
Vllm v1 部署deepseek 深刻理解
年初部署了deepseek,距离现在有一阵子了,两台H800部署,整体下来首token3s以内,输入1000,输出500-900左右的情况下算力能支持到32并发。使用vllm部署,但是在部署的时候因为没有测试环境,直接上的生产,所以对于部署时的参数没有充分的调整。导致最大长度一直是32k。
这个地方我起初一直认为是显存不够,导致不能将最大上下文长度设置到128k,随即想法遭到了领导的质疑,在几次思索下我也对于目前的状态表示了怀疑,开启了探索。部署环境如下:
显卡:H800*16
推理引擎vllm
部署模型deepseek
并行方式:张量并行=8,流水线并行=2
一、deepseek显存分析
首先是对deepseek部署的显存做出分析。
关于显存分析有现成的网站,这里推荐一个(碰巧搜到的一个)https://tools.thinkinai.xyz/#/server-calculator。这里不做详细的显存分析,大家直接看这个网站给出的生产环境所需显存大小,在32k的情况已经快要承包内存了,我还看过其他的这种显存分析网站,相比较还是这好一点,原因是大多数的显存分析只是对于静态的权重和激活等做出分析,实际上对于前向推理,还要考虑显存占用的峰值,这一点主要体现在输出的中间过程和激活。如下图。
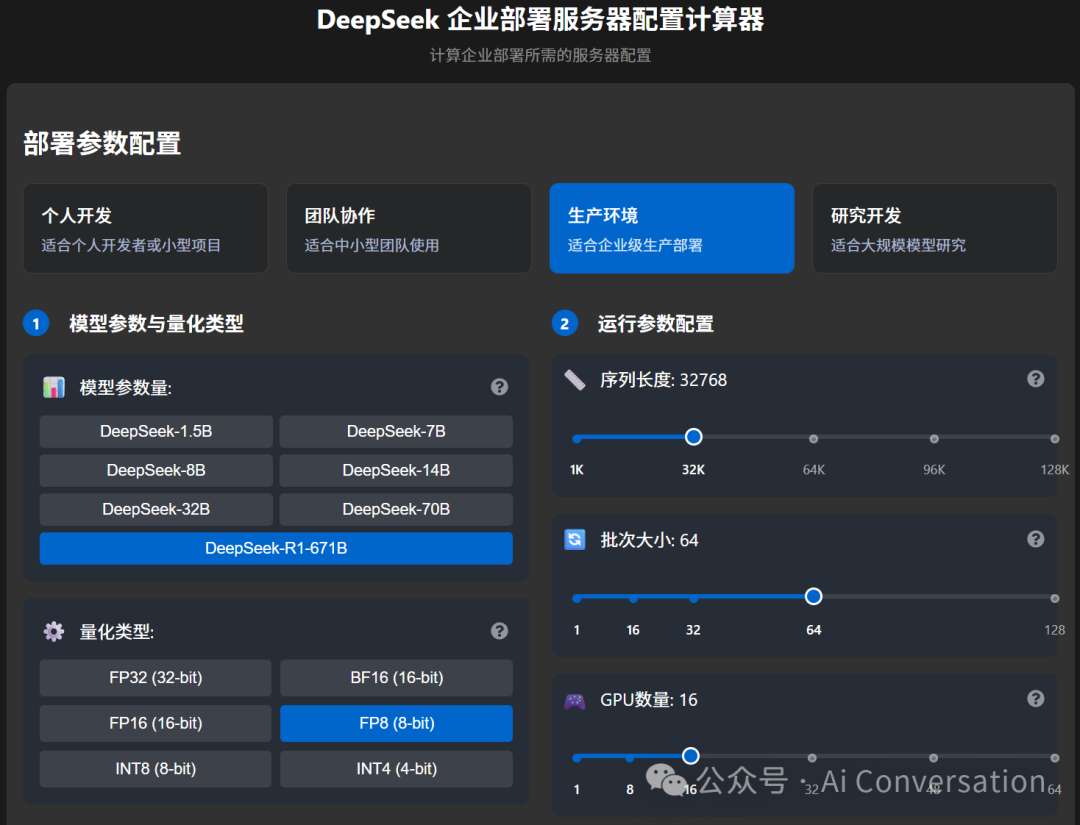
添加图片注释,不超过 140 字(可选)
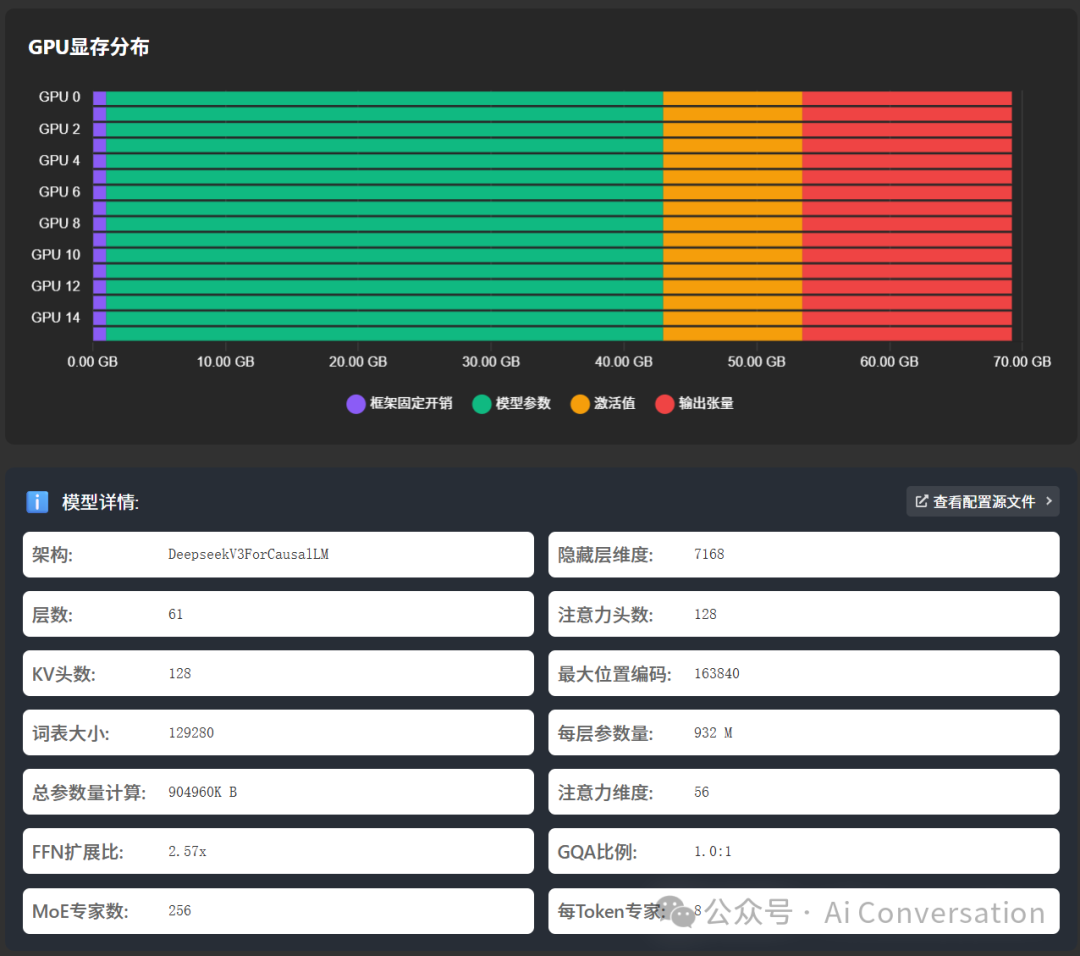
添加图片注释,不超过 140 字(可选)
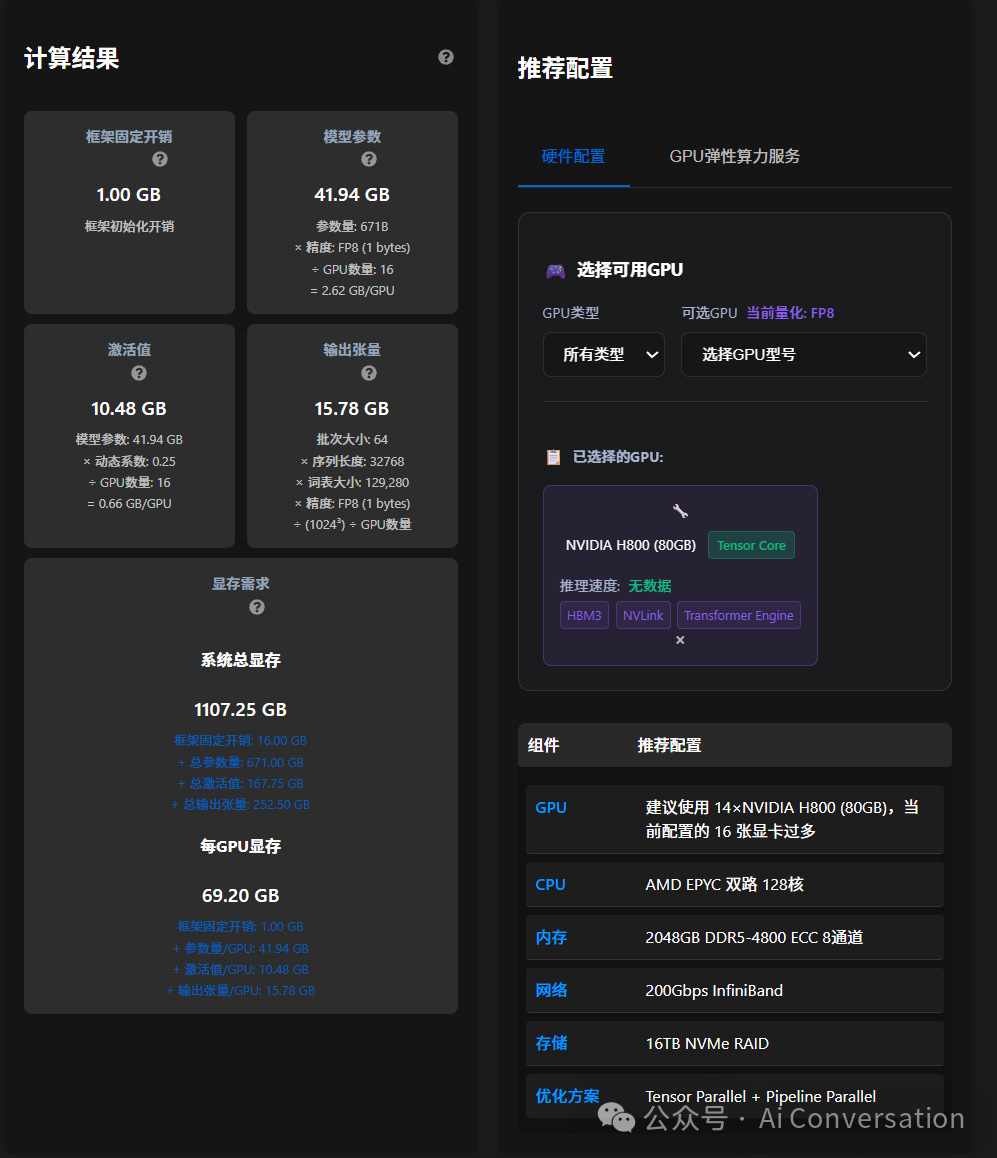
添加图片注释,不超过 140 字(可选)
二、vllm Chunked Prefill
神奇的是我在部署的时候可以设置最大模型长度,这一点一下让我有些错愕,不知道是什么原因。我采用的主要参数是max-model-len和max-num-batched-tokens、max-num-seqs。其中max-num-seqs表示最大的并发推理数量,max-model-len表示模型最大推理长度。主要是受限于模型本身(模型训练的影响)和显存。max-num-batched-tokens表示一个批次的最大处理tokens数量。为啥要有这个max-num-batched-tokens?这一点主要是vllm的设计要实现连续批处理(Continuous Batching)和分页注意(PagedAttention),这也是vllm的优势。我的配置是max-model-len=128000 max-num-batched-tokens=32000.这种配置在之前的vllm版本是会报错的,但是v1版本就解决了这个问题,也就是利用了Chunked Prefill。请看官方的解释,如下图:

添加图片注释,不超过 140 字(可选)
三、Chunked Prefill原理
Chunked Prefill在2023年发表,论文名称为:SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills
论文动机:大模型部署时特别是部署moe这种超大模型,就需要多个gpu服务器节点一同支持。部署的方式我们会选用流水线并行,也就是pipeline并行。大模型推理分prefill 和 decode 两个阶段,因为prefill阶段是计算密集型,但是decode阶段是访存密集型,这就造成了两者的速度差异非常大,在流水线并行时就会造成很多的气泡。
讲的更清楚一点:为什么流水线并行会有很多气泡?流水线并行将一个大的神经网络模型按层(或模块)切分,并将这些部分分配到不同的计算设备(如 GPU)上。数据(通常是一个batch)像流水线一样依次通过这些设备。
气泡产生的主要原因在于依赖关系和启动/排空阶段:
1 启动阶段(Startup Phase):
-
当第一个批次进入流水线时,只有第一个设备(Stage 1)在工作。
-
当第一个微批次移动到第二个设备(Stage 2)时,第一个设备开始处理第二个批次,但此时第三、第四个设备仍然是空闲的。
-
这种空闲状态会一直持续,直到第一个批次到达最后一个设备。在这个过程中,许多设备在等待数据,形成了前向传播的启动气泡。可以想象一个,因为prefill 和 decode 计算时间大不一样,造成了气泡严重的情况。
2 排空阶段(Drain/Flush Phase):
-
当最后一个批次通过第一个设备后,该设备就变得空闲了,因为它没有新的数据需要处理。
-
随着最后一个批次在流水线中前进,越来越多的设备会相继完成它们的工作并进入空闲状态。
-
这个过程形成了反向传播(如果是训练)或仅前向传播(如果是推理)的排空气泡。
简单来说,由于每个设备必须等待前一个设备完成其工作才能开始,并且在批次的开始和结束时,并非所有设备都能同时工作,这就导致了大量的 GPU 空闲时间,即“气泡”。流水线越深(设备越多),气泡问题就越严重。因此论文就尝试解决这个问题,提出了chunkedprefills。
做法:Prefill 阶段(预填充/提示处理),这个阶段通常计算量很大,因为需要为提示中的每个 Token 计算注意力(Attention),阶段的特点是并行度高,但序列长度可能很长。Chunked Prefill 是一种针对 Prefill 阶段 的优化技术。它的核心思想是:将长的输入提示(Prompt)分割成多个更小的块(Chunks),然后将这些块像流水线中
的微批次一样,分批送入模型进行处理。
具体来说:
-
不是一次性处理整个长提示,而是将其切分为 Chunk 1, Chunk 2, ..., Chunk N。
-
这些 Chunks 依次通过流水线的各个阶段。
-
每个 Chunk 在通过一个阶段后,会将其计算出的键(Key)和值(Value)缓存(KV Cache)传递给下一个 Chunk(在同一阶段内)或下一个阶段(当它移动时)。
Chunked Prefill 主要通过以下方式减少流水线气泡,尤其是在 Prefill 阶段:
-
实现流水线并行: 通过将长提示切块,它创造了类似于微批次的单元,使得在 Prefill 阶段应用流水线并行成为可能。如果没有分块,整个 Prefill 阶段就像一个巨大的、不可分割的任务,无法在流水线中有效流动。
-
提前启动后续阶段: 当第一个 Chunk 完成第一阶段并进入第二阶段时,第二个 Chunk 可以立即进入第一阶段。这与标准流水线并行处理微批次的方式类似,显著减少了启动阶段的气泡。相比于等待整个长提示处理完一个阶段再进入下一个阶段,这种方式可以让流水线更快地“热身”并保持更高的利用率。
-
更好的资源利用: 由于 Prefill 阶段计算密集,将其分块并流水化处理,可以更均匀地分配计算负载,让各个 GPU 尽可能保持繁忙,从而减少空闲时间(气泡)。
-
与解码阶段的结合: Chunked Prefill 可以与后续的解码阶段更平滑地结合。一旦最后一个 Chunk 完成 Prefill 并生成第一个 Token,系统就可以无缝切换到解码阶段的流水线处理。
四:参考链接
1 https://docs.vllm.ai/en/latest/configuration/optimization.html#parallelism-strategies
2 https://www.zhihu.com/search?type=content&q=Chunked%20Prefill
3 https://github.com/vllm-project/vllm/issues/18681
4 https://arxiv.org/abs/2308.16369
人工智能芯片与自动驾驶

 浙公网安备 33010602011771号
浙公网安备 33010602011771号