
OpenVX代码优化裁减简介
OpenVX代码优化裁减简介

在OpenVX中,裁减(Reduction)是一种操作,它对数组或图像中的元素执行聚合操作。这里的“裁减”是指将大型数组或图像减少到单一数值的过程。
OpenVX提供了几种不同的裁减操作,包括求和(Summation)、平均(Average)、最小值(Minimum)、最大值(Maximum)和累加器(Accumulator)。
以下是一个简单的例子,展示了如何在OpenVX中使用求和操作:
#include <VX/vx.h>
vx_status example_reduction(vx_context context) {
// 创建图像
vx_image src = vxCreateImage(context, 640, 480, VX_DF_IMAGE_U8);
// 定义一个累加器来存储结果
vx_scalar sum = vxCreateScalar(context, VX_TYPE_UINT32, &vx_false_value);
// 创建裁减节点
vx_reduction node_sum = vxCreateVirtualReduction(
vxGetContext((vx_reference)src),
VX_REDUCE_SUM, // 指定求和操作
VX_TYPE_UINT32, // 指定输出数据类型
vx_true_value); // 指定初始值,对于求和操作,通常设置为0
// 添加图像和累加器作为裁减节点的输入和输出
vxAddReductionNode(
node_sum, // 裁减节点
(vx_reference)src, // 输入图像
NULL, // 可选的窗口和比例参数,这里不使用
(vx_reference)sum // 输出累加器
);
// 运行图形,这里需要实现图形运行的逻辑
// 清理资源
vxReleaseImage(&src);
vxReleaseScalar(&sum);
vxReleaseReduction(&node_sum);
return VX_SUCCESS;
}
在这个例子中,创建了一个图像和一个累加器,然后定义了一个求和的裁减节点,并将它们加入到图形执行引擎中。注意,实际的图形执行需要更多的代码,这里只是展示了如何创建和配置裁减节点。
这只是一个简化的例子,实际的OpenVX图形执行,需要更多的错误检查和资源管理。在应用程序中,通常需要调用vxStart和vxWait来启动和等待图形的执行。

/* 矩阵访问示例 */
const vx_size columns = 3;
const vx_size rows = 4;
vx_matrix matrix = vxCreateMatrix(context, VX_TYPE_FLOAT32, columns, rows);
vx_status status = vxGetStatus((vx_reference)matrix);
if (status == VX_SUCCESS)
{
vx_int32 j, i;
#if defined(OPENVX_USE_C99)
vx_float32 mat[rows][columns]; /* note: row major */
#else
vx_float32 *mat = (vx_float32 *)malloc(rows*columns*sizeof(vx_float32));
#endif
if (vxCopyMatrix(matrix, mat, VX_READ_ONLY, VX_MEMORY_TYPE_HOST) == VX_SUCCESS) {
for (j = 0; j < (vx_int32)rows; j++)
for (i = 0; i < (vx_int32)columns; i++)
#if defined(OPENVX_USE_C99)
mat[j][i] = (vx_float32)rand()/(vx_float32)RAND_MAX;
#else
mat[j*columns + i] = (vx_float32)rand()/(vx_float32)RAND_MAX;
#endif
vxCopyMatrix(matrix, mat, VX_WRITE_ONLY, VX_MEMORY_TYPE_HOST);
}
#if !defined(OPENVX_USE_C99)
free(mat);
#endif
}
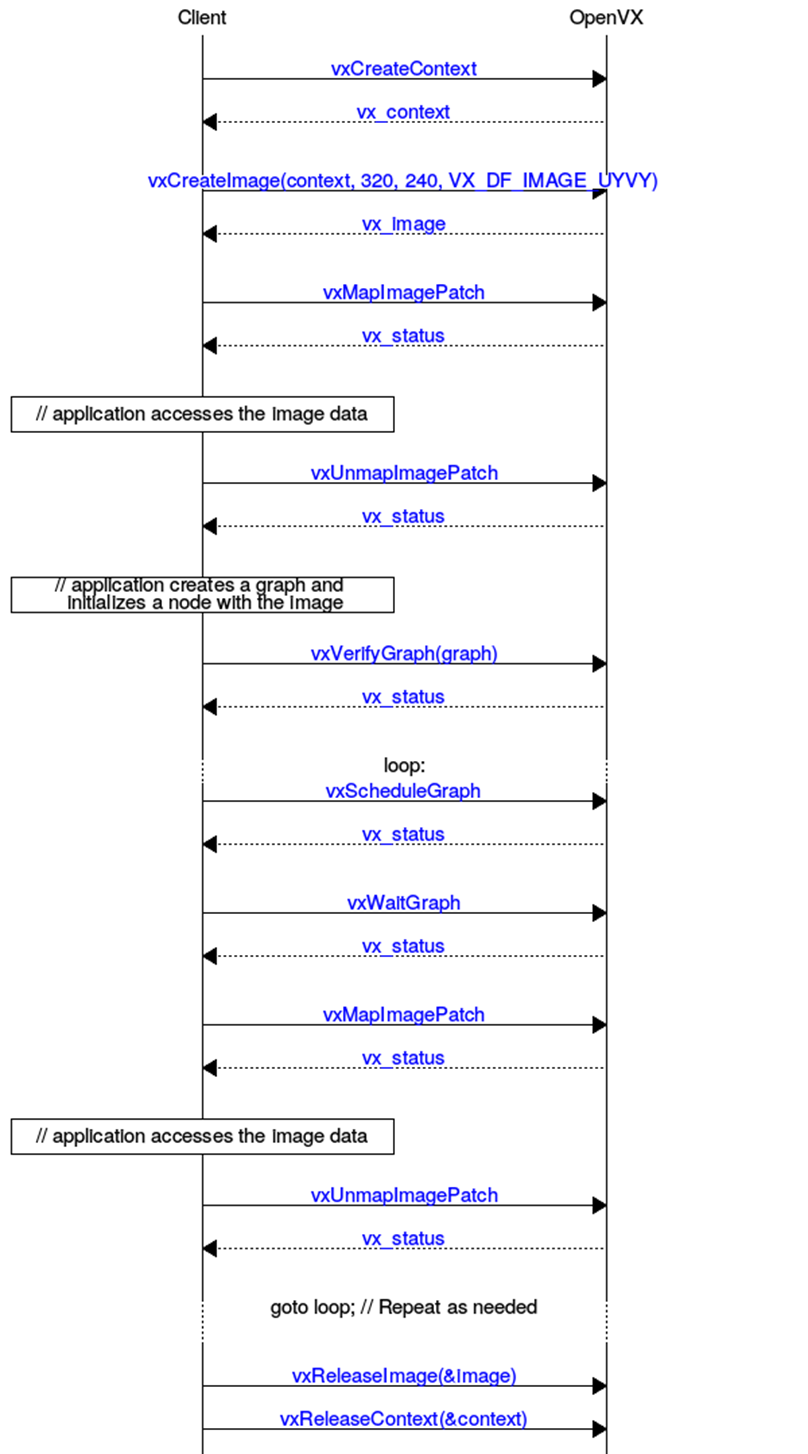
/* 图像访问示例 */
/* 由于更复杂的内存布局要求,图像和阵列的访问方式略有不同。*/
vx_status status = VX_SUCCESS;
void *base_ptr = NULL;
vx_uint32 width = 640, height = 480, plane = 0;
vx_image image = vxCreateImage(context, width, height, VX_DF_IMAGE_U8);
vx_rectangle_t rect;
vx_imagepatch_addressing_t addr;
vx_map_id map_id;
rect.start_x = rect.start_y = 0;
rect.end_x = rect.end_y = PATCH_DIM;
status = vxMapImagePatch(image, &rect, plane, &map_id,
&addr, &base_ptr,
VX_READ_AND_WRITE, VX_MEMORY_TYPE_HOST, 0);
if (status == VX_SUCCESS)
{
vx_uint32 x,y,i,j;
vx_uint8 pixel = 0;
/* 两种解决方案 */
/* 使用线性寻址功能/宏 */
for (i = 0; i < addr.dim_x*addr.dim_y; i++) {
vx_uint8 *ptr2 = vxFormatImagePatchAddress1d(base_ptr,
i, &addr);
*ptr2 = pixel;
}
/* 2d地址选择 */
for (y = 0; y < addr.dim_y; y+=addr.step_y) {
for (x = 0; x < addr.dim_x; x+=addr.step_x) {
vx_uint8 *ptr2 = vxFormatImagePatchAddress2d(base_ptr,
x, y, &addr);
*ptr2 = pixel;
}
}
/* 客户直接寻址
* 对于子采样平面,比例将发生变化
*/
for (y = 0; y < addr.dim_y; y+=addr.step_y) {
for (x = 0; x < addr.dim_x; x+=addr.step_x) {
vx_uint8 *tmp = (vx_uint8 *)base_ptr;
i = ((addr.stride_y*y*addr.scale_y) /
VX_SCALE_UNITY) +
((addr.stride_x*x*addr.scale_x) /
VX_SCALE_UNITY);
tmp[i] = pixel;
}
}
/* 客户端更高效的直接寻址。
*对于子采样平面,比例将发生变化。
*/
for (y = 0; y < addr.dim_y; y+=addr.step_y) {
j = (addr.stride_y*y*addr.scale_y)/VX_SCALE_UNITY;
for (x = 0; x < addr.dim_x; x+=addr.step_x) {
vx_uint8 *tmp = (vx_uint8 *)base_ptr;
i = j + (addr.stride_x*x*addr.scale_x) /
VX_SCALE_UNITY;
tmp[i] = pixel;
}
}
/* 将数据提交回图像
*/
status = vxUnmapImagePatch(image, map_id);
}
vxReleaseImage(&image);
// 数组访问示例
// 数组只需要一个值,即步长,而不是图像所需的整个寻址结构。
vx_uint8 *ptr2 = vxFormatImagePatchAddress1d(base_ptr,
i, &addr);
*ptr2 = pixel;
}
/* 2d地址选择 */
for (y = 0; y < addr.dim_y; y+=addr.step_y) {
for (x = 0; x < addr.dim_x; x+=addr.step_x) {
vx_uint8 *ptr2 = vxFormatImagePatchAddress2d(base_ptr,
x, y, &addr);
*ptr2 = pixel;
}
}
/* 客户直接寻址
* 对于子采样平面,比例将发生变化
*/
for (y = 0; y < addr.dim_y; y+=addr.step_y) {
for (x = 0; x < addr.dim_x; x+=addr.step_x) {
vx_uint8 *tmp = (vx_uint8 *)base_ptr;
i = ((addr.stride_y*y*addr.scale_y) /
VX_SCALE_UNITY) +
((addr.stride_x*x*addr.scale_x) /
VX_SCALE_UNITY);
tmp[i] = pixel;
}
}
/* 客户端更高效的直接寻址。
*对于子采样平面,比例将发生变化。
*/
for (y = 0; y < addr.dim_y; y+=addr.step_y) {
j = (addr.stride_y*y*addr.scale_y)/VX_SCALE_UNITY;
for (x = 0; x < addr.dim_x; x+=addr.step_x) {
vx_uint8 *tmp = (vx_uint8 *)base_ptr;
i = j + (addr.stride_x*x*addr.scale_x) /
VX_SCALE_UNITY;
tmp[i] = pixel;
}
}
/* 将数据提交回图像
*/
status = vxUnmapImagePatch(image, map_id);
}
vxReleaseImage(&image);
// 数组访问示例
// 数组只需要一个值,即步长,而不是图像所需的整个寻址结构。
vx_size i, stride = sizeof(vx_size);
void *base = NULL;
vx_map_id map_id;
/* 一次访问整个阵列 */
vxMapArrayRange(array, 0, num_items, &map_id, &stride, &base, VX_READ_AND_WRITE, VX_MEMORY_TYPE_HOST, 0);
for (i = 0; i < num_items; i++)
{
vxArrayItem(mystruct, base, i, stride).some_uint += i;
vxArrayItem(mystruct, base, i, stride).some_double = 3.14f;
}
vxUnmapArrayRange(array, map_id);
// Map/Unmap对可使用类似于以下的方法在数组的单个元素上调用:
/* 单独访问每个数组项 */
for (i = 0; i < num_items; i++)
{
mystruct *myptr = NULL;
vxMapArrayRange(array, i, i+1, &map_id, &stride, (void **)&myptr, VX_READ_AND_WRITE, VX_MEMORY_TYPE_HOST, 0);
myptr->some_uint += 1;
myptr->some_double = 3.14f;
vxUnmapArrayRange(array, map_id);
}
人工智能芯片与自动驾驶

 浙公网安备 33010602011771号
浙公网安备 33010602011771号