
YOLA 打破低光检测困境,解锁光照不变特征新力量
You Only Look Around: Learning Illumination Invariant Feature for Low-light Object Detection
一、研究背景与意义
在计算机视觉领域,目标检测作为关键技术,广泛应用于自动驾驶、安防监控等诸多场景。深度学习的发展推动了目标检测技术的显著进步,但低光环境下的目标检测仍然是一个极具挑战性的难题。低光环境会导致图像质量下降、可见度降低,在夜间监控和黄昏驾驶等场景中,误检率大幅增加。传统应对低光目标检测的方法主要集中在图像增强技术上,虽然这些方法在改善视觉效果和感知质量方面有一定成效,但由于其优化目标是人类视觉感知,与机器学习模型进行有效准确目标检测的需求并不总是一致,因此往往无法直接提升目标检测性能。
另一个研究方向是对预训练模型进行微调以适应低光条件。通常,检测器先在大量光照良好的数据集上进行训练,然后在较小的低光数据集上微调。然而,这些技术大多严重依赖合成数据集,这限制了它们在实际场景中的应用。近期一些方法利用拉普拉斯金字塔进行多尺度边缘提取和图像增强,或者利用分层特征提升低光视觉效果,但这些基于任务特定损失驱动的方法,因光照变化多样而面临较大的解空间问题。
在这样的背景下,文章提出的You Only Look Around(YOLA)框架意义重大。它从特征学习的全新视角出发,利用兰伯特图像形成模型学习光照不变特征,为低光环境下的目标检测开辟了新途径,有望突破现有方法的局限,显著提升低光目标检测的性能。
二、相关工作
2.1 通用目标检测
当前现代目标检测方法主要分为基于锚点和无锚点两类。基于锚点的检测器源于滑动窗口范式,将密集锚点看作是在空间排列的滑动窗口,通过匹配策略(如交并比IoU、Top-K等)为锚点分配正负样本,常见的方法有R-CNN、SSD、YOLOv2、RetinaNet等。无锚点检测器则摆脱了手工设置锚点超参数的限制,增强了模型的泛化能力,代表性方法有YOLOv1、FCOS、DETR等。然而,无论是基于锚点还是无锚点的检测器,在低光条件下的性能都不尽人意。
2.2 低光目标检测
低光目标检测的研究主要集中在几个方向。一是利用图像增强技术直接提升低光图像质量,如KIND、SMG、NeRCo等方法,增强后的图像用于后续检测的训练和测试阶段。但图像增强的目标与目标检测不同,这种策略并非最优,平衡视觉质量和检测性能的超参数调整也较为复杂。二是探索在训练过程中集成图像增强和目标检测,但仍面临诸多挑战。三是像MAET、IA - YOLO和GDIP等方法,通过在合成数据集上训练,设计可微图像处理模块来提升低光目标检测性能,但对合成数据集的依赖限制了其实际应用。近期一些方法利用多尺度分层特征,以任务特定损失驱动来改善低光视觉,但与本文方法不同,它们通常需要额外的低光增强数据集或合成数据集。
2.3 光照不变表示
为减少光照对下游任务性能的影响,研究人员探索了多种光照不变技术。在高级任务方面,有用于人脸识别的光照归一化方法,以及利用光照不变图像表示改善汽车场景理解和分割、实现交通目标检测的方法。在低级任务中,一些基于物理的不变量,如颜色比率(CR)和交叉颜色比率(CCR),被用于固有图像分解。然而,这些方法大多依赖固定公式导出的光照不变表示,可能无法充分捕捉特定于下游应用的多样复杂光照场景。相比之下,本文方法能够以端到端的方式自适应学习光照不变特征,增强了与下游任务的兼容性。
添加图片注释,不超过 140 字(可选)
三、方法
3.1 光照不变特征
基于兰伯特假设,在二色反射模型的物体反射项中,图像中像素在某一颜色通道的值可以表示为 。其中,和分别表示表面法线和光照方向,是它们之间的相互作用函数,表示点处光源在颜色通道的光谱功率分布,表示点处物体在颜色通道的固有属性(反射率)。
由于仅由位置分量决定,与颜色通道无关,通过计算同一空间位置不同颜色通道值的差异,可以有效消除的影响。利用相邻像素光照近似均匀的假设,计算相邻像素值的差异,能进一步消除光照项的影响。以相邻像素和以及红()、蓝()通道为例,定义交叉颜色比率为 ,对其取对数并代入像素值表达式,在光照近似均匀假设下,可简化得到光照不变形式: 。
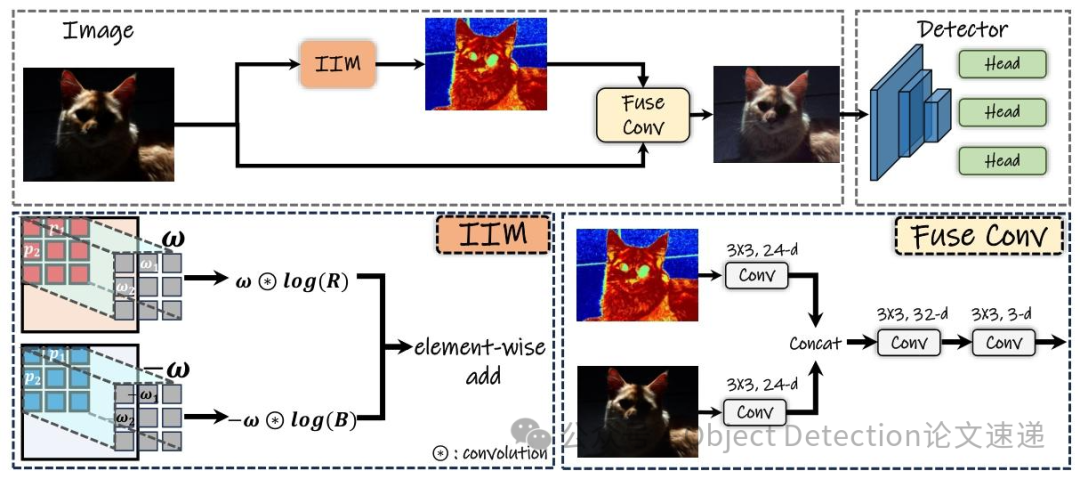
这表明同一通道内的减法可消除光照项(通过零均值约束实现),跨通道减法可去除表面法线和光照方向项,为设计学习光照不变范式提供了思路。实际中,使用卷积操作提取特征,提取的特征经IIM处理融合后送入检测器。当使用固定权重(相邻像素差值为1或 - 1)时,称为IIM - Edge。
3.2 光照不变模块(IIM)
虽然上述计算光照不变特征的公式简单有效,但固定的形式存在局限性,难以充分捕捉不同场景下特定于下游任务的多样复杂光照变化。为解决这一问题,本文采用卷积操作将公式改进为更具适应性的形式,通过学习一组卷积核来提取光照不变特征,提高了特征提取的鲁棒性和效率。
IIM主要包含可学习卷积核和零均值约束两个部分。可学习卷积核的目标是将固定的光照不变特征转化为可学习形式,通过学习一组卷积核(为卷积核数量,为卷积核大小),将交叉颜色比率(CCR)扩展为更通用灵活的形式 ,其中和分别表示卷积核内的一组像素位置和相应权重。为保证扩展形式仍满足光照不变性,的对数需满足 ,这样就能消除项和项,最终特征可表示为 。类似地,可得到和,形成应用卷积核到图像的特征 。
零均值约束方面,在卷积核的背景下,为确保消除光照项,只需保证卷积核的均值为0,即 ,通过来实现该约束。
四、实验
4.1 实验设置
本文使用流行的基于锚点的检测器YOLOv3和无锚点的检测器TOOD对提出的方法进行评估。两个检测器均先在COCO数据集上进行预训练,然后在目标数据集上使用随机梯度下降(SGD)优化器进行微调,初始学习率为1e - 3。对于ExDark数据集,将图像大小调整为608×608,训练24个epoch,在第18和23个epoch时学习率降低为原来的1/10。对于 +DARK FACE数据集,TOOD检测器的图像大小调整为1500×1000,YOLOv3保持608×608的分辨率,与MAET方法一致,YOLOv3训练20个epoch,在第14和18个epoch时学习率下降,TOOD训练12个epoch,在第8和11个epoch时学习率下降。此外,还实现了一个简单的光照不变模型YOLA - Naive,通过去除IIM并使用均方误差(MSE)损失来确保各种光照特征的一致性。实验使用MMDetection工具包实现YOLA。
4.2 数据集
评估方法使用了两个真实场景数据集:ExDark和 +DARK FACE。ExDark数据集包含7363张从低光环境到黄昏的图像,涵盖12个类别,其中3000张用于训练,1800张用于验证,2563张用于测试,评估指标为平均精度均值()和IoU阈值为0.5时的平均召回率。 +DARK FACE数据集包含6000张标记的人脸边界框图像,5400张用于训练,600张用于测试,评估指标同样为召回率和。此外,还在COCO 2017数据集上评估方法的泛化能力。
4.3 低光目标检测
添加图片注释,不超过 140 字(可选)
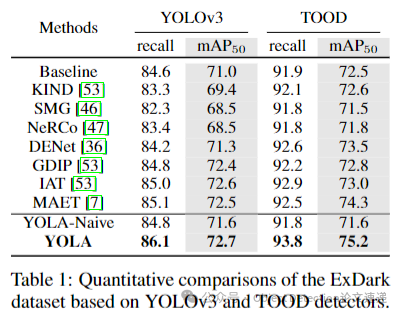
在ExDark数据集上,基于YOLOv3和TOOD检测器的实验结果表明,与低光图像增强(LLIE)方法(如KIND、SMG、NeRCo)相比,考虑机器感知的端到端方法(如DENet、MAET)在目标检测中通常能取得更好的结果,但本文的YOLA方法更为简单有效。与YOLA - Naive相比,YOLA性能更优,因为其提取的特征固有地具有光照不变性,解空间更小。在基于锚点的YOLOv3和无锚点的TOOD检测器上,YOLA分别比基线提高了1.7和2.5的,展现出优越性和有效性。同时,YOLA的参数数量(0.008M)明显低于大多数LLIE和低光目标检测技术,在轻量级实际应用中具有潜力。
4.4 低光人脸检测
添加图片注释,不超过 140 字(可选)
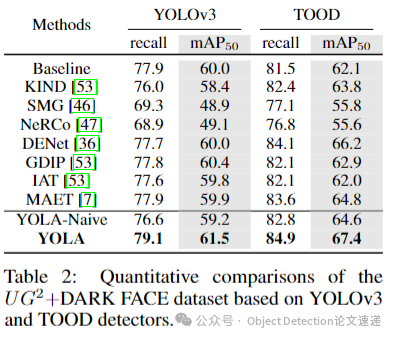
在 +DARK FACE数据集上的实验显示,大多数集成到YOLOv3检测器中的LLIE方法未能取得令人满意的结果,这表明基于增强的方法可能会损害小尺寸人脸的细节,阻碍有用特征的学习。而考虑目标检测任务的方法表现更好,YOLA在该数据集上的提高了1.5,在先进的TOOD检测器上也优于其他LLIE和低光目标检测方法,达到了67.4的,突出了YOLA在提高基于锚点和无锚点检测范式性能方面的优越泛化能力。
4.5 定性结果
使用TOOD检测器在ExDark和 +DARK FACE数据集上的定性结果表明,现有方法存在漏检情况,而YOLA在检测这些具有挑战性的案例时表现出色,在复杂场景中展现出优越性能。虽然YOLA没有明确约束图像亮度,但增强后的图像在最终结果中往往显示出亮度增加,由于对增强图像的值范围未加约束,可视化结果可能略显灰暗,实验中对图像进行了通道归一化处理。
4.6 消融实验

添加图片注释,不超过 140 字(可选)
4.6.1 光照不变模块(IIM)
在TOOD检测器上评估IIM的有效性,结果表明,通过引入IIM来提取光照不变特征,检测器在ExDark和 +DARK FACE数据集上分别获得了2.3和4.8的性能提升。
4.6.2 零均值约束
去除卷积核的零均值约束后,TOOD检测器在两个数据集上的性能下降,分别降低了0.3和0.5,这表明利用零均值约束减轻光照影响对低光目标检测有益。
4.6.3 可学习卷积核
评估固定卷积核(IIM - Edge)和可学习卷积核的效果,结果显示IIM - Edge在ExDark和 +DARK FACE数据集上分别比基线提高了1.3和2.4的,证明了引入光照不变特征对低光目标检测的益处。将固定卷积核替换为可学习卷积核后,在两个数据集上又分别获得了1.4和2.9的提升,进一步证明了可学习卷积核的有效性。此外,通过施加一致性损失(II Loss)来稳定卷积核学习,防止卷积核出现平凡解,减轻光照不均匀的影响。可视化结果显示,固定卷积核提取的特征相对单一,主要是简单的边缘特征,而可学习卷积核能够提取更多样化的模式,产生更丰富、更具信息性的表示。
4.7 泛化能力
添加图片注释,不超过 140 字(可选)
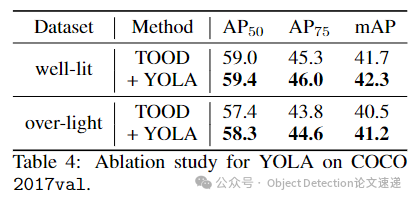
将YOLA应用于通用目标检测数据集COCO 2017,在良好光照和过亮光照场景下进行训练和评估。采用(IoU在0.5到0.95之间的平均值)、和作为评估指标,结果表明,集成YOLA的检测器在两种场景下的性能均有显著提升,证明了YOLA良好的泛化能力。
五、研究创新点总结
-
全新的特征学习视角:区别于传统方法,YOLA从特征学习出发,利用兰伯特图像形成模型学习光照不变特征,为低光目标检测开辟了新路径。
-
创新的IIM模块:设计了IIM模块,无需额外配对数据集即可提取光照不变特征,且能无缝集成到现有目标检测方法中,增强其在低光环境下的性能。
-
有效的零均值约束和可学习卷积核:通过零均值约束消除光照项影响,结合可学习卷积核自适应学习光照不变特征,提高了特征提取的有效性和适应性。
-
良好的泛化能力:YOLA不仅在低光目标检测任务中表现出色,在良好光照和过亮光照场景下同样能提升检测性能,展现了优秀的泛化能力。
参考文献链接
人工智能芯片与自动驾驶

 浙公网安备 33010602011771号
浙公网安备 33010602011771号