
NVIDIA英伟达Jetson Thor 即将正式发售,深度分析Jetson Thor
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
英伟达Jetson Thor系列产品即将正式发售,英伟达官网放出了产品参数,目前有三个产品,包括一个是完整的开发套件,即AGX Thor Developer Kit,另外两个则是一片模组,高算力模组型号是T5000,低算力型号是T4000。目前还未公布价格,笔者推测AGX Thor Developer Kit价格在2999-3299美元之间,T5000价格是2299-2599美元,T4000价格是1999-2199美元。这三款产品目标市场都是具身智能和物理AI。T5000近似汽车领域的Thor-X,T4000近似汽车领域的Thor-U。
添加图片注释,不超过 140 字(可选)
T5000和T4000是一片699脚的板对板模组,面积是100毫米*87毫米,集成了TPP (Thermal Transfer Plate) 带热管的散热板。板对板连接器由MOLEX提供。
英伟达Jetson AGX Thor Developer Kit

添加图片注释,不超过 140 字(可选)
母板上的网卡芯片由瑞昱提供,型号为RTL8126,支持10/100/1000M/2.5G/5G Ethernet controller for PCIe;无线网卡与蓝牙模块由Azuruwave提供,型号为AW-XB560NF;140瓦直流适配器由台达电提供;1TB NVMe硬盘由西部数据提供。
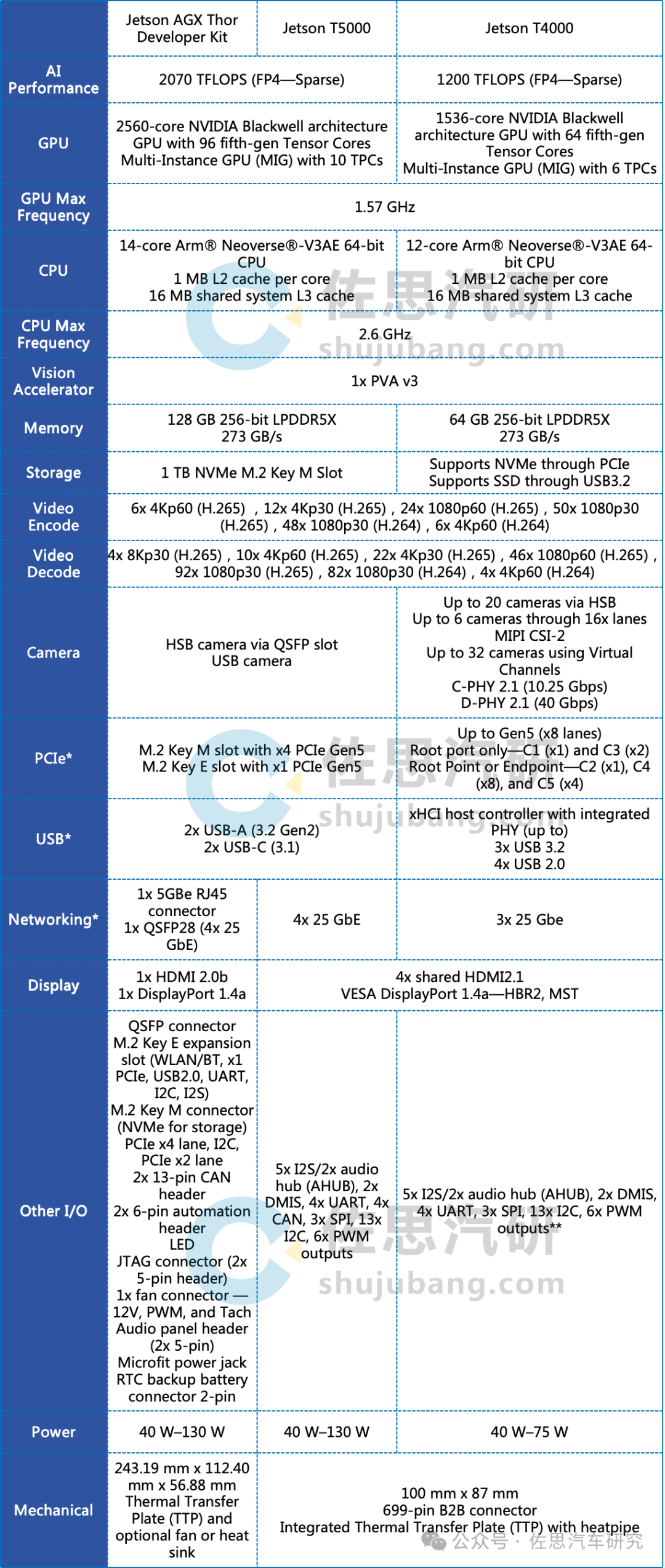
Jetson Thor架构
添加图片注释,不超过 140 字(可选)
图片来源:英伟达
ARM V3AE内部框架图

添加图片注释,不超过 140 字(可选)
图片来源:ARM
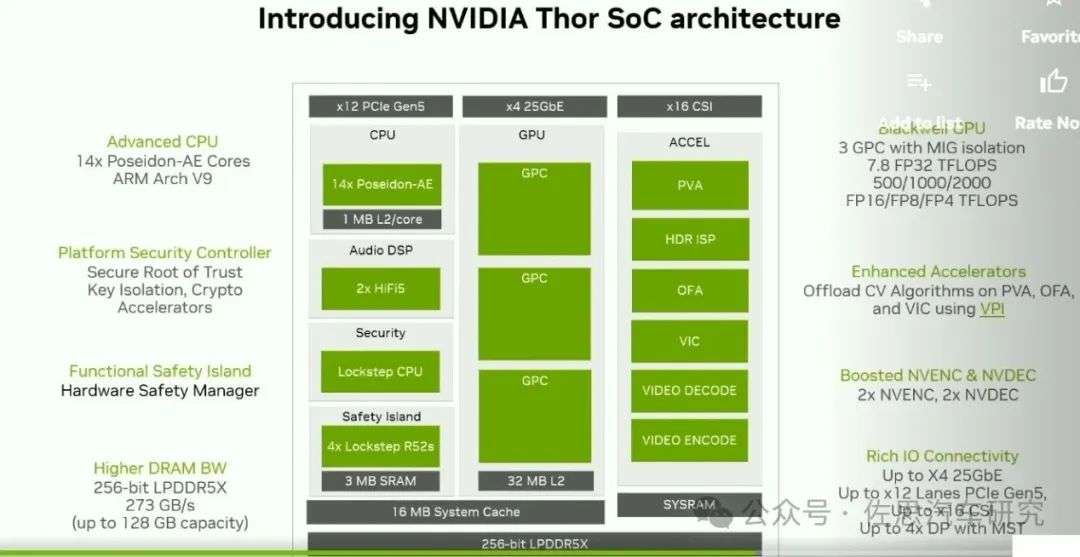
Thor使用ARM的V3AE架构,AE代表特别针对汽车,指令L1缓存64KB,数据L1缓存为64KB,L2缓存最高支持3MB,Thor选择了1MB,L3缓存是16MB。顶配Thor-X为14核心,次顶配Thor-U为12核心。CPU最高运行频率是2.6GHz。
添加图片注释,不超过 140 字(可选)
数据来源:英伟达
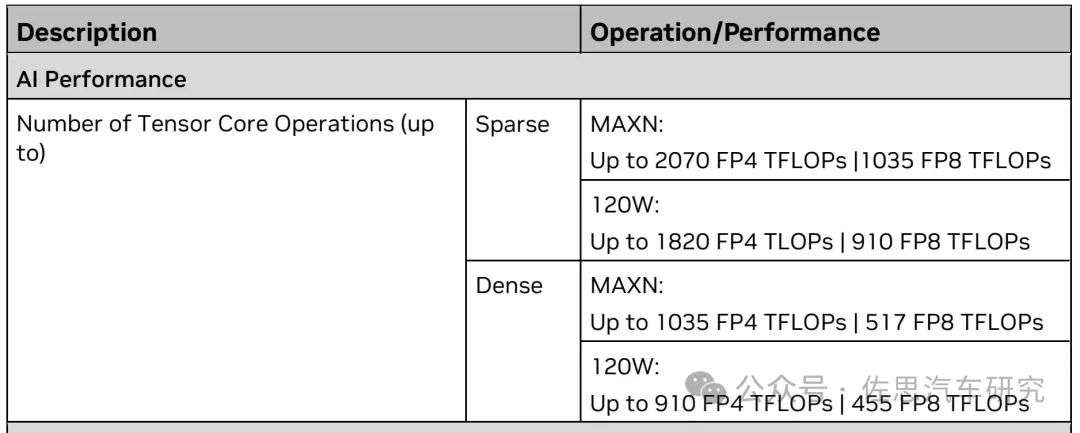
与Orin相比,Thor取消了DLA,并且低精度AI运算完全由张量核心负责,GPU则负责高精度运算,分工明确,实际算力值就是理想算力值。不像上一代的Orin,AI算力由CUDA核心、张量核心和DLA三者相加。FP4精度下稀疏算力2070TFLOPs,由于transformer架构更适合浮点,所以英伟达这里只点出浮点计算算力,当然,浮点支持是比整数INT难度要高的。
这里我们简单解析一下,为什么英伟达仅仅用96个张量核心就取得2070TOPS的超高算力。
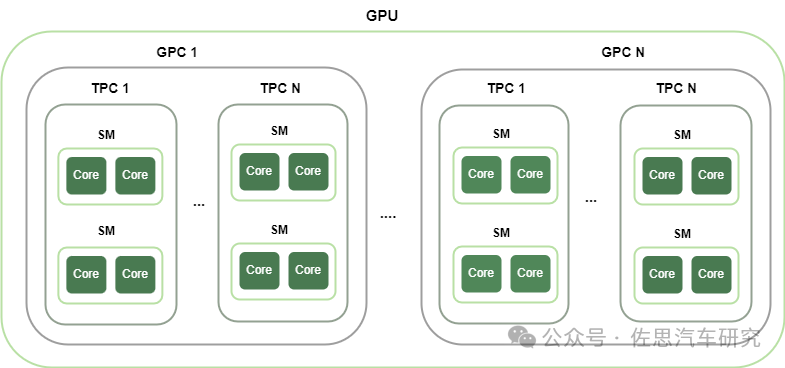
首先我们要对GPU架构有所了解,与CPU相比,GPU的体系架构中的一个最大特点就是增加了大量的运算单元ALU,通常GPU的一个处理器(也叫做流式多处理器,Streaming Multiprocessor)包括数十甚至上百个简单的计算核,整个GPU可以达到上千个核,与CPU相比,每个核的结构简单了很多,通常不支持一些CPU中使用的较为复杂的调度机制。在执行指令的时候,为了充分利用每一次读取指令带来的开销,GPU会以一组线程为单位同时执行相同的指令,即SIMT(单指令多线程)的方式,在CUDA GPU上,一组线程称为warp,也翻译叫线程束,一个warp有32个线程,每个线程执行相同的指令但访问不同的数据。为了将一个并行程序映射到GPU的多级并行度上,CUDA中首先将一组线程(通常不超1024个)组成一个线程块(block),每个线程块中的线程又可以分成多个warp被调度到GPU核上执行,一个线程块可以在一个SM上运行,多个线程块又可以组成一个网格(grid)。
AI运算最耗时的是矩阵的乘积累加,简写为MMA,英伟达的张量核心使用PTX MMA指令,PTX即Parallel Thread Execution,PTX 程序描述了一个核函数,该函数由大量 GPU 线程执行,这些线程在 GPU 的硬件执行单元(即 CUDA 核心)上执行。线程被组织为网格,每个网格由协作线程阵列 ( CTA )组成。PTX 线程可以访问来自多个状态空间的数据,这些状态空间是具有不同特性的内存存储区域。具体而言,线程具有每个线程的寄存器,CTA 内的线程具有共享内存,并且所有线程都可以访问全局内存。在指令发出时,指令单元选择一个 Warp,并向 Warp 中的线程发出指令。这种执行方法称为单指令多线程 ( SIMT )。与单指令多数据 ( SIMD ) 类似,SIMT 使用一条指令控制多个处理单元,但与 SIMD 不同的是,SIMT 指定的是单线程行为,而不是向量宽度。
为了简化计算,英伟达用m、n、k,描述参与乘法累加运算的Warp宽度矩阵块的形状,matrix_a块的尺寸为m*k;matrix_b的尺寸为k*n;accumulator块的尺寸为m*n。英伟达张量核心每一代的进步主要是扩展Warp的宽度。

添加图片注释,不超过 140 字(可选)
整理:佐思汽研
用MMA可以简单计算算力值,如Blackwell在FP4精度下,每周期的浮点算力是256*256*96,每条PTX指令,可以同时完成乘积和累加,即2OPs,即256*256*96*2=12582912,英伟达张量核心运行频率大致在1.3-1.7GHz之间,96个张量核心即48个SM单元,算力即为48*1.7GHz*12.582912=1026.7TOPS,与英伟达官方的1030TOPS非常接近。比第一代张量核心算力提高了几百倍。
添加图片注释,不超过 140 字(可选)
来源:网络
Thor的设计非常奇特,完全不同于英伟达的GPU产品。一般来说,一个GPU包含N个GPC(Graphics Processing Clusters),一个GPC包含N个TPC(Texture/Thread Processing Clusters),一个TPC包含N个SM(Streaming Multiprocessors)。以英伟达RTX5090为例,它有11个GPC,其中10个GPC包含8个TPC,1个GPC包含5个TPC,合计85个TPC,每个TPC包含2个SM,每个SM包含128个CUDA核心和4个张量核心,也就是说SM单元是完全一致的,而Thor是3个GPC,有两个GPC是包含4个TPC,一个GPC,包含2个TPC,也就是10个TPC。如果SM单元是完全一致的,那么不可能有96个张量核心。可能是某一个GPC全部都是张量核心。
Thor包含2560个CUDA核心,算力最高是8.064TFLOPs@FP32,功耗达130瓦,最高频率1.575GHz。Thor包含一个3.0版PVA可编程加速器,算力为165GFLOPs@FP32,支持立体双目视差匹配和光流算法,运行频率1.215GHz。
Jetson T5000系统框架图
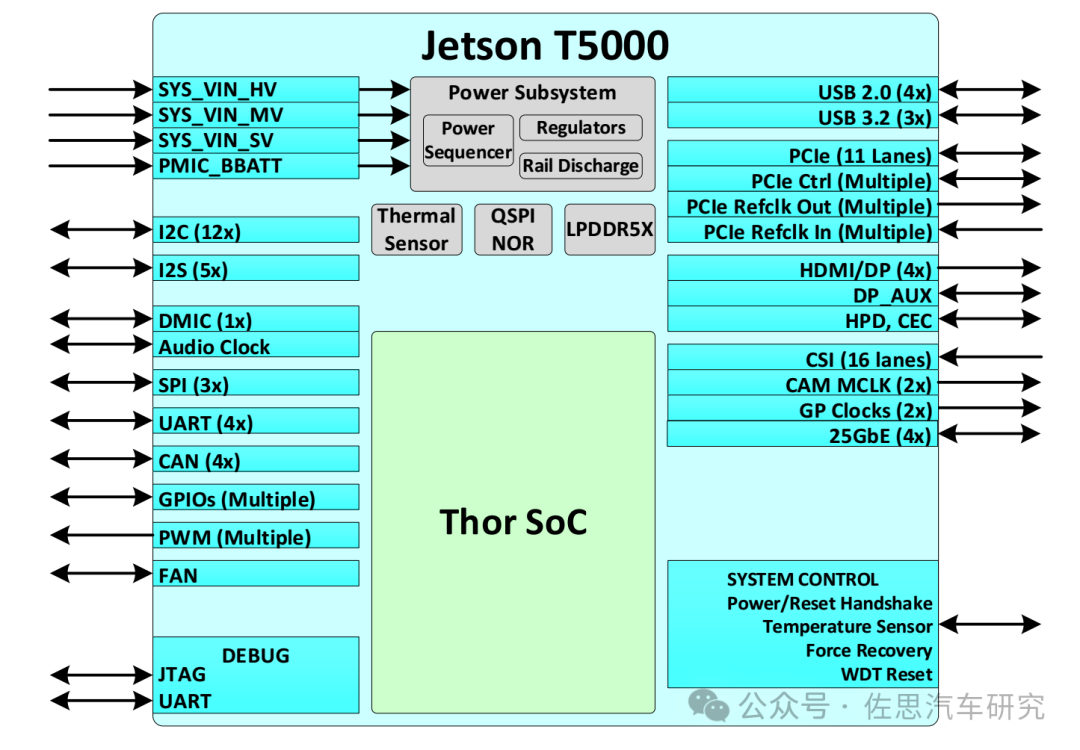
添加图片注释,不超过 140 字(可选)
图片来源:英伟达
对比Jetson AGX Orin,接口数量有所扩展,I2C由8个增加到12个,I2S由4个增加到5个,CAN由2个增加到4个,增加了一个音频时钟接口,显示输出大幅度增加,HDMI/DP由1个增加到4个,做舱驾一体也没问题。
尽管Jetson Thor不是为汽车领域设计的,但仍然能基本满足车载需求,运行稳定在-25℃至115℃,Slowdown温度为109℃,可以7*24运行连续5年,不过输入电压略高,在7-20V之间。
Jetson Thor基本可以相当于两片Thor-U的性能,特别是在AI算力方面,因为两片Thor-U即便使用五代PCIe交换机连接,带宽也不过64GB/s,远低于英伟达第五代NVLink的1800GB/s,只有用NVLink才能达到理想状态,将GPU算力翻倍增加。当然,对于普通消费者,肯定觉得两片Thor-U更好。
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
参考文献链接
人工智能芯片与自动驾驶

 浙公网安备 33010602011771号
浙公网安备 33010602011771号