


YOLO11多尺度优化
问题点:特征颜色、纹理及形态的多样性,加之光照条件变化,导致检测难度变大
解决方案:引入了一种多维联合注意力模块,该模块利用扩张卷积来捕捉不同尺度的特征信息,从而增强了模型的感受野和多尺度处理能力。
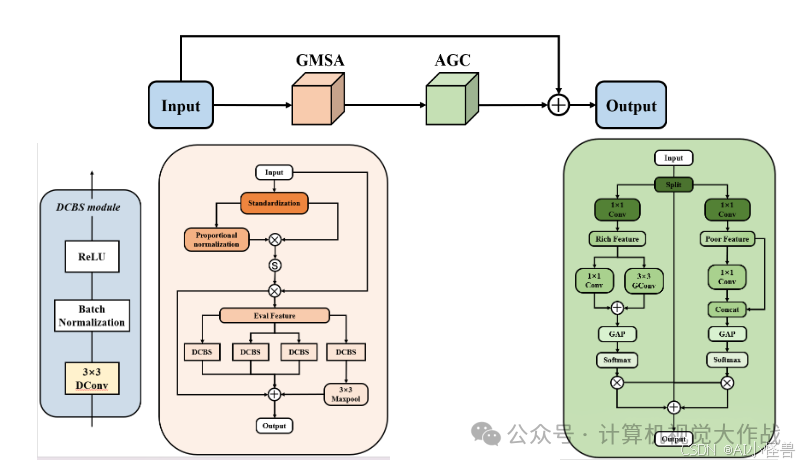
添加图片注释,不超过 140 字(可选)
分别加入到YOLO11的backbone、neck、detect,助力涨点
改进1结构图:
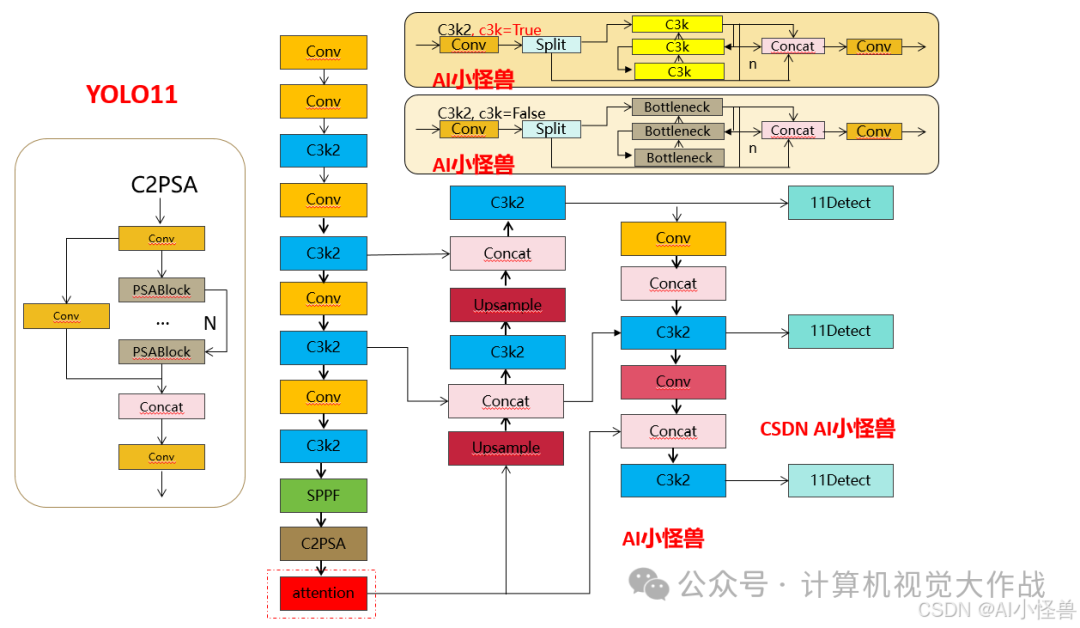
添加图片注释,不超过 140 字(可选)
改进2结构图:
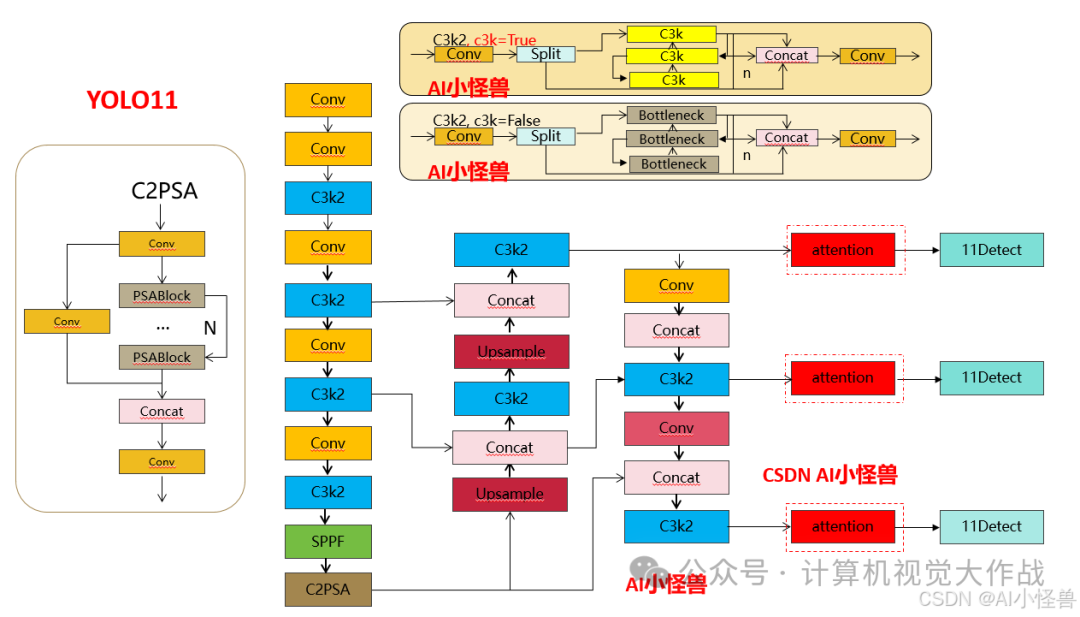
添加图片注释,不超过 140 字(可选)
改进3结构图:
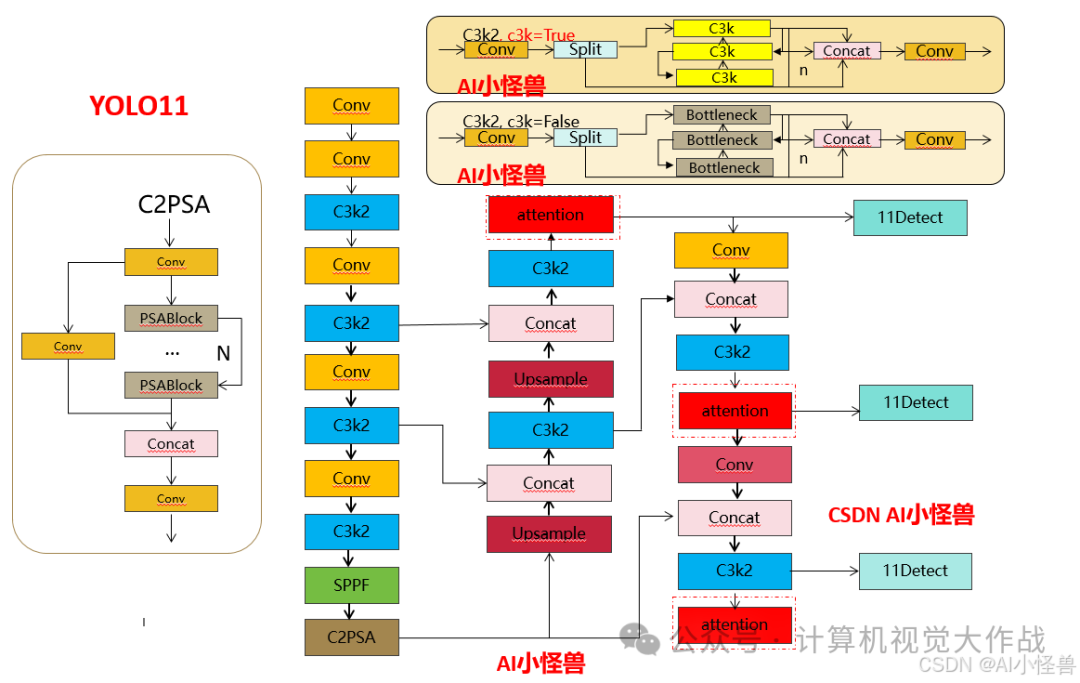
添加图片注释,不超过 140 字(可选)
1 YOLO11介绍
Ultralytics YOLO11是一款尖端的、最先进的模型,它在之前YOLO版本成功的基础上进行了构建,并引入了新功能和改进,以进一步提升性能和灵活性。YOLO11设计快速、准确且易于使用,使其成为各种物体检测和跟踪、实例分割、图像分类以及姿态估计任务的绝佳选择。
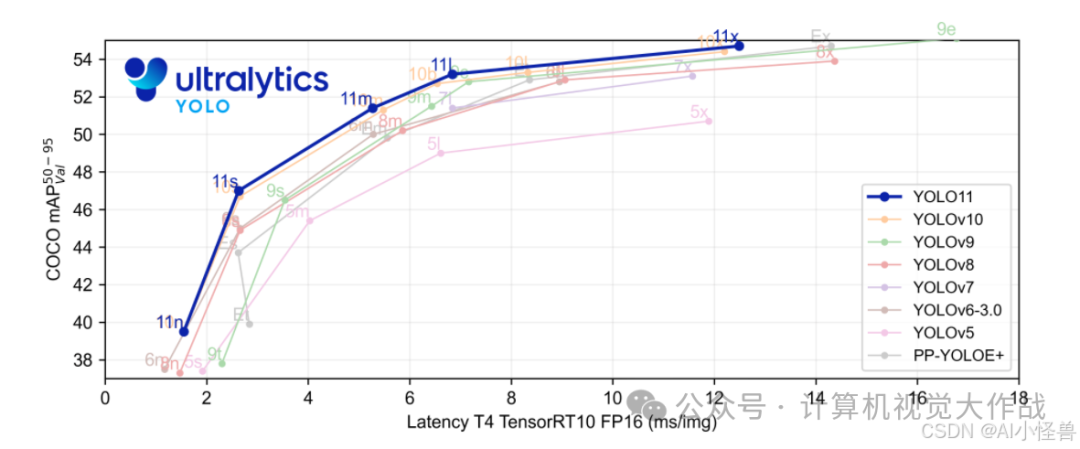
添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
结构图如下:
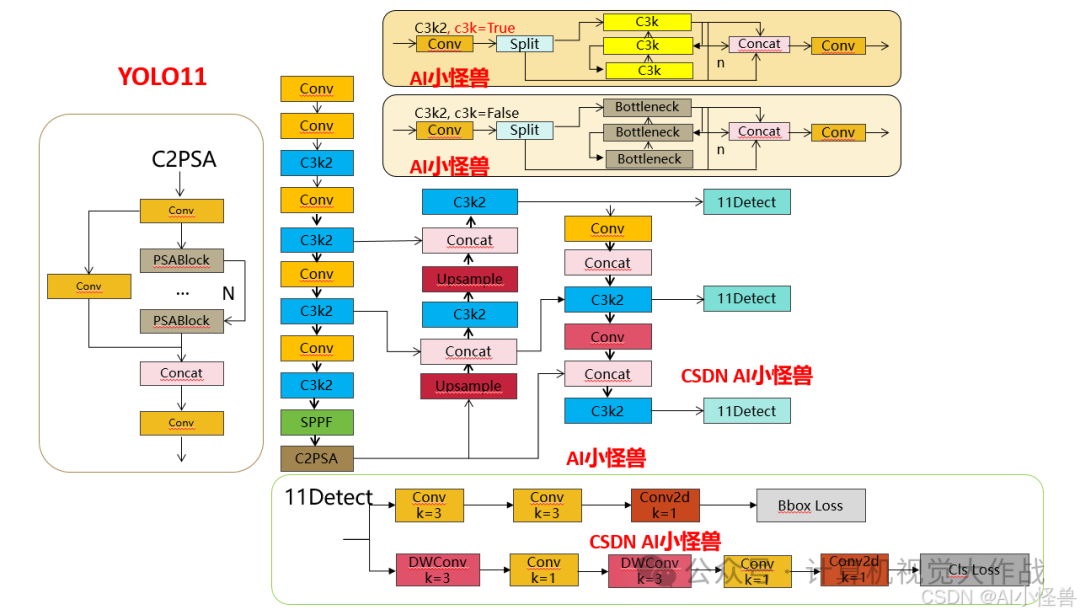
添加图片注释,不超过 140 字(可选)
1.1 C3k2
C3k2,结构图如下
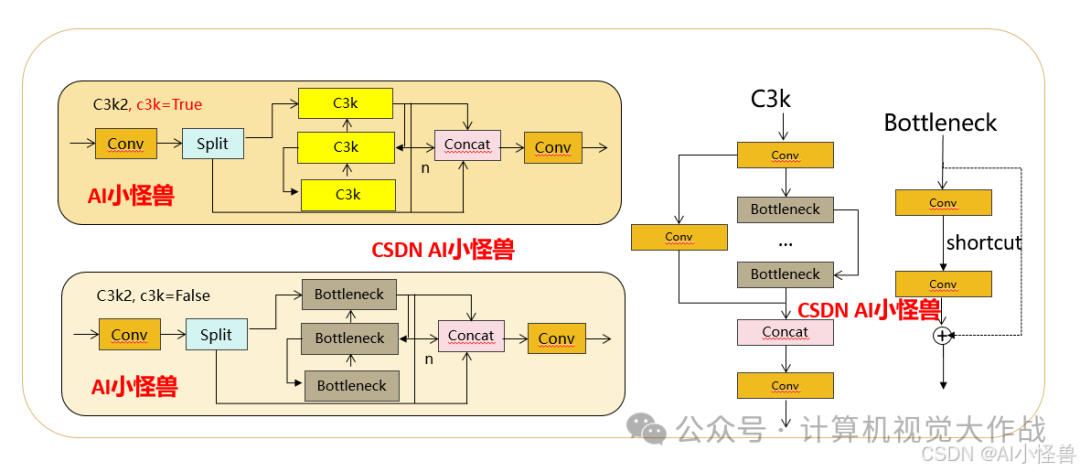
添加图片注释,不超过 140 字(可选)
C3k2,继承自类C2f,其中通过c3k设置False或者Ture来决定选择使用C3k还是Bottleneck

添加图片注释,不超过 140 字(可选)
实现代码ultralytics/nn/modules/block.py
1.2 C2PSA介绍
借鉴V10 PSA结构,实现了C2PSA和C2fPSA,最终选择了基于C2的C2PSA(可能涨点更好?)
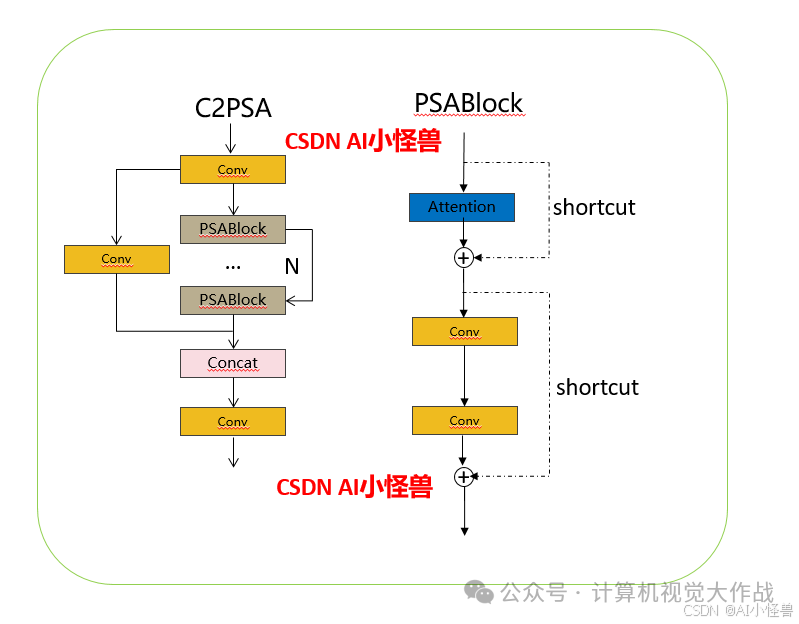
添加图片注释,不超过 140 字(可选)
实现代码ultralytics/nn/modules/block.py
1.3 11 Detect介绍
分类检测头引入了DWConv(更加轻量级,为后续二次创新提供了改进点),结构图如下(和V8的区别):
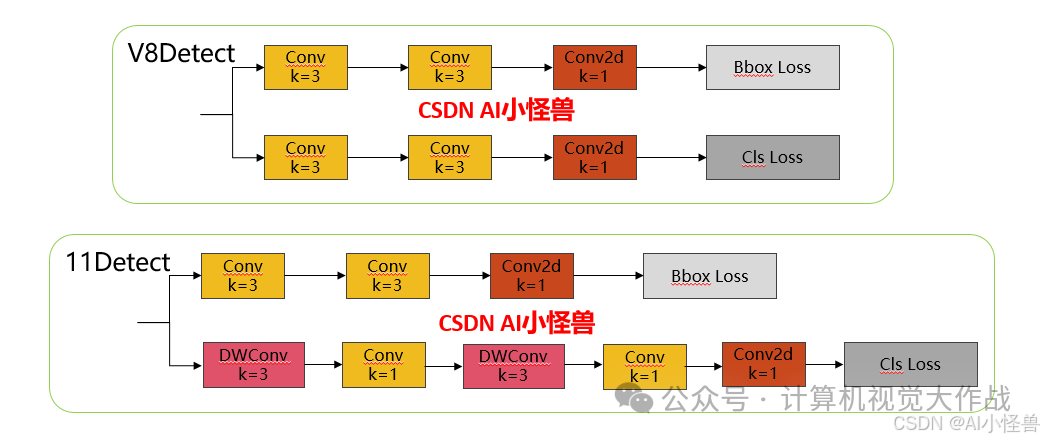
添加图片注释,不超过 140 字(可选)
实现代码ultralytics/nn/modules/head.py
2 原理介绍
病害对于提高诊断精度以及优化农业病害管理至关重要。然而,病害颜色、纹理及形态的多样性,加之光照条件变化与病害的渐进发展,给相关工作带来了诸多挑战。为解决这些问题,我们提出了一种具备边缘感知能力的多尺度网络。
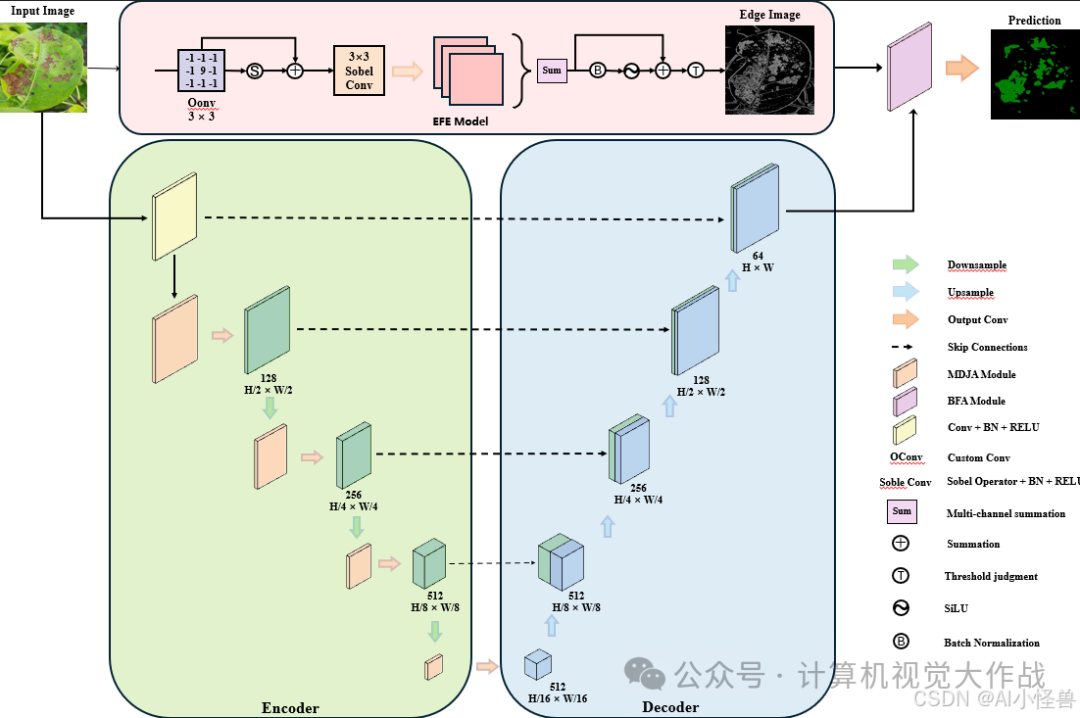
添加图片注释,不超过 140 字(可选)
引入了一种多维联合注意力模块(MDJA),该模块利用扩张卷积来捕捉不同尺度的病灶信息,从而增强了模型的感受野和多尺度处理能力。
添加图片注释,不超过 140 字(可选)
3 如何加入到YOLO11
3.1新建ultralytics/nn/block/EBMA.py
核心代码:
class EFE(nn.Module): def __init__(self, in_channels, sobel_strength=1): super(EFE, self).__init__() self.sobel_strength = sobel_strength self.in_channels = in_channels # self.conv = nn.Conv2d(in_channels=3, out_channels=1, kernel_size=1) sobel_x = sobel_strength * torch.tensor([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]], dtype=torch.float32).view(1, 1, 3, 3) sobel_y = sobel_strength * torch.tensor([[-1, -2, -1], [0, 0, 0], [1, 2, 1]], dtype=torch.float32).view(1, 1, 3, 3) sobel = sobel_strength * torch.tensor([[-1, -1, -1], [-1, 9, -1], [-1, -1, -1]], dtype=torch.float32).view(1, 1, 3, 3) self.register_buffer('sobel_x', sobel_x) self.register_buffer('sobel_y', sobel_y) self.register_buffer('sobel', sobel) self.bn = nn.BatchNorm2d(in_channels) self.silu = nn.SiLU(inplace=True) self.threshold = 1 self.sigmoid = nn.Sigmoid() def forward(self, x): sobel_x = self.sobel_x.expand(self.in_channels, 1, 3, 3) sobel_y = self.sobel_y.expand(self.in_channels, 1, 3, 3) sobel = self.sobel.expand(self.in_channels, 1, 3, 3) # x_o = F.conv2d(x, sobel, padding=1, groups=self.in_channels) # grad1 = self.bn(grad1) # x_o = self.relu(grad1) # x_o = x_o.clamp(0, 1) y = self.sigmoid(x_o) * x + x grad_x = F.conv2d(y, sobel_x, padding=1, groups=self.in_channels) grad_y = F.conv2d(y, sobel_y, padding=1, groups=self.in_channels) grad2 = torch.sqrt(grad_x ** 2 + grad_y ** 2) grad2 = self.bn(grad2) grad2 = self.silu(grad2) grad2 = grad2.sum(dim=1, keepdim=True) # print(output) x_1 = grad2.clamp(0, 1) output = self.sigmoid(x_1) * x_1 + x_1 return output
3.3 yaml修改
提供多种 MDJA修改方式,分别加在网络不同位置,总有一种适合你的数据集
3.3.1 yolo11-MDJA.yaml
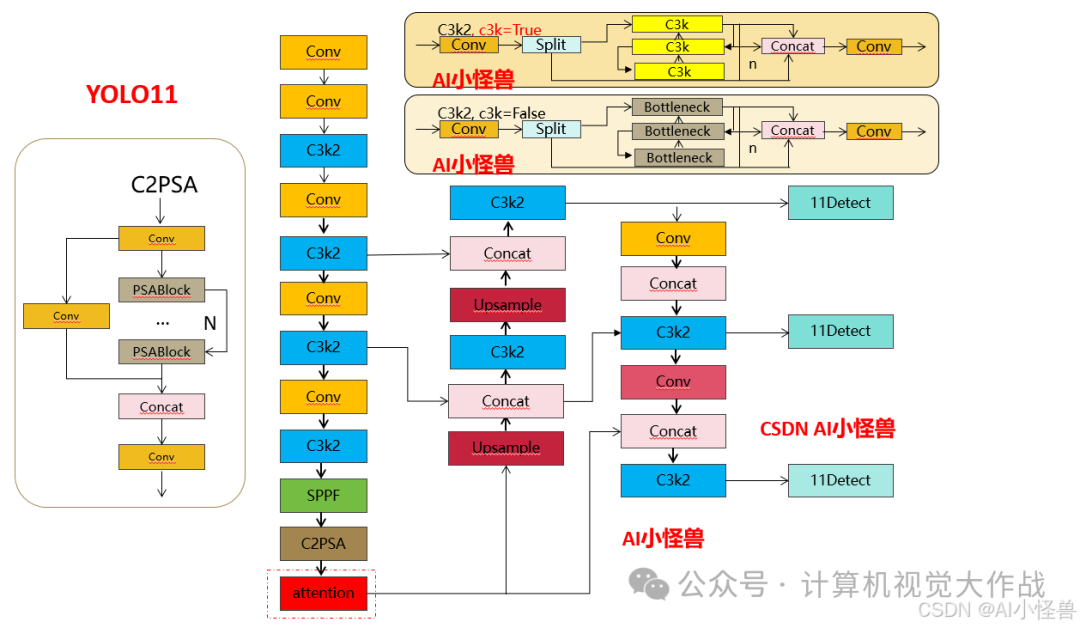
添加图片注释,不超过 140 字(可选)
# Ultralytics YOLO 🚀, AGPL-3.0 license# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parametersnc: 80 # number of classesscales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n' # [depth, width, max_channels] n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs# YOLO11n backbonebackbone: # [from, repeats, module, args] - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2 - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4 - [-1, 2, C3k2, [256, False, 0.25]] - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8 - [-1, 2, C3k2, [512, False, 0.25]] - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16 - [-1, 2, C3k2, [512, True]] - [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32 - [-1, 2, C3k2, [1024, True]] - [-1, 1, SPPF, [1024, 5]] # 9 - [-1, 2, C2PSA, [1024]] # 10 - [-1, 1, MDJA, [1024]] # 11# YOLO11n headhead: - [-1, 1, nn.Upsample, [None, 2, "nearest"]] - [[-1, 6], 1, Concat, [1]] # cat backbone P4 - [-1, 2, C3k2, [512, False]] # 14 - [-1, 1, nn.Upsample, [None, 2, "nearest"]] - [[-1, 4], 1, Concat, [1]] # cat backbone P3 - [-1, 2, C3k2, [256, False]] # 17 (P3/8-small) - [-1, 1, Conv, [256, 3, 2]] - [[-1, 14], 1, Concat, [1]] # cat head P4 - [-1, 2, C3k2, [512, False]] # 20 (P4/16-medium) - [-1, 1, Conv, [512, 3, 2]] - [[-1, 11], 1, Concat, [1]] # cat head P5 - [-1, 2, C3k2, [1024, True]] # 23 (P5/32-large) - [[17, 20, 23], 1, Detect, [nc]] # Detect(P3, P4, P5)
3.3.2 yolo11-MDJA1.yaml
添加图片注释,不超过 140 字(可选)
# Ultralytics YOLO 🚀, AGPL-3.0 license# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parametersnc: 80 # number of classesscales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n' # [depth, width, max_channels] n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs# YOLO11n backbonebackbone: # [from, repeats, module, args] - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2 - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4 - [-1, 2, C3k2, [256, False, 0.25]] - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8 - [-1, 2, C3k2, [512, False, 0.25]] - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16 - [-1, 2, C3k2, [512, True]] - [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32 - [-1, 2, C3k2, [1024, True]] - [-1, 1, SPPF, [1024, 5]] # 9 - [-1, 2, C2PSA, [1024]] # 10# YOLO11n headhead: - [-1, 1, nn.Upsample, [None, 2, "nearest"]] - [[-1, 6], 1, Concat, [1]] # cat backbone P4 - [-1, 2, C3k2, [512, False]] # 13 - [-1, 1, nn.Upsample, [None, 2, "nearest"]] - [[-1, 4], 1, Concat, [1]] # cat backbone P3 - [-1, 2, C3k2, [256, False]] # 16 (P3/8-small) - [-1, 1, Conv, [256, 3, 2]] - [[-1, 13], 1, Concat, [1]] # cat head P4 - [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium) - [-1, 1, Conv, [512, 3, 2]] - [[-1, 10], 1, Concat, [1]] # cat head P5 - [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large) - [16, 1, MDJA, [256]] # 23 - [19, 1, MDJA, [512]] # 24 - [22, 1, MDJA, [1024]] # 25 - [[23, 24, 25], 1, Detect, [nc]] # Detect(P3, P4, P5)
3.3.3 yolo11-MDJA2.yaml
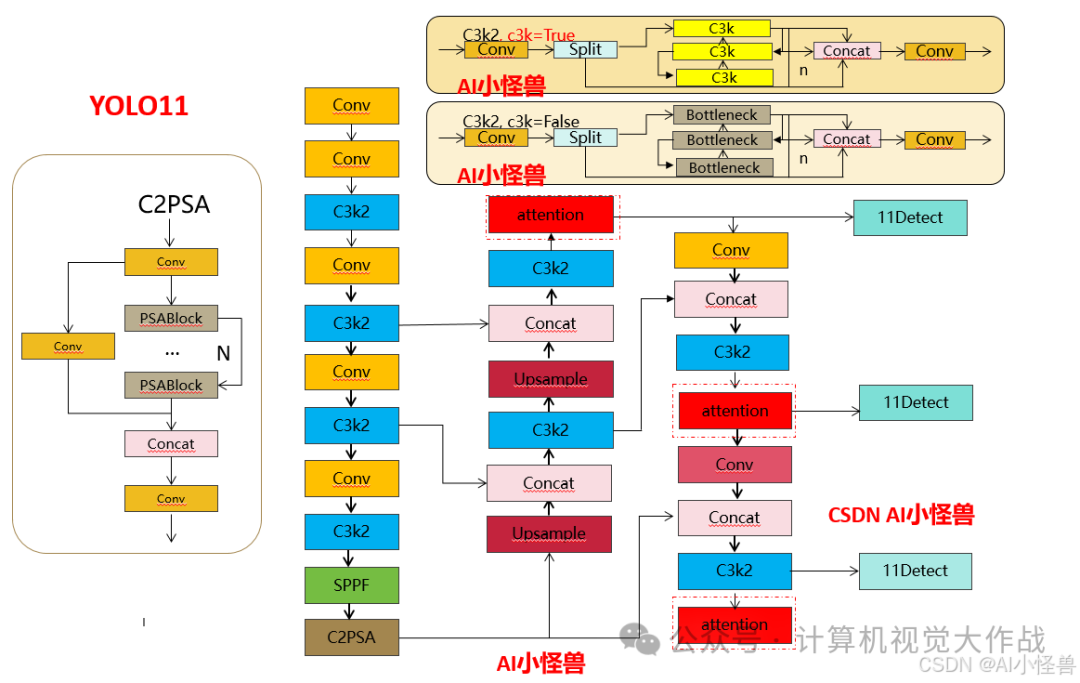
添加图片注释,不超过 140 字(可选)
# Ultralytics YOLO 🚀, AGPL-3.0 license# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parametersnc: 80 # number of classesscales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n' # [depth, width, max_channels] n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs# YOLO11n backbonebackbone: # [from, repeats, module, args] - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2 - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4 - [-1, 2, C3k2, [256, False, 0.25]] - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8 - [-1, 2, C3k2, [512, False, 0.25]] - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16 - [-1, 2, C3k2, [512, True]] - [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32 - [-1, 2, C3k2, [1024, True]] - [-1, 1, SPPF, [1024, 5]] # 9 - [-1, 2, C2PSA, [1024]] # 10# YOLO11n headhead: - [-1, 1, nn.Upsample, [None, 2, "nearest"]] - [[-1, 6], 1, Concat, [1]] # cat backbone P4 - [-1, 2, C3k2, [512, False]] # 13 - [-1, 1, nn.Upsample, [None, 2, "nearest"]] - [[-1, 4], 1, Concat, [1]] # cat backbone P3 - [-1, 2, C3k2, [256, False]] # 16 (P3/8-small) - [-1, 1, MDJA, [256]] # 17 - [-1, 1, Conv, [256, 3, 2]] - [[-1, 13], 1, Concat, [1]] # cat head P4 - [-1, 2, C3k2, [512, False]] # 20 (P4/16-medium) - [-1, 1, MDJA, [512]] # 21 - [-1, 1, Conv, [512, 3, 2]] - [[-1, 10], 1, Concat, [1]] # cat head P5 - [-1, 2, C3k2, [1024, True]] # 24 (P5/32-large) - [-1, 1, MDJA, [1024]] # 25 - [[17, 21, 25], 1, Detect, [nc]] # Detect(P3, P4, P5)
参考文献链接
https://mp.weixin.qq.com/s/j2yLrN3LVl6w1IhQwrh1tw
人工智能芯片与自动驾驶


 浙公网安备 33010602011771号
浙公网安备 33010602011771号