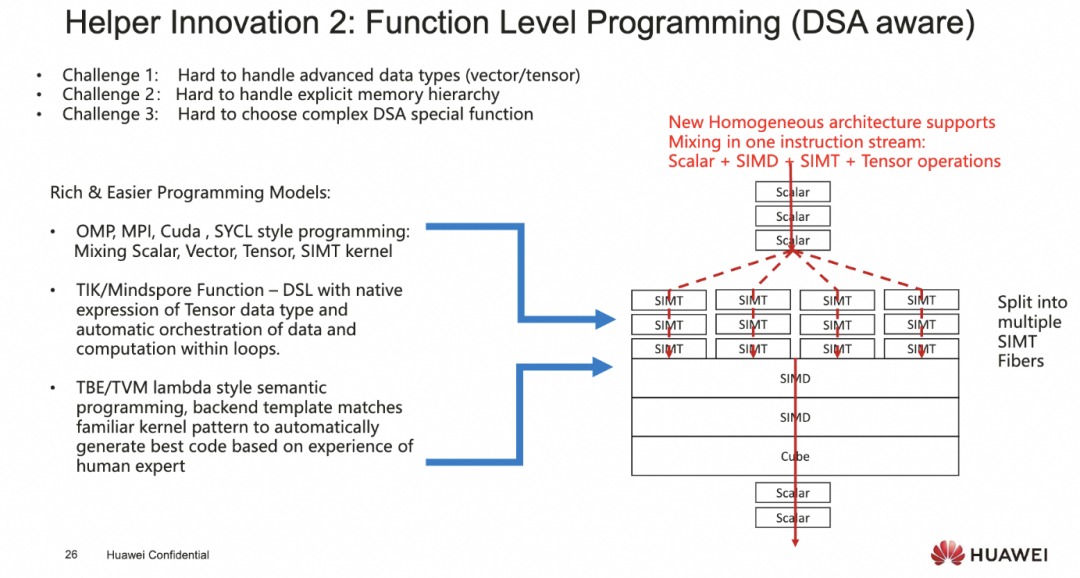
添加图片注释,不超过 140 字(可选)
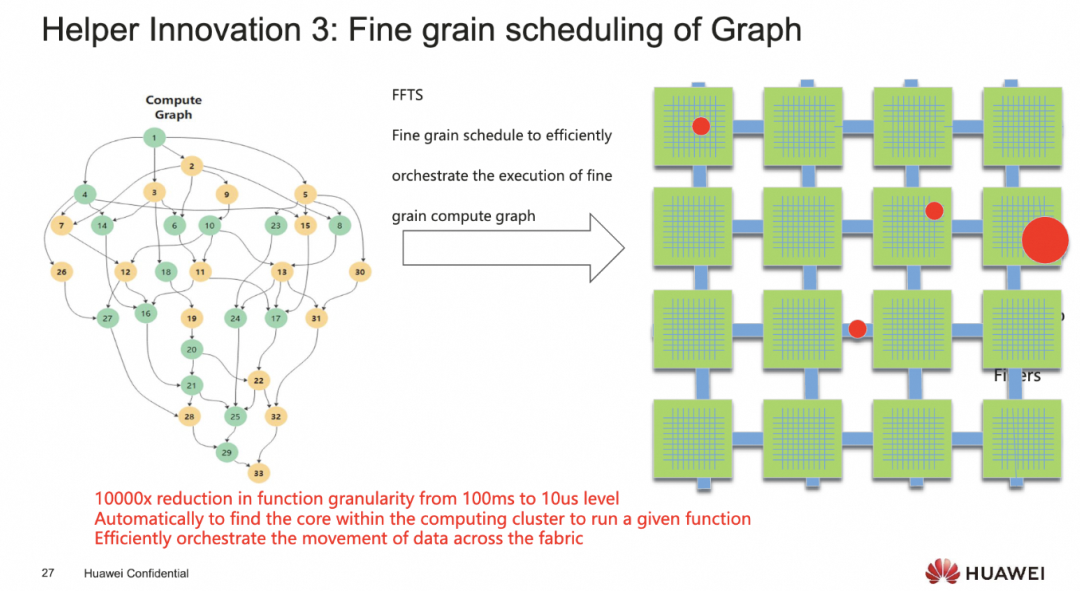
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
3. 一些分析
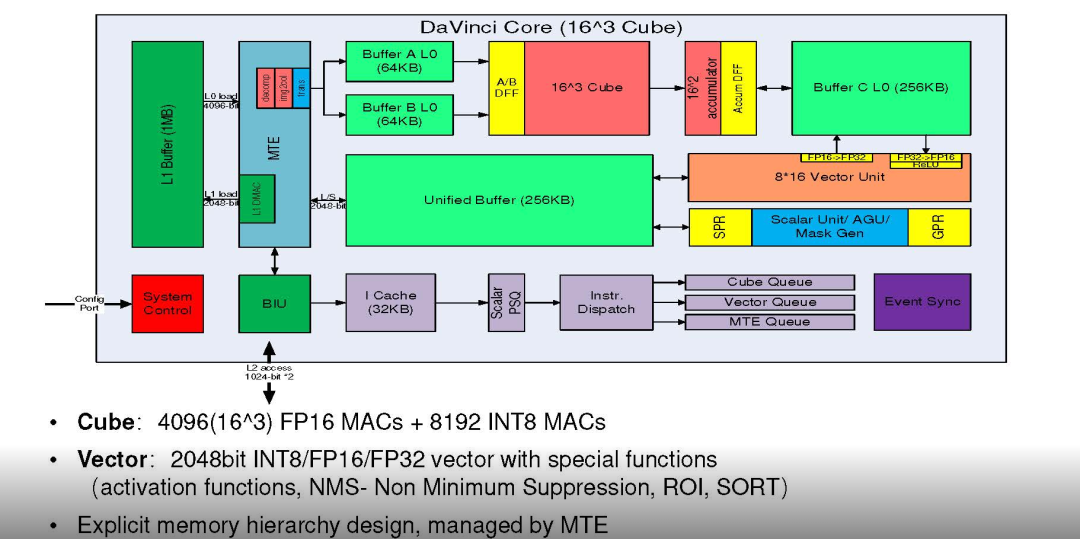
从PPA的角度来看, 正如NV过去30年走过的路, 用DSA从CPU里Offload出来, 然后逐渐统一各种Shader DSA构建统一的可编程架构出现了CUDA以及非常优雅的SIMT抽象. 而到了AI时代, 又因为计算上向更高维度的Tensor演进, 出现了Tensor Core, 正是在这个时候, 华为开始研发用于AI的DaVinci架构和相应的CUBE(AIC)

添加图片注释,不超过 140 字(可选)
对于TensorCore或者CUBE大家反正都差不多, 实质的争论是SIMT vs SIMD. 也就是某种意义上来说是否兼容GPGPU/CUDA的争论.
从个人而言, Nvidia在逐渐走向基于Task-Based Tensor Computation的DSL抽象, 而且现在模型中大量的计算本身就是Tile Based. 在以Tensor表达时, SIMD和SIMT并无太大的差异..只是我们注意到NV SIMT范式其实是在原有的OpenGL API基础上演化出来的, 然后很长一段时间它需要复用SM去同时应对图形和AI两个市场. 其实这一块直到在Turing/Ada这些带有光追的RT-Core时才再一次分裂开来...
当然SIMT相对于SIMD还是有一些优势的, 在一些稀疏的数据不连续的场景下, 或者对于访问内存延迟的一些问题处理上, 还有未来一些不确定的element-wise的一些操作上, 相对于SIMD会更加灵活一些. 而且本身SIMT的抽象相对于SIMD还是更加优雅一些的.
当然我没用过Ascend 910的处理器, 只是偶尔翻看了几页资料, 直观上来看, DataPath上并没有太多的问题, 唯一可能的问题是CUBE操作的一些数据不像SIMT上可以放到RMEM做一些更灵活的Epilogue处理, 而是只能到Vector Unit上, Vector上SIMD做一些Epilogue的处理不知道难度有多大, 总觉得挺烦人的, 或许这是大家吐槽的地方?
Unified Buffer虽然和NV SMEM概念类似, 或者说它倒是更像如今的TMEM. 这些数据通路上的细节问题, 或许可以小改一下, 让客户少一些学习成本? 而可能关键的问题还是出在一些ControlPath和软硬件交付的contract上.
添加图片注释,不超过 140 字(可选)
其实一切的实质问题是如何用最简单的编程模型保证足够的Data Locality 这是每个架构师最难取舍的, 推倒重来很容易, 但是工业界并不会给你太多这样的机会. 例如黄教主的第一代NV1就是这样一个故事, 最终还是向生态妥协,特别是1995年微软发布DirectX后, 然后很快的纠正了错误发布NV3 才逐渐活下来.
回到Davinci架构本身, 如果把它作为一个NPU CoProcessor在手机芯片上是合适的, 配合一些ARM Core如果能够很灵活的去控制一些指令队列, 编程上应该还行吧? 也就是说它实质上的设计是一个协处理器, 而如果作为独立的加速器, 控制路径看上去简单了一些, 无法实现很多细粒度的操作? 当然伴随着UB的超大带宽和低延迟, 配合一些kunpeng的ARM core 也不是不行? 让ARM Core上抽象出一个更好的类似于Warp的scheduler去issue指令到Ascend? 然后再做些非常native的协程抽象?
4. 谈谈生态和习惯的重要性
另一方面对于SIMT和SIMD的争议, 在廖博的session中提出的这种同构的融合方案, 各取所长看上去也挺好的?
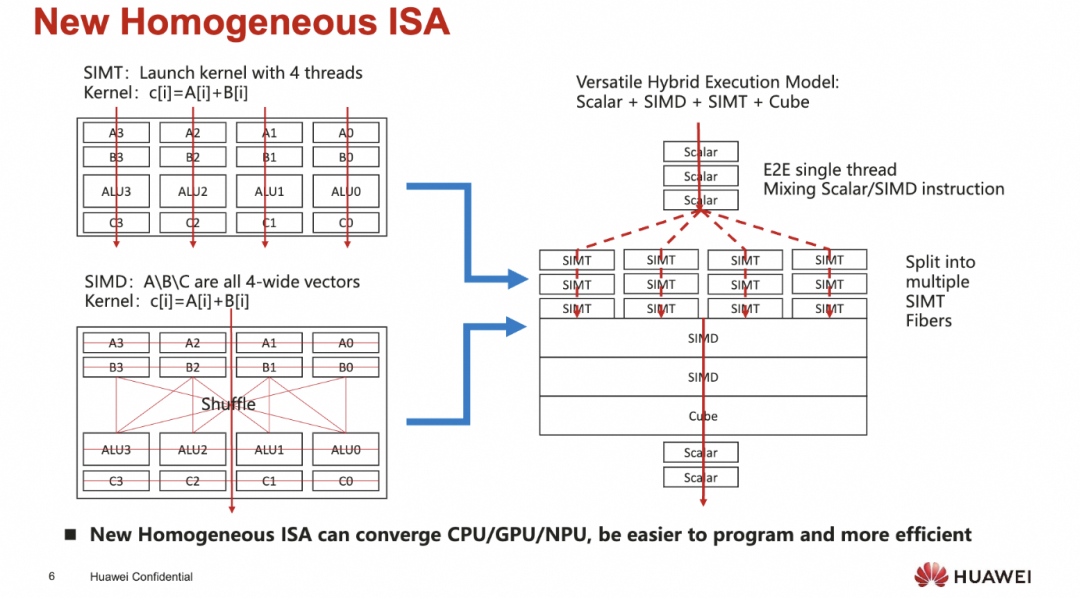
添加图片注释,不超过 140 字(可选)
但实际上的软件抽象是什么样子的, 应该是我比较菜没想明白. Jim Keller以前有一页
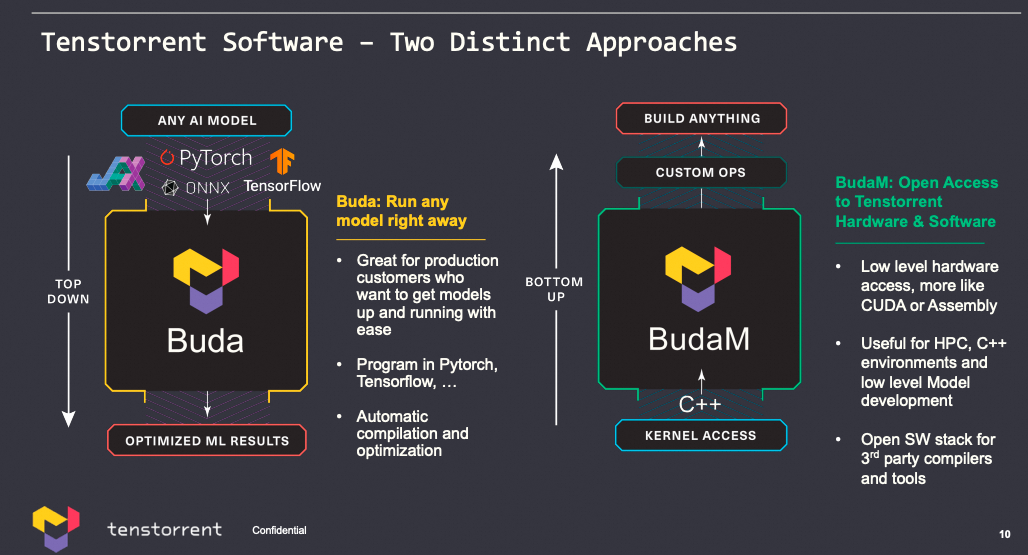
添加图片注释,不超过 140 字(可选)
但是后来又有一个耐人寻味的Session[4] TOP Down or Bottom UP?
实质性的问题回到了生态上, 这些问题很大程度上不是单纯的技术问题了. 当你破坏了用户已有的习惯和认知时, 代价是极大的. NV不也曾因为D3D的生态而妥协过么, 很多时候一些“革命性的设计”会因为偏离了行业的标准而失败.. Nvidia自身的失败就有两次:
一次是在刚创业的时候, NV1 Quadratic Texture Mapping, 将纹理映射到曲面上, 比三角形像素填充看上去表面效果更好, 但是芯片做出来和主流框架并不兼容, 而且还有不少渲染错误.. 最终1995年微软的Direct3D以行业常用的三角形像素填充作为标准..
第二次失败大概是在2002年微软在DirectX9.0中定义了新的Shader Model 2.0(SM2.0) , 标准的Shader Language发布, 而前一代的GeForce 3并未完全支持可编程, 新的GeForce 4也未意识到生态巨大的变革, 仅支持DX8.0. 此时ATI Radeon 9700新的架构, 由于SM2.0引入了一些高级控制指令, 例如Jump/Loop/subroutines, 实际上也就构成了SIMT的真正的雏形.
而后nVidia在2003年发布的GeForce FX, 在Vertex Shader中支持了Branching的能力, 并支持Dynamic Flow Control来应对一些pipeline的性能问题, 然后在GeForce 6上构建了完全可编程Vertex/Pixel Shader
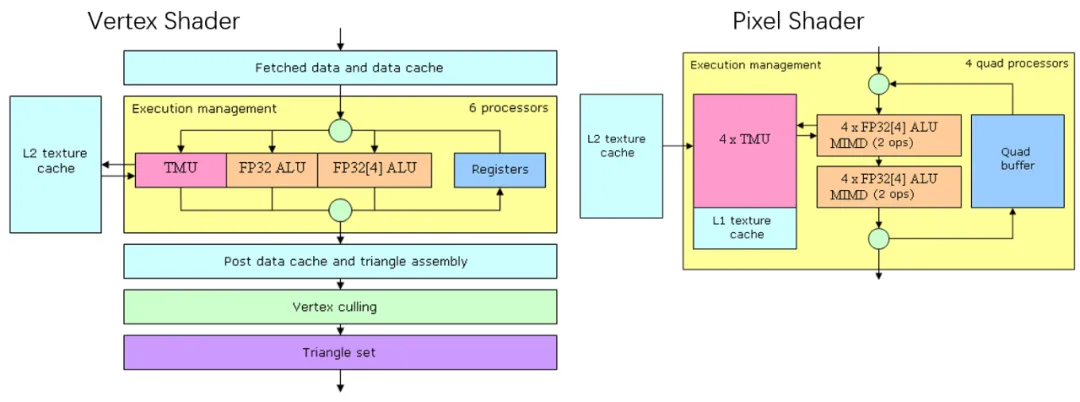
添加图片注释,不超过 140 字(可选)
最终延续对生态的支持, 统一VS和PS构建了SIMT的CUDA, 而正是这个时候ATI又误入了VLIW, Intel Larrabee又去搞了Many Core..看到当年的一个PPT
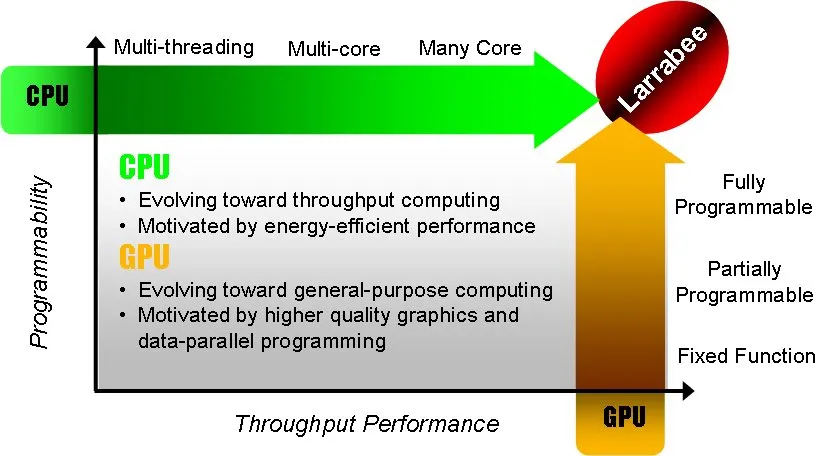
添加图片注释,不超过 140 字(可选)
5. 再来谈谈DPU和网络处理器
其实一直有一个感觉: One Size never fit all. 工业界针对不同的领域一定会出现各个领域独有的代码, GPU侧重于数据并行的方式, 而CPU更侧重于任务并行的方式.

添加图片注释,不超过 140 字(可选)
或许按照如下表格基本上就能看清楚为什么需要3个不同的socket了..
实际上DPU这名字我认为一直以来都是扯淡的, 它来自于Fungible的Pradeep, 然后老黄将其发扬光大了... 从网络处理器的视角来看, 为了数据处理的高效性和降低访问内存, 很多处理都只对报文头处理,对Payload的内容不可见. 只有部分做安全防火墙的产品有DPI的需求..
过去几十点的这一段历史可以参考
从查表的软件算法优化再到TCAM, 从纯软件的转发代码再到并行的PXF(Paralleled eXpress Forwarding), 最终回到Run-to-Completion的可编程架构... 整个网络处理器的发展时间脉络和GPU是基本类似的, 都是面临需要处理的数据庞大规模而产生的...
2004年~2008年, 差不多和CUDA同一时期, 思科也面临多个产品线大量的ASIC, 想去资源复用, 通过一个处理器来覆盖多个产品线, 于是开始了Quantum Flow Processor的研发... 最根本的一个需求就是要完全C可编程的去接原来在CPU上跑的一些转发代码. 处理器架构上做了很多妥协但又维持了很好的编程抽象.
但我们又来反观Nvidia(Mellanox)在RDMA上最近十年的发展, 不管叫它DPU也好还是SuperNIC, 实质的问题是什么, 那就是简单的ASIC Pipeline无法覆盖业务需求了.
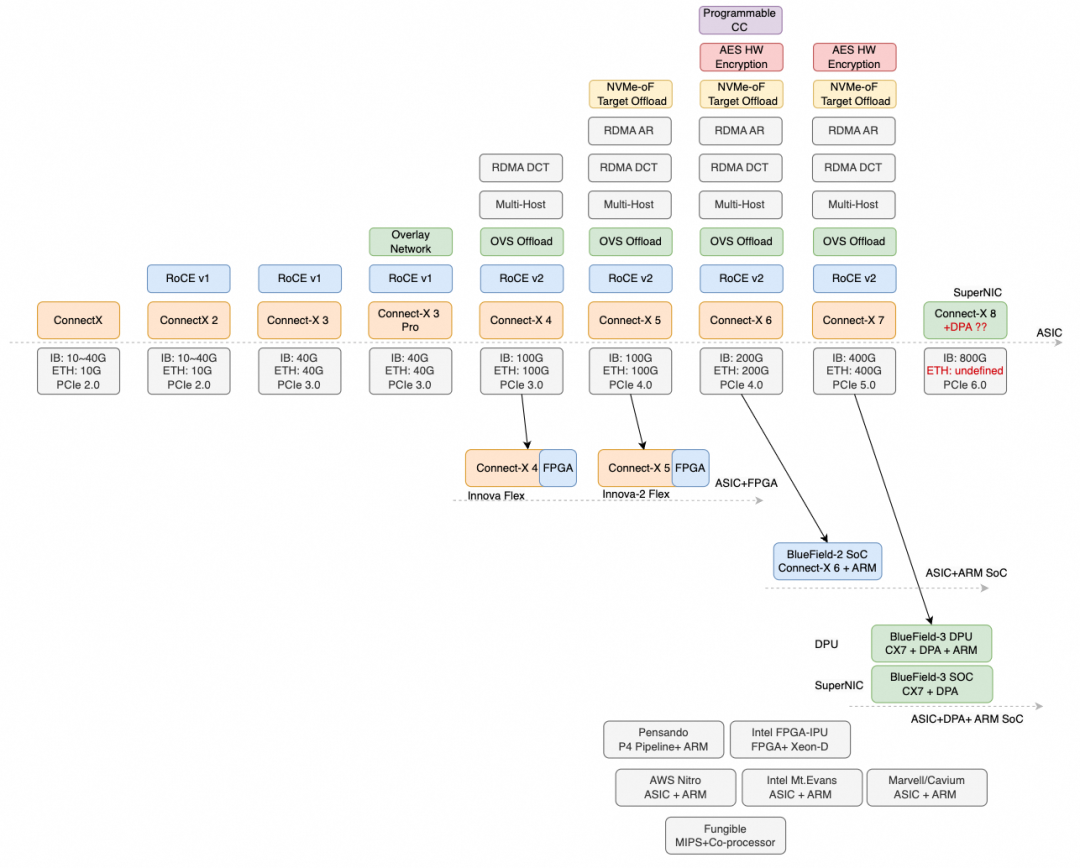
添加图片注释,不超过 140 字(可选)
但是这里面暗含了很多问题, Mellanox是一个纯ASIC公司, 直到后期收购了EzChip和Tilera才获得网络处理器和片上网络的一些技术, 然后微架构上EzChip这群人压根就不像Cisco QFP/Cavium/RMI这样做过很多复杂的NP.
BF3最终搞出来一堆DPA配一堆ARM Core, 还搞了一个DOCA.. 实质的问题是什么? 有一篇论文可以读一下《Demystifying Datapath Accelerator Enhanced Off-path SmartNIC》[5]
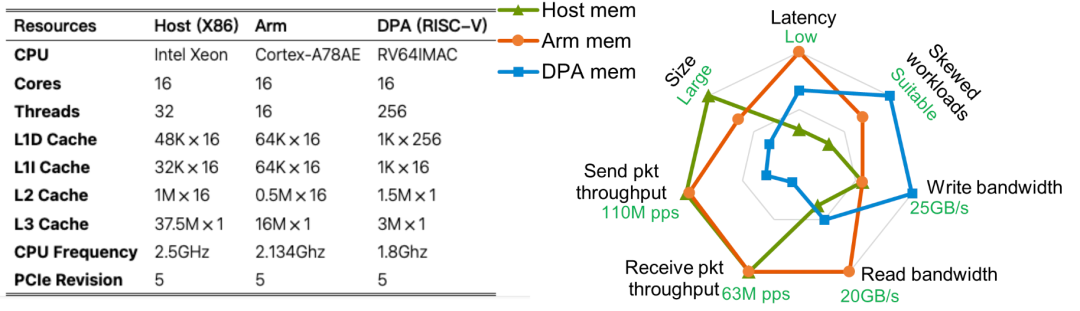
添加图片注释,不超过 140 字(可选)
BF3实际上在很多workload上都有问题, 我又来Cue一下隔壁友商的3FS一类的存储跑满40GB/s了么? 几个月了呀...RoCE的DeepEP跑好没?
其实后来Cisco也犯了一个很大的错误, 就是Polaris的项目, 把企业网路由交换无线多个产品线的代码融合到一起, 还顺便把华为带到坑里了, 当年我还和华为数通的胡总聊过, 别这样干... 这就是One Size never fit all的另一个例子...
6. 同构视角下的异构计算
Cisco也和廖博讲的海思的情况类似, 海思是从端侧很小算力的平台到大型的训练/推理集群, Cisco也有从最小规格的路由器到超大规模的运营商级的路由器, 需要软件从一些小的Arm Core到X86, 然后一直cover到运营商级别的自研NP.
其实NetDAM和UB在解决同一个问题, 本质上是在Interconnect上做一些文章, 但是至少在我的认知里面, 我会为了保证上层生态的兼容性, 做出一些取舍. 不会简单的想用一个协议栈去替换已有的东西.
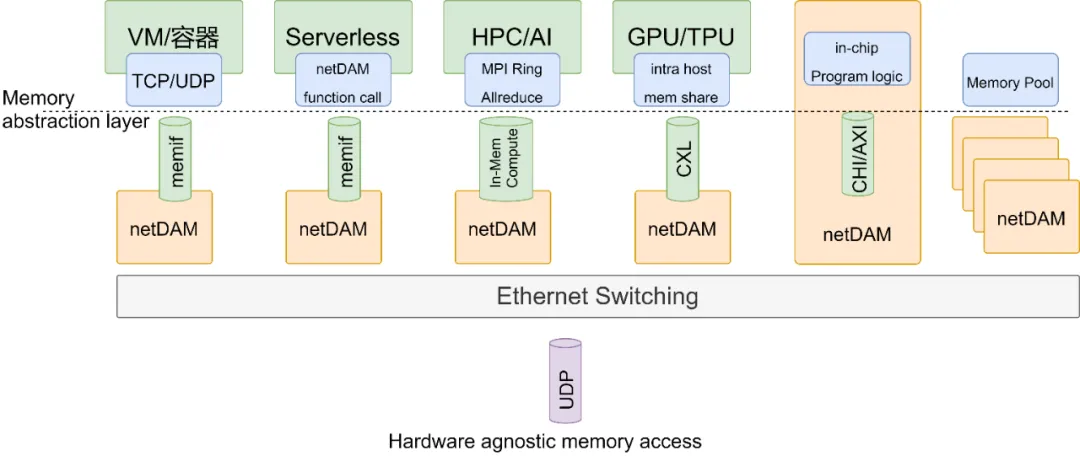
添加图片注释,不超过 140 字(可选)
你可以看到NetDAM的设计上, 对上我需要兼顾所有的通用处理器类型和语义, 对下采用标准的以太网结构. 实质上NetDAM就是一种Ethernet Based ScaleUP(SUE), 也就是隔壁友商天天吹的国内首创, 实际上过去几年我一直在和BRCM的Tomhawk Ultra(TF1)团队合作, 包括里面的一些芯片架构,Message Packing, 内存语义, INCA操作等..

添加图片注释,不超过 140 字(可选)
The greatest generalization is abstraction, 而这层抽象在Memory上
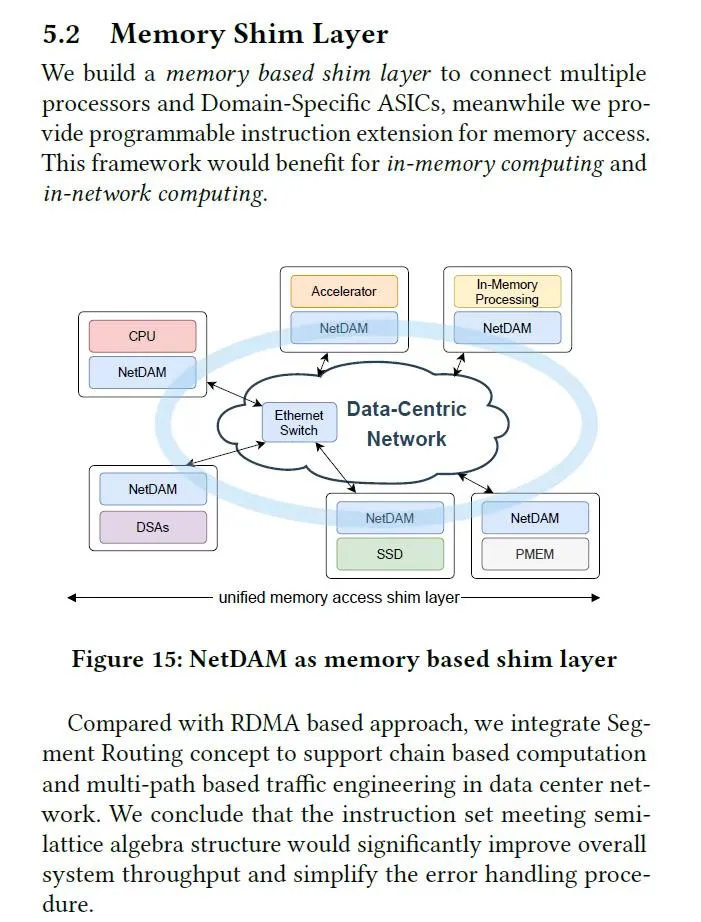
添加图片注释,不超过 140 字(可选)
在网卡上加一块可大可小的Memory的实质是什么? It's a Monad!无论是最早的图灵机还是冯诺伊曼架构, 还有后来的各种向量机/SIMT再到TensorCore/CUBE. 内存就是一个很好的Monad.. 通过内存的交付物来解决DSA和通用处理器互连的问题...不光是数据路径还有很多指令相关的控制路径.
其实你看NVidia, 关于TC的操作上, 也是在RMEM/SMEM包括TMEM上构建一个Abstraction Layer和CUDA Core进行交互...
另一方面正如我几年前预料到的那样, ScaleUP对节点数需求的实质是Memory semantic ScaleOut...例如DeepSeek-V3论文中阐述的ScaleUP和RDMA ScaleOut语义上的复杂性问题, 几年前就完全预料到了...
最后来谈谈作为架构师的一些经验吧, 很简单的一条经验就是, 你必须要Bottom Up去了解整个芯片架构的各种物理约束, 硬件抽象,再到它是否适配, 然后同时又需要从应用的视角, 中间算子的视角Top Down去了解用户的使用习惯, 最终在一个合适的位置找到一个Contract, 让软件和硬件能够达成交易.
这也是为什么你会在这个公众号看到从算法层面上的一些分析, 又会有应用上去做一些Agent相关的工作, 同时还要关注算子相关的, 例如Cutlass一类的开发, 再到网络上RDMA传输, 最终到芯片架构各种ScaleUp互连的分析等...
实质性的问题就是作为一个架构师或者一个架构师团队, 必须要把这些全部拉通, 才能再同构视角下做好异构计算...另一方面是一个长期主义的事情, 任何东西推倒重来都会导致新建设成为一个孤岛和独立的生态, 想想当初NV推CUDA是多么的卑微, 而AMD/ATI又在整个架构上多么的摇摆, 一会儿VLIW,一会儿又OpenCL...折腾了好多年...
因为以前还在Cisco做过很多年的Marketing, 再对技术人提一些建议, 很多技术本身终局是对的, 但是推出的时间点不对一样会前浪死在沙滩上. 记得我2019年在思科搞AIOps, 将AI引入到整个Cisco网络平台上的时候, 其实在内部很多Marketing讨论会时, 大家当时谈到的观点就是这个技术可能还有点太早了. 最后果真等我放弃等待离职后的几年, 如今Cisco的一系列发布证明了这一点..
很多事情吧, 不要太急, 不要想着革命性的进展, 历史的巨轮总会慢慢的航行, 掉头慢. 尊重生态, 即便是以终为始, 也一步步的逐渐去调转船头 :)
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
参考资料
[1]
Apple Backs Project to Bridge its MLX Framework with Nvidia’s CUDA Ecosystem: https://winbuzzer.com/2025/07/15/apple-backs-project-to-bridge-its-mlx-framework-with-nvidias-cuda-ecosystem-xcxwbn/
[2]
An Outlook for New Homogeneous Computing System: https://www.chaspark.com/#/stw/media/720435943085228032
[3]
An Outlook for New Homogeneous Computing System: https://www.chaspark.com/#/stw/media/720435943085228032
[4]
Jim Keller:使用RISC-V构建AI —— 61DAC Keynote: https://www.bilibili.com/video/BV19u8zeNER8/
[5]
Demystifying Datapath Accelerator Enhanced Off-path SmartNIC: https://arxiv.org/html/2402.03041v2
参考文献链接
人工智能芯片与自动驾驶

 浙公网安备 33010602011771号
浙公网安备 33010602011771号