
开发OpenCL内核测试用例
开发OpenCL内核测试用例
前面的例子只有主机侧的代码,没有GPU运行的代码,实际上没有调用AMDGPU的异构计算能力,参考网上的代码,写一个实现两个一维向量加和的内核,投到AMDGPU上得到计算结果:
#include <stdio.h>
#include <stdlib.h>
#include <alloca.h>
#include <CL/cl.h>
#pragma warning( disable: 4996 )
int main() {
cl_int error;
cl_platform_id platforms;
cl_device_id devices;
cl_context context;
FILE *program_handle;
size_t program_size;
char *program_buffer;
cl_program program;
size_t log_size;
char *program_log;
char kernel_name[] = "createBuffer";
cl_kernel kernel;
cl_command_queue queue;
//获取平台
error = clGetPlatformIDs(1, &platforms, NULL);
if (error != 0) {
printf("获取平台失败!");
return -1;
}
//获取设备
error = clGetDeviceIDs(platforms, CL_DEVICE_TYPE_GPU, 1, &devices, NULL);
if (error != 0) {
printf("获取设备失败!");
return -1;
}
//创建上下文
context = clCreateContext(NULL,1,&devices,NULL,NULL,&error);
if (error != 0) {
printf("创建上下文失败!");
return -1;
}
//创建程序,注意要用rb
program_handle = fopen("kernel.cl","rb");
if (program_handle == NULL) {
printf("内核不能打开!");
return -1;
}
fseek(program_handle,0,SEEK_END);
program_size = ftell(program_handle);
rewind(program_handle);
program_buffer = (char *)malloc(program_size+1);
program_buffer[program_size] = '\0';
error=fread(program_buffer, sizeof(char), program_size, program_handle);
if (error == 0) {
printf("读内核失败!");
return -1;
}
fclose(program_handle);
program = clCreateProgramWithSource(context,1,(const char **)&program_buffer,
&program_size,&error);
if (error < 0) {
printf("无法创建程序!");
return -1;
}
//编译程序
error = clBuildProgram(program,1,&devices,NULL,NULL,NULL);
if (error < 0) {
//确定日志文件的大小
clGetProgramBuildInfo(program,devices,CL_PROGRAM_BUILD_LOG,0,NULL,&log_size);
program_log = (char *)malloc(log_size+1);
program_log[log_size] = '\0';
//读取日志
clGetProgramBuildInfo(program, devices, CL_PROGRAM_BUILD_LOG,
log_size+1, program_log, NULL);
printf("%s\n",program_log);
free(program_log);
return -1;
}
free(program_buffer);
//创建命令队列
queue = clCreateCommandQueue(context, devices, CL_QUEUE_PROFILING_ENABLE, &error);
if (error < 0) {
printf("无法创建命令队列");
return -1;
}
//创建内核
kernel = clCreateKernel(program,kernel_name,&error);
if (kernel==NULL) {
printf("无法创建内核!\n");
return -1;
}
//初始化参数
float result[100];
float a_in[100];
float b_in[100];
for (int i = 0; i < 100; i++) {
a_in[i] = i;
b_in[i] = i*2.0;
}
//创建缓存对象
cl_mem memObject1 = clCreateBuffer(context, CL_MEM_READ_ONLY|CL_MEM_COPY_HOST_PTR, sizeof(float)*100, a_in,&error);
if (error < 0) {
printf("创建memObject1失败!\n");
return -1;
}
cl_mem memObject2 = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, sizeof(float) * 100, b_in, &error);
if (error < 0) {
printf("创建memObject2失败!\n");
return -1;
}
cl_mem memObject3 = clCreateBuffer(context, CL_MEM_WRITE_ONLY,
sizeof(float) * 100, NULL, &error);
if (error < 0) {
printf("创建memObject3失败!\n");
return -1;
}
//设置内核参数
error = clSetKernelArg(kernel, 0, sizeof(cl_mem),&memObject1);
error|= clSetKernelArg(kernel, 1, sizeof(cl_mem), &memObject2);
error |= clSetKernelArg(kernel, 2, sizeof(cl_mem), &memObject3);
if (error != CL_SUCCESS) {
printf("设置内核参数时出错!\n");
return -1;
}
//执行内核
size_t globalWorkSize[1] = {100};
size_t localWorkSize[1] = {1};
error = clEnqueueNDRangeKernel(queue,kernel, 1, NULL, globalWorkSize,
localWorkSize, 0, NULL, NULL);
if (error != CL_SUCCESS) {
printf("排队等待内核执行时出错!\n");
return -1;
}
//读取执行结果
error = clEnqueueReadBuffer(queue, memObject3, CL_TRUE, 0, 100*sizeof(float),
result, 0, NULL, NULL);
if (error != CL_SUCCESS) {
printf("读取结果缓冲区时出错!\n");
return -1;
}
//显示结果
for (int i = 0; i < 100; i++) {
printf("%f ", result[i]);
}
printf("\n");
//释放资源
clReleaseDevice(devices);
clReleaseContext(context);
clReleaseCommandQueue(queue);
clReleaseProgram(program);
clReleaseKernel(kernel);
clReleaseMemObject(memObject1);
clReleaseMemObject(memObject2);
clReleaseMemObject(memObject3);
return 0;
}
设备端代码:
__kernel void createBuffer(__global const float *a_in,
__global const float *b_in,
__global float *result) {
int gid = get_global_id(0);
result[gid] = a_in[gid] + b_in[gid];
}
编译命令不变,kernel.cl会被主文件读入,然后被ROCm动态编译为GPU端指令,通过ROCm运行时加载GPU端运行,GPU计算原理,如图1-31所示。得到计算结果,计算结果符合预期,如图1-32所示。
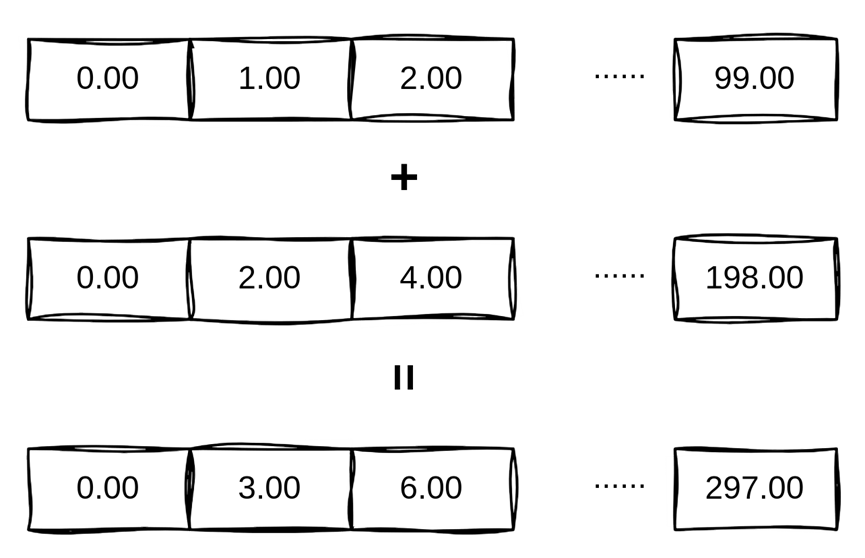
图1-31 GPU端运行计算原理

图1-32 kernel.cl被ROCm动态编译为GPU端指令,加载GPU端运行,得到计算结果
驱动开发者,实际上最关心的是KFD端的调用序列,通过追踪可以看到,此时由于加入了设备端计算的功能,KFD的IOCTL调用序列明显比前面长了好多,其中包括了命令队列创建的IOCTL也被调用到,因为设备端代码要通过命令队列传递给AMDGPU去执行。
人工智能芯片与自动驾驶

 浙公网安备 33010602011771号
浙公网安备 33010602011771号