
数据共享操作(上)
数据共享操作
本地数据共享(LDS)是一种延迟非常低的临时数据RAM,其有效带宽至少比直接、无缓存的全局内存高一个数量级,允许在工作组中的工作项之间共享数据。与只读缓存不同,LDS允许内存空间的高速写到读重用(完全收集/读取/加载和分散/写入/存储操作)。
1. 数据共享概述
显示了使用OpenCL将LDS集成到AMD加速器内存中的概念框架,如图5-24所示。

图5-24 使用OpenCL将LDS集成到AMD加速器内存中的概念框架
物理上位于片上,直接靠近ALU,LDS可以比全局存储器快大约一个数量级(假设没有存储体冲突)。
每个计算单元有64kB内存,分为32组512个字。每个存储体都是256x32双端口RAM(每个时钟周期1R/1W)。Dword按顺序放置在存储体中,但所有存储体都可以同时执行存储或加载。一个工作组最多可以请求64kB内存。
LDS存储器的高带宽不仅是通过其邻近ALU来实现的,也是通过同时访问其存储体来实现的。因此,可以同时执行32条写或读指令,每条名义上为32位。扩展指令read2/write2每个可以是64位。如果同时对同一组进行了多次访问尝试,则会发生组冲突。在这种情况下,对于索引和原子操作,硬件通过将它们转换为串行访问,以防止对同一存储体的并发访问。这可能会降低LDS的有效带宽。因此,为了帮助实现最佳吞吐量(最佳效率),避免组冲突非常重要。
2. 内存层次结构中的数据流
内存结构中数据流的概念图,如图5-25所示。

图5-25 内存结构中数据流的概念图
要从全局内存将数据加载到LDS中,需要从全局内存中读取数据,并将其放入工作项的寄存器中,然后对LDS执行存储。同样,为了将数据存储到全局内存中,数据从LDS读取并放入工作项的寄存器中,然后放入全局内存中。为了有效地利用LDS,内核必须对全局内存和LDS之间传输的内容执行许多操作。也可以绕过VGPR将数据,从内存缓冲区直接加载到LDS中。
LDS原子在LDS硬件中执行。因此,尽管ALU不直接用于这些操作,但LDS执行此功能会产生延迟。
3. SOP1说明
SOP1指令架构,如图5-26所示。

图5-26 SOP1指令架构
这种格式的指令可能会使用一个32位的文字常量,该常量紧随指令之后。
4. SOPC说明
SOPC指令架构,如图5-27所示。

图5-27 SOPC指令架构
这种格式的指令可能会使用一个32位的文字常量,该常量紧随指令之后。
5. SOPP说明
SOPP指令架构,如图5-28所示。

图5-28 SOPP指令架构
6. S_NOP 0
将下一条指令的发出延迟一小部分固定时间。
根据SIMM16[3:0]插入0..15个等待状态。0x0表示下一个指令可以在下一个时钟发出,0xf表示下一条指令可以在16个时钟后发出。
for i in 0U: SIMM16.u16[3: 0].u32 do
nop()
endfor
注释
示例:
s_nop 0 // 等待1个循环
s_nop 0xf // 等待16个循环
7. SMEM说明
SMEM指令架构,如图5-29所示。

图5-29 SMEM指令架构
8. VOP2指令
VOP2指令架构,如图5-30所示。

图5-30 VOP2指令架构
这种格式的指令可能会使用32位文字常量DPP或SDWA,它会在指令之后立即出现。
9. 使用VOP3编码的VOP2
这种格式的指令也可以编码为VOP3。允许访问额外的控制位(例如ABS、OMOD),以换取不使用文字常数。VOP3操作码为:VOP2操作码+0x100,如图5-31所示。
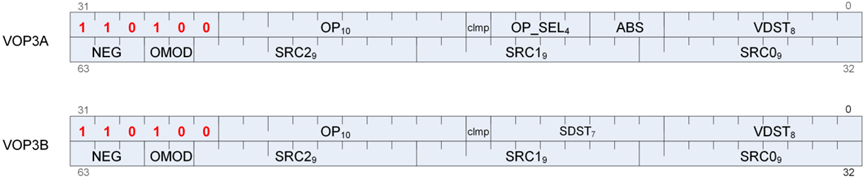
图5-31 VOP3操作码为:VOP2操作码+0x100
10. VOP1说明
VOP1指令格式说明,如图5-32所示。

图5-32 VOP1指令格式说明
这种格式的指
令可能会使用32位文字常量DPP或SDWA,它会在指令之后立即出现。
人工智能芯片与自动驾驶

 浙公网安备 33010602011771号
浙公网安备 33010602011771号