
聊聊HBM Roadmap和HBM4的关键特性
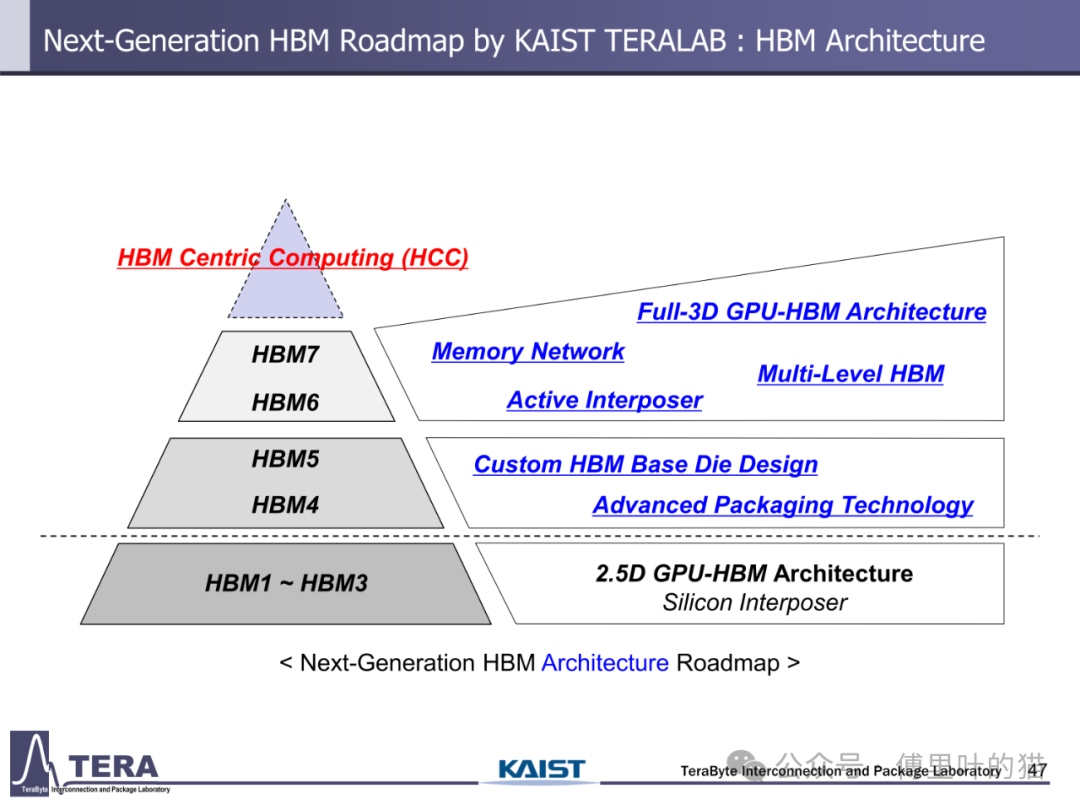
今天我们来看下KAIST TERALAB在前两天的一次workshop中公布的一些关于HBM的技术。KAIST 实验室在高带宽内存(HBM)设计技术方面处于世界领先地位,由被部分业内人士称为 “HBM 之父” 的 Kim Joungho 教授领导,在 HBM 领域有诸多开创性的研究成果。2017 年 Kim Joungho 教授首次正式公布了 Kim 法则,该法则对半导体行业的长期规划和研发目标设定起到了重要的指导作用。在前几天,该实验室举办了关于下一代 HBM 路线图的技术展示会,介绍了从 HBM4 到 HBM8 的长期路线图,涵盖 HBM 架构、冷却方法、TSV 密度、中介层等方面的进展。
这个ppt有371页,内容比较多,这篇文章我们先看HBM Roadmap Overview和HBM4 Key features两部分。
HBM Roadmap Overview
在数据爆炸式增长与 AI 计算需求狂飙的时代,存储器技术正经历着前所未有的变革。高带宽存储器(HBM)作为突破 "内存墙" 的关键技术,其roadmap展现了从单纯容量升级到计算存储融合的全维度进化。
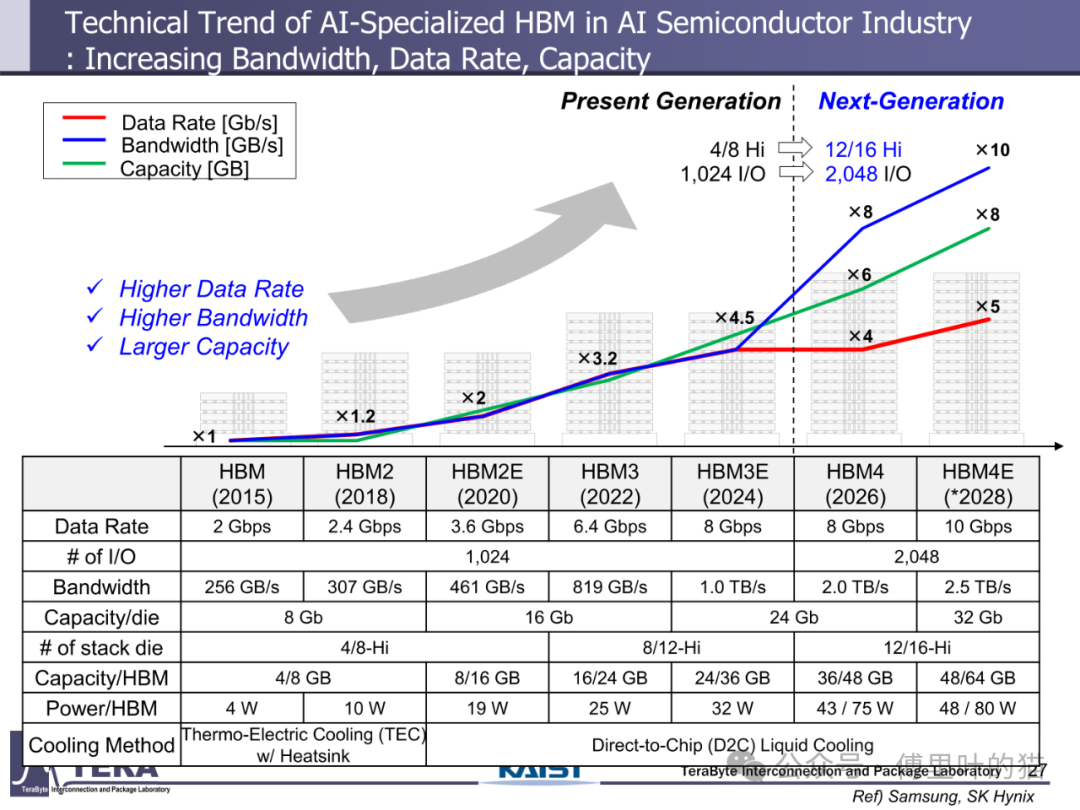
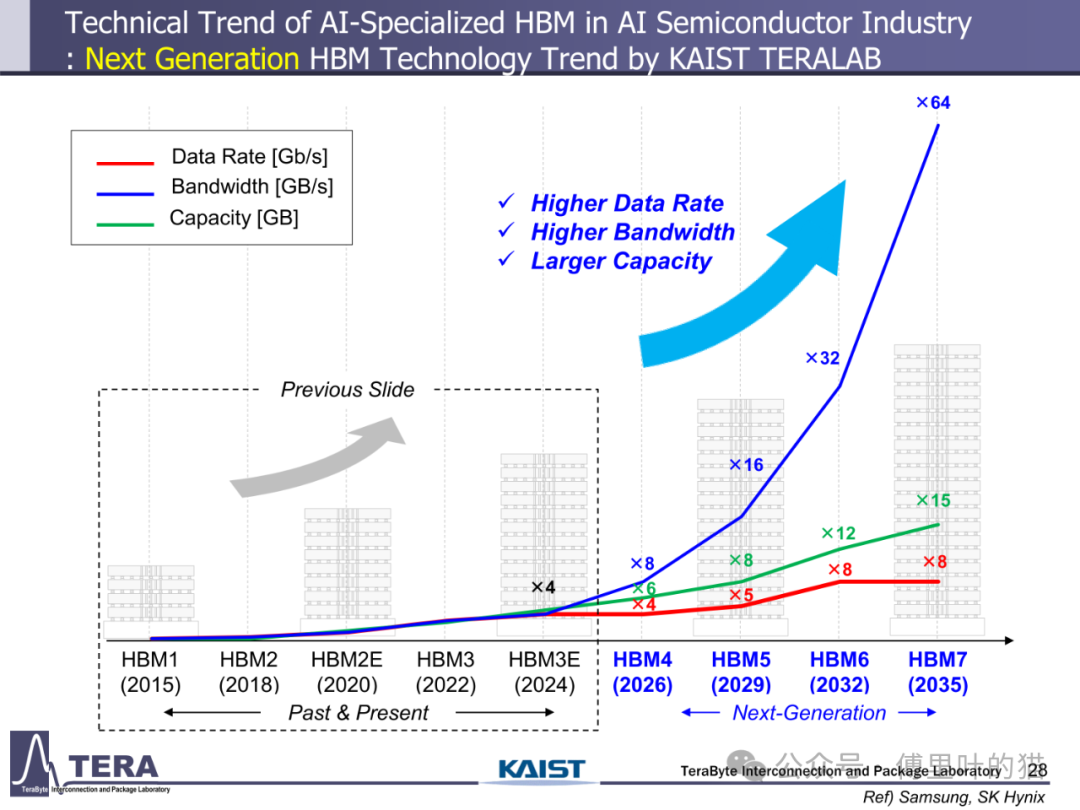
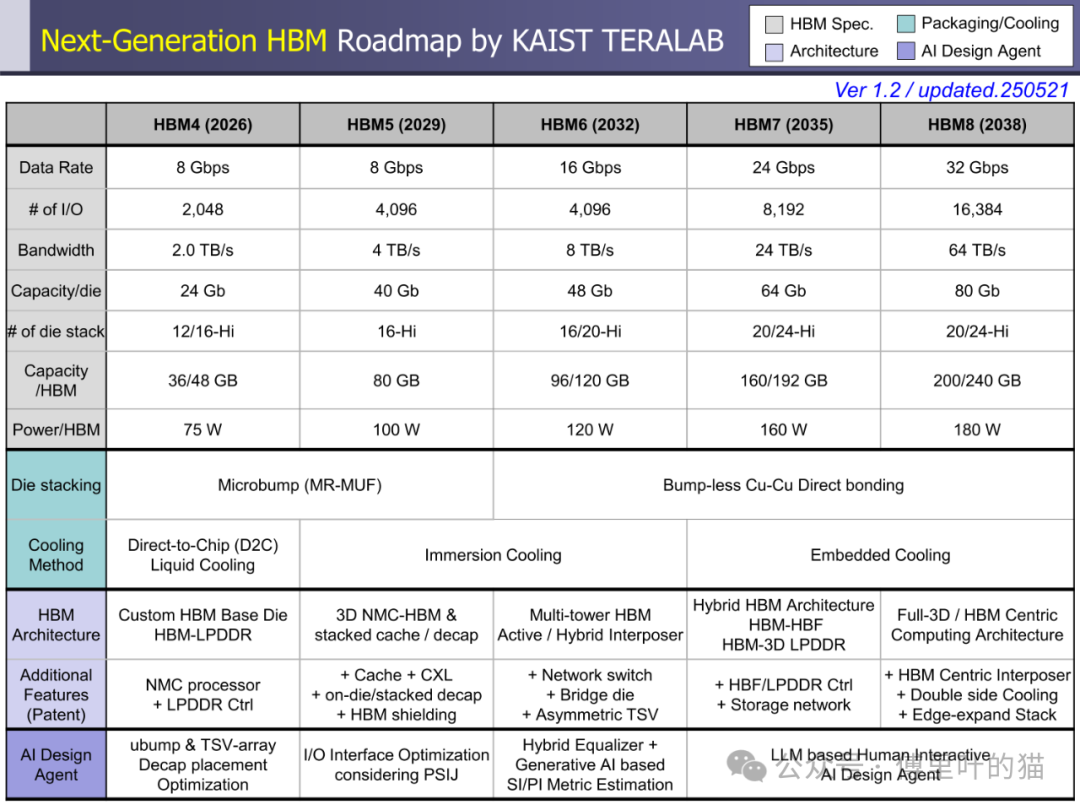
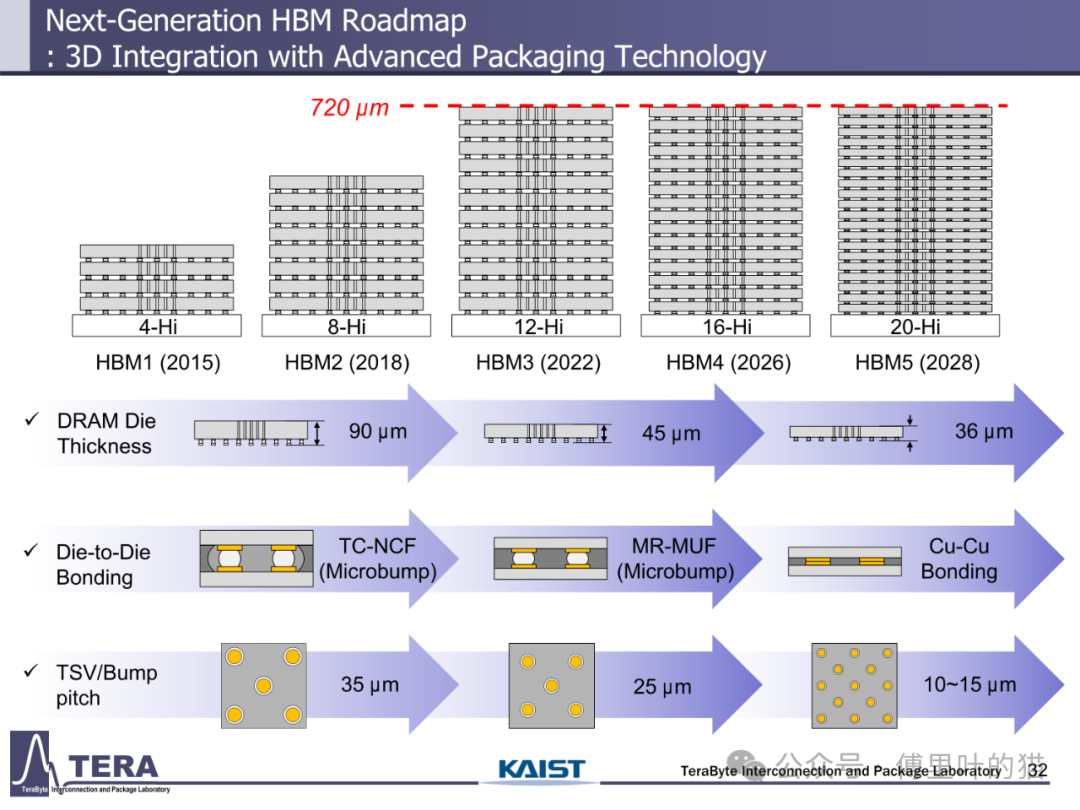
HBM 的发展始终围绕 "更高带宽" 这一核心目标展开。从技术实现路径看,带宽提升依赖于互连数量、单线路数据速率与 TSV(硅通孔)密度的协同优化。HBM1 时代仅具备 1024 个 I/O 接口,数据速率为 2Gbps,带宽 256GB/s;而到 HBM4 阶段,I/O 数量翻倍至 2048 个,数据速率维持 8Gbps 但通过架构优化使带宽跃升至 2.0TB/s,HBM8 更将实现 16384 个 I/O 与 32Gbps 数据速率的组合,带宽达到惊人的 64TB/s。这种指数级增长背后,是混合键合、窄间距封装等工艺的突破 —— 从 HBM3 的 Microbump(MR-MUF)技术到 HBM5 的无凸点 Cu-Cu 直接键合,键合精度从 35μm 级向 10-15μm 级演进,为高密度互连奠定基础。
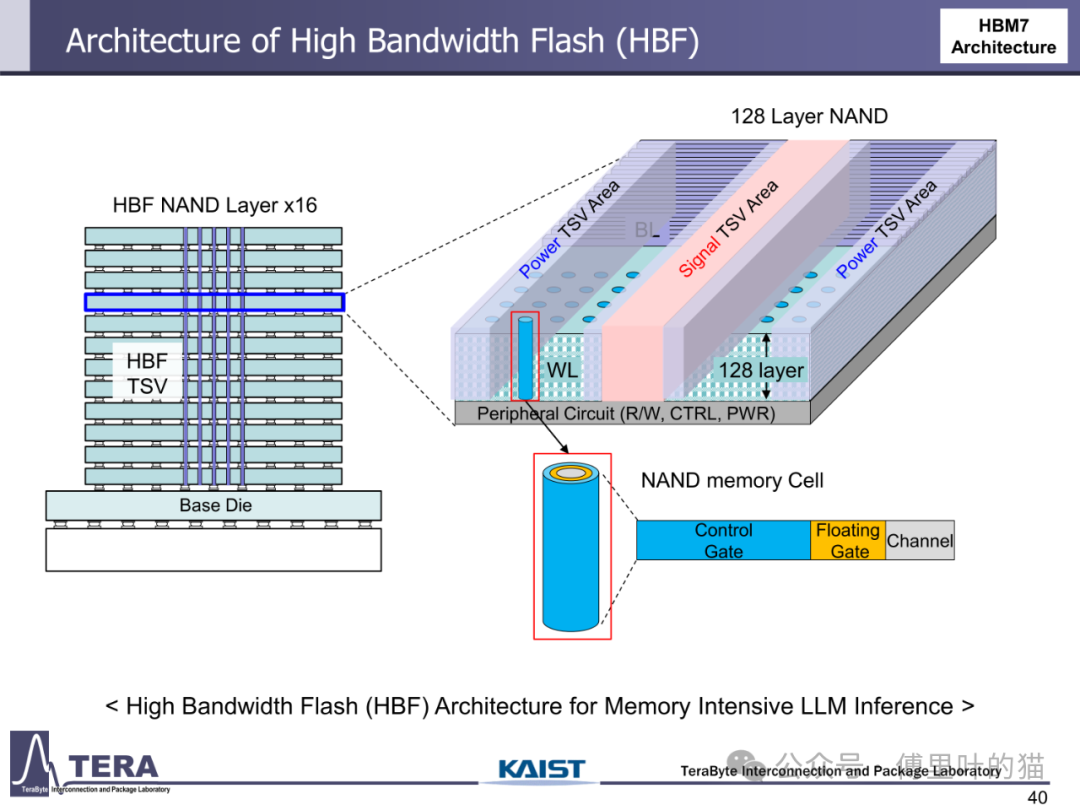
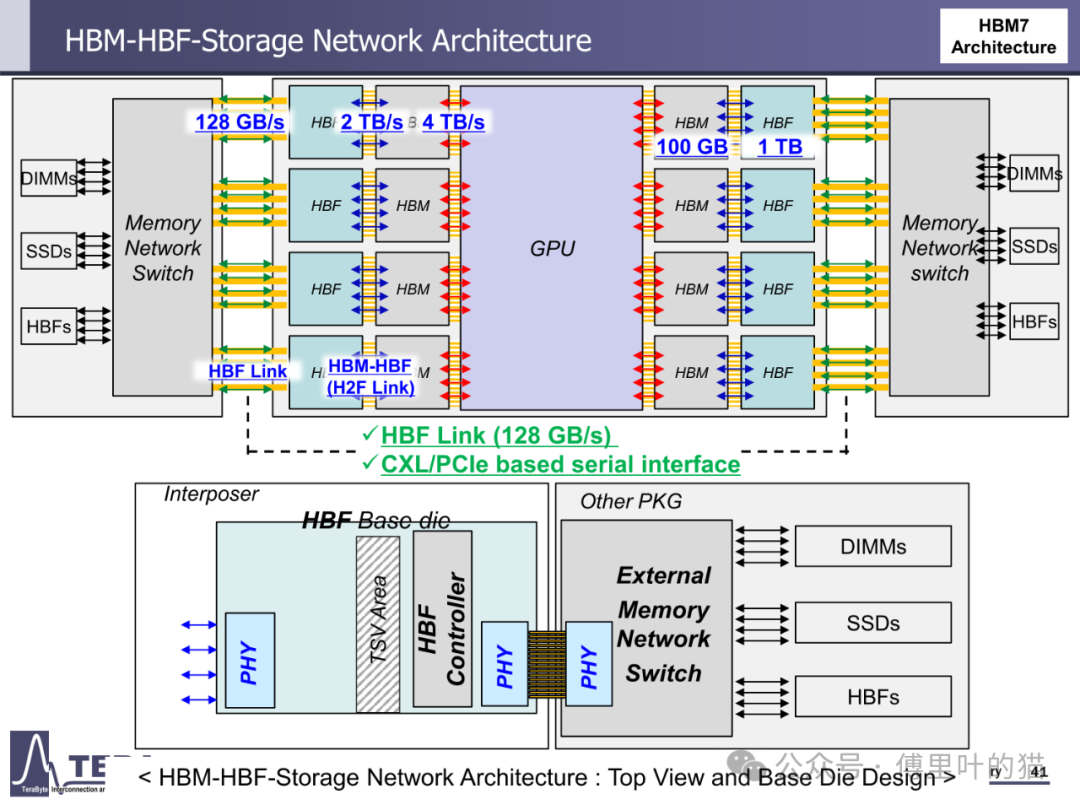
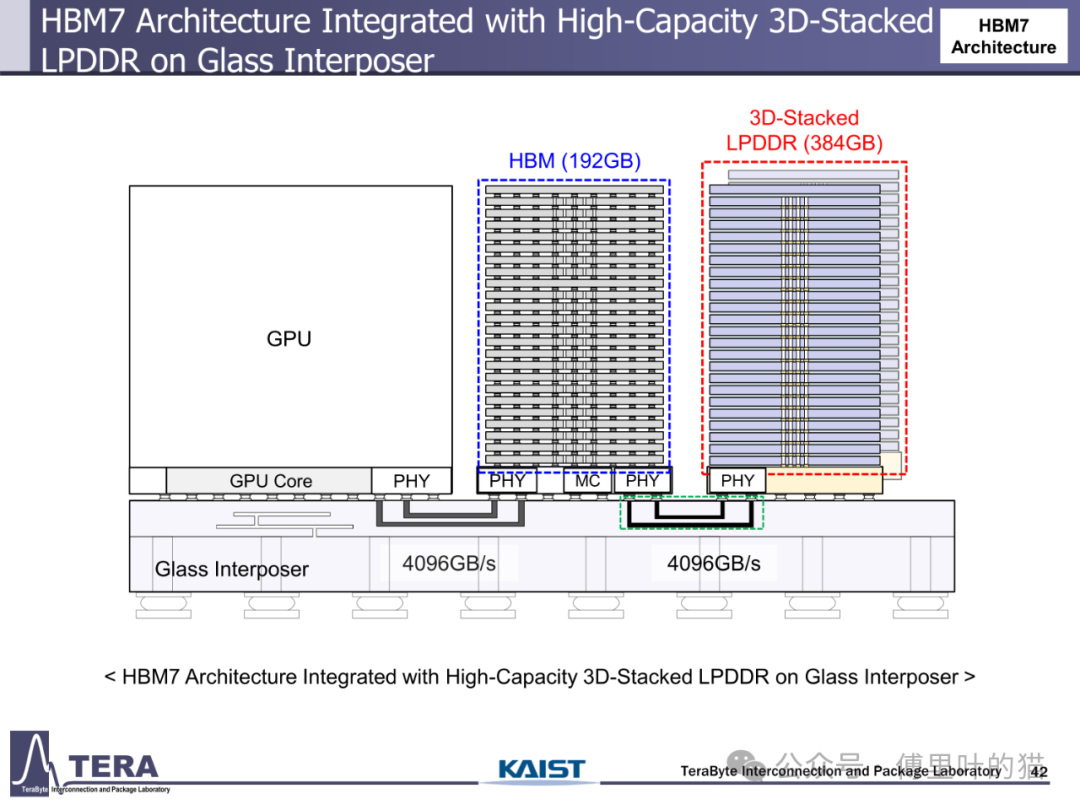
存储容量的升级与带宽增长形成协同效应。HBM1 的单颗容量仅 4/8GB,而 HBM4 通过将堆叠层数从 HBM3 的 8/12-Hi 提升至 12/16-Hi,结合 24Gb/die 的存储密度,使容量达到 36/48GB。更长远来看,HBM8 将通过 20/24-Hi 的堆叠与 80Gb/die 的密度,实现 200/240GB 的超大容量。这种容量跃升不仅依赖 DRAM 工艺进步,更得益于分层存储架构与内存网络的创新 —— 通过集成 LPDDR-HBM 与 HBF(高带宽闪存),HBM7 构建起 "内存 - 存储" 一体化网络,支持 128GB/s 的 HBF 链路与 CXL 接口,实现从内存到存储的无缝数据流转。
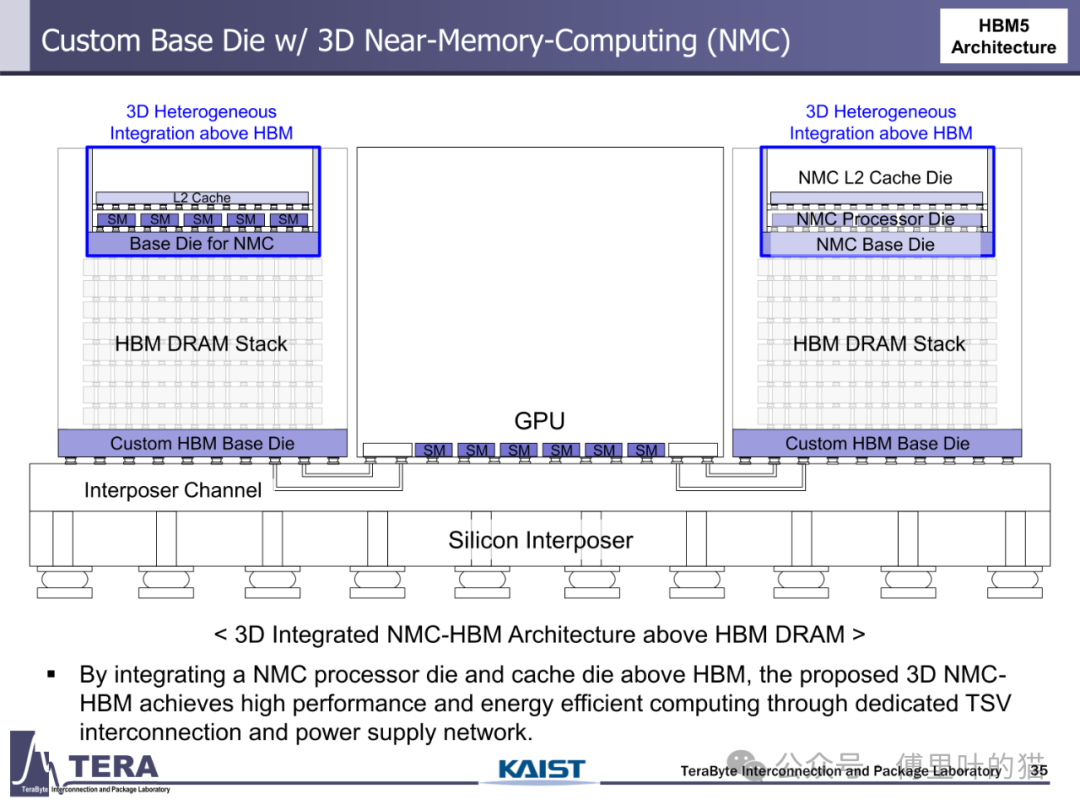
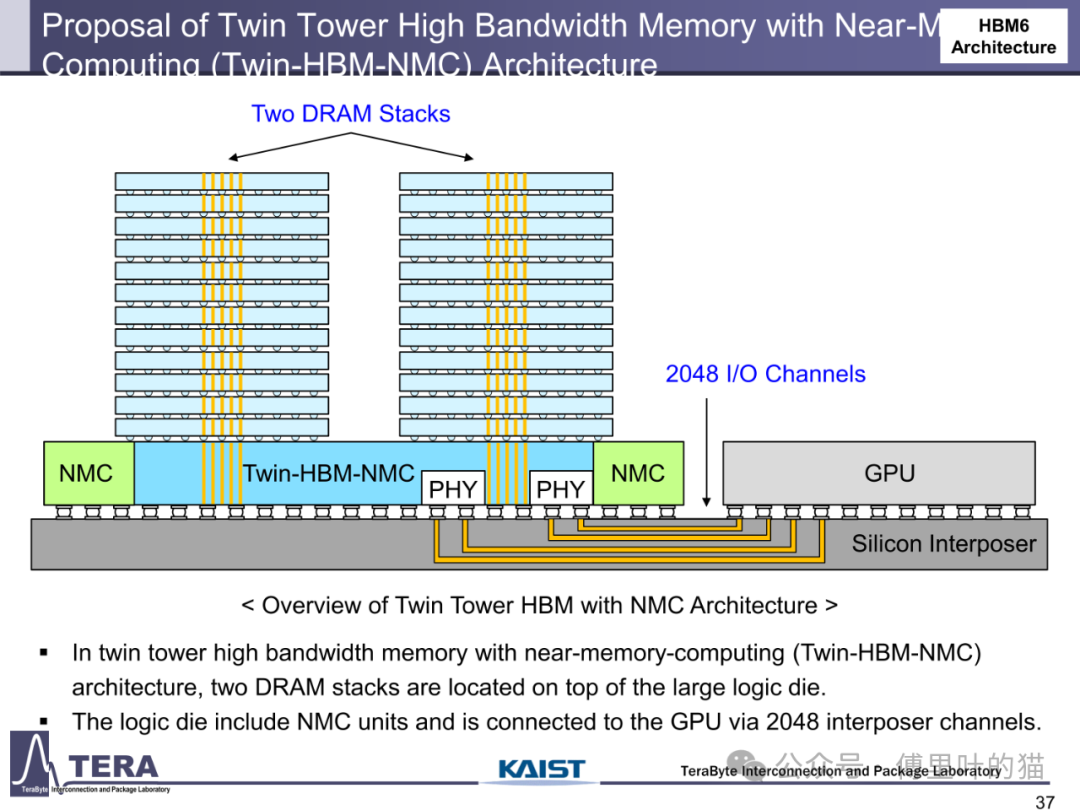
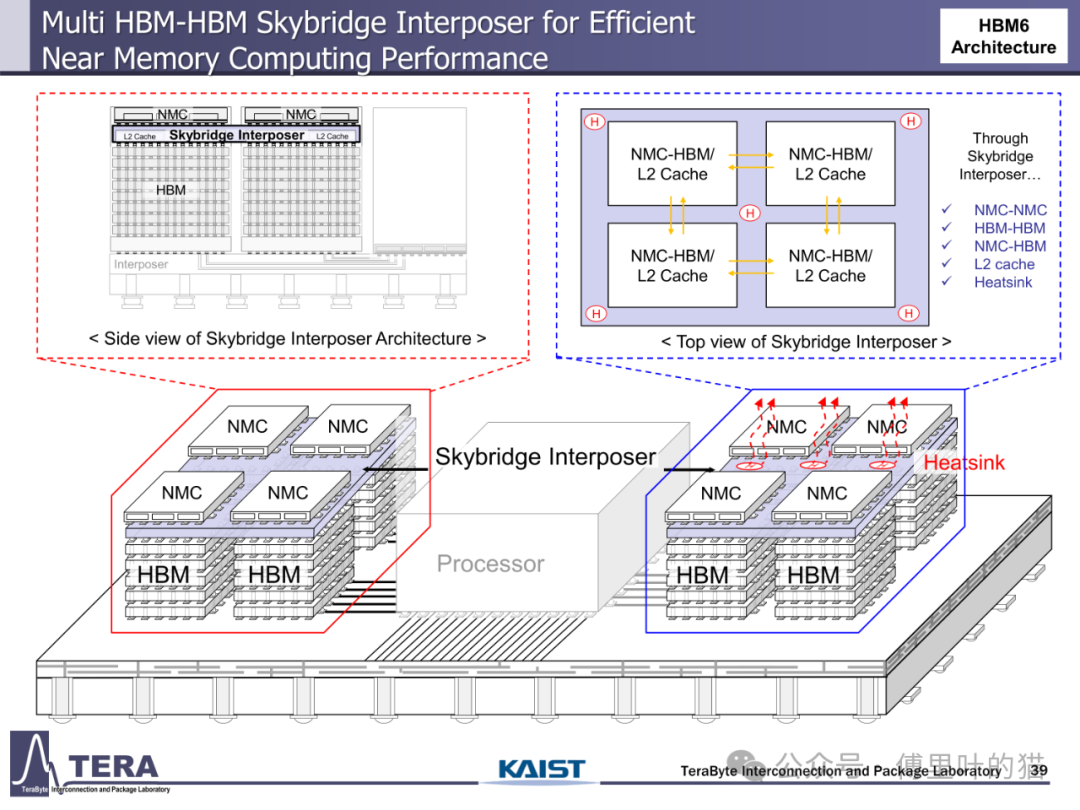
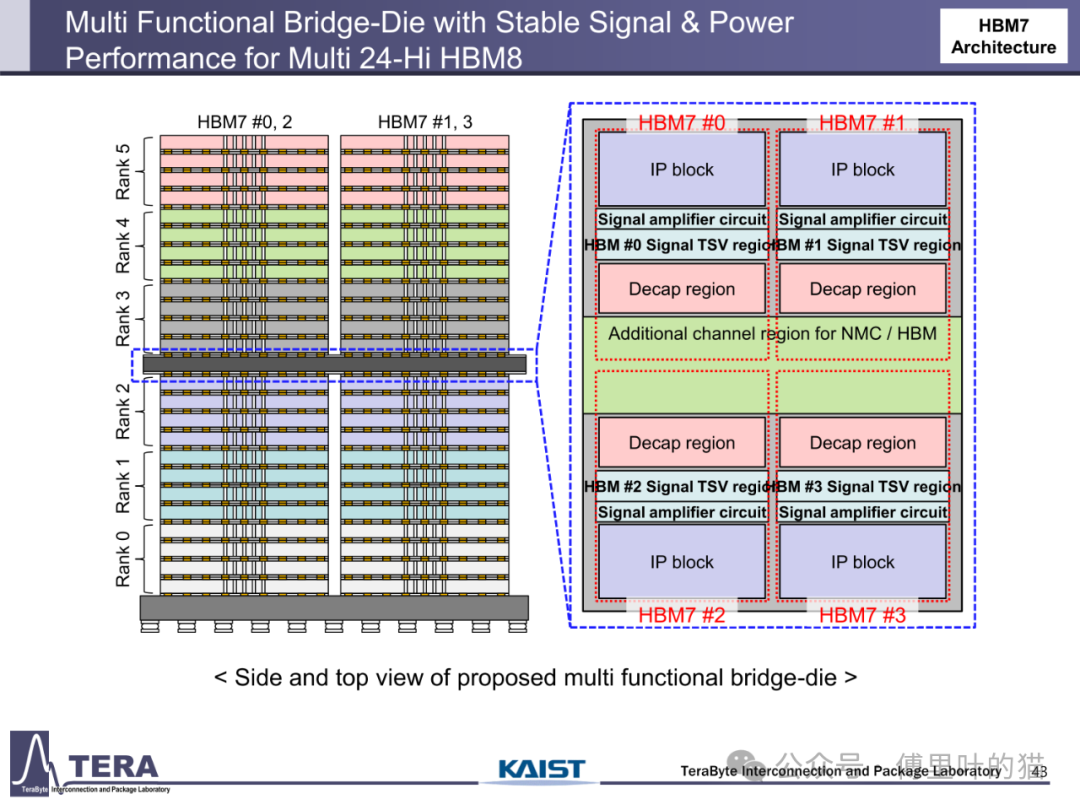
计算能力与存储架构的融合成为 HBM 路线图的革命性方向。传统存储架构中,数据在 CPU、GPU 与内存间的迁移造成巨大延迟,而 HBM 通过 "近内存计算(NMC)" 技术将计算单元直接嵌入存储堆叠。HBM5 架构中,NMC 处理器 die 与 L2 缓存 die 被集成到 HBM 上方,通过专用 TSV 互连形成 3D 异构计算单元,使矩阵运算等密集型任务无需跨芯片数据迁移,计算能效提升数倍。HBM7 更进一步引入 "双塔式 HBM-NMC" 架构,通过两堆 DRAM 与 2048 条中介层通道与 GPU 连接,构建起以存储为中心的计算架构,这种 "存储即计算" 的模式正在重塑 AI 硬件的底层逻辑。
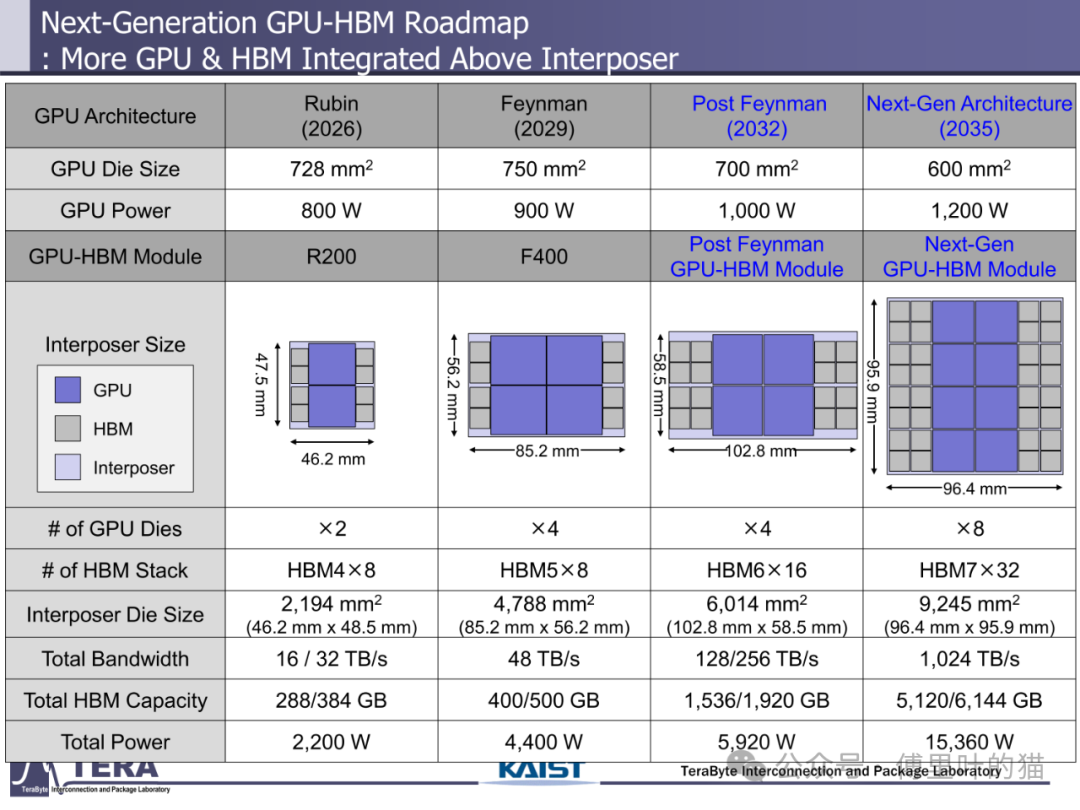
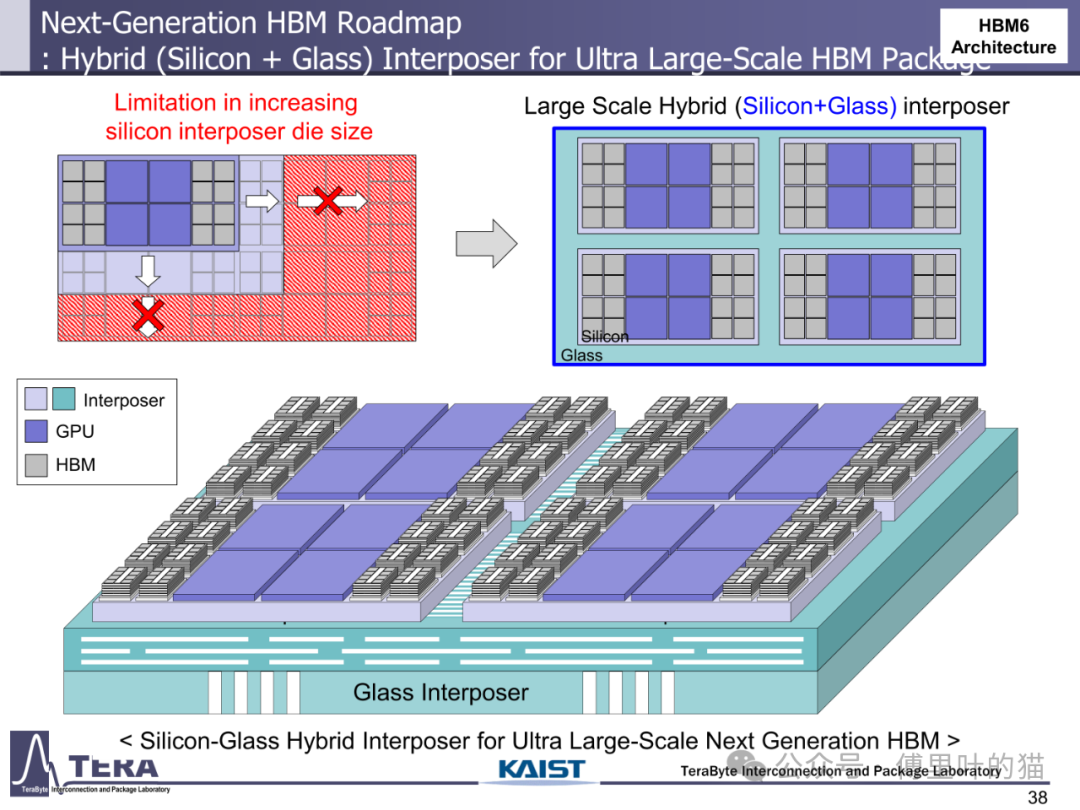
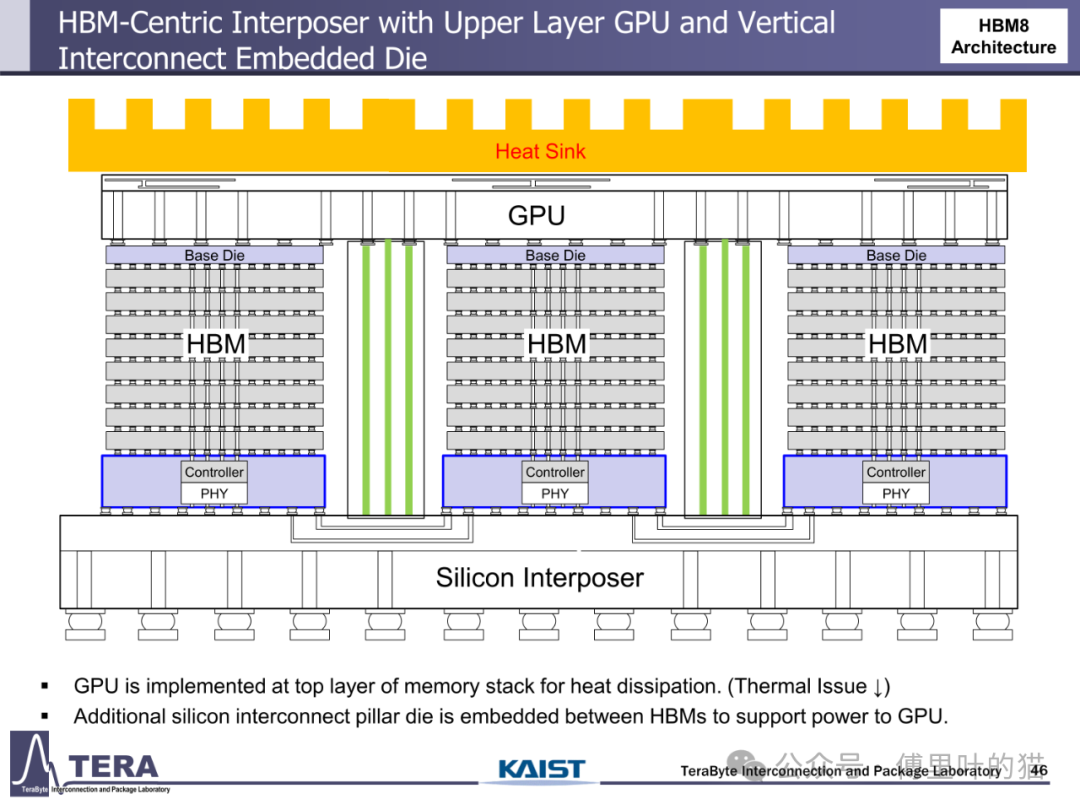
3D 集成技术的突破为 HBM 演进提供了物理基础。从 HBM1 的 2.5D 硅中介层到 HBM6 的硅 / 玻璃混合中介层,封装技术经历了从单一材料到异质集成的跨越。硅中介层的尺寸限制在 HBM6 时代被打破 —— 通过硅与玻璃中介层的混合使用,超大尺寸封装得以实现,支持更多 HBM 堆叠与 GPU 集成。HBM8 更采用双面中介层设计,在中介层中嵌入冷却通道与垂直互连柱,使 GPU 可直接部署在存储堆叠顶部,既优化散热又缩短数据路径,这种全 3D 集成架构标志着 HBM 从单纯存储器件向系统级解决方案的蜕变。
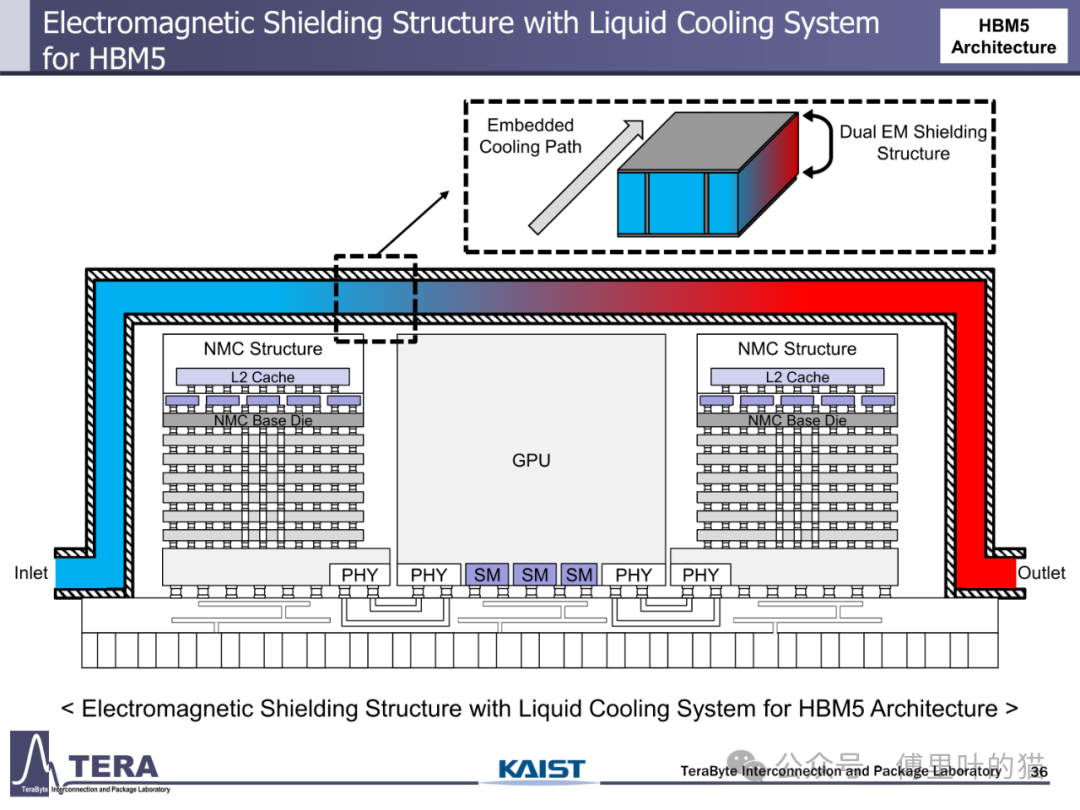
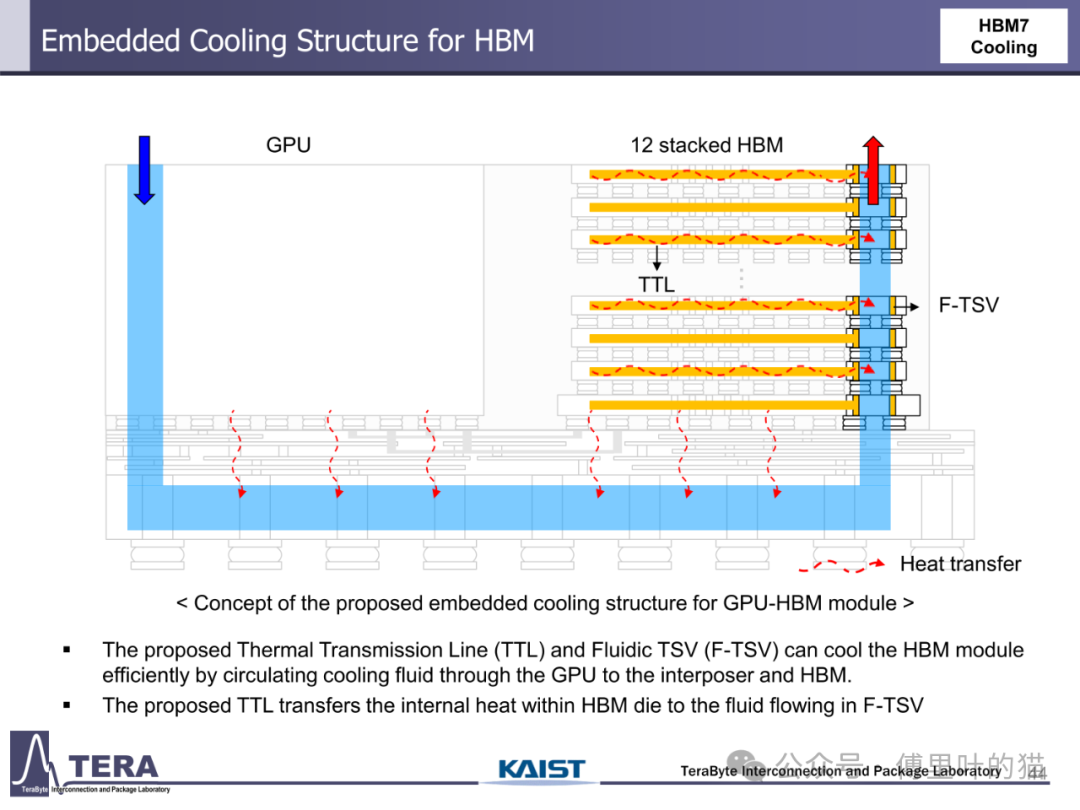
散热技术的创新与功耗控制是 HBM 规模化应用的关键保障。HBM1 采用热电冷却 + 散热器的被动方案,而 HBM3 首次引入直接芯片液冷(D2C)技术,将散热效率提升一个量级。HBM5 进一步采用浸没式冷却,应对 100W 级的功耗需求;HBM7 则开发出嵌入式冷却结构,通过热传输线(TTL)与流体 TSV(F-TSV)实现冷却流体在 GPU、中介层与 HBM 间的循环,即使功耗达到 160W 也能保证系统稳定运行。这种散热方案的演进与 HBM 功耗增长形成动态平衡 —— 从 HBM1 的 4W 到 HBM8 的 180W,散热技术始终支撑着性能提升。
AI 技术正深度融入 HBM 的设计与优化流程。KAIST TERA 实验室提出的 AI 设计代理,通过强化学习算法对微凸点布局、TSV 阵列与去耦电容放置进行优化,相比传统设计方法提升信号完整性与电源效率。在 HBM4 设计中,AI 工具被用于 I/O 接口优化,考虑 PSIJ(封装系统交互)效应实现高速信号传输;HBM7 更引入基于大语言模型(LLM)的人机交互设计代理,通过自然语言交互实现 SI/PI 指标估算与混合均衡器设计,将 AI 从后端优化延伸至前端架构设计,开启智能设计新时代。
Key Features in HBM4
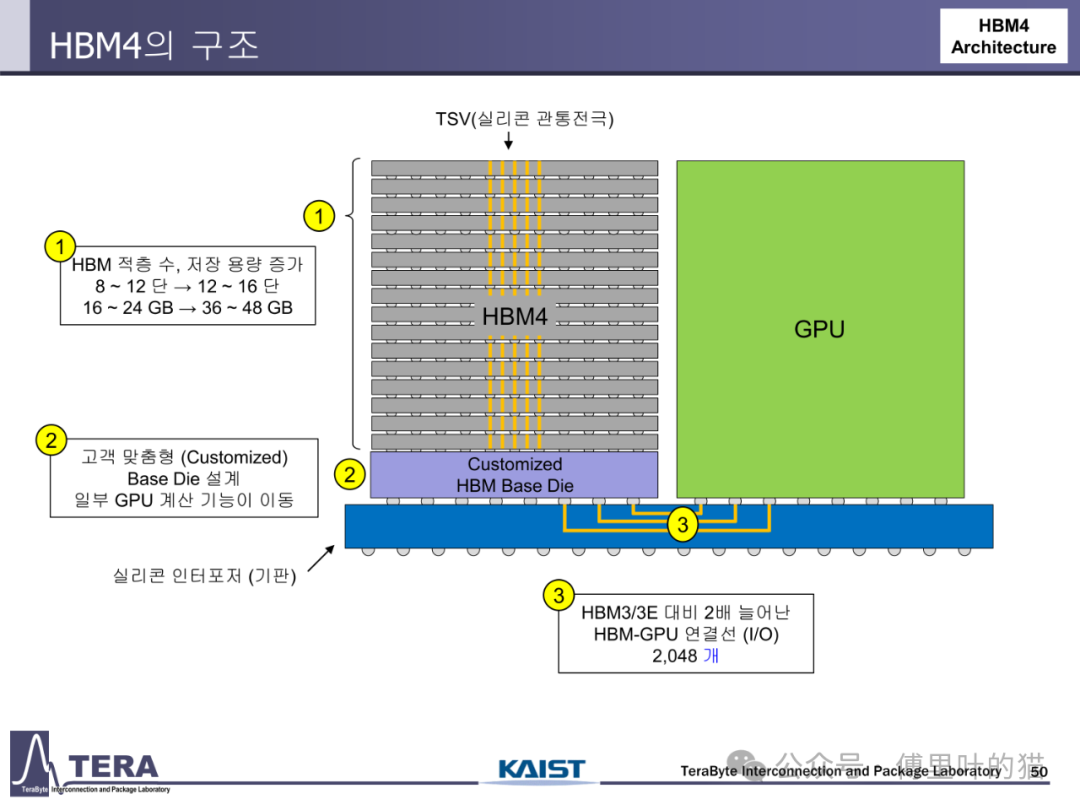
作为 HBM 技术从 3D 集成向计算存储融合过渡的关键节点,HBM4 在 KAIST TERA 实验室的路线图中扮演着承上启下的角色。这款计划于 2026 年推出的存储器,不仅在带宽、容量等性能指标上实现翻倍提升,更通过自定义基底 die 设计、HBM-LPDDR 融合架构与 AI 驱动的设计流程,重新定义了高带宽存储器的技术边界。
电气规格:性能跃升背后的技术协同
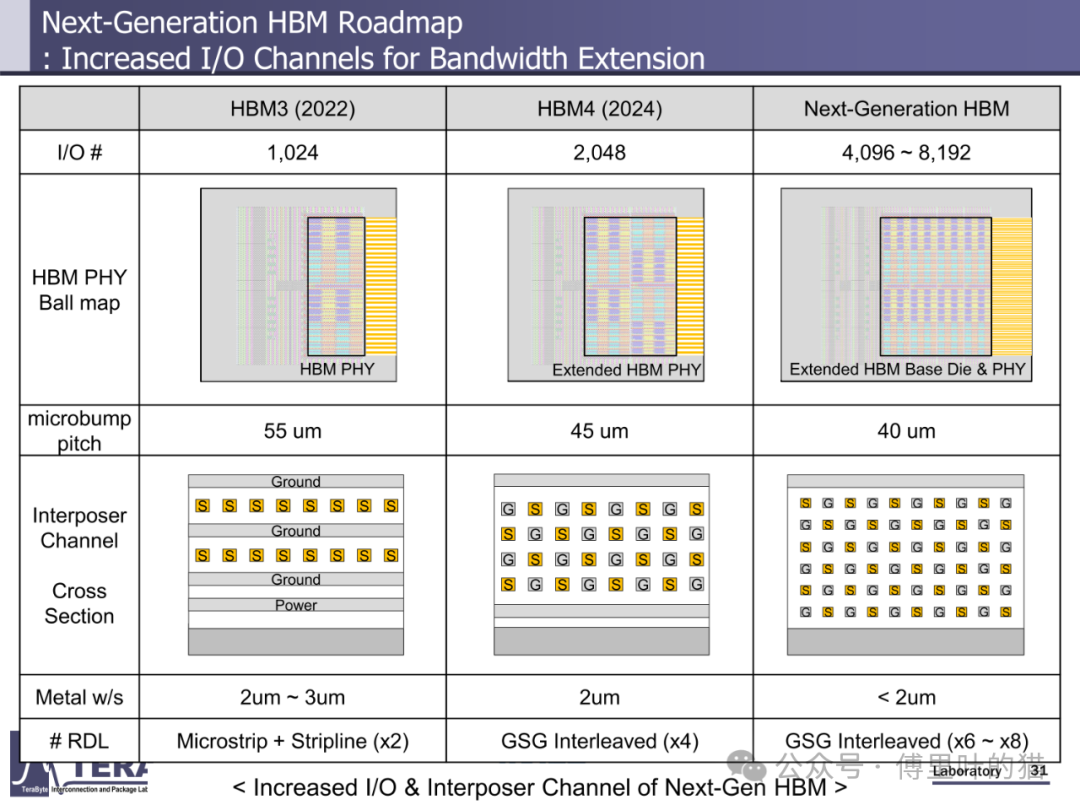
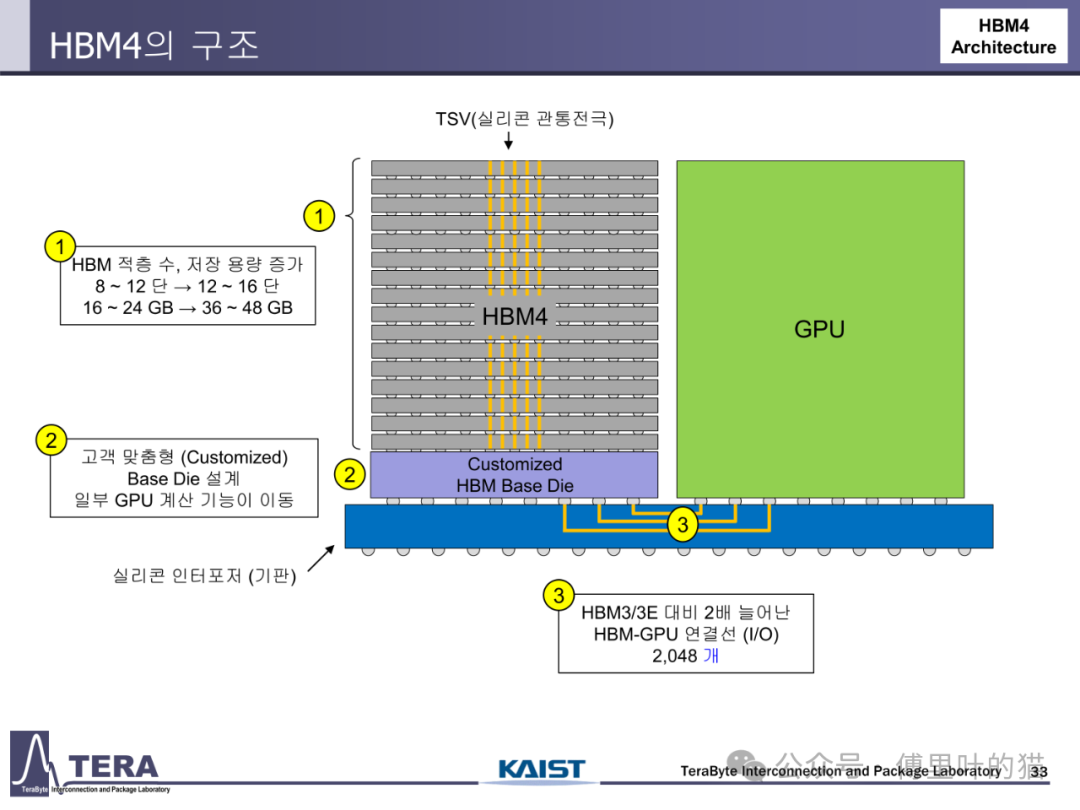
HBM4 的电气规格代表了当前存储器技术的巅峰水平。其数据速率维持在 8Gbps,但通过将 I/O 数量从 HBM3 的 1024 个翻倍至 2048 个,使总带宽达到 2.0TB/s,较 HBM3 的 819GB/s 实现了 144% 的提升。这种带宽增长并非简单的数量叠加,而是依赖于信号完整性技术与封装工艺的协同进步 ——HBM4 采用扩展的 HBM PHY(物理层)与 GSG(地 - 信号 - 地)交错式布线结构,在有限的中介层空间内实现 4 倍于 HBM3 的通道密度,同时通过 2μm 以下的金属线宽与多层 RDL(再分布层)设计,降低信号串扰与延迟。
存储容量的提升在 HBM4 中体现为 "堆叠层数 × 单 die 密度" 的双重突破。其堆叠层数从 HBM3 的 8/12-Hi 提升至 12/16-Hi,单 die 容量从 HBM3E 的 24Gb 进一步优化至 24Gb(注:文档中 HBM4 的 Capacity/die 为 24Gb,通过更多层数实现总容量提升),使单颗 HBM4 的容量达到 36/48GB,较 HBM3 的 16/24GB 实现翻倍。这种容量增长不仅满足 AI 模型对大内存的需求,更通过分层存储架构实现数据分级管理 —— 热数据存储于 HBM 高速层,冷数据下沉至 LPDDR 或 HBF 层,在性能与成本间取得平衡。
功耗与散热的平衡在 HBM4 中达到新高度。尽管带宽与容量翻倍,HBM4 的功耗仅从 HBM3 的 25W 增至 32W,能效比(带宽 / 功耗)提升近 50%。这得益于低电压信号传输技术与电源网络优化 ——HBM4 采用片上电源管理单元(PMU)与去耦电容(Decap)的智能布局,通过 AI 驱动的电源完整性分析,减少动态功耗与电压波动。散热方面,HBM4 首次全面采用直接芯片液冷(D2C)技术,取代 HBM3E 部分场景的风冷方案,通过微通道冷却结构将热密度控制在 500W/cm² 以下,确保高负载下的稳定运行。
封装与冷却:3D 集成的工艺革命
HBM4 的封装技术标志着从 "被动中介层" 向 "主动封装" 的转变。其采用 Microbump(MR-MUF)键合技术,将凸点间距缩小至 25μm 级,较 HBM3 的 35μm 提升 40%,使单位面积互连密度大幅提升。更关键的是,HBM4 首次引入 "自定义基底 die(Custom HBM Base Die)" 设计 —— 在传统 HBM 基底 die 中集成 NMC 处理器与 LPDDR 控制器,使基底 die 从单纯的信号转接单元进化为具备计算与存储管理功能的智能中枢。这种设计不仅减少了芯片间互连数量,更将部分 GPU 计算功能迁移至基底 die,缩短数据处理路径。
硅中介层在 HBM4 中实现了 "密度 × 尺寸" 的双重突破。相比 HBM3/3E,HBM4 的 HBM-GPU 连接 I/O 数量翻倍至 2048 个,中介层采用微带线与带状线混合布线结构,通过两层 RDL 实现信号分层传输,降低串扰。同时,中介层尺寸从 HBM3 的 46.2mm×48.5mm(2194mm²)提升至 HBM4 与 GPU 集成后的 85.2mm×56.2mm(4788mm²),支持更多 HBM 堆叠与 GPU die 部署。这种大尺寸中介层的制造依赖于先进的硅通孔(TSV)阵列技术,HBM4 的 TSV 密度达到 10000 个 /mm²,为高速信号传输提供物理基础。
冷却架构的革新是 HBM4 实现高性能的必要条件。直接芯片液冷(D2C)技术在 HBM4 中得到全面应用,通过在 HBM 基底 die 与 GPU die 上直接加工微通道,使冷却液体与发热元件零距离接触,换热效率较传统风冷提升 10 倍以上。D2C 技术采用闭环流体循环设计,冷却液从入口流经 HBM 与 GPU 的微通道,带走热量后从出口进入外部散热器,形成高效散热回路。这种设计使 HBM4 在 2.0TB/s 带宽下的运行温度控制在 85℃以内,满足数据中心长期稳定运行的需求。
架构创新:从存储器件到计算节点的质变
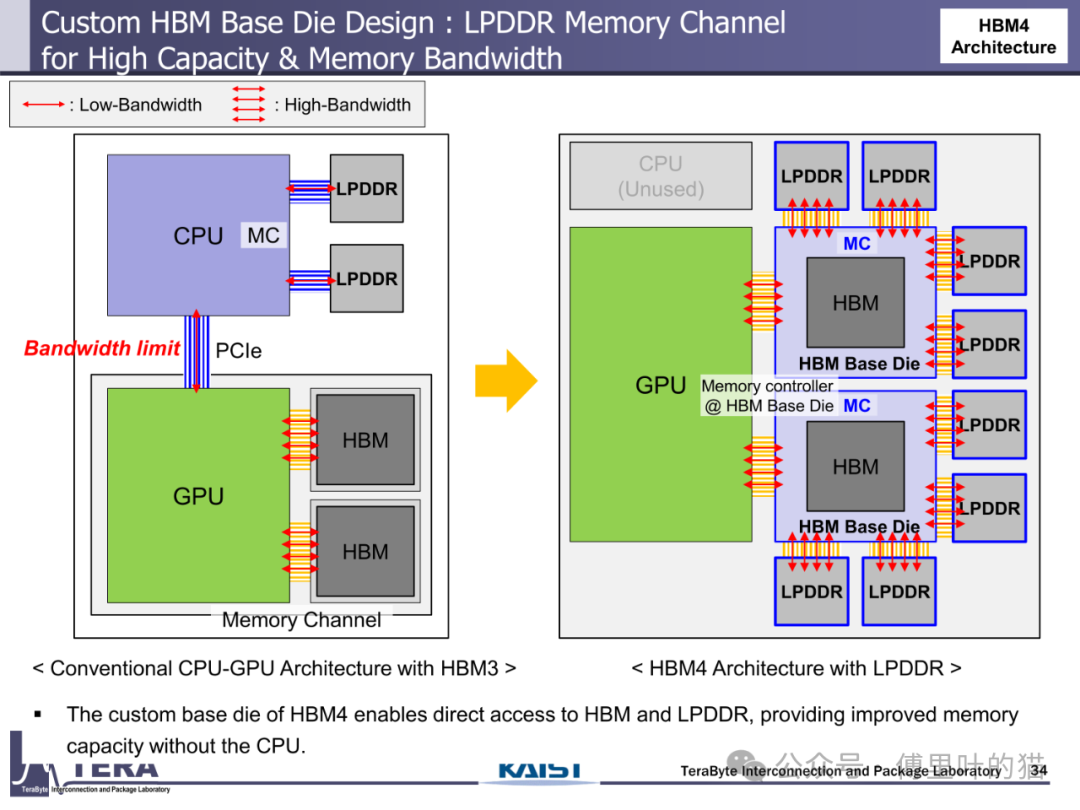
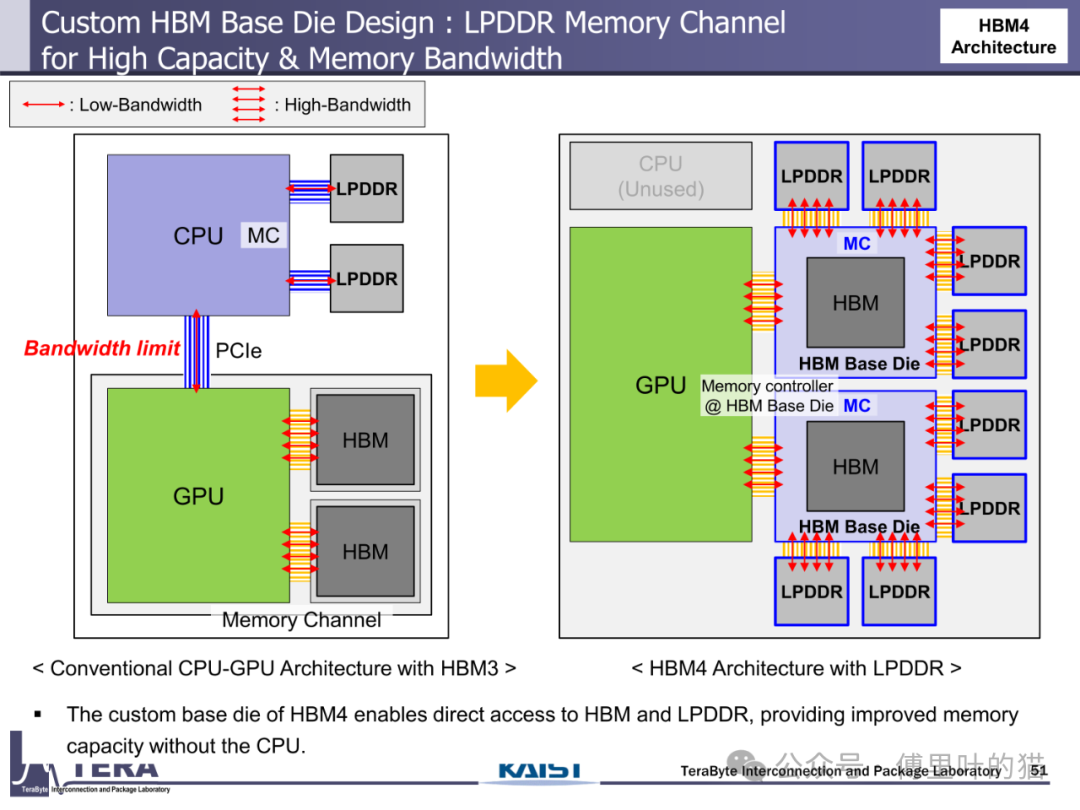
HBM4 最具革命性的突破在于其 "存储 - 计算" 融合架构。通过在自定义基底 die 中集成 NMC 处理器与 LPDDR 控制器,HBM4 实现了 "三重计算能力嵌入":首先,NMC 处理器可执行简单的数据预处理任务,如数据压缩、特征提取,减少向 GPU 传输的数据量;其次,LPDDR 控制器支持 HBM 与 LPDDR 的直接数据交互,绕开 CPU 实现存储层级间的高效数据迁移;最后,基底 die 中集成的缓存逻辑可对热点数据进行本地缓存,降低对 GPU 缓存的访问压力。这种架构使 HBM4 从单纯的存储器件转变为具备初级计算能力的智能节点。
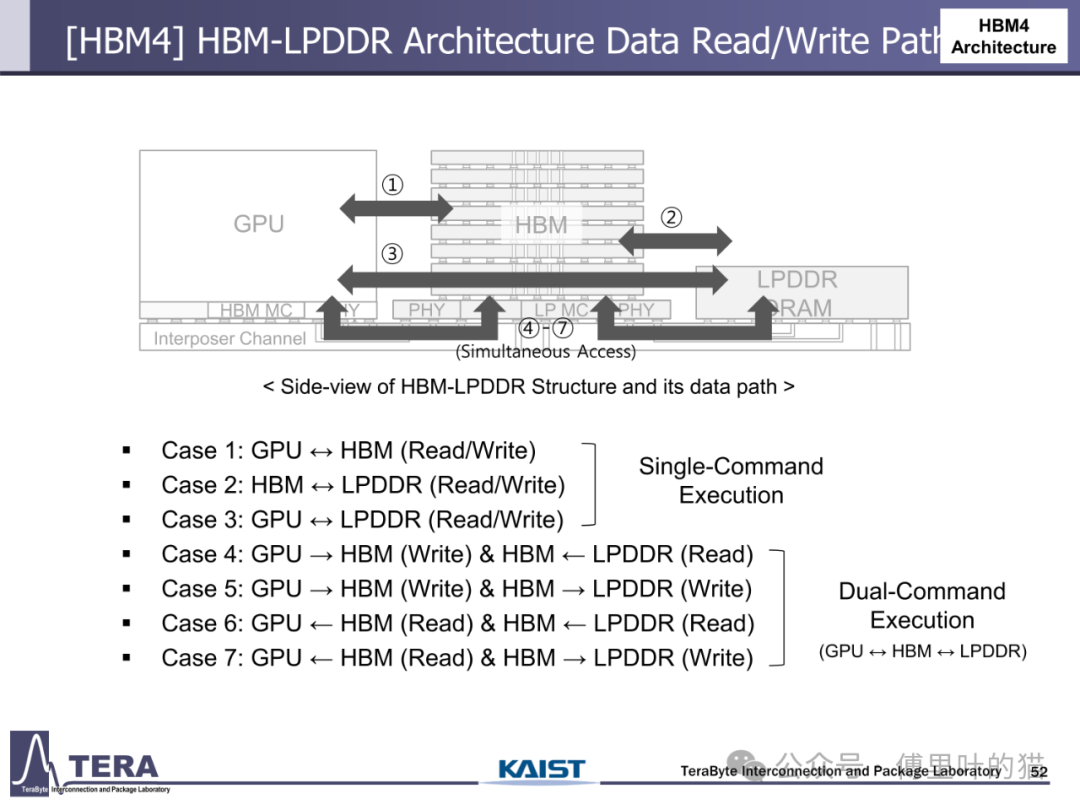
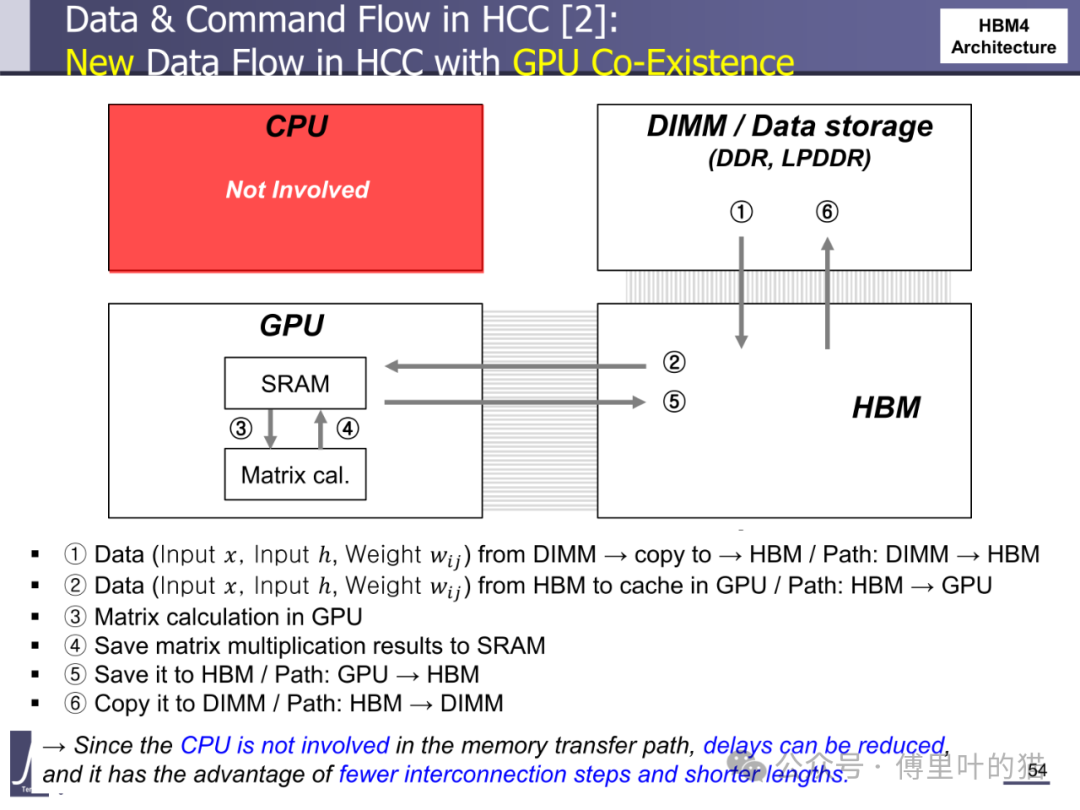
HBM-LPDDR 融合架构彻底重构了数据读写路径。在传统 HBM3 架构中,CPU 作为数据迁移的中枢,数据从 DIMM 到 HBM 需要经过 CPU-GPU-HBM 的多跳路径;而 HBM4 通过自定义基底 die 中的内存控制器,实现了 GPU 对 HBM 和 LPDDR 的直接访问。这种架构支持七种数据操作模式,包括 GPU 与 HBM 的直接读写、HBM 与 LPDDR 的双向迁移、GPU 与 LPDDR 的跨层级访问等。特别是在 "双命令执行" 模式下,GPU 可同时向 HBM 写入数据并从 LPDDR 读取数据,实现存储资源的并行利用,带宽利用率提升 30% 以上。
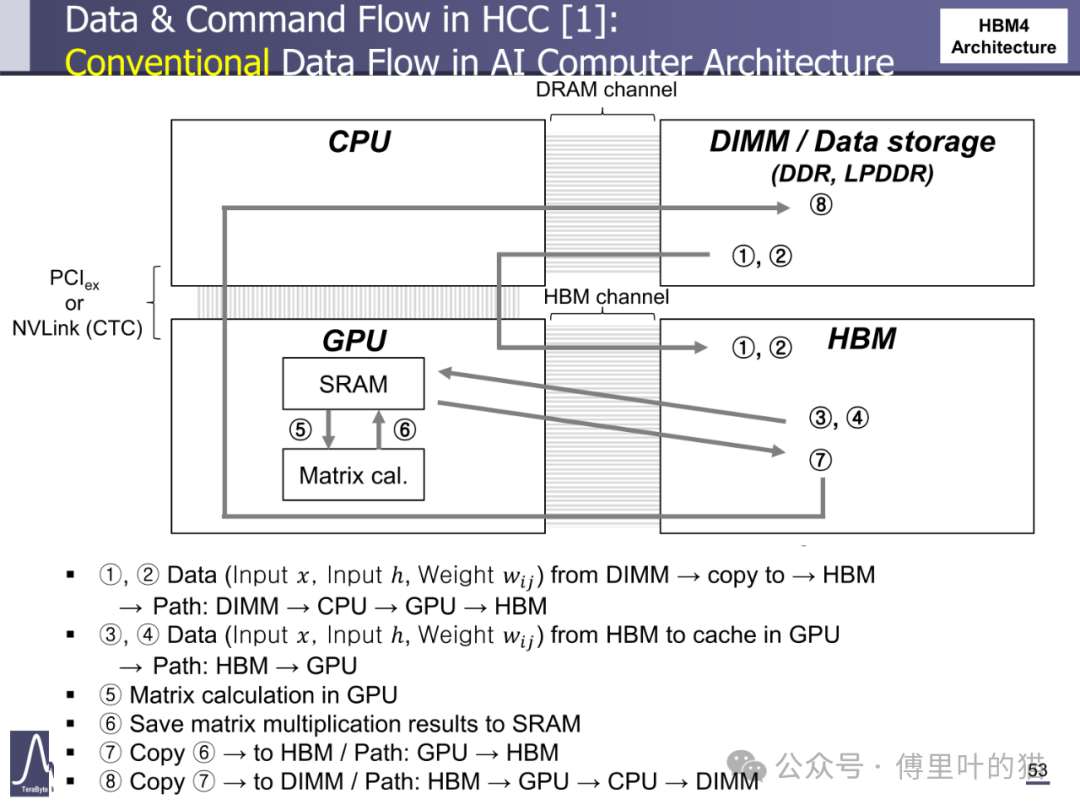
HBM Centric Computing(HCC)理念在 HBM4 中得到初步实践。HCC 架构通过优化数据流动路径,减少 CPU 在数据迁移中的参与度。在传统 AI 计算流程中,数据从 DIMM 到 HBM 需要经过 CPU 中转,涉及多次拷贝;而 HBM4 的 HCC 架构允许数据直接从 DIMM 写入 HBM,再由 GPU 直接读取,省略 CPU 参与的步骤。这种优化使数据迁移延迟降低 40%,尤其适合大型 AI 模型的训练场景 —— 在矩阵运算中,数据从 HBM 到 GPU 缓存的路径缩短,配合 NMC 处理器在基底 die 中完成的数据预处理,使整体计算效率提升 25% 以上。
AI 设计代理:智能驱动的研发范式变革
HBM4 的研发引入了全流程的 AI 设计工具,开启智能设计新时代。基于强化学习的优化算法被应用于微凸点布局、TSV 阵列设计与去耦电容放置 ——AI 模型通过学习海量设计案例,自动生成最优的互连拓扑与电源网络,相比传统人工设计,信号完整性提升 15%,电源噪声降低 20%。这种 AI 驱动的物理设计方法,不仅缩短了研发周期,更突破了人类设计师在复杂系统优化中的认知局限。
在接口设计层面,HBM4 利用 AI 工具解决高速信号传输中的挑战。考虑 PSIJ(封装系统交互)效应的 I/O 接口优化,通过机器学习模型预测封装对信号的影响,自动调整驱动器参数与端接电阻,确保 2048 个 I/O 在 8Gbps 速率下的信号质量。生成式 AI 技术被用于混合均衡器设计 ——AI 模型根据信道特性自动生成均衡滤波器系数,实现对高频衰减的动态补偿,使信号眼图张开度提升 30%,满足高速串行传输的要求。
AI 设计代理在 HBM4 中的最高阶应用是 "设计空间探索(DSE)"。通过构建多物理场仿真模型与机器学习代理模型,AI 工具可在数小时内完成传统方法需要数周的设计优化。例如,在散热设计中,AI 可同时优化微通道结构、流体流速与材料选择,在满足散热需求的前提下最小化功耗;在电源设计中,AI 通过分析功耗分布与热耦合效应,自动生成去耦电容的最优配置方案。这种智能设计范式使 HBM4 的研发效率提升 50%,同时实现了传统方法难以达到的多目标优化效果。
HBM4 的出现标志着存储器技术进入 "存储 - 计算 - 智能" 三位一体的发展阶段。从电气规格的性能跃升,到封装冷却的工艺突破,再到架构层面的计算融合与设计流程的智能化,HBM4 不仅是一个存储器迭代型号,更是未来计算架构的关键支点。随着 HBM 技术沿着 KAIST TERA 实验室的路线图持续演进,我们正见证着 "存储即计算" 这一愿景从概念走向现实,为 AI 时代的算力革命提供坚实的硬件基础。

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
参考文献链接
人工智能芯片与自动驾驶

 浙公网安备 33010602011771号
浙公网安备 33010602011771号