
字节跳动 GPU Scale-up 白皮书,EthLink 网
白皮书核心内容:
1.GPU架构和互联方案
GPU架构分析:
-
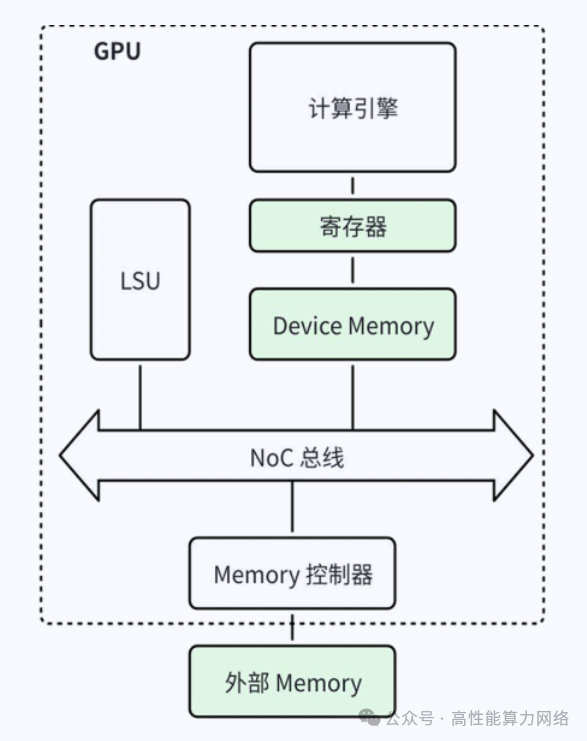
主流GPU架构支持Load-Store语义,计算引擎处理数据,LSU负责数据传输。
-
新型GPU增加了类似DMA引擎的传输模块(如NVIDIA的TMA),以减少计算引擎用于数据传输的算力资源消耗。
添加图片注释,不超过 140 字(可选)
GPU互联方案:
-
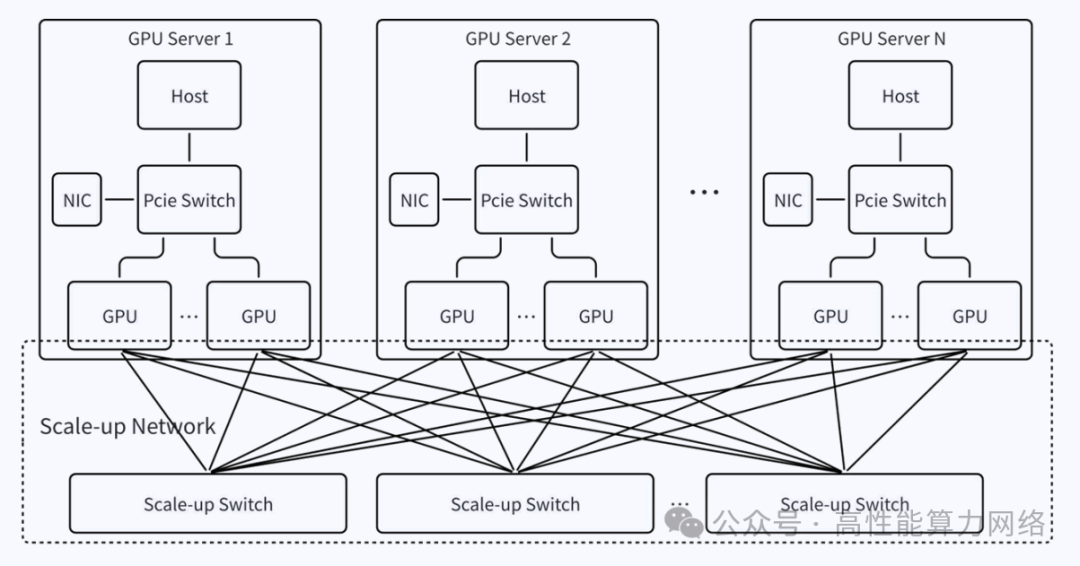
AI集群需要Scale-up和Scale Out网络来协同完成任务。
-
Scale-up网络特点:高带宽、低时延,支持Load/Store语义,用于同步操作。
-
Scale Out网络特点:相对低带宽、高时延,支持RDMA语义,用于异步操作。
-
字节跳动提出了自研的Scale-up网络协议EthLink,支持Load/Store和RDMA语义。 2.下一代Scale-up互联方案
需求分析:
-
需要支持Load/Store语义以高效传输小块数据和控制信息。
-
需要支持RDMA语义以高效传输大块数据,节省计算引擎算力。
-
需要实现远端Global Memory和本地Shared Memory之间的数据传输。
-
需要简洁的接口以适应GPU内部模块的交互操作。
-
可以由系统软件保证Cache Coherency,而非网络硬件。
-
需要对相同传输路径的语义操作和数据报文进行保序。
网络方案:
-
GPU可以通过Load/Store语义执行同步操作,也可以通过RDMA语义执行异步操作。
-
Scale-up网络承接Load/Store语义的数据传输流程,不再需要网络硬件保证Cache Coherency。
-
Scale-up网络承接RDMA语义的数据传输流程,由RDMA Engine完成数据传输。 3.EthLink网络方案
添加图片注释,不超过 140 字(可选)
EthLink协议栈:
添加图片注释,不超过 140 字(可选)
-
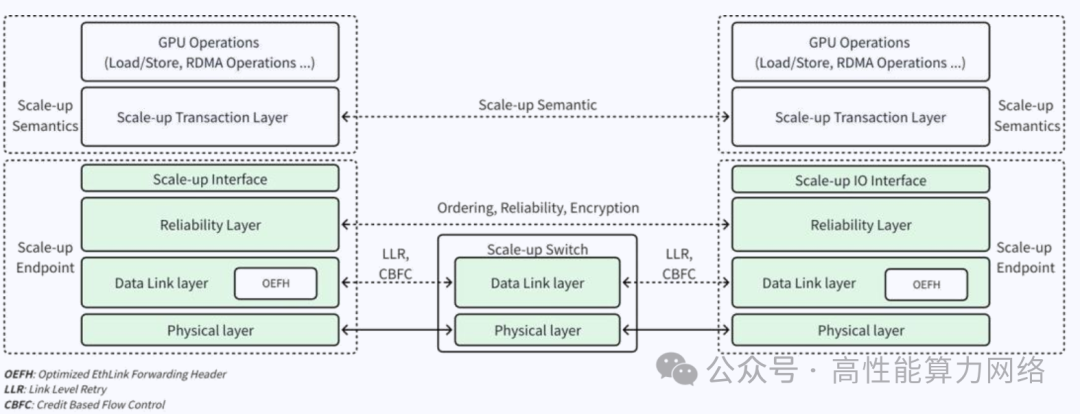
GPU侧协议栈分为Scale-Up语义层和Scale-up网络层。
-
Scale-Up语义层进一步分为GPU操作和Scale-up事务层。
-
GPU操作包括Load/Store、RDMA 语义。
-
Scale-up事务层定义了Memory Read、Memory Write等(类似PCIe的Memory Read、Memory Write操作)操作。
-
EthLink采用LLR(Link Layer Retry)和CBFC(Credit-Based Flow Control)实现可靠的无损网络;同时优化链路层报文头以减少传输开销。
网络拓扑:
-
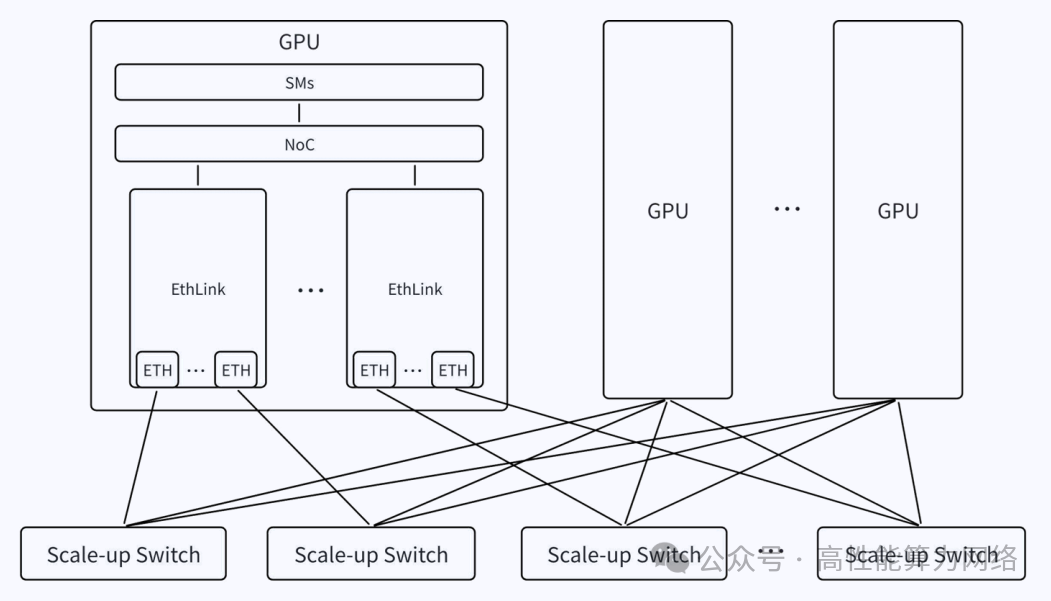
每个GPU服务器部署多个EthLink协议栈,支持1~4个以太网接口。
-
GPU服务器之间通过低时延以太网交换机互连,同一个Scale-up域最大支持1024个GPU节点。
添加图片注释,不超过 140 字(可选)
-
使用Multi-Path实现端口负载均衡,引入乱序问题需由上层应用处理。
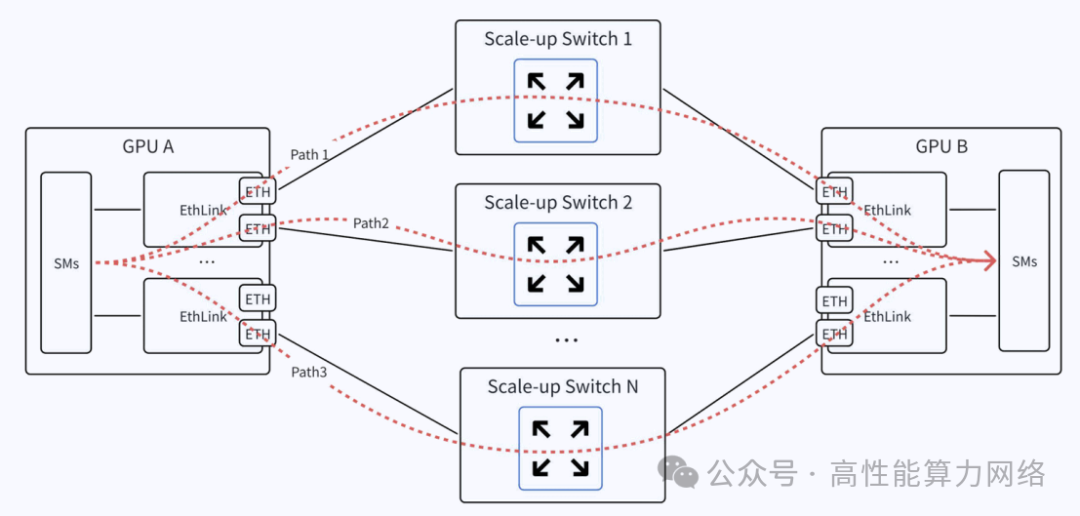
添加图片注释,不超过 140 字(可选)
网络接口:
-
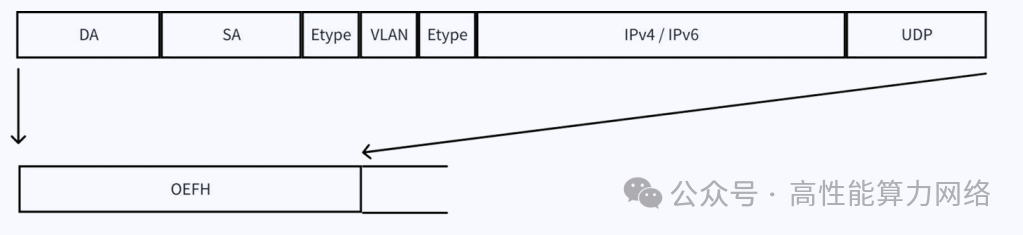
报文封装:EthLink报文格式引入了RH(Reliability Header)和OEFH(Optimized EthLink Forwarding Header)。
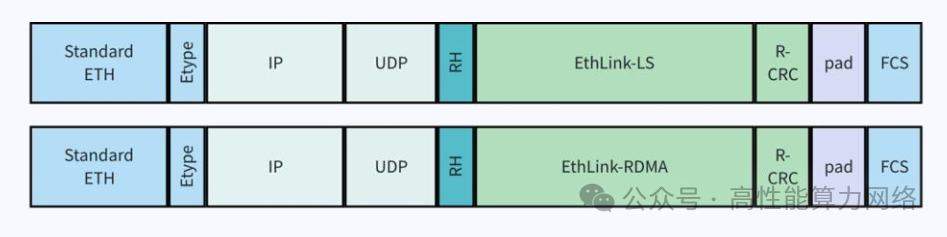
添加图片注释,不超过 140 字(可选)
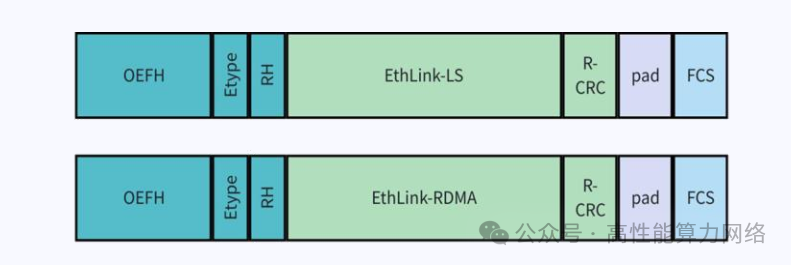
添加图片注释,不超过 140 字(可选)
RH用于保证端到端可靠性,是对 LLR 提供的链路层可靠性的增强;OEFH 使用更小的报文 header 来提升报文有效负载率。 OEFH 的格式如下图所示,包含 source 和 destination GPU ID,交换机根据GPU ID 来转发报文。
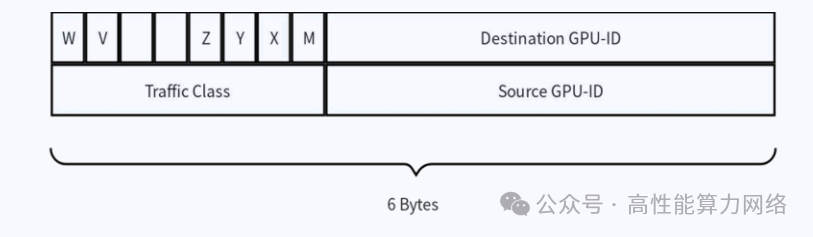
添加图片注释,不超过 140 字(可选)
OEFH 能够取代标准以太网和 TCP/IP 协议栈中的 ETH+IP+UDP 报文头,显著缩短了报文头长度,降低了报文开销。
添加图片注释,不超过 140 字(可选)
-
FEC:选择RS-272这种低延迟的FEC方案。
-
链路层可靠传输:支持LLR和CBFC以降低丢包概率和延迟。
-
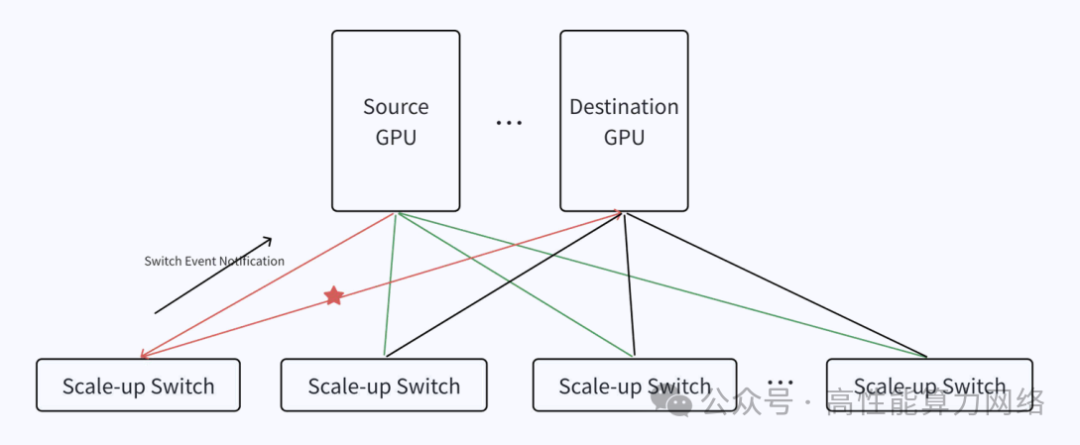
Switch Event Notification:交换机与GPU间建立状态反馈机制,快速切换路径避免丢包。
添加图片注释,不超过 140 字(可选)
参考文献链接
人工智能芯片与自动驾驶

 浙公网安备 33010602011771号
浙公网安备 33010602011771号