
ROCm数据布局与HIP实施
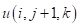
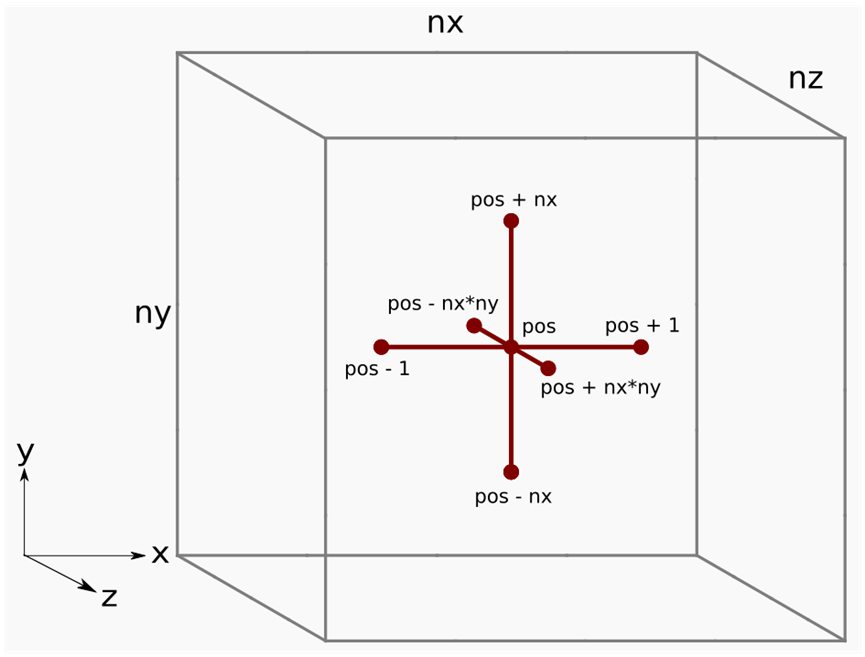
等表达式的正确展开。在网格点位置应用的拉普拉斯模板,如图4-1所示。
return;
const int slice = nx * ny;
size_t pos = i + nx * j + slice * k;
// 计算模板操作的结果
f[pos] = u[pos] * invhxyz2
+ (u[pos - 1] + u[pos + 1]) * invhx2
+ (u[pos - nx] + u[pos + nx]) * invhy2
+ (u[pos - slice] + u[pos + slice]) * invhz2;
}
template <typename T>
void laplacian(T *d_f, T *d_u, int nx, int ny, int nz, int BLK_X, int BLK_Y, int BLK_Z, T hx, T hy, T hz) {
dim3 block(BLK_X, BLK_Y, BLK_Z);
dim3 grid((nx - 1) / block.x + 1, (ny - 1) / block.y + 1, (nz - 1) / block.z + 1);
T invhx2 = (T)1./hx/hx;
T invhy2 = (T)1./hy/hy;
T invhz2 = (T)1./hz/hz;
T invhxyz2 = -2. * (invhx2 + invhy2 + invhz2);
laplacian_kernel<<<grid, block>>>(d_f, d_u, nx, ny, nz, invhx2, invhy2, invhz2, invhxyz2);
}
拉普拉斯宿主函数负责启动设备内核拉普拉斯核,线程块大小为BLK_X=256,BLK_Y=1,BLK_Z=1。BLK_X*BLK_Y*BLK_Z=256的当前线程块大小是推荐的默认选择,因为它很好地映射到硬件工作调度器,但其他选择可能会更好。一般来说,选择此性能参数可能高度依赖于问题大小、内核实现和设备的硬件特性。虽然这个内核实现支持3D块大小,但GPU没有2D和3D的概念。定义3D组的可能性是作为程序员的便利功能提供的。
HIP实现适用于GPU内存中适合的任何问题大小。对于不能平均除以线程块大小的问题大小,引入了处理剩余部分的其他组。如果剩余部分很小,即许多线程映射到计算域之外没有工作可做的区域,这些额外的线程块可能会具有较低的线程利用率。这种低线程利用率会对性能产生负面影响。将关注可被线程块大小整除的问题大小。要调度的块数由上限操作(nx-1)/block.x+1,…决定。如前所述,它对组的数量进行四舍五入,以确保覆盖整个计算域。
内核中的退出条件。当线程位于边界上或边界外时,返回(退出),因为只计算内部点的有限差分。内核退出策略在实践中的工作原理是,由于波阵面以锁步方式执行指令,因此边界外的任何线程都将被其余内核屏蔽。被屏蔽的线程在执行指令期间将处于空闲状态。回到性能问题,块大小不能平均分配问题大小。如果选择nx=258,将在x方向上得到两个线程块,但第二个线程块中只有一个线程有工作要做。
// 计算模板操作的结果
f[pos] = u[pos] * invhxyz2
+ (u[pos - 1] + u[pos + 1]) * invhx2
+ (u[pos - nx] + u[pos + nx]) * invhy2
+ (u[pos - slice] + u[pos + slice]) * invhz2;
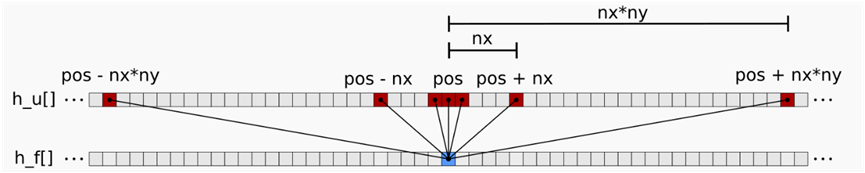
多次访问数组u。对于每次访问,编译器将生成一条全局加载指令,该指令将从全局内存中访问数据,除非该数据已存在于缓存中。正如将看到的,这些全局加载指令可能会对性能产生重大影响。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号