
2025最新!三万字长文,详解统一多模态理解与生成模型的进展、挑战与机遇
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
Paper:Unified Multimodal Understanding and Generation Models: Advances, Challenges, and Opportunities
Abs:https://arxiv.org/abs/2505.02567
Github:https://github.com/AIDC-AI/Awesome-Unified-Multimodal-Models

添加图片注释,不超过 140 字(可选)
00Abstract
近年来,多模态理解模型与图像生成模型均取得了显著进展。尽管这两个领域各自发展迅速,但长期以来彼此相对独立,形成了不同的架构范式:多模态理解主要采用自回归架构,而扩散模型则成为图像生成的核心支柱。近期,统一多模态理解与生成任务的框架引发了广泛关注。GPT-4o的新能力正体现了这一趋势,展示了统一模型的潜力。然而,两大领域架构差异明显,带来了诸多挑战。为梳理当前统一建模的研究进展,我们开展了全面综述,旨在为未来研究提供指引。
首先,我们介绍多模态理解与文本生成图像模型的基础概念及最新进展。随后,我们系统回顾现有统一模型,将其划分为三大架构范式:基于扩散的模型、基于自回归的模型,以及融合自回归与扩散机制的混合方法。
针对每一类方法,我们详细分析其结构设计与创新点。此外,我们汇总了专门面向统一模型的数据集与评测基准,为后续探索提供资源支持。最后,我们讨论该新兴领域面临的关键挑战,包括分词策略、跨模态注意力机制与数据瓶颈。
鉴于该领域仍处于早期阶段,我们预计未来将有快速突破,并计划定期更新本综述。我们的目标是激励更多相关研究,并为学术界提供有价值的参考资料。
01INTRODUCTION
近年来,大语言模型(LLMs)如LLaMa、PanGu、Qwen与GPT的快速发展,正在深刻变革人工智能领域。这些模型在规模与能力方面不断扩展,推动了各类应用中的重大突破。伴随这一进步,LLMs也逐步扩展至多模态领域,催生出强大的多模态理解模型,如LLaVa、Qwen-VL、InternVL、Ovis与GPT-4。这些模型的能力已从早期的图像描述拓展至可基于用户指令执行复杂推理任务。与此同时,图像生成技术也经历了飞速发展,SD系列与FLUX等模型现已能够生成高质量、紧密贴合用户提示的图像。
当前,LLMs与多模态理解模型的主流架构范式是自回归生成,其核心在于基于解码器的结构与下一个token预测,进行顺序文本生成。相比之下,文本生成图像领域的发展路径则截然不同。早期以生成对抗网络(GANs)为主导,随后迅速转向扩散模型,后者结合了UNet与DiT等架构,以及CLIP与T5等先进文本编码器。目前,尽管已有部分探索尝试将LLM风格架构应用于图像生成,但扩散模型在生成性能方面仍占据主流地位。
虽然自回归模型在图像生成质量上落后于扩散方法,但由于其与LLMs在结构上的高度一致性,使其在构建统一多模态系统方面具有独特吸引力。一个具备理解与生成多模态内容的统一模型,潜力巨大:它既能基于复杂指令生成图像,又能对视觉数据进行推理,还能通过生成结果实现多模态分析可视化。2025年3月,GPT-4o增强能力的发布进一步凸显了这一趋势,激发了学术界与产业界对统一多模态模型的广泛关注。
然而,设计这样一个统一框架仍面临诸多挑战。这需要在推理与文本生成方面充分发挥自回归模型的优势,同时融合扩散模型在高质量图像合成中的强大能力。目前,许多关键问题尚未解决,例如如何有效地将图像标记化以适配自回归生成。一些方法采用扩散模型管道中常见的VAE或VQ-GAN或其相关变体来生成图像token,另一些方法则利用EVA-CLIP或OpenAI-CLIP等语义编码器。此外,虽然自回归模型通常对文本使用离散token,但有研究表明,对于图像token,连续表示可能更为适合。除了tokenization之外,融合并行扩散策略与序列自回归生成的混合架构,正成为除单纯自回归架构外的另一有前景方向。因此,在统一多模态模型中,图像tokenization技术与架构设计均仍处于早期探索阶段。
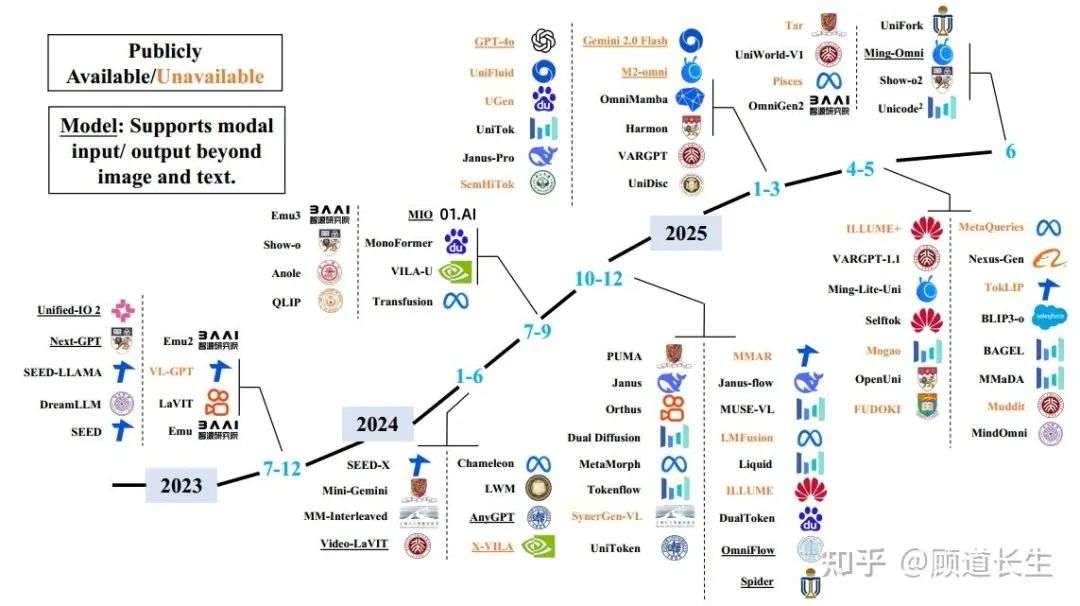
图1. 公开与未公开统一多模态模型的发展时间线。图中模型按发布时间从2023年至2025年排序。图中带下划线的模型表示任意模态输入输出模型(any-to-any multimodal models),即支持处理除文本与图像之外的输入或输出,如音频、视频与语音。该时间线展示了该领域的快速发展趋势。
为全面梳理当前统一多模态模型的发展现状(如图1所示),并为未来研究提供参考,我们撰写了本综述。我们首先介绍多模态理解与图像生成领域的基础概念与最新进展,涵盖自回归与扩散两大范式。随后,系统回顾现有统一模型,并将其归纳为三类主流架构范式:基于扩散的架构、基于自回归的架构,以及融合自回归与扩散机制的混合架构。在自回归与混合架构类别中,我们进一步基于图像tokenization策略对模型进行细分,反映出当前方法的多样性。
除架构综述外,我们还整理了专门用于训练与评测统一多模态模型的数据集与基准,涵盖多模态理解、文本生成图像、图像编辑等相关任务,为后续研究提供资源基础。最后,我们讨论该新兴领域面临的核心挑战,包括高效tokenization策略、数据构建、模型评测等。解决这些问题,将对提升统一多模态模型的能力与可扩展性至关重要。
当前社区中已存在诸多优秀综述,涵盖大语言模型、多模态理解与图像生成等方向,而本综述则专注于理解与生成任务的整合。读者可结合这些综述,获得更广阔的视角。我们希望本综述能激励更多研究,助力该快速发展的领域,并为社区提供有价值的参考资料。所有相关文献、数据集与基准资源,均已开源至GitHub,并将持续更新以反映最新进展。
02PRELIMINARY
2.1 Multimodal Understanding Model
多模态理解模型是指基于大语言模型(LLM)的架构,能够接收、推理并生成多模态输入的输出。这类模型将LLM的生成与推理能力扩展到超越文本的数据,能够在多种信息模态下实现丰富的语义理解。现有方法大多集中于视觉-语言理解(VLU),通过融合视觉(如图像与视频)与文本输入,实现对空间关系、物体、场景及抽象概念的综合理解。图2展示了多模态理解模型的典型架构。这些模型运行在混合输入空间中,其中文本数据以离散表示方式编码,视觉信号则被编码为连续表示。与传统LLM类似,这类模型的输出以离散token形式生成,通常采用基于分类的语言建模和特定任务的解码策略。
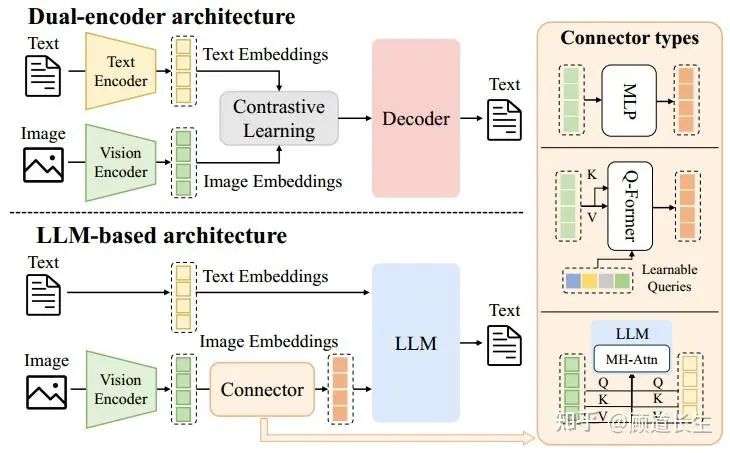
图2. 多模态理解模型的架构,包括多模态编码器、连接器与大语言模型(LLM)。多模态编码器将图像、音频或视频转换为特征,这些特征通过连接器处理后输入LLM。连接器的架构大致可分为三类:基于投影的连接器、基于查询的连接器和基于融合的连接器。
早期VLU模型主要采用双编码器架构,通过分别编码图像与文本,并在对齐的潜在空间中联合推理,代表性方法包括CLIP、ViLBERT、VisualBERT与UNITER。这些开创性模型奠定了多模态推理的核心原则,但过度依赖基于区域的视觉预处理和独立编码器,限制了模型的可扩展性与泛化能力。 随着强大LLM的兴起,VLU模型逐渐转向仅解码器架构,通常以冻结或微调的LLM为基础。这些方法主要通过结构各异的连接器转换图像嵌入,如图2所示。例如,MiniGPT-4采用单层可学习投影层,将CLIP提取的图像嵌入映射到Vicuna的token空间。BLIP-2提出查询Transformer,将冻结的视觉编码器与冻结的LLM(如Flan-T5或Vicuna)连接,以极少的可训练参数实现高效视觉-语言对齐。Flamingo则通过门控跨注意力层,将预训练视觉编码器与冻结的Chinchilla解码器连接。
近期VLU研究趋势逐渐转向通用多模态理解。
-
• GPT-4V在GPT-4框架基础上扩展图像输入能力,虽为闭源模型,但展现出强大的视觉推理、图像描述与多模态对话能力。
-
• Gemini基于解码器架构,支持图像、视频与音频模态,其Ultra版本在多模态推理任务中树立了新基准。
-
• Qwen系列展示了可扩展的多模态设计:Qwen-VL集成视觉接收器与定位模块,Qwen2-VL引入动态分辨率处理与M-RoPE机制,增强对多样输入的稳健性。
-
• LLaVA-1.5与LLaVA-Next结合CLIP视觉编码器与Vicuna风格LLM,在VQA与指令跟随任务中表现出色。
-
• InternVL系列探索统一多模态预训练策略,联合学习文本与视觉数据,提升各类视觉-语言任务表现。
-
• Ovis通过可学习的视觉嵌入查找表引入结构嵌入对齐机制,使视觉嵌入结构上对齐文本token。
近期部分模型进一步探索可扩展、统一的多模态处理架构。DeepSeek-VL2采用专家混合(MoE)架构,提升跨模态推理能力。总体而言,这些模型展现出向指令微调、token中心化框架演进的趋势,能够以统一、可扩展的方式处理多样化多模态任务。
2.2 Text-to-Image Model
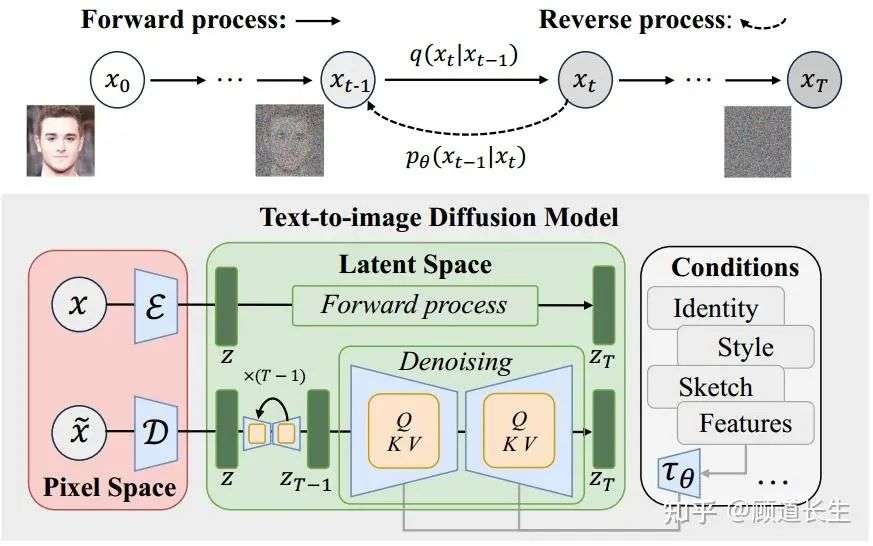
图3. 基于扩散的文本到图像生成模型示意图,其中引入了除文本之外的各种条件来引导生成结果。图像生成被建模为一对马尔可夫链:前向过程通过添加高斯噪声逐步破坏输入数据,反向过程则学习一个参数化分布,逐步去噪还原回输入数据。
扩散模型(Diffusion models,DM)将生成过程建模为一对马尔可夫链:一个前向过程会逐步通过添加高斯噪声在T个时间步内破坏数据 ,得到 ;另一个反向过程则学习一个参数化的分布,逐步去噪还原回数据流形。正式地,如图3所示,在前向过程中,给定数据分布 ,在每个时间步 ,数据 的加噪过程为:
其中 是噪声的方差超参数。在反向过程中,模型会逐步去噪数据,以逼近马尔可夫链的反向过程。反向转移过程 被参数化为:
其中网络对均值 和方差进行参数化。网络输入带噪数据与时间步,输出用于噪声预测的正态分布参数。噪声向量通过采样初始化,然后依次从学习得到的转移核 中采样,直到t=1。
训练目标是最小化负对数似然的变分下界,具体为:
其中 是模型在时间步t预测的噪声, 是该时间步真实加入的噪声。
早期的扩散模型采用U-Net架构来逼近得分函数[19]。U-Net设计基于宽残差网络(Wide ResNet),结合了残差连接与自注意力模块,以保持梯度流并恢复细粒度的图像细节。这些方法大致可分为像素级方法和潜特征级方法。
像素级方法直接在像素空间中执行扩散过程,包括引入“无分类器引导”的GLIDE[71]和使用预训练大语言模型T5XXL[23]作为文本编码器的Imagen[72]。然而,这些方法的训练与推理计算开销昂贵,促使了潜扩散模型(Latent Diffusion Models,LDMs)[14]的发展,LDMs在预训练变分自编码器的潜空间中运作,从而在保留高生成质量的同时显著提升了计算效率,进而激发了多种基于扩散的生成模型的诞生,如VQ-Diffusion[73]、SD 2.0[74]、SD XL[75]和UPainting[76]。
随着Transformer架构的进步,扩散过程中也开始采用基于Transformer的模型。开创性的Diffusion Transformers(DiT)[20]将输入图像切分为一系列patch,并通过多层Transformer模块处理。DiT还将扩散时间步t和条件信号c作为输入。 DiT的成功激励了众多先进生成方法的出现,包括将自监督视觉表示引入扩散训练以增强大规模表现的REPA[77],采用两组独立权重分别建模文本与图像模态的SD 3.0[15],以及其他方法[78],[79],[80]。这些方法通常利用对比学习将图像与文本模态对齐到共享潜空间,通过在大规模图文对齐数据上联合训练独立的图像与文本编码器[22],[53],[81]。
具体而言,GLIDE[71]探索了CLIP引导和无分类器引导,表明CLIP条件扩散优于早期GAN基线,并支持强大的文本驱动图像编辑。SD[14]使用冻结的CLIP-ViT-L/14编码器为其潜扩散去噪器提供条件,从而实现高质量、低计算的生成。SD 3.0[15]使用CLIP ViT-L/14、OpenCLIP bigG/14和T5-v1.1 XXL将文本转化为嵌入用于生成引导。
近期扩散模型的发展中,已引入大语言模型(LLMs)以提升文本到图像的扩散生成[82],[83],显著改善了文本-图像对齐与生成质量。 RPG[83]利用多模态LLMs的视觉-语言先验,从文本提示中推理出补充的空间布局,并在文本引导的图像生成与编辑过程中操控物体组合。
然而,这些方法通常针对特定任务需采用不同的模型架构、训练策略和参数配置,导致模型管理复杂。 一个更具扩展性的解决方案是采用统一生成模型,能够处理多种数据生成任务[84],[85],[86],[87]。
-
• OmniGen[84]不仅具备文本到图像生成能力,还支持图像编辑、主体驱动生成和视觉条件生成等下游任务。
-
• UniReal[85]将图像级任务视为不连续的视频生成,将不同数量的输入输出图像视为帧,从而无缝支持图像生成、编辑、定制与合成等任务。
-
• GenArtist[86]提供统一的图像生成与编辑系统,由多模态大语言模型(MLLM)代理协调。
-
• UniVG[87]则将多模态输入视为统一条件,仅用一套权重即可实现多种下游应用。
随着该领域研究的持续推进,预计未来将涌现出更多能够涵盖更广泛图像生成与编辑任务的统一模型。
自回归模型。自回归(Autoregressive,AR)模型通过将序列的联合分布因式分解为条件概率的乘积来建模序列,其中每个元素都是基于之前已生成的所有元素逐步预测的。这一范式最初是为语言建模而设计的,但已被成功地扩展到视觉领域,通过将图像映射为一维的离散标记序列(像素、patch或潜在编码)来实现。形式上,给定一个序列 ,模型的训练目标是通过对所有先前元素进行条件建模来逐个生成每个元素:
。
其中 是模型参数。训练目标是最小化负对数似然(NLL)损失:
。
如图4所示,现有方法根据序列表示策略分为三类:
-
• 基于像素的方法
-
• 基于token的方法
-
• 基于多token的方法。
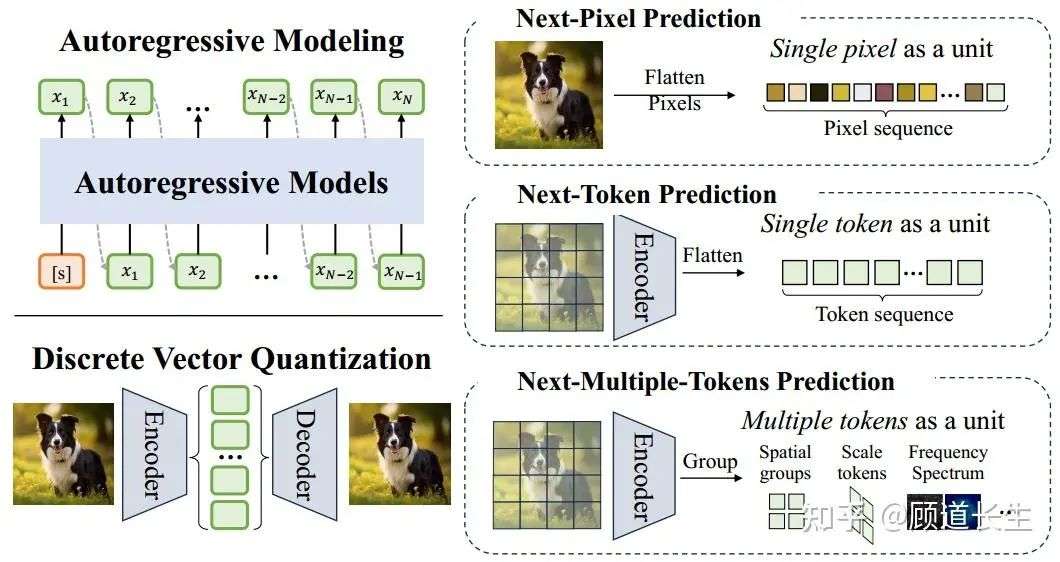
图4. 自回归模型中的核心组件示意图,包括自回归序列建模和离散向量量化。现有自回归模型大致可分为三类:下一像素预测(Next-Pixel Prediction)将图像展平成像素序列,下一token预测(Next-Token Prediction)通过视觉tokenizer将图像转换为token序列,而下一多token预测(Next-Multiple-Tokens Prediction)在每个自回归步骤中输出多个token。
1)基于像素的方法。PixelRNN [88] 是首个针对下一像素预测的开创性方法。该方法将二维图像转化为一维像素序列,并利用LSTM层按顺序生成每个像素,基于之前生成的像素值。尽管其在建模空间依赖性方面有效,但计算开销巨大。PixelCNN [89] 通过引入膨胀卷积更高效地捕捉长程像素依赖关系,而 PixelCNN++ [90] 则结合离散化逻辑混合似然和架构优化,提升了图像质量和效率。一些后续研究 [91] 还提出了并行化方法,以降低计算开销,尤其是针对高分辨率图像的快速生成。
2)基于token的方法。受自然语言处理范式启发,基于token的自回归(AR)模型将图像转换为紧凑的离散token序列,大幅缩短序列长度,从而支持高分辨率图像生成。该过程通常先进行向量量化(VQ):通过重构损失和承诺损失训练的编码器-解码器学习一个紧凑的token索引字典,随后使用仅含解码器的transformer对这些token的条件分布建模 [92]。典型的VQ模型包括 VQ-VAE-2 [93]、VQGAN [32]、ViT-VQGAN [94] 等 [95]、[96]、[97]。 许多研究致力于提升仅含解码器的transformer模型。
LlamaGen [24] 将VQGAN的tokenizer应用于LLaMA骨干网络 [1]、[2],在生成质量方面与DiT相当,且随着参数规模的增大性能进一步提升。与此同时,像DeLVM [98]这样的数据高效变体能在显著减少数据的前提下实现相当的保真度,AiM [26]、ZigMa [99] 和 DiM [100] 等模型则将Mamba [101]中的线性或门控注意力机制整合进来,实现了更快的推理速度和更优的性能。
为提升上下文建模能力,还提出了随机和混合解码策略,如 SAIM [102]、RandAR [103] 和 RAR [104] 通过随机打乱patch预测顺序以克服严格的光栅顺序偏差,而 SAR [105] 将因果学习推广至任意顺序和跳跃间隔。混合框架进一步融合不同范式,例如 RAL [106] 通过对抗性策略梯度缓解曝光偏差,ImageBART [107] 将层次化扩散更新与AR解码交替进行,DisCo-Diff [108] 则在扩散解码器中引入离散latent以实现最优的FID分数。
3)基于多token的方法。为提升生成效率,近年来的AR模型已从单token预测转向多token组预测,在不牺牲质量的前提下大幅加快了生成速度。Next Patch Prediction(NPP)[109] 将图像token聚合为高信息密度的patch-level token,显著缩短了序列长度。
类似地,Next Block Prediction(NBP)[110] 将分组扩展到更大的空间块,例如整行或整帧。Neighboring AR(NAR)[111] 提出局部“邻域”预测机制以向外扩展,Parallel Autoregression(PAR)[112] 则将token划分为不相交子集以并行解码。MAR [25] 放弃了离散token和固定顺序,转而采用基于扩散损失的连续表示。
除了空间分组外,VAR [113] 提出粗到细的多尺度预测范式,进一步催生了一系列高级方法,如 FlowAR [114]、M-VAR [115]、FastVAR [116] 和 FlexVAR [117]。部分频域方法采用频谱分解策略:FAR [118] 和 NFIG [119] 先生成低频结构,再精细化高频细节。xAR [120] 则抽象统一了patch、像元、尺度乃至整幅图像等自回归单元,在单一框架下实现泛化。这些基于多token的方法展示了定义合适自回归单元在保真度、效率和可扩展性方面的重要性。
控制机制也被整合进自回归解码器,以实现更精准的编辑。ControlAR [121] 在解码过程中引入了边缘图、深度线索等空间约束,实现细粒度的token级编辑控制。ControlVAR [122] 在此基础上引入尺度感知条件,提升了图像整体的一致性与可编辑性。 CAR [123] 进一步发展了该概念,专注于在自回归模型中引入高级控制机制,以增强视觉输出的细节和可控性。对于涉及多物体或时序一致性场景的复杂任务,Many-to-Many Diffusion(M2M)[124] 将自回归框架扩展至多帧生成,确保图像间的语义与时间一致性。MSGNet [125] 结合VQ-VAE与自回归建模,在场景中多个实体之间维持空间语义对齐。
在医学领域,MVG [126] 将自回归图像生成扩展至图像分割、图像合成和去噪等任务,通过引入成对的提示图像输入进行条件建模。 这些基于自回归的文本到图像生成方法奠定了模型架构和视觉建模方法的基础,切实推动了面向理解与生成的统一多模态模型研究。
表1 统一多模态理解与生成模型概览。本表根据模型的骨干架构、编码器-解码器结构以及所使用的扩散模型或自回归模型对各模型进行了分类。表中包含模型名称、所用编码器、解码器以及在图像生成中使用的掩码信息。此外,还列出了这些模型的发布时间,以展示多模态架构随时间的演进过程。
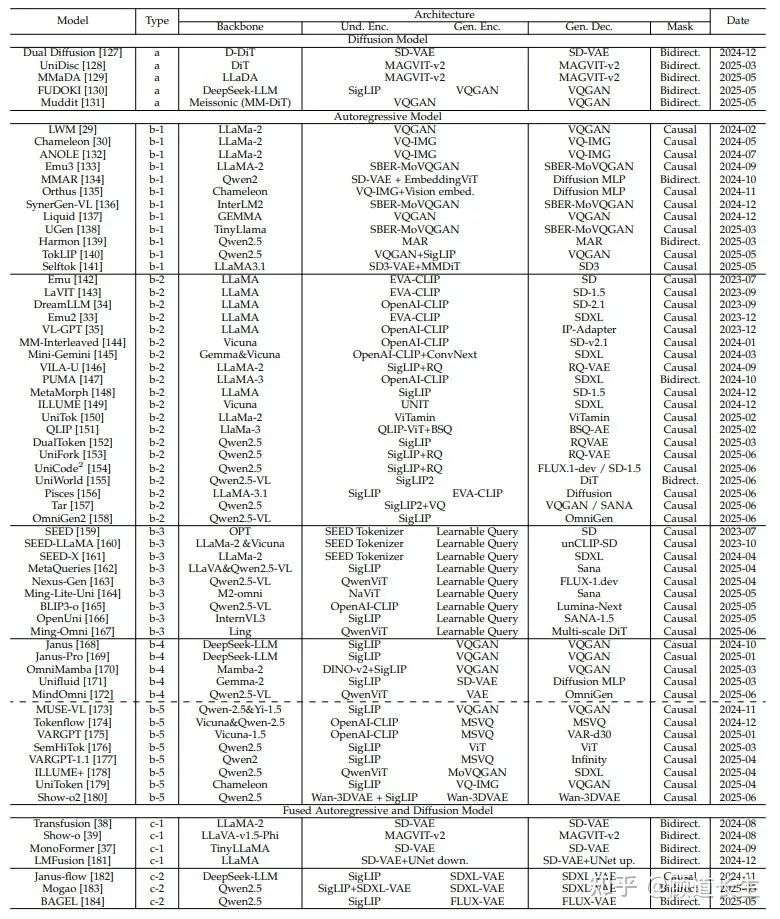
表1
03UNIFIED MULTIMODAL MODELS FOR UNDERSTANDING AND GENERATION
统一多模态模型旨在构建一个能够跨多个模态理解和生成数据的单一架构。这些模型被设计用于处理多种形式的输入(例如,文本、图像、视频、音频),并以统一的方式生成一个或多个模态的输出。一个典型的统一多模态框架可以抽象为三个核心组件:特定模态的编码器,将不同的输入模态投射到表示空间;一个模态融合骨干网络,集成来自多个模态的信息并启用跨模态推理;以及特定模态的解码器,用于生成所需模态的输出(例如,文本生成或图像合成)。
在本节中,我们主要关注支持视觉-语言理解和生成的统一多模态模型,即接受图像和文本作为输入,并生成文本或图像作为输出的模型。如图5所示,现有的统一模型可以大致分为三种主要类型:扩散模型、自回归模型和融合的AR + 扩散模型。
对于自回归模型,我们进一步根据它们的模态编码方法将其分为四个子类别:基于像素的编码、基于语义的编码、可学习的查询编码和混合编码。这些编码策略代表了处理视觉和文本数据的不同方式,导致多模态表示的集成度和灵活性不同。融合的AR + 扩散模型根据模态编码分为两类:基于像素的编码和混合编码。这些模型结合了自回归和扩散技术的各个方面,提供了一种更统一和高效的多模态生成方法。
在接下来的章节中,我们将深入探讨每个类别:
-
• 第3.1节探讨基于扩散的模型,讨论它们在从噪声表示中生成高质量图像和文本方面的独特优势。
-
• 第3.2节聚焦于基于自回归的模型,详细说明不同编码方法如何影响其在视觉-语言任务中的表现。
-
• 第3.3节讨论融合的AR + 扩散模型,探讨这两种范式的结合如何增强多模态生成能力。
-
• 最后,我们扩展讨论到任何到任何的多模态模型,这种模型将此框架推广到视觉和语言之外,支持更广泛的模态,如音频、视频和语音,旨在构建通用的、通用的生成模型。
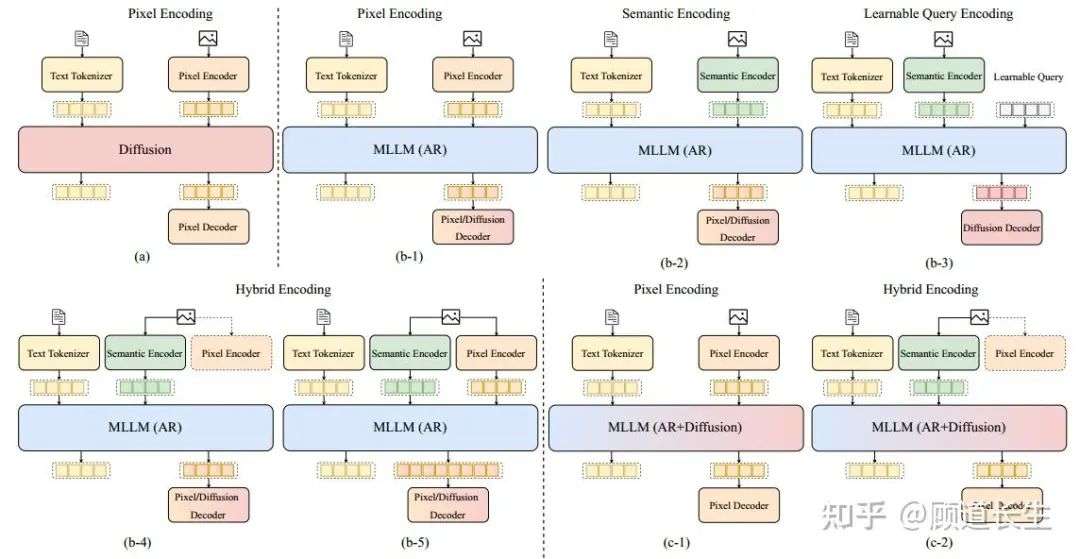
图5. 统一多模态理解与生成模型的分类。根据其骨干架构,模型分为三大类:扩散模型(Diffusion)、多模态大语言模型(MLLM)(自回归,AR)和多模态大语言模型(MLLM)(自回归+扩散)。每个类别进一步根据所采用的编码策略进行细分,包括像素编码、语义编码、可学习查询编码和混合编码。我们展示了这些类别内的架构变化及其对应的编码-解码器配置。
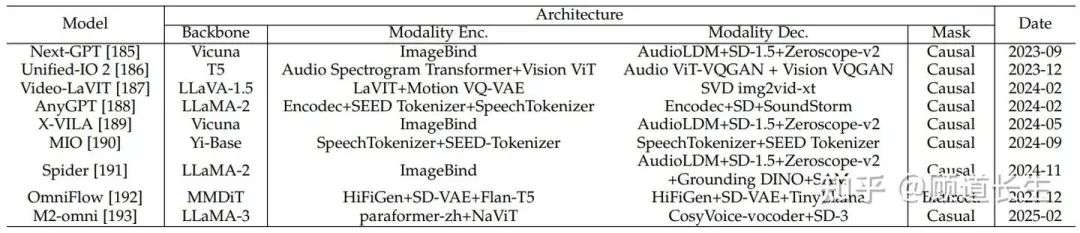
表2 支持超越图像和文本的任意模态输入/输出的多模态模型概览。此表对支持多种输入和输出模态(包括音频、音乐、图像、视频和文本)的模型进行了分类。表中包含模型的骨干架构、模态编码器与解码器、在视觉生成中所使用的注意力掩码类型,以及模型的发布时间。这些模型展示了近年来多模态交互向更广泛领域拓展的趋势。
3.1 Diffusion Models
扩散模型由于几个关键优势,在图像生成领域取得了显著成功。首先,与生成对抗网络(GANs)相比,扩散模型提供了更优的样本质量,具有更好的模式覆盖能力,并且能够缓解常见的问题,如模式崩溃和训练不稳定性[194]。其次,训练目标——从略微扰动的数据中预测添加的噪声——是一个简单的监督学习任务,避免了对抗动态的复杂性。第三,扩散模型具有很高的灵活性,允许在采样过程中融入各种条件信号,如分类器引导[194]和无分类器引导[195],这增强了可控性和生成的保真度。此外,噪声调度[196]和加速采样技术[197][198]的改进大大减少了计算负担,使得扩散模型变得越来越高效和可扩展。
利用这些优势,研究人员将扩散模型从单模态任务扩展到多模态生成,旨在支持在统一框架内同时生成文本和图像输出。如图5(a)所示,在多模态扩散模型中,去噪过程不仅依赖于时间步和噪声,还依赖于多模态上下文,例如文本描述、图像或联合嵌入。这种扩展使得不同模态之间的生成得以同步,并且允许生成输出之间实现丰富的语义对齐。
一个典型的例子是双重扩散模型(Dual Diffusion)[127],它引入了一个双分支的扩散过程,用于联合文本和图像生成。具体来说,给定一对文本和图像,双重扩散首先使用预训练的T5编码器[23]对文本进行编码,通过softmax概率建模获得离散的文本表示,并使用来自稳定扩散的VAE编码器[14]对图像进行编码,得到连续的图像潜变量。文本和图像潜变量分别通过独立的前向扩散过程进行加噪,最终在每个时间步得到噪声潜变量。
在反向过程中,模型使用两个模态特定的去噪器联合去噪文本和图像潜变量:一个基于Transformer的文本去噪器和一个基于UNet的图像去噪器。关键是,在每个时间步,去噪器都融入了跨模态的条件,其中文本潜变量关注图像潜变量,反之亦然,从而在去噪过程中的每个阶段实现模态之间的语义对齐。去噪后,文本潜变量通过T5解码器解码为自然语言,图像潜变量则通过VAE解码器解码为高质量的图像。
训练由两个不同的损失项监督:图像分支最小化标准的噪声预测损失,而文本分支最小化对比对数损失。通过将两个扩散链结合起来,并引入明确的跨模态交互,双重扩散模型能够从纯噪声中实现连贯且可控的多模态生成。
与Dual Diffusion [127]不同,后者通过Stable Diffusion [14]将离散文本扩散与连续图像扩散结合,UniDisc [128]采用了一个完全离散的扩散框架,从头开始训练一个扩散Transformer [199]。它使用LLaMA2 tokenizer [2] 对文本进行标记,并使用MAGVITv2编码器 [200] 将图像转换为离散的标记,从而在离散标记空间中实现了两种模态的统一。
这些标记经过离散的前向扩散过程,在此过程中,结构化的噪声同时作用于多模态。在反向过程中,UniDisc逐步去噪这些标记,生成一致的序列。然后,LLaMA2和MAGVIT-v2解码器将这些序列转换为高质量的文本和图像。通过采用完全离散的方法,UniDisc能够同时精炼文本和图像标记,提升推理效率并支持多样的跨模态条件。
与早期的离散扩散方法不同,FUDOKI [130]提出了一种基于离散流匹配 [201] 的新生成方法。在这一框架下,FUDOKI通过采用动力学最优的、度量诱导的概率轨迹来建模噪声和数据分布之间的直接路径。这一设计使得模型具备了一个连续自我校正机制,相较于早期方法中使用的简单掩蔽策略,具有明显优势。FUDOKI的模型架构基于Janus1.5B [168],但对其进行了必要的修改,以支持统一的视觉-语言离散流建模。
一个关键变化是将标准的因果掩蔽替换为全注意力掩蔽。这允许每个标记都能够关注其他标记,从而增强了全局上下文理解。尽管这一修改去除了显式的因果结构,模型仍然通过将输出logits向前移动一个位置来支持下一个标记预测。另一个重要的区别是在处理时间或污染水平时,FUDOKI不再依赖扩散模型中需要的显式时间步嵌入,而是直接从输入数据中推断污染状态。
继Janus-1.5B之后,FUDOKI解耦了理解和生成的处理路径。使用SigLIP编码器 [202] 来捕捉图像理解的高层语义特征,而来自LlamaGen [24] 的VQGAN-based tokenizer将图像编码为一系列低级离散标记,用于图像生成。在输出阶段,由Janus1.5B骨架生成的特征嵌入通过模态特定的输出头传递,产生最终的文本和图像输出。
类似地,Muddit [131]引入了一个统一的模型,用于处理文本和图像的双向生成,采用完全离散的扩散框架。其架构特征是一个单一的多模态扩散Transformer(MM-DiT),其架构设计类似于FLUX [203]。为了利用强大的图像先验,MM-DiT生成器是从Meissonic [204]初始化的,这是一种经过高分辨率合成训练的模型。两种模态都被量化为共享的离散空间,在该空间中,预训练的VQ-VAE [32]将图像编码为代码本索引,CLIP模型 [22]提供文本标记嵌入。在其统一训练过程中,Muddit采用余弦调度策略对标记进行掩蔽,单一的MM-DiT生成器被训练为预测在另一模态条件下的干净标记。对于输出,轻量级的线性头解码文本标记,而VQ-VAE解码器则重建图像,从而允许单一参数集处理文本和图像生成。
在此基础上,MMaDA [129]将扩散范式扩展到统一的多模态基础模型。它采用LLaDA-8B-Instruct [205]作为语言骨架,并使用MAGVIT-v2 [206]图像标记器将图像转换为离散的语义标记。这个统一的标记空间使得在生成过程中能够实现无缝的多模态条件。为了改善跨模态对齐,MMaDA引入了一种混合思维链(CoT)微调策略,将文本和视觉任务之间的推理格式统一。这种对齐促进了冷启动强化学习,使得从一开始就能有效地进行后期训练。
此外,MMaDA引入了一种新的UniGRPO方法,这是一种基于强化学习的统一策略梯度RL算法,专为扩散模型设计。UniGRPO通过利用多样化的奖励信号(如事实正确性、视觉-文本对齐和用户偏好)来实现推理和生成任务的后期训练优化。这个设计确保了模型在广泛的能力范围内持续改进,而不是过度拟合到某个狭窄的任务特定奖励。
尽管这些方法具有创新性,但在统一离散扩散模型领域仍然存在显著的挑战和局限性。主要问题之一是推理效率。尽管像Mercury [207]和Gemini Diffusion [208]这样的模型展示了高效并行标记生成的潜力,大多数开源离散扩散模型仍然落后于它们的自回归对手的实际推理速度。这一差异主要是由于缺乏对关键-值缓存的支持,以及在并行解码多个标记时输出质量下降的问题。扩散模型的有效性还受到训练困难的阻碍。
与自回归训练不同,在自回归训练中,每个标记都提供了学习信号,而离散扩散训练仅提供稀疏监督,因为损失是在随机选择的掩蔽标记子集上计算的,这导致训练语料库的使用效率低下且方差较大。此外,这些模型表现出长度偏向,并且难以在不同输出长度之间进行泛化,因为它们缺乏像自回归模型中那样的内置停止机制。
在架构和支持基础设施方面也需要进一步发展。架构上,许多现有模型复用了最初为自回归系统设计的架构,这一方法因工程简便性而被选择,但这种方法并不总是适合扩散过程,后者旨在以与自回归模型的顺序性质根本不同的方式捕捉联合数据分布。在基础设施方面,离散扩散模型的支持仍然有限。与自回归模型可用的成熟框架相比,它们缺乏成熟的管道和健全的开源选项。
这一差距阻碍了公平比较,减缓了研究进展,并使得实际部署变得复杂。解决推理、训练、架构和基础设施中的这些相互关联的挑战,对于推动统一离散扩散模型的能力和实际应用至关重要。
3.2 Auto-Regressive Models
统一多模态理解与生成模型的一个主要方向是采用自回归(AR)架构,在该架构中,视觉和语言的token通常被序列化,并依次建模。在这些模型中,通常基于大型语言模型(LLMs)如LLaMA系列 [1],[2],[209]、Vicuna [58]、Gemma系列 [210],[211],[212] 和Qwen系列 [5],[6],[9],[10] 所改编的Transformer骨干网络,作为统一的模态融合模块,用于自回归地预测多模态输出。
为了将视觉信息融入AR框架,如图5所示,现有方法在模态编码中提出了不同的图像token化策略。 这些方法大致可分为四类:像素级编码、语义级编码、可学习查询编码和混合编码方法。
1)像素级编码。 如图5(b-1)所示,像素级编码通常指的是通过纯图像重建监督的预训练自动编码器(如VQGAN类模型 [32],[213],[214],[215])将图像表示为连续或离散token。这些编码器将高维像素空间压缩为紧凑的潜在空间,其中每个空间patch对应一个图像token。在统一多模态自回归模型中,从此类编码器序列化的图像token与文本token类似地处理,使得两种模态可在单个序列中建模。
近期的研究在各种编码器设计中采用并增强了像素级token化方法。LWM [29] 使用VQGAN tokenizer [32] 将图像编码为离散潜在代码,无需语义监督。它提出了一个多模态世界建模框架,将视觉和文本token序列化在一起,实现统一的自回归建模。通过仅利用基于重建的视觉token和文本描述学习世界动态,LWM展示了无需特定语义token化也能实现大规模多模态生成。
Chameleon [30] 和ANOLE [132] 都采用了VQ-IMG [215],这是一种为内容丰富的图像生成设计的改进版VQ-VAE,相比标准VQGAN tokenizer,VQ-IMG 具备更深的编码器、更大的感受野,并引入残差预测,以更好地保留复杂的视觉细节。这一增强使Chameleon和ANOLE更忠实地序列化图像内容,从而支持高质量多模态生成。
此外,这些模型还支持交错生成,允许在统一的自回归框架中交替生成文本和图像token。Emu3 [133]、SynerGen-VL [136] 和UGen [138] 采用了SBER-MoVQGAN [213],[214],这是一种多尺度VQGAN变体,可将图像编码为同时捕捉全局结构和细节的潜在表示。通过多尺度token化,这些模型提升了视觉表示的表达能力,同时保持了高效的训练吞吐量。与LWM [29] 类似,Liquid [137] 使用了VQGAN风格的tokenizer,并提出了一个新见解:当视觉理解与生成在单一自回归目标和共享视觉token表示下统一时,这两者能相互促进。
此外,MMAR [134]、Orthus [135]、Harmon [139] 提出了利用连续值图像token的框架,这些token由对应的编码器提取,避免了离散化带来的信息损失。它们还通过在每个自回归图像patch嵌入顶部引入轻量级扩散头,将扩散过程与AR骨干解耦。这一设计确保了骨干网络的隐藏表示不局限于最终去噪步骤,有利于更好的图像理解。TokLIP [140] 将低层离散VQGAN tokenizer与ViT基础的token编码器SigLIP [202]结合,捕获高层连续语义,从而在赋予视觉token高层语义理解能力的同时,也增强了低层生成能力。Selftok [141] 提出了一种新颖的离散视觉自一致tokenizer,在高质量重建与压缩率之间实现了有利权衡,并促进了有效的视觉强化学习中的最优策略改进。
除MMAR [134] 和Harmon [139] 外,这些模型在预训练和生成阶段均应用了因果注意力掩码,确保每个token仅关注序列中的先前token。它们通过next-token预测损失进行训练,同时预测图像和文本token,从而在模态间实现统一的训练目标。值得注意的是,在像素级编码方法中,用于从潜在token重建图像的解码器通常遵循VQGAN类模型最初提出的成对解码器结构。 这些解码器是专门优化的轻量级卷积架构,主要用于将离散潜在网格映射回像素空间,侧重于准确的低层重建,而非高层语义推理。
此外,由于一些方法(如MMAR [134]、Orthus [135] 和Harmon [139])将图像token化为连续潜在表示,它们采用了轻量级扩散MLP作为解码器,将连续潜在表示映射回像素空间。 尽管像素级编码方法在实践中有效,但仍存在几个内在局限性:首先,视觉token仅为像素级重建而优化,通常缺乏高层语义抽象能力,使得文本与图像表示之间的跨模态对齐更具挑战性。
其次,像素级token化倾向于生成稠密的token网格,尤其在高分辨率图像中,相比纯文本模型显著增加了序列长度,从而在自回归训练和推理过程中带来巨大的计算和内存开销,限制了可扩展性。第三,由于底层视觉编码器是通过重建中心目标进行训练的,生成的视觉token可能保留模态特定偏差,如对纹理和低层模式的过度敏感,这并不一定适用于语义理解或细粒度的跨模态推理。
2)语义编码。为克服像素级编码器固有的语义局限性,越来越多的工作采用语义编码方法,如图5(b-2)所示,该方法利用预训练的文本对齐视觉编码器(如OpenAI-CLIP [22]、SigLIP [202]、EVA-CLIP [36] 或更新的统一tokenizer如UNIT [216])处理图像输入。一些模型还利用多模态自回归模型编码的多模态特征,作为扩散模型的条件,从而在保留多模态理解能力的同时实现图像生成,例如OmniGen2 [158],该模型利用Qwen2.5-VL [10] 作为多模态模型,增强的OmniGen [217] 作为图像扩散模型。然而,大多数此类模型是在大规模图文对齐数据集上以对比学习或回归目标进行训练,从而生成与语言特征高度对齐的视觉嵌入,这些表示促进了跨模态对齐,特别适合多模态理解与生成。
多种代表性模型采用不同的语义编码器与架构设计来支持统一多模态任务。Emu [142]、Emu2 [33] 和LaViT [143] 均采用EVA-CLIP [36] 作为视觉编码器。Emu [142] 首次提出架构,将冻结的EVA-CLIP编码器、大语言模型以及扩散解码器结合,实现VQA、图像描述和图像生成统一。Emu2 [33] 在Emu [142] 基础上提出简化且可扩展的统一多模态预训练框架,将MLLM扩展至37B参数,大幅提升理解与生成能力。
LaViT [143] 在EVA-CLIP基础上引入动态视觉token化机制,通过selector和merger模块根据图像复杂度自适应选择视觉token,动态确定每幅图像的视觉token序列长度,有效减少冗余信息,同时保留关键信息,提升了训练效率和生成质量,适用于图像描述、视觉问答和图像生成等任务。
DreamLLM [34]、VL-GPT [35]、MMInterleaved [144] 和PUMA [147] 则采用OpenAI-CLIP [22] 编码器。DreamLLM [34] 通过轻量线性投影对齐CLIP嵌入与文本token,VL-GPT [35] 则在OpenAI-CLIP视觉编码器之后引入强大的因果Transformer,有效保留原图语义信息和像素细节。MM-Interleaved [144] 和PUMA [147] 通过CLIP tokenizer结合简单的ViT-Adapter或池化操作,提取多粒度图像特征,从而实现细粒度特征融合,支持丰富的多模态生成。
Mini-Gemini [145] 提出视觉token增强机制,使用双语义编码器:CLIP预训练的ViT编码器获取全局视觉token,LAION预训练的ConvNeXt编码器提取局部密集信息,再通过交叉注意力模块融合,提升全局token的细节表现,然后与文本token共同输入LLM进行联合视觉-语言理解与生成,有效桥接CLIP特征的语义抽象与密集编码器的像素精度。 MetaMorph [148] 使用SigLIP [202] 提取视觉嵌入,在预训练语言模型中引入模态特定适配器(adapter),在多个Transformer层内深度融合视觉-语言信息。
ILLUME [149] 则采用UNIT [216] 作为视觉编码器,提供兼具语义对齐与像素保真度的统一表示。不同于仅基于对比目标的CLIP类编码器,UNIT [216] 同时结合图像重建与对比对齐损失进行联合训练,生成既适合视觉-语言理解,又适合图像生成的token。基于UNIT tokenizer,ILLUME 能高效生成同时保留语义与像素信息的视觉token,在图像描述、VQA、文本生成图像和交错生成等多个任务中表现出色。
类似地,VILA-U [146] 和UniTok [150] 借鉴UNIT [216],引入图文对比学习,得到兼具语义对齐与像素保真度的视觉tokenizer。QLIP [151] 通过二值球面量化解决重建与图文对齐任务间的冲突。Tar [157] 利用LLM词汇初始化视觉codebook,引入尺度自适应池化与解码机制,根据需求调整tokenizer长度:粗粒度用于高效生成,细粒度用于全面理解,并在生成阶段结合扩散技术提升图像生成质量。
UniFork [153] 基于VILA-U的文本对齐视觉特征,不同于完全共享参数的MLLM,UniFork 仅在浅层共享参数,深层则采用专用网络,在共享学习与任务特化间取得平衡。UniCode2 [154] 采用级联codebook,首先以SigLIP特征聚类的固定codebook为基础,再引入可学习的补充codebook,增强语义细化与泛化能力。最新工作DualToken [152] 利用SigLIP浅层特征进行重建,深层特征进行语义学习,同时获取纹理与语义特征,在下游MLLM任务中表现优异。
这些模型大多在MLLM训练中应用因果注意力掩码,使用next-token预测损失同时优化文本与视觉token生成。在图像生成方面,大部分模型采用扩散解码器,如SD系列 [14],[219]、IP-adapter [220]、FLUX [16] 和Lumina-Next [221],这些解码器与MLLM独立训练。 推理时,MLLM生成语义级视觉token,然后输入扩散解码器进行最终图像合成。之所以选择“语义编码器+扩散解码器”的设计,主要原因是语义嵌入包含高层概念信息,但缺乏用于直接像素重建的空间密度与细节粒度。
扩散模型的迭代去噪机制尤其适合此类场景:即使输入token稀疏或抽象,仍能逐步细化语义表示,生成高分辨率、逼真的图像。相比之下,虽然VILA-U [146] 和UniTok [150] 少数模型尝试采用像素级解码器,但其图像质量仍不及扩散解码器。因此,扩散解码器为语义压缩视觉token提供了更健壮、表现力更强的解码路径,大幅提升文本-图像对齐、全局一致性与视觉保真度。
UniWorld [155] 和Pisces [156] 致力于此类方案的扩展与优化。UniWorld 直接使用预训练MLLM输出特征作为DiT的高层条件信号,同时利用SigLIP提供低层条件信号,实现全面的视觉语义控制。Pisces 采用EVA-CLIP作为视觉生成任务条件,通过扩散进一步增强生成效果,针对不同任务引入灵活的视觉向量长度与专用MLP编码器,在提升模型设计灵活性的同时,降低相较单一编码器配置的推理成本。
尽管语义编码具备诸多优势,但也存在一定局限性:首先,由于低层细节被抽象,生成的视觉token在像素层面缺乏可控性,难以实现精细图像编辑、局部修复或结构保持转换。其次,语义编码器通常仅提供全局或中层表示,难以满足空间对应需求(如指称表达分割或精确姿态合成)。最后,由于语义编码器与扩散解码器通常独立训练,缺乏端到端优化,可能导致MLLM输出与解码器预期不匹配,偶尔引发语义漂移或生成伪影。
3)可学习查询编码。可学习查询编码已成为生成自适应、任务相关图像表示的有效策略。如图5(b-3)所示,该方法不再依赖固定视觉tokenizer或密集图像patch,而是引入一组可学习的查询token,动态从图像特征中提取有用内容。这些查询token充当内容感知探测器,与视觉编码器交互,生成紧凑且语义对齐的嵌入,适用于多模态理解与生成。
当前可学习查询编码方法大致可分为两大代表性范式:
-
• 第一类由SEED [159] 代表,其提出了seed tokenizer学习因果视觉嵌入。具体而言,输入图像首先通过BLIP-2 ViT编码器 [53] 编码为密集token特征,随后与一组可学习查询token拼接,并通过因果Q-Former处理,生成因果视觉嵌入。该设计结合图文对比学习与图像重建监督共同训练,使得生成的嵌入同时保留低层视觉细节与高层语义对齐能力。基于此,SEEDLLAMA [160] 和SEED-X [161] 进一步增强模型能力,将OPT主干 [222] 替换为更强大的LLaMA2模型 [2],并升级解码器为UnCLIPSD [14] 或SDXL [219],显著提升了理解与生成性能。
-
• 第二类方法由MetaQueries [162] 提出,提供了更简化的可学习查询编码方案。该方法首先通过冻结的SigLIP编码器 [202] 提取图像特征,然后与可学习查询token拼接,直接输入冻结的视觉语言主干模型(如LLaVA [209] 或Qwen2.5-VL [10])。输出的因果嵌入被用作扩散图像解码器的条件输入,实现高质量图像生成。由于主干保持冻结,模型的视觉语言理解能力与预训练模型保持一致,提供了轻量高效的多模态生成方案。
OpenUni [166] 在MetaQueries架构基础上优化,完全采用可学习查询token,并在MLLM与扩散模型之间仅使用轻量连接器,实现紧凑的多模态理解与生成。OpenUni展示了该连接器可以极度简化,例如仅需6层Transformer即可实现高效连接。
Nexus-Gen [163] 和Ming-Lite-Uni [164] 继承MetaQueries范式,并在多模态生成方面实现了显著提升。NexusGen [163] 引入更强大的扩散解码器FLUX-1.dev,大幅提升了图像生成质量,使模型更好捕捉复杂细节与高保真特征。Ming-Lite-Uni [164] 则引入强大的MLLM模型M2-omini [193],实现高级视觉-语言交互,该模型通过先进的视觉-语言条件生成机制,提升条件图像嵌入的语义对齐能力。此外,Ming-Lite-Uni在扩散模型中引入多尺度可学习token,增强跨尺度语义对齐能力,能更好地从文本提示生成细致、上下文丰富的图像,有效缓解分辨率不匹配与语义不一致问题,使其在多模态理解与生成中表现出色。
Ming-Omni [167] 采用集成MoE架构,通过为每个token专门设计的路由机制实现模态特定路由,从而实现定制化的路由分布。为应对视觉生成中的多尺度现象 [113],Ming-Omni引入多尺度可学习查询token,通过对齐策略逐层生成从粗到细的图像。此外,Ming-Omni整合了音频模态,实施双阶段训练策略,以缓解音频理解与生成任务之间的相互影响:第一阶段侧重理解能力,第二阶段专注于提升生成质量。
BLIP3-o [165] 亦采用可学习查询token以桥接多模态理解与生成,但其设计使用两个扩散模型:一个用于学习CLIP嵌入,另一个则以CLIP为条件生成图像。该方法发现流匹配损失优于MSE损失,能带来更多样化的图像采样与更优的图像质量。
综上,这些基于可学习查询的方法具有共同优势:它们能生成自适应、紧凑且语义丰富的表示,既支持高效图像理解,又能实现高质量生成。通过专注于任务驱动的token提取,这些模型为统一多模态框架提供了灵活且可扩展的替代方案。
尽管具有灵活性与优异性能,可学习查询编码仍存在一些限制,可能影响其广泛应用。首先,核心挑战在于可学习查询token带来的额外计算开销。随着查询token数量增加,模型的内存消耗与计算复杂度显著上升,尤其在扩展至大规模数据集或更复杂多模态任务时尤为明显。此外,使用固定编码器(如MetaQueries中的方法)可能在面对与预训练数据分布差异较大的新颖或复杂视觉输入时,限制模型的灵活性。
其次,SEED [159] 和MetaQueries [162] 等方法依赖冻结或预训练主干,可能限制视觉特征对下游任务的适应性。虽然冻结主干可降低训练成本并保留已有知识,但也会限制模型根据任务动态调整图像特征与查询token语义对齐的能力,尤其在复杂或组合型场景中更为明显。
最后,尽管可学习查询能够高效提取任务相关内容,但在处理多样化视觉内容时未必始终表现出色。例如,面对复杂场景(如多物体、细粒度细节或含糊视觉线索),少量查询token可能难以全面捕捉视觉输入中的丰富性与多样性,尤其是在要求生成高度细节化输出的任务中,固定或有限数量的查询token可能无法覆盖所有关键信息。
4)混合编码。为解决单一视觉表示方法的固有限制,统一多模态模型中引入了混合编码策略。像素级编码方法(如VQVAE或VQGAN)在保留细节方面表现优异,但往往缺乏与文本的语义对齐能力;相反,语义编码器(如SigLIP或CLIP变体)能够生成语义丰富的抽象表示,但难以保留低层图像细节。
混合编码旨在融合这两类方法的优势,将像素层次与语义层次特征整合为统一表示。根据像素token与语义token的整合方式,混合编码方法大致分为伪混合编码与联合混合编码两类。
伪混合编码。典型方法包括Janus [168]、Janus-Pro [169]、OmniMamba [170]、Unifluid [171] 与MindOmni [172]。如图5(b-4)所示,这些模型采用双编码器——通常为语义编码器(如SigLIP)与像素编码器(如VQGAN或VAE),但按任务特异性使用。
训练时,语义编码器用于视觉-语言理解任务,像素编码器用于图像生成任务。尽管双编码器在联合理解与生成数据集上同时训练,但推理阶段中理解任务仅启用语义编码器,文本生成图像时仅启用像素编码器。然而,在图像编辑任务中,Unifluid [171] 使用语义编码器编码源图像,MindOmni [172] 同时使用VAE与语义编码器编码源图像。这种设计的核心动机在于,通过混合数据联合训练,提升理解与生成任务的整体性能。然而,由于推理时仅启用单一编码器,这类方法未能充分发挥混合编码的潜力,既无法在生成中利用语义引导,也无法在理解中利用高保真细节。
因此,这类模型通常使用像素解码器将潜变量重建为图像。
联合混合编码。如图5(b-5)所示,联合混合编码方法将语义与像素token整合为统一输入,供语言模型或解码器同时使用,从而在推理时同步利用两种表示。这类方法的融合策略存在差异。
MUSE-VL [173] 与UniToken [179] 将SigLIP与VQGAN特征沿通道维度拼接后输入LLM。Tokenflow [174] 则采用双编码器与共享映射的双码本结构,实现高层语义与低层像素细节的联合优化。VARGPT [175]、VARGPT-1.1 [177] 与ILLUME+ [178] 将语义与像素token在序列维度拼接,确保LLM输入中同时保留两种token。SemHiTok [176] 提出语义引导的层次码本(SGHC),兼具语义信息与纹理信息,既可保留语义,又能实现像素重建。
值得注意的是,与上述方法直接使用独立网络分支处理图像不同,Show-o2 [180] 针对3DVAE [223] 生成的潜特征,使用独立网络分支,并通过时空融合模块整合各分支输出,从而同时捕捉低层与高层视觉信息。然而,该操作可能导致细微语义信息损失,因为Show-o2中的3DVAE会对图像或视频进行有损压缩,可能在语义细节处理上表现欠佳。
通过同时整合语义与视觉细节信息,联合混合编码实现了更强大的多模态理解与生成能力。
这些模型支持像素解码器(如VQGAN、Infinity [224]、VAR-D30 [113])与扩散解码器(如SDXL [219]),能生成语义对齐度高、视觉真实感强的图像。
尽管混合编码通过整合像素与语义的互补优势展现出良好前景,但仍面临多重挑战。首先,大多数伪混合方法在推理时无法同时利用两类编码器,导致未能充分发挥细节与语义的协同潜力。即使是联合混合方法,不同类型token的融合也可能引发模态失衡或冗余,若融合策略不当,可能影响下游任务表现。
此外,双编码器架构会显著增加计算与内存开销,特别是在高分辨率或长序列场景下,扩展性面临较大挑战。对齐像素token与语义token亦非易事,隐式的不匹配可能导致表征不一致或学习信号冲突。
最后,当前混合编码方法普遍假设像素token与语义token隐式对齐,但在实际训练中,这种对齐难以保证,尤其在数据稀缺或噪声数据环境中,更易出现监督冲突或表征失真问题。
3.3 Fused Autoregressive and Diffusion Models
融合自回归(AR)和扩散建模最近成为统一的视觉-语言生成的强大框架。在这一范式中,文本token是自回归地生成的,保持了大语言模型的组合推理优势,而图像token通过多步去噪过程生成,遵循扩散建模原则。这种混合策略使得图像生成可以以非序列化的方式进行,从而提高了视觉质量和全局一致性。
代表性模型如Transfusion [38]、Show-o [39]、MonoFormer [37]和LMFusion [181]都采用了这种方法。在生成过程中,噪声被添加到潜在的视觉表示中,并通过迭代方式去除,过程受先前生成的文本或完整跨模态上下文的条件。尽管这种设计由于多个采样步骤增加了推理成本,但它在符号控制和视觉保真度之间达到了有效的折衷,使其非常适合高质量的视觉-语言生成任务。现有的融合AR + 扩散模型通常采用两种图像token化策略之一:像素级编码和混合编码。
像素级编码:如图5(c-1)所示,像素级编码将图像转化为离散的token或连续的潜在向量,然后作为目标用于基于扩散的去噪过程,条件为自回归生成的文本token。在最近的工作中,Transfusion [38]、MonoFormer [37] 和 LMFusion [181] 都采用了通过SD-VAE提取的连续潜在表示。这些模型共享一个共同的训练目标,结合了语言建模的自回归损失和图像重建的扩散损失,并利用双向注意力来实现空间一致性。
尽管共享这一框架,每个模型都引入了不同的架构创新:Transfusion [38] 提出了一个统一的transformer骨干架构,具有特定模态的层,用于同时处理离散和连续输入;MonoFormer [37] 引入了一个紧凑的架构,采用共享块和任务相关的注意力掩蔽,以平衡AR和扩散任务;LMFusion [181] 使得冻结的LLM能够通过轻量级的视觉注入模块执行高质量的图像生成,在训练时只训练视觉分支。
相比之下,Show-o [39] 使用基于MAGVIT-v2 [206] 的离散像素级token化器,生成与transformer风格解码兼容的符号图像token。它支持基于AR的文本token生成和基于扩散的图像合成,通过自回归和扩散损失的组合进行监督。这些模型共同展示了像素级编码在平衡来自语言模型的语义控制和来自扩散过程的高分辨率视觉保真度方面的有效性。
尽管效果显著,融合AR和扩散框架中的像素级编码方法也面临若干局限性。首先,依赖于连续潜在空间的模型(例如通过SD-VAE)由于扩散采样的迭代特性和需要高维特征处理,在训练和推理期间引入了显著的计算开销。当扩展到高分辨率图像生成或多轮视觉-语言交互时,这一问题尤为突出。
其次,文本和视觉模态之间的对齐仍然具有挑战性。尽管双向注意力机制能够实现跨模态融合,但潜在空间的表示,特别是通过SD-VAE中的无监督重建目标学习的表示,可能并不总是与语义上有意义的语言token进行最优对齐,可能导致较弱的细粒度控制能力或生成结果不易解释。最后,Show-o中使用的离散token化方案继承了VQ模型的诸多问题,如代码本崩溃和表示细微视觉细节的能力有限。这些符号token虽然与transformer风格的建模兼容,但可能会限制视觉多样性,并减少相较于连续潜在方法的重建保真度。
混合编码:如图5(c-2)所示,混合编码将语义特征(例如来自CLIP或ViT编码器)和像素级潜在表示(例如来自SD-VAE)融合,提供更具表现力的图像表示。这种方法使得模型在保持详细视觉信息的同时,可以利用高层次的语义抽象。
具体而言,Janus-flow [182]、Mogao [183]和BAGEL [184]采用双编码器架构,并提出了一种简约架构,将AR语言模型与修正流结合起来。它们解耦了理解和生成编码器,使用SigLIP或SigLIP与SDXL-VAE的连接作为视觉编码器用于多模态理解,SDXL-VAE或FLUX-VAE用于图像生成。然而,伪混合编码设计限制了模型在生成过程中同时利用语义和像素级特征的能力,因为在图像合成过程中只有像素编码器处于激活状态。
这种解耦,虽然有利于模块化和训练效率,但在图像解码过程中阻止了模型充分利用语义提示,可能削弱细粒度对齐和多模态组合能力。
尽管取得了进展,混合编码方法仍面临几个挑战。双编码器架构和自回归与扩散过程的结合增加了模型的总体复杂性。这可能导致更高的计算成本和更长的训练时间,使得它们在效率上不如简单的模型。此外,确保语义和像素级特征之间的有效对齐需要仔细的架构设计和优化。这个对齐过程可能难以实现和微调,限制了模型在平衡地利用两种模态方面的能力。
此外,在一个统一的模型中平衡视觉-语言理解和图像生成的目标通常会导致折衷,即改进某一任务可能会以牺牲另一任务为代价。这些局限性凸显了需要更高效的混合设计,以便在减少计算开销的同时,能够更好地利用视觉和语义特征的优势,并保持任务之间的高性能。
3.4 Any-to-Any Multimodal Models
尽管早期的统一多模态模型主要关注文本-图像对,近年来的研究已经扩展到任何对任何的多模态建模。这一雄心勃勃的方法旨在创建能够处理和生成各种模态的模型,包括音频、视频、语音、音乐等。 这些模型旨在将特定模态的编码器和解码器统一在一个架构中,使任务能够跨模态生成,例如文本到音频、视频到文本、语音到音乐甚至图像到视频生成。本节回顾了这一新兴领域的代表性工作,重点介绍了它们的设计原则、模块化以及当前的局限性。
大多数任何对任何模型遵循模块化设计,每个模态配有一个专门的编码器和解码器,而共享的骨干网络促进跨模态表示学习和序列建模。例如,OmniFlow [192] 集成了 HiFiGen [225] 进行音频和音乐生成,SD-VAE [14] 进行图像处理,并使用类似DiT的扩散模型(MMDiT)[15]作为骨干网络。 这种模块化设计使得模型能够有效地结合不同模态进行复杂的生成任务。
一些模型依赖于共享的嵌入空间来在特征级别统一不同的模态。例如,Spider [191]、X-VILA [189] 和 Next-GPT [185] 利用ImageBind——一个通过对比训练的模型,将六种模态(文本、图像、视频、音频、深度和热成像)映射到一个共享的嵌入空间。这个统一的表示使得通过特定模态的解码器(如Stable Diffusion [14]、Zeroscope或基于LLM的文本解码器[1])进行灵活的条件生成成为可能。虽然这种方法在理论上优雅,但它的生成能力通常受到解码器质量和共享嵌入粒度的限制。
其他模型,如AnyGPT [188] 和Unified-IO 2 [186],扩展了序列到序列的范式,以处理多模态。AnyGPT [188] 使用EnCodec [226] 进行音频token化,SpeechTokenizer [227] 处理语音,并训练一个统一的Transformer,具有特定模态的前缀。而Unified-IO 2 [186] 则采用更结构化的编码器-解码器设计,包含视觉、音频和语言模态,支持如AST到文本、语音到图像或视频字幕等任务,在一个模型中实现。
最近,M2-omni [193] 是任何对任何统一多模态模型的一个重要新增,它引入了一个高度灵活的架构,能够处理和生成各种模态,包括文本、图像、视频和音频。M2-omini通过集成多个特定模态的token化器和解码器,每个解码器都专门设计用来处理不同数据类型的独特特性,迈出了重要的一步。具体来说,它利用NaViT [228] 对任意分辨率的视频和图像进行编码,并将预训练的SD-3 [219] 作为图像解码器。对于音频,M2-omini引入paraformerzh [229] 来提取音频token,并将预测的离散音频token传入预训练的CosyVoice [230] 流匹配和声码器模型生成音频流。
这种集成确保了M2-omini能够有效地从各种输入生成高质量的图像和音频流,使其成为一个真正的多模态强大工具。
尽管取得了有希望的进展,当前的任何对任何模型仍然面临几个挑战。一个关键问题是模态不平衡,文本和图像模态通常占主导地位,而音频、视频和音乐等模态的代表性不足,这限制了这些模型可以处理的任务的多样性。另一个挑战是可扩展性,支持多种模态会增加模型的复杂性,从而导致更高的推理延迟和更大的资源需求。此外,确保跨模态的一致性仍然是一个复杂的任务,模型常常在保持生成输出的一致性和对齐性方面遇到困难。
这些挑战代表了任何对任何多模态模型开发中的持续研究方向。
尽管如此,这些模型代表了朝着开发能够理解和生成全方位人类感官输入和交流的通用基础模型迈出的关键一步。随着数据、架构和训练范式的演变,未来的任何对任何模型有望变得更加可组合、高效,并能够真正实现跨模态的通用生成。
04DATASETS ON UNIFIED MODELS
大规模、高质量、多样化的训练数据是构建强大统一多模态理解与生成模型的基石。这些模型通常需要在大量图文对上进行预训练,以学习跨模态的关联性和表示能力。需要注意的是,在进行大规模多模态数据预训练之前,这些模型通常会先在大规模自然语言语料库(如Common Crawl、RedPajama [281]、WebText [282]等)上初始化参数。由于本综述主要关注多模态模型,本节将不讨论纯文本数据。
根据主要用途和模态特征,常用的预训练多模态数据集大致可以分为以下几类:
-
• 多模态理解数据集
-
• 文本到图像生成数据集
-
• 图像编辑数据集
-
• 图文交错数据集
-
• 其他基于文本和图像共同条件的图像生成数据集
本节将详细介绍表3中列出的各类别具有代表性的数据集,重点关注2020年及以后发布的数据集。
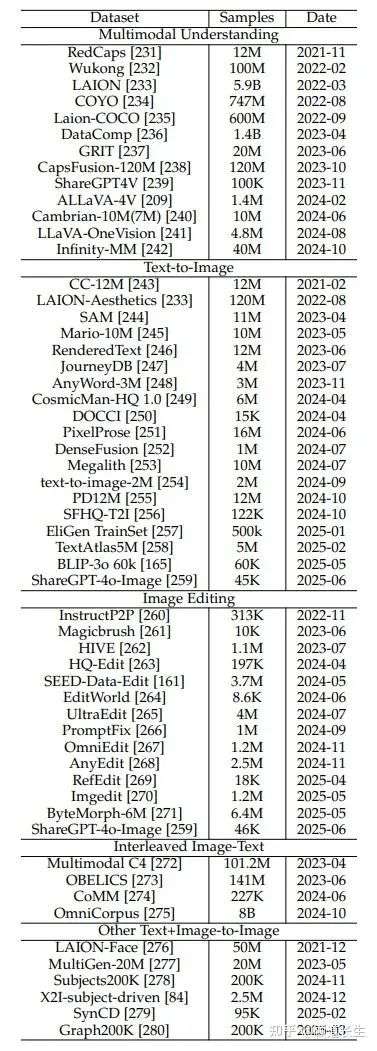
表3 统一多模态理解与生成模型预训练常用数据集概览。本表按主要应用(多模态理解、文本到图像生成、图像编辑、交错图文数据,以及其他条件生成任务)对数据集进行分类,详细列出了每个数据集的大致样本数量和发布时间。
4.1 Multimodal Understanding Datasets
这些数据集主要用于训练模型的跨模态理解能力,使其能够执行图像描述、视觉问答(VQA)、图文检索和视觉定位等任务。它们通常由大规模的图像与相应文本描述对组成。
-
• RedCaps [231]:该数据集包含来自Reddit的1200万对图文对,特别擅长捕捉社交媒体平台上用户经常分享的日常物品和瞬间(如宠物、兴趣、食物、休闲等)。
-
• Wukong [232]:Wukong数据集是一个大规模中文多模态预训练数据集,包含1亿个从网络中筛选的中文图文对。其构建旨在解决大规模高质量中文多模态预训练数据的缺乏,极大地推动了面向中文场景的多模态模型的发展。
-
• LAION [233]:LAION(Large-scale Artificial Intelligence Open Network,大规模人工智能开放网络)项目提供了目前公开最大的图文对数据集之一。例如,LAION-5B包含近60亿个从网络爬取的图文对,数据通过CLIP模型过滤以确保图像与文本之间的相关性。凭借其庞大的规模和多样性,LAION数据集已成为众多大型多模态模型预训练的基础。其子集Laion-COCO [235]包含6亿个高质量图文样本,旨在提供一个风格上更接近MS COCO [283]的大规模数据集。
-
• COYO [234]:COYO是另一个大规模图文对数据集,包含约7.47亿个样本。与LAION类似,它同样来源于网络爬取,并经过过滤处理,为社区提供了除LAION之外的另一大型预训练资源。
-
• DataComp [236]:DataComp包含14亿个样本,基于Common Crawl数据,通过精心设计的过滤策略(CLIP得分与基于图像的过滤)筛选而成,旨在提供比原始爬取数据更高质量的图文对。
-
• ShareGPT4V [239]:该数据集包含约10万个高质量图文对话数据,专为增强大型多模态模型的指令跟随与对话能力设计,使其成为更强的多模态对话智能体。
-
• ALLaVA [209]:该数据集包含140万个样本,全部为合成生成,旨在促进资源友好型轻量级视觉语言模型(LVLMs)的训练。数据生成流程基于强大的专有模型(如GPT-4V)多阶段生成:首先从LAION与Vision-FLAN等来源中选取图像;其次生成细致、详细的图像描述;最后生成复杂推理的视觉问答对,强调带有证据和推理链条的详细答案,支持稳健的视觉指令微调。
-
• CapsFusion-120M [238]:这是一个大规模数据集,包含1.2亿个图文对,从Laion-COCO [235]中精选而来。其图像描述由Laion-COCO中的原始描述与CapsFusionLLaMA [238]生成的描述融合而成。
-
• Cambrian-10M(7M)[240]:Cambrian-10M是为多模态指令微调设计的大规模数据集,涵盖多种类别但分布不均。为提升数据质量,该数据集通过精细化数据比例筛选,衍生出更高质量的Cambrian-7M子集。
-
• LLaVA-OneVision [241]:该视觉指令微调数据集包含两大部分:一是320万张多样化、已分类的单图像数据集(涵盖问答、OCR、数学等类别);二是OneVision数据集,包含160万条混合模态数据(包括视频、多图像以及部分精选的单图像数据)。
-
• Infinity-MM [241]:Infinity-MM是一个全面的多模态训练数据集,包含超过4000万条样本,由广泛收集和整理的开源数据集与新生成的数据组成。其内容涵盖图像描述、通用视觉指令、高质量精选指令,且大量数据由GPT-4生成或通过定制的视觉语言模型(VLM)流水线合成,确保数据的对齐性与多样性。所有数据都经过严格处理与过滤,以保证质量和一致性。
-
• 其他数据集:近期开发的其他理解数据集还包括GRIT(基于网格的图像-文本表示)[237],包含2000万条样本,专注于细粒度图像区域与文本短语的对齐。此外,尽管SAM数据集 [244]最初不包含图文对,但其收集的1100万张高分辨率图像及详细分割掩码,提供了宝贵的空间和语义信息,有助于增强多模态模型的细粒度理解能力,例如理解物体位置、边界,或执行区域特定操作。
此外,部分用于文本生成图像的数据集同样可用于多模态理解任务。
4.2 Text-to-Image Datasets
这些数据集主要用于训练根据文本描述生成图像的模型。它们通常由图文对组成,往往更强调图像的审美质量、内容丰富性或特定风格特征。
-
• CC-12M(Conceptual Captions 12M)[243]:CC-12M包含约1200万对图文样本,从网页Alt文本中提取并过滤而来。与原始网络爬取数据相比,其文本描述通常更加简洁和具象,因而被广泛用于训练文本生成图像模型。
-
• LAION-Aesthetics [233]:这是LAION数据集的子集,利用审美评分模型筛选出大约1.2亿张具有更高“审美价值”的图像及其文本描述。
-
• 文本渲染数据集:一些专门针对提升图像中文字渲染准确性和可读性的问题而开发的数据集。 Mario-10M [245]包含1000万个样本,用于训练TextDiffuser模型 [245],专注于优化文本位置和可读性。 RenderedText数据集 [246]提供1200万张高分辨率合成手写文本图像,涵盖多种视觉风格,是手写文本理解与生成的重要资源。 AnyWord-3M [248]包含300万个样本,用于训练如AnyText [248]这类模型,着重提升生成文本的质量。 TextAtlas5M [258]专注于密集文本生成,包含混合文档、合成数据和真实世界图像,配有人类标注长描述,适合处理复杂文本密集型图像场景。
-
• ourneyDB [247]:JourneyDB包含400万对由Midjourney平台2生成的高质量图像与文本提示。由于Midjourney以创意和艺术性图像著称,该数据集为训练模型学习复杂、细节丰富、艺术风格的文本到图像映射提供了宝贵资源。
-
• CosmicMan-HQ 1.0 [249]:该数据集包含600万张高质量真实人像图像,平均分辨率为1488 × 1255像素。其文本标注极为细致,覆盖1.15亿个属性,具备不同粒度,可用于增强人像生成能力。
-
• DOCCI [250]:DOCCI包含1.5万张精选图像,每张配有人类撰写的长文本英文描述(平均136词),旨在提供高度细节化、能区分相似图像的描述。其强调细粒度描述和对比图像集合,是训练和评估图像生成与文本生成模型的优质资源,尤其适用于处理复杂细节与构图。
-
• PixelProse [251]:PixelProse从DataComp [236]、CC-12M [243]和RedCaps [231]中提取,包含丰富注释的图文对。该数据集还提供诸如水印信息和审美评分等元数据,可用于筛选获得符合预期的图像。
-
• Megalith [253]:Megalith数据集包含约1000万个Flickr图像链接,这些图像被归类为“照片”,且具备无版权限制的许可证。社区基于ShareCaptioner [239]、Florence2 [284]和InternVL2 [11], [66]等模型生成的图像描述也对外公开。
-
• PD12M [255]:PD12M包含1240万张高质量公共领域和CC0许可图像,配有使用Florence-2-large [284]生成的合成文本描述。该数据集旨在为文本生成图像模型提供大规模数据,同时尽量避免版权问题。
4.3 Image Editing Datasets
随着模型能力的不断提升,基于指令的图像编辑已成为重要的研究方向。
此类数据集通常包含三元组(源图像、编辑指令、目标图像),用于训练模型根据文本指令修改输入图像,从而增强统一模型的理解与生成能力。
-
• InstructPix2Pix [260]:该数据集通过创新的合成方法生成:首先,大语言模型(如GPT-3)生成编辑指令和目标图像的描述;然后,文本生成图像模型(如Stable Diffusion)基于原始和目标描述生成“前后”图像。此方法自动生成了约31.3万条(指令、输入图像、输出图像)训练样本。
-
• MagicBrush [261]:MagicBrush是一个高质量、手工标注的指令图像编辑数据集,包含约1万条样本,涵盖各种真实且细致的编辑操作(如对象添加/删除/替换、属性修改、风格迁移),并提供编辑区域的掩码。由于手工标注,其指令更自然、多样。
-
• HIVE [262]:HIVE框架引入了人类反馈机制,提供了110万条训练数据(生成过程类似InstructPix2Pix,结合GPT-3和Prompt-to-Prompt,并进行循环一致性增强)以及3600条人类评分的奖励数据集。
-
• EditWorld [264]:EditWorld提出了“世界指令图像编辑”任务,聚焦于真实世界动态。其数据集通过两条路径构建:一是利用GPT-3.5生成世界指令并用T2I模型生成复杂图像对,二是从视频中提取帧对,并使用视觉语言模型生成描述动态变换的指令。
-
• PromptFix [266]:PromptFix构建了一个大规模指令跟随数据集(101万条三元组),专注于涵盖广泛图像处理任务,尤其是低层次任务(如修复、去雾、超分辨率、上色)。
-
• HQ-Edit [263]、SEED-Data-Edit [161]、UltraEdit [265]、OmniEdit [267]、AnyEdit [268]:这些是近期规模更大的图像编辑数据集。例如,SEED-Data-Edit包含370万条样本,UltraEdit有400万条,AnyEdit提供250万条,OmniEdit有120万条,HQ-Edit包含19.7万条。它们通常结合自动生成与人工筛选/标注,旨在提供更大规模、更高质量、更多样化的编辑指令与图像对,以训练更强的指令图像编辑模型。
-
• RefEdit [269]:该合成数据集专门针对复杂场景中的指代表达指令编辑问题,使用GPT-4o生成文本组件(提示、指令、指代表达),使用FLUX生成初始图像,利用Grounded SAM从表达中生成精确掩码,并结合特定模型进行对象移除或修改等可控编辑。
-
• ImgEdit [270]:ImgEdit是一个大规模(120万对编辑样本)数据集,旨在支持高质量的单轮与多轮图像编辑。其多阶段生成流程包括:过滤LAION-Aesthetics,使用视觉语言模型与检测/分割模型生成指令(包括空间提示与多轮对话),采用最先进的生成模型(如FLUX、带插件的SDXL)执行任务特定的修复,并用GPT-4o进行最终质量筛选。
-
• ByteMorph-6M [271]:ByteMorph-6M是一个超过600万对图像编辑数据集,专为涉及非刚性运动(如视角变化、物体变形、人类动作变化)的指令编辑设计。其构建流程包括:首先,利用视觉语言模型根据指令模板为初始帧生成“运动描述”;然后,使用图像生成视频模型基于该运动描述生成动态视频;最后,从视频中采样帧对,并使用大语言模型生成精确描述两帧变化的编辑指令,从而形成源目标编辑数据。
-
• ShareGPT-4o-Image (Editing) [259]:该数据集补充了ShareGPT-4o-Image中的文本生成图像部分,包含4.6万条指令图像编辑三元组。这些样本首先从其文本生成图像集或真实照片中选取源图像,再从预定义任务库中采样编辑任务(如对象操作、风格迁移),然后使用大语言模型为该任务和图像合成自然语言指令,最终利用GPT-4o的图像生成能力生成编辑后图像。
4.4 Interleaved Image-Text Datasets
除了包含图像与文字描述配对的数据集外,另一重要类别是交错图文数据集。这类数据集包含文档或序列,其中文本与图像自然交错排列,类似网页或文档中的内容。对这些交错数据的训练,能够提升模型的多模态内容理解与生成能力,这是统一模型的重要目标。
-
• Multimodal C4 (MMC4) [272]:MMC4是在大规模纯文本C4 [23]语料库的基础上,利用算法将图像插入文本文档而创建的。该公共数据集包含超过1.01亿份文档和5.71亿张图像,旨在为设计用于处理图文混合序列的模型提供必要的交错预训练数据。
-
• OBELICS [273]:OBELICS是一个开放的、网页级别的大规模数据集,从Common Crawl中提取,包含1.41亿份多模态网页文档、3.53亿张图像和1150亿个文本标记。该数据集注重完整文档结构的保留,而非孤立的图文对,旨在提升模型在各类基准测试中的表现。
-
• CoMM [274]:CoMM是一个高质量、精心策划的数据集,专注于交错图文序列的连贯性与一致性,包含约22.7万条样本。针对大型数据集中常见的叙事连贯性与视觉一致性问题,该数据集主要从教学类与视觉故事类网站(如WikiHow)采集内容,并应用多角度的过滤策略。CoMM旨在增强多模态大语言模型(MLLMs)生成逻辑严谨、视觉一致的多模态内容的能力,并引入专门用于评测此类能力的新基准任务。
-
• OmniCorpus [275]:OmniCorpus是一个超大规模(百亿级别)的图文交错数据集,包含86亿张图像、1696亿个文本标记和22亿份文档。该数据集利用高效的数据引擎,从多元来源(包括英文与非英文网站、视频网站中的关键帧和音频转录)提取和过滤内容,同时结合人类反馈过滤机制以提升数据质量,旨在为多模态大语言模型研究提供坚实的数据基础。
4.5 Other Text+Image-to-Image Datasets
除了前述类别,为进一步提升统一模型的能力(例如基于指定主体图像生成图像,或利用控制信号如深度图、Canny边缘图),本节介绍相关数据集。
-
• LAION-Face [276]:上述数据集侧重于通用主体驱动生成,而身份保留图像生成属于该类别的一个特殊子集。LAION-Face包含5000万对图文数据,近期如InstantID [285]等方法已成功实现保持角色身份的图像生成。
-
• MultiGen-20M [277]:该数据集包含2000万样本,旨在训练能够基于多种控制信号(如文本描述、边缘图、深度图、分割图、草图)统一图像生成的模型,如UniControl [277]。它整合了多个来源的数据,并转换为统一格式,使模型能学习多任务、多条件的图像生成。数据集可构造为三元组,例如“深度图、带提示的指令、目标图像”(指令如:“根据深度图生成令人印象深刻的场景。”),以有效训练统一模型。
-
• Subjects200K [278]:该数据集含20万样本,专注于主体驱动图像生成,对于个性化内容创作至关重要。其通过多阶段流程合成生成:首先由LLM(如ChatGPT-4o)生成结构化的物体类别与场景描述,然后利用图像生成模型(如FLUX [16])生成多样而一致的配对图像,最后由LLM进行质量评估,确保主体一致性、合理构图和高分辨率。
-
• SynCD [279]:SynCD(Synthetic Customization Dataset)提供约9.5万组专为文本+图像到图像定制任务设计的图像数据集,解决缺少公开多视角同一物体数据的问题。它通过利用现有文本到图像模型与3D资产数据集(如Objaverse [286]),合成在不同光照、背景、姿态下同一物体的多视角一致图像,结合共享注意力和深度引导技术。
-
• X2I-subject-driven [84]:该数据集用于主体驱动图像生成,由两部分组成。GRIT-Entity数据集从GRIT [237]数据集中自动检测并分割图像中的物体,并可选用MS-Diffusion [287]重绘提升质量和多样性。为增强生成能力,其还构建了更高质量的Web-Images数据集,通过自动文本分析与大语言模型筛选识别知名个体,从网络中抓取其图像,自动视觉验证确保主体准确性,再对选定图像生成描述。
-
• Graph200K [280]:Graph200K是在Subjects200K基础上构建的图结构数据集,每张图像附带49种标注,涵盖五大元任务:条件生成(如Canny边缘、深度图、分割图)、身份保留、风格转换(语义相关与不相关)、图像编辑(使用VLM与修复模型进行背景变化与不变化编辑)、图像恢复(通过在线退化)。该结构旨在提升任务密度与关联性,使模型通过图中路径学习共享与可迁移知识,从而实现通用图像生成。
主体驱动生成(包括单主体与多主体)已成为社区关注的关键图像生成能力,并有望成为统一模型中的重要特性。然而,从公开数据集中获取此类专门数据具有挑战性,因此通常采用数据合成方法,如Subjects200K与SynCD。这些数据集展示了为满足主体驱动生成与定制等任务的训练需求,日益依赖合成数据的趋势。
为创建大规模数据集,各类数据合成管道已被开发,用于程序化生成合适的训练数据,通常利用易获取的图像或视频资源。以下简要概述这些管道:
-
• 基于图像的数据合成:这类管道通常从单张图像开始,先使用BLIP-2 [53]或Kosmos2 [237]等模型生成初始描述(包括带边框的定位描述),随后进行目标检测(如Grounding DINO [290])与分割(如SAM [244]),提取主体掩码与区域描述。可用于单主体与多主体定制数据的生成。
-
• 基于视频的数据合成:图像生成的数据常导致模型学习中的“复制粘贴”问题。视频数据合成管道通过使用视频分割模型(如SAM2 [291])从不同帧中提取主体,缓解此问题。此外,该管道还能用于图像编辑任务的训练数据生成 [85]。
近期开发的大规模、高质量、多样化数据集在推动统一多模态模型的鲁棒性方面至关重要,涵盖图文对、交错图文文档及特定任务格式。
虽然大规模网页数据(如LAION、COYO)与交错文档语料(如MMC4、OBELICS)为预训练提供了广泛语义覆盖与上下文理解能力,但越来越多的努力专注于提升数据质量并针对特定属性或高级能力定制资源。专用数据集在改进指令编辑、文本渲染、协调的多模态生成与复杂条件控制方面日益关键。
此外,鉴于指令编辑与主体定制等任务的高质量公开数据稀缺,数据合成管道的开发与应用已成为必需,使得针对这些特定功能所需的训练数据得以创建。
最终,这些多样化数据资源的持续演进、规模扩张、特定化与合成创新,是推动统一多模态模型理解与生成能力不断提升的核心动力。
05BENCHMARKS
现代大规模统一多模态模型不仅应在像素层面对视觉与语言信息进行对齐,还需具备复杂推理能力、支持连贯的多轮对话,并能整合外部知识。 与此同时,这些模型还应能生成高度保真的视觉输出,既忠实于文本提示,又为用户提供细致的风格与构图控制能力。 在本节中,我们系统性地总结了相关评测基准,具体统计请参见表4。
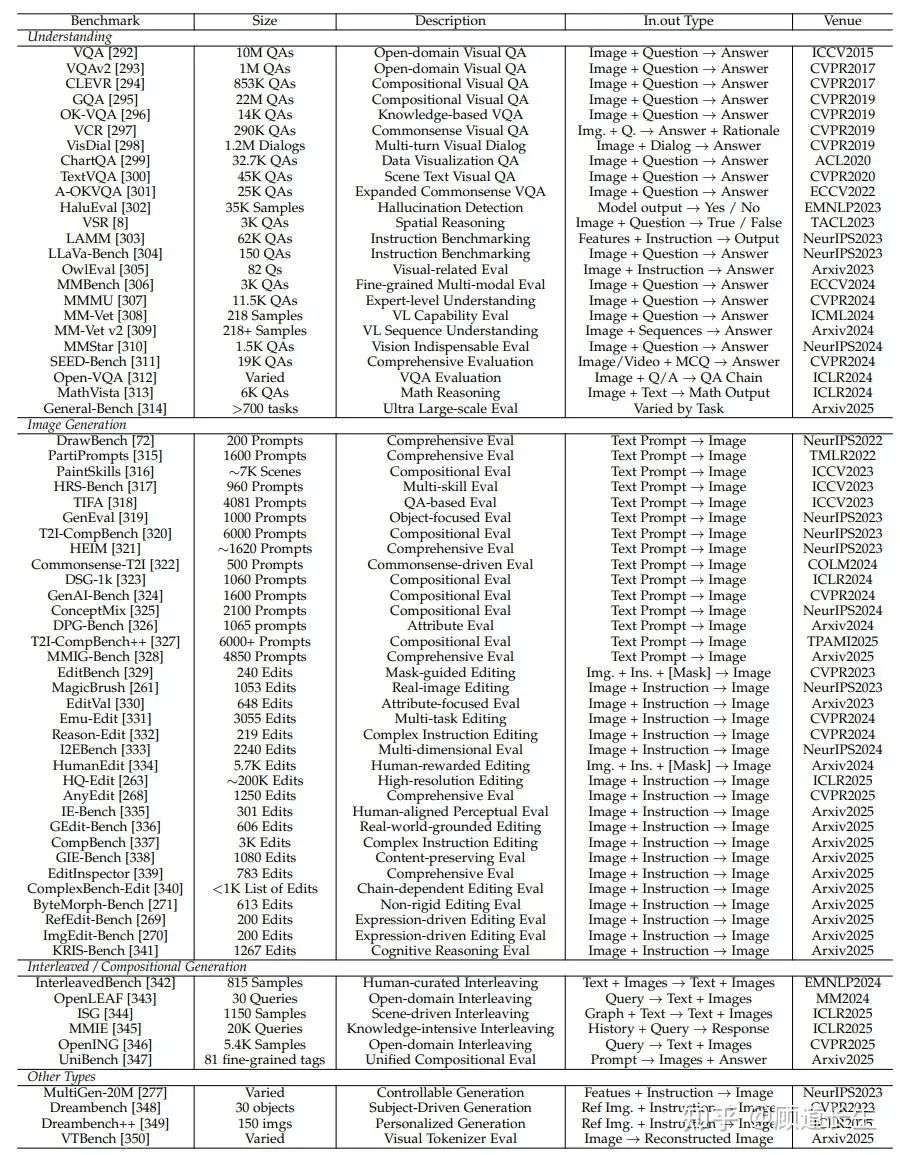
表4 当前统一大规模生成模型评测与基准的统计概览。本表将基准划分为理解、图像生成与交错生成三大类,详细列出了各基准的数据规模、数据描述、输入/输出类型及发表会议。
5.1 Evaluation on Understanding
感知能力。现代视觉-语言大模型必须通过定位、识别和检索,准确地将视觉输入与语言描述对齐。早期的图像-文本检索与图像描述基准(如Flickr30k [351]、MS COCO Captions [352])主要评测模型能否检索相关的图像描述,并将文本短语定位到图像区域。视觉问答基准如VQA [292]、VQA v2 [293]、VisDial [298] 和 TextVQA [300]进一步要求模型理解复杂场景,并就物体、属性和关系回答开放式问题。领域特定的基准如ChartQA [299]评测模型对结构化图表的理解能力,而VSR [8]则评测模型在真实场景中的空间关系推理能力。
为了统一评测,大规模元基准套件同时测试低层次感知能力与专家级推理能力。
MMBench [306]提供了3000道双语多选题,涵盖定位、识别和检索任务,可用于跨语言对比。MMMU [307]新增约1.15万道大学水平多模态问题,涉及六大领域,考察领域知识与逻辑推理能力。
HaluEval [302]专注于识别模型幻觉,包含多样化的模型生成与人工标注陈述。MM-Vet [308]涵盖识别、OCR、空间推理、数学及开放问答,其v2版本 [309]进一步评测交错图文序列理解。SEEDBench [311]设计了自动生成多选题的流程,涵盖12个评测维度,最终提供1.9万道多选题。LLaVa-Bench [304]提供基于COCO [283]与“in-the-wild”图像的密集问答集,用于通用性测试。LAMM [303]则包含涵盖2D与3D模态的指令微调样本,助力智能体开发。
Open-VQA [312]引入层级式追问机制,细化粗略的VQA回答。OwlEval [305]提供人类评审的开放式视觉问答,评估回答的相关性与信息量。MMStar [310]则精选六大核心能力、18个细分方向的挑战样本,实现高精度评测。
推理能力。在感知层评测基础上,推理类基准进一步检验模型的认知能力。CLEVR [294]系统性地变化物体属性与空间关系,要求模型执行多跳推理程序,测试计数、比较与关系逻辑能力。面向真实图像的GQA [295]借助密集场景图生成组合性问题,其功能程序用于评测一致性、定位与合理性。
面向常识推理的扩展基准如OK-VQA [296]及其更大版本A-OKVQA [301]挑选需超出图像、依赖世界知识库检索或推理的问题。VCR [297]则要求模型不仅选择正确答案,还需选出合适的推理理由,从而联合评测识别与解释能力,以及多步常识推理链。
领域特定推理数据集进一步拓展推理测试范围。ChartQA [299]引入结合视觉感知与数量推理的图表问答,涵盖数据提取、逻辑比较与算术计算。
MathVista [313]则扩展到视觉数学问题求解,融合细粒度视觉理解与符号运算,覆盖多样化数学问题。这些基准构成一套分层推理光谱,涵盖结构化逻辑推理、开放领域常识、视觉解释与高精度数值任务,为多模态推理系统提供全面压力测试。
此外,General-Bench [314]作为一个超大规模基准,整合700多个任务、32.58万个实例,横跨多种模态与能力,提供多模态通用模型的综合评测套件。
5.2 Evaluation on Image Generation
文本到图像生成。早期的自动评测指标如FID [353]与CLIPScore [22]奠定了图像质量评估的基础。近期的基准测试更注重组合推理、提示对齐和真实应用。PaintSkills [316]、DrawBench [72]和PartiPrompts [315]评测模型的组合能力。GenEval [319]涵盖六个细粒度任务,包括单物体生成、物体共现、计数、颜色控制、相对位置与属性绑定,通过与预训练检测器输出对比评估生成效果。
在此基础上,GenAI-Bench [324]提供1600条精心设计的人类提示,涵盖关系、逻辑和属性类别,其评测框架结合人工偏好判断与自动对齐评分,实现全面评测。HRS-Bench [317]评测13项能力,归为准确性、鲁棒性、泛化、公平性和偏差五大类别,确保可扩展且可靠的性能测量。
此外,DPG-Bench [326]专注于多物体密集提示下的图像生成,每个物体具备多种属性和关系。T2I-CompBench [320]及其升级版T2I-CompBench++ [327]专门评测组合泛化能力,测试新颖属性与关系组合生成能力,采用检测器打分。VISOR [354]提出自动评估生成模型空间理解能力的方法。
Commonsense-T2I [322]考察模型生成日常常识概念的能力。EvalMuse40K [355]提供4万条众包提示,聚焦细致概念表达,HEIM [321]覆盖12项评测指标,包括文本图像对齐、图像质量、美学、原创性、推理、知识、偏见、有害性、公平性、鲁棒性、多语言性和效率。
针对实用性,FlashEval [356]通过迭代搜索压缩大规模评测集,加速评测流程。MEMOBench [357]引入全面评测T2I模型与多模态大模型情感理解与表达能力的基准。ConceptMix [325]评估T2I模型的组合生成能力,通过抽取视觉概念k元组构造提示,并用强视觉语言模型自动验证概念生成情况。
TIFA [318]提供基于VQA的细粒度基准,评测文本到图像的忠实性。DSG-1k [323]通过多层语义图优化VQA问题生成,强化图像与提示对齐的问答评测。MMIG-Bench [328]引入多维评测框架,全面检验文本到图像生成模型。
图像编辑。指令引导的图像编辑基准持续扩大规模与任务范围。MagicBrush [261]是大规模人工标注的真实图像编辑数据集,覆盖单轮、多轮、带遮罩和无遮罩编辑场景。HQ-Edit [263]包含约20万高分辨率编辑对,配有对齐与一致性得分,便于量化评测编辑质量。
I2EBench [333]整合2K多图像与4K多步指令,涵盖16种编辑维度。EditVal [330]提供标准化基准,具备细粒度编辑标注与对齐人类判断的自动评测流程。EmuEdit [331]覆盖背景变更、物体编辑与风格修改等七种编辑任务,包含指令与输入输出对。Reason-Edit [332]是诊断性基准,专注因果与反事实推理,考察物体关系、属性依赖与多步推理。
EditBench [329]通过遮罩输入与参考图像对,跨越物体、属性与场景,构建文本引导的图像修复诊断性基准。HumanEdit [334]收录5751张高分辨率图像与开放式指令,涵盖六类编辑类型,并附带遮罩与多阶段人类反馈。IE-Bench [335]提供人类对齐的文本驱动图像编辑基准,具备多样编辑与感知评分。
最新基准如GEdit-Bench [336],包含606对真实世界指令与图像;CompBench [337]通过大规模多模态大模型与人类协作,将编辑拆分为位置、外观、动态与物体四个维度;GIE-Bench [338]结合多选VQA与物体感知遮罩,评测编辑准确性与内容保持性。后续基准如[268]、[270]、[339]、[340]也全面评测文本驱动图像编辑的视觉一致性、伪影检测、指令遵循、视觉质量与细节保留能力。
其他基准还包括:ByteMorph-Bench [271],聚焦非刚性图像变形;RefEditBench [269],评测复杂多实体场景中的指代表达编辑;KRIS-Bench [341],提供认知基础的因果、概念与程序推理评测套件。
其他类型图像生成。除文本到图像生成与编辑外,部分基准专注于条件生成与个性化合成。MultiGen-20M [277]提供2000万组图像-提示-条件三元组,支持多样视觉条件下的自动评测。DreamBench [348]使用30个参考物体与精心设计的提示,结合人工保真度评分,评测个性化生成。DreamBench++ [349]扩展至150个主题与1350条提示,结合先进视觉语言模型,评测概念保持、构图与风格。
VTBench [350]系统性评测自回归图像生成中的视觉分词器,涵盖图像重建、细节保留与文本保持等任务。
5.3 Evaluation on Interleaved Generation
交错评测基准旨在考验模型在多轮交互中无缝切换文本与图像模态的能力,以模拟现实中的对话与故事叙述场景。InterleavedBench [342] 是代表性基准,专门为交错文本与图像生成评测而精心策划,涵盖丰富任务,涉及多样化真实应用场景,从文本质量、感知保真度、多模态一致性与有用性等维度全面评测模型能力。
在此基础上,ISG [344]引入场景图注释与四层次评测框架(整体、结构、区块级与图像特定层面),覆盖8类场景与21个子任务,共1K样本,能够细致评估交错文本图像输出的细节与一致性。
其他基准聚焦开放域指令与端到端交错生成。OpenING [346]收集5K条人类标注实例,涵盖56个真实任务(如旅游指南、设计创意),配合IntJudge系统,测试开放式多模态生成方法在任意指令驱动下的交错生成能力。相比之下,OpenLEAF [343]聚焦30个开放域查询,每条均由标注员编写与审核,针对基础交错文本图像生成评测,利用多模态大模型评审器(LMM evaluators)与人工验证,评测实体一致性与风格一致性。
MMIE [345]提出统一交错评测套件,从12个领域与102个子领域中抽样,涵盖多项选择与开放式问答任务,以多样化形式全面评测模型在交错生成中的能力。
最新基准UniBench [347]专为统一模型而设计,作为全面的组合基准,包含81个细粒度标签,确保高多样性,系统性评测模型的组合能力与交错生成表现。
06CHALLENGES AND OPPORTUNITIES ON UNIFIED MODELS
目前,统一多模态模型仍处于初级阶段,面临诸多亟需解决的重要挑战,以实现稳健且可扩展的理解与生成能力。
首先,视觉与文本数据的高维特性导致极长的token序列。如何在保留表达能力的前提下,有效压缩token、降低内存与计算开销,是核心问题。高效的token化与压缩策略势在必行。
其次,随着图像分辨率与上下文长度的提升,跨模态注意力机制成为性能瓶颈。稀疏注意力、分层注意力等可扩展机制有望缓解该问题。
第三,预训练数据集中的图像-文本对,尤其是复杂图像组合与交错图文数据,往往存在噪声或偏差。因此,可靠的数据筛选、去偏与合成策略至关重要,以确保公平性与稳健性。
第四,目前评测协议大多针对单一任务,缺乏综合性基准。未来亟需设计评测统一理解与生成能力的完整性基准,尤其是针对复杂任务如图像编辑、交错图文生成。
除架构、数据与评测方面的挑战外,将“思维链(CoT)推理”与“强化学习(RL)”技术应用于统一多模态大模型(MLLM)也值得探索。CoT推理能够引导模型生成中间推理步骤,特别适用于复杂视觉问答或图像条件生成场景;RL则可优化长程目标,如事实一致性、用户满意度或任务成功率,突破传统基于token的似然优化。
此外,探讨现有统一MLLM中的人口与社会偏差问题,也是实现负责任部署的重要议题。随着模型跨模态与多任务能力不断提升,预训练数据中的文化刻板印象、性别偏见或地域不平衡,可能被无意放大并输出有害内容。未来需研究有效的公平性训练管道。
最后,基于个性化知识的生成能力,正成为统一MLLM的重要前沿方向。个性化模型旨在将用户自定义概念(如特定对象、角色或风格)融入理解与生成中。然而,当前方法多将理解与生成任务分开建模,分别学习概念嵌入,导致模型难以泛化处理隐式知识组合的复杂提示,如在未显式描述“帽子”的情况下,生成“戴着它的帽子”。
若能在统一框架下融合个性化理解与生成,模型将具备更强的语义对齐与上下文泛化能力。
据我们所知,目前大多数统一多模态模型仍主要聚焦于图像理解与文本生成图像(text-to-image generation),而图像编辑功能多通过后续微调获得。更先进的功能如空间控制图像生成、主体驱动图像生成、交错图文生成,在统一框架中的探索仍较少。
因此,我们认为,该领域在架构设计、训练效率、数据集建设、评测方法、公平性机制与推理能力等方面,仍存在大量值得深入研究的机遇,以推动统一多模态模型的持续突破与演进。
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
参考文献链接
Paper:Unified Multimodal Understanding and Generation Models: Advances, Challenges, and Opportunities
Abs:https://arxiv.org/abs/2505.02567
Github:https://github.com/AIDC-AI/Awesome-Unified-Multimodal-Models
人工智能芯片与自动驾驶

 浙公网安备 33010602011771号
浙公网安备 33010602011771号