
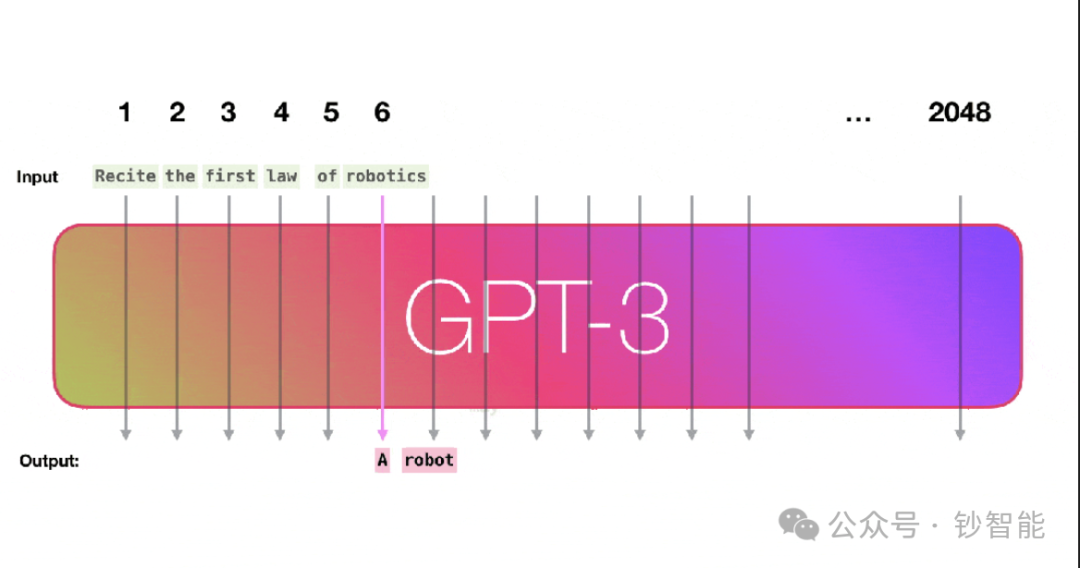
LLM细节:Batch推理Prompt
添加图片注释,不超过 140 字(可选)
Batch Inference结果差异的本质是随机性参数控制不足与确定性解码中批量处理机制引入的系统性偏差共同作用的结果。在旋转位置编码模型中,输入填充导致的位置索引混乱是核心矛盾,而数值精度和Batch Size的影响进一步放大了这种差异。工程实践中,通过输入对齐和固定填充策略可有效缓解,根本解决需依赖模型架构和框架层面的优化。
当使用大语言模型(LLM)进行批量推理(Batch Inference)时,即使关闭随机采样(sampling=False),结果仍可能与单例推理(batch_size=1)不同,核心原因可分为随机性相关因素和确定性解码中的系统性偏差两类:
随机性相关因素(可通过参数控制)
-
温度参数(Temperature)
-
:强制选择概率最高的token(贪心解码),结果高度确定。
-
:按概率分布随机采样,数值越大,输出多样性越高,批量推理结果差异越明显。
-
控制输出概率分布的熵值:
-
Top-K与Top-P(Nucleus Sampling)
-
Top-K:限制候选token为概率最高的K个,K越小,随机性越低(如K=1时等价于贪心解码)。
-
Top-P:累积概率超过阈值P的最小候选集,P越接近1,候选集越大,随机性越高。
若未关闭采样(sampling=True),上述参数直接导致批量结果的随机性差异;即使关闭采样(sampling=False,默认贪心解码),仍可能受其他确定性因素影响。
确定性解码中的系统性偏差(核心难点)
当sampling=False时,模型采用贪心解码(每一步选概率最高的token),但批量推理结果仍可能不同,核心原因是批量处理时的输入预处理和计算机制引入了隐性差异:
-
输入填充(Padding)与位置编码的冲突
-
即使填充值为<pad>或0,模型对填充位置的处理(如注意力掩码)可能影响上下文建模,尤其在多模态模型中,图片编码的位置可能与文本填充产生交互。
-
批量输入需对齐长度,填充位置(左/右)改变token的绝对位置索引。
-
对旋转位置编码(如RoPE、ALiBi)而言,位置索引直接影响编码计算(如ChatGLM、Qwen、Llama 2采用的RoPE),左填充会导致位置索引逆序,与单例推理(无填充)的位置编码完全不同,进而改变注意力权重和输出。
-
填充方向(Padding Side: Left/Right):
-
填充值(Padding Value):
-
批量大小(Batch Size)的影响
-
不同Batch Size导致计算图结构变化(如矩阵并行的分块方式),在混合精度训练(FP16/BF16)下,浮点运算的舍入误差累积差异会被放大,导致中间层激活值不同,最终输出分歧。
-
案例:当Batch Size=1时无填充,而Batch Size>1时需填充,直接触发位置编码的不一致(见上述填充问题)。
-
数据类型(Dtype)与数值精度
-
FP16/BF16的低精度运算在批量矩阵乘法(如Attention的Q/K/V计算)中引入舍入误差,不同Batch Size下误差累积路径不同,导致softmax输出概率轻微变化,贪心解码时可能选择次优token。
-
特别地,RMSNorm等归一化层对浮点精度敏感,低精度下的均值/方差计算误差可能放大差异。
-
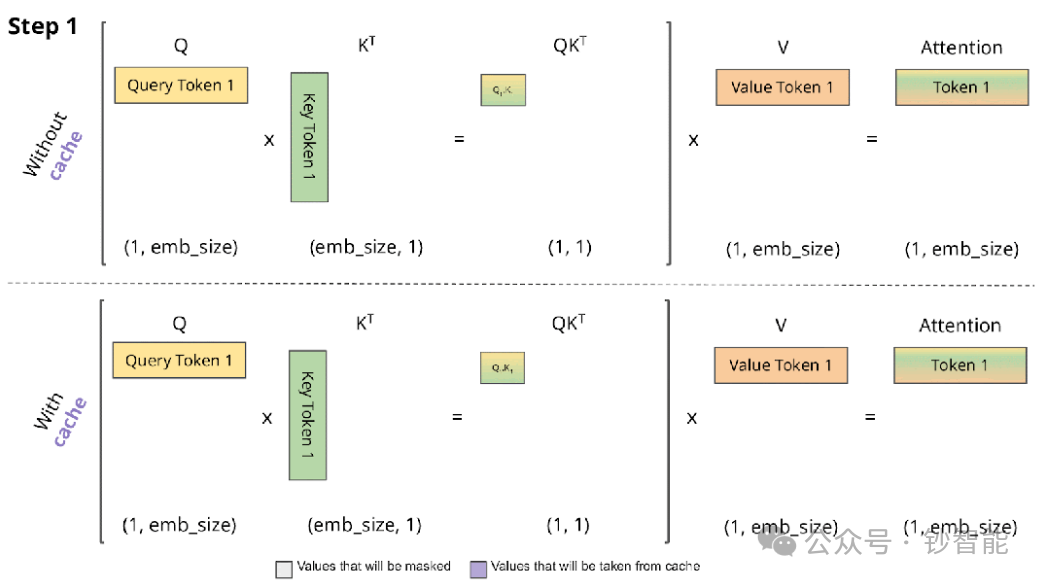
KV-Cache机制的批量管理
-
开启KV-Cache时,批量处理中不同样本的缓存更新顺序可能引入微小差异;
-
即使关闭KV-Cache,填充导致的位置编码问题仍占主导,因此无法解决根本矛盾。
添加图片注释,不超过 140 字(可选)
关键模型特性:旋转位置编码的“致命伤”
上述问题在使用旋转位置编码(RoPE及其变种)的模型中尤为显著,原因在于:
-
RoPE通过三角函数对绝对位置索引进行编码,位置索引直接决定编码向量(如第i个token的位置编码为rope(i))。
-
批量填充时,同一batch内不同样本的token实际位置(如真实文本长度+填充位置)与单例推理的绝对位置完全不同,导致编码向量差异,进而改变注意力权重和生成逻辑。
-
对比:固定位置编码(如BERT的正弦编码)不依赖绝对索引,影响较小;相对位置编码(如T5的relative position bias)对填充更鲁棒。
实验验证与现象总结
-
当输入长度一致时(无填充):
-
若Batch内所有样本token长度相同(如同一Prompt+相同图片数量的多模态输入),批量推理结果与单例一致(因无需填充,位置编码统一)。
-
当输入长度不一致时(需填充):
-
差异随Batch Size、填充方向、Dtype变化,旋转位置编码模型差异显著,固定位置编码模型差异较小。
-
微调的缓解作用:
-
若微调时输入处理方式(如固定填充方向、长度)与推理一致,模型对填充引入的位置偏差产生适应性,批量结果差异可缩小(如F1偏差<3%)。
解决方案与工程实践建议
-
消除随机性的基础设置 # 强制确定性解码(贪心算法) generate(..., do_sample=False, temperature=0.0, top_k=1, top_p=0.0)
-
规避填充相关偏差的核心手段
-
输入对齐:预处理时确保同一Batch内所有样本token长度一致(如截断或padding到固定长度),避免动态填充。
-
固定填充策略:统一使用右填充(主流框架默认),并在微调时保持一致的填充方式。
-
位置编码适配:对旋转位置编码模型,可尝试在推理时禁用填充(仅适用于输入长度可控场景)。
-
数值稳定性优化
-
使用FP32精度推理(牺牲速度,换取确定性),或在框架层面优化混合精度计算顺序(如PyTorch的deterministic算法)。
-
长期解决方案
-
期待模型架构改进:如采用更鲁棒的相对位置编码,或在填充时保留真实位置索引(如Hugging Face未来可能支持的position_ids显式传入)。
-
社区进展:参考ChatGLM-6B、Qwen等模型的Issue讨论,关注框架补丁(如Transformers库对批量位置编码的修复)。
参考资源与扩展阅读
-
核心Issue与讨论
-
ChatGLM-6B批量推理结果不一致
-
Qwen模型批量推理偏差分析
-
Hugging Face Transformers批量解码问题
-
学术研究
-
OpenReview论文:Batch Size对推理结果的影响(指出填充和位置编码是核心因素)
参考文献链接
人工智能芯片与自动驾驶

 浙公网安备 33010602011771号
浙公网安备 33010602011771号