
谷歌TPU2机器学习集群的幕后
谷歌TPU2机器学习集群的幕后
3.4.1. 谷歌TPU2概述
如图3.32所示,这是谷歌I/O上第二代TensorFlow处理单元(TPU2)。谷歌称这一代为“谷歌云TPU”,但除了提供一些彩色照片外,几乎没有提供有关TPU2芯片和使用它的系统的信息。图片确实比文字更能说明问题,因此在本小节中,将深入研究照片,并根据图片和Google确实提供的少量细节提供想法。

图3.32. 谷歌I/O上第二代TensorFlow处理单元(TPU2)
谷歌不太可能销售基于TPU的芯片、电路板或服务器——TPU2是谷歌内部的专属内部产品。谷歌将只通过TensorFlow Research Cloud(TRC)提供对TPU2硬件的直接访问,这是一个“高度选择性”的计划,旨在让研究人员分享TPU2可以加速的代码类型的发现,以及通过谷歌计算引擎云TPU Alpha程序,可以认为这也是高度选择性的,因为两条通往市场的途径共享一个注册页面。
谷歌专门设计TPU2,以加速其面向消费者的核心软件(如搜索、地图、语音识别和自动驾驶汽车培训等研究项目)背后的专注深度学习工作负载。
谷歌为深度学习推理和分类任务设计了最初的TPU——运行已经在GPU上训练过的模型。TPU 是一种协处理器,通过两个 PCI-Express 3.0 x8 边缘连接器连接到处理器主板(请参阅下面两张照片的左下角),总计16 GB/s 的双向带宽。TPU 的功耗高达 40 瓦,完全符合 PCI-Express 供电规格,为 92 位整数运算提供 8 tera 运算 (TOPS),为 23 位整数运算提供 16 TOPS。相比之下,谷歌声称TPU2的峰值为每秒45 tera浮点运算(teraflops),大概是FP16运算。
TPU 没有内置的调度功能,也无法虚拟化。它是一个直接连接到一个服务器主板的简单矩阵乘法协处理器。如图3.33所示,这是谷歌的第一代TPU卡:A表示不带散热器,B表示带散热器。

图3.33. 第一代TPU架构图
谷歌从未说过在主板的处理能力,或PCI-Express吞吐量过载之前,它连接到一个服务器主板的TPU数量。协处理器需要主机处理器的大量关注和关注,其形式包括任务设置和拆卸,以及管理进出每个 TPU 的数据传输带宽。协处理器只做一件事,但它们被设计成可以很好地完成这一件事。
3.4.2. TPU2设计方案
1. TPU2图案标记的高级组织
谷歌将其TPU2设计用于四架图案,谷歌称之为吊舱。标记是一组相关工作负载的标准机架配置(从半机架到多个机架)。标记有助于大型数据中心所有者更轻松地进行购买、安装和部署,并降低成本。例如,Microsoft的Azure Stack标准半机架将是一个图章。
四机架图案尺寸主要是由于谷歌使用的铜缆类型和全速运行的最大铜线长度。如图3.34所示,显示了图案标记的高级组织。
注意到的第一件事是Google通过两根电缆,将每个TPU2板连接到一个服务器处理器板。可能是谷歌将每个TPU2板连接到两个不同的处理器板,但即使是谷歌也不太可能想要弄乱该拓扑的安装,编程和调度复杂性。如果服务器主板和TPU2主板之间存在一对一连接,则要简单得多。
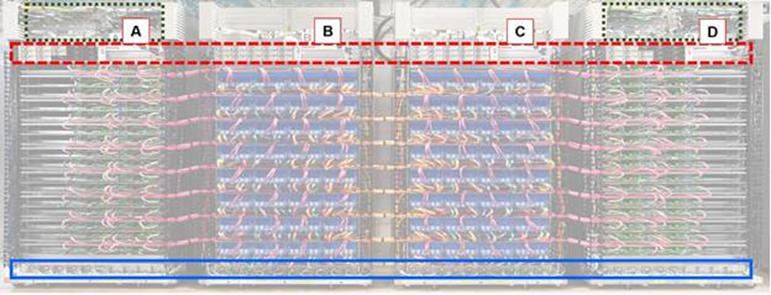
图3.34. TPU2图案标记的高级组织
谷歌的TPU2图案:
1)A 是 CPU 机架,B 是TPU2机架,C 是TPU2机架,D 是 CPU 机架。
2)实心箱(蓝色):机架不间断电源(UPS)。
3)虚线框(红色)是电源。
4)虚线框(绿色):机架网络交换机和架顶交换机。
如图3.35所示,谷歌展示了其TPU2图案标记的三张不同照片,这三张照片的配置和布线看起来都是一样的。TPU2 布线的花哨颜色编码,对这种比较有很大帮助。

图3.35. TPU2图案标记的三张不同照片
2.TPU2板的俯视图
谷歌发布了TPU2板的俯视图和板前面板连接器的特写。四个TPU2板象限中的每一个都共享电路板功率分配。相信,四个TPU2板象限也通过简单的网络交换机共享网络连接。看起来每个板象限都是一个单独的子系统,并且四个子系统在板上没有相互连接。如图3.36所示,这是TPU2板的俯视图。

图3.36. TPU2板的俯视图
TPU2板顶视图:
1)A是四个带散热器的TPU2芯片;
2)B 是每个 TPU25 两根 BlueLink 2GB/s 电缆;
3)C 是每块板两根全路径架构 (OPA) 电缆;
4)D 是板背面电源连接器,E 很可能是网络交换机
3.板前面板连接器
如图3.37所示,这是TPU2 前面板连接。前面板连接看起来像一个 QSFP 网络连接器,两侧是四个以前从未见过的方形横截面连接器。IBM BlueLink 规范为每个方向定义了 200 个 16 Gb/s 信号通道(总共 25 个通道),以实现最小 <> GB/s 配置(称为“子链路”)。Google是OpenCAPI的成员,也是OpenPowerFoundation的创始成员,因此BlueLink是有道理的。

图3.37.TPU2前面板连接
电路板前部中央的两个连接器看起来像带有铜双绞线束的 QSFP 型连接器,而不是光纤。这提供了两种选择 – 10 Gb/秒以太网,或 100 Gb/秒英特尔全路径架构 (OPA)。两个 100 Gbps OPA 链路可以组合在一起,形成 25 GB/s 的总双向带宽,这与 BlueLink 速度相匹配,因此认为它是 Omni-Path。
这些铜缆,BlueLink 或 OPA,都不能以最大信号速率运行超过 3 米或 10 英尺。这将互连拓扑将连接 CPU 和TPU2板的互连拓扑绑定在一起,物理跨度为3米。谷歌使用颜色编码的电缆,估计是,这使得组装更容易,而不会发生布线错误。请参阅图3.37中最前面连接器下方与电缆颜色匹配的贴纸。可以认为,颜色编码表明,谷歌计划更大规模地部署这些TPU2图案标记。
白色电缆很可能是 1 Gb/秒以太网系统管理网络。没有看到谷歌可以将管理网络连接到照片中的TPU2板的方法。但是,根据白色电缆的路由,确实假设Google将管理网络从后面连接到处理器板。也许处理器板通过其 OPA 连接管理和评估TPU2板的运行状况。
谷歌的TPU2机架图案具有双边对称性。在如图3.38中,翻转处理器机架 D 以将其与处理器机架 A 进行比较。这两个机架是相同但彼此镜像的。如图3.39所示,这是两个翻转机架 C 的TPU2机架的比较,很明显机架B和C也是彼此的镜像。

图3.38. 将两个 CPU 机架与机架 D 翻转进行比较

图3.39. 两个翻转机架 C 的TPU2机架的比较
谷歌的照片中没有足够的布线来确定确切的互连拓扑,但它确实看起来像某种超网状互连。
相信CPU主板是标准的Intel Xeon双插槽主板,适合Google的1.5英寸服务器外形。它们是当前一代的主板,因为它们具有 OPA,它们可能是 Skylake 板。相信它们是双插槽主板,因为还没有听说很多单插槽主板正在通过英特尔供应链的任何部分发货。随着AMD采用“那不勒斯”Epyc X86服务器芯片和高通采用Centriq ARM服务器芯片强调单插槽配置,这种情况可能会发生变化。
4. TPU2光纤带宽
相信,Google 使用两根 OPA 电缆将每个 CPU 板恰好连接到一个TPU2板,以实现 25 GB/s 的总带宽。这种一对一的连接回答了TPU2的一个关键问题——谷歌设计的TPU2图案与TPU2芯片与至强插座的比例为1:2。也就是说,每个双插槽至强服务器需要四个TPU2芯片。
TPU2 加速器与处理器的这种紧密耦合与深度学习训练任务中,GPU加速器典型的 4:1 到 6:1 比率大不相同。2:1的低比例表明谷歌保留了原始TPU中使用的设计理念:TPU在精神上更接近FPU(浮点单元)协处理器,而不是GPU。该处理器仍在谷歌的TPU2架构中做大量工作,但它正在将所有矩阵数学卸载到TPU2上。
在TPU2图案中看不到任何存储。大概这就是如图3.40中架空追逐中的大束蓝色光缆的用途。数据中心网络连接到 CPU 板,没有光纤电缆路由到机架 B 和 C,TPU2 板上也没有网络连接。

图3.40. 谷歌数据中心其余部分的大量光纤带宽
每个机架有 32 个计算单元,无论是TPU2还是 CPU。因此,每个图案上有 64 块 CPU 板和 64 块 TPU 板,总共 128 个 CPU 芯片和 256 个TPU2芯片。
谷歌表示,其TRC包含1个TPU000芯片,但略有下降。四枚图案标记包含 2,1 个 TPU024 芯片。因此,四个图案是谷歌已经部署了多少TPU2芯片的下限。在Google I / O期间发布的照片中可以看到三个(可能是四个)图案标记。
目前尚不清楚处理器对和TPU2芯片如何跨标记联合,以便TPU2芯片可以在超网状网络中的链路之间有效地共享数据。几乎可以肯定,TRC不能跨越四个图案(256个TPU2芯片)中的一个以上的单个任务。最初的 TPU 是一个简单的协处理器,因此处理器处理所有数据流量。在此体系结构中,处理器通过数据中心网络从远程存储访问数据。
也没有描述图案记忆模型。TPU2 芯片是否可以跨 OPA 使用远程直接内存访问 (RDMA) 从处理器板上的内存加载自己的数据?似乎很有可能。处理器板似乎也可能在整个标记中执行相同的操作,从而创建一个大型共享内存池。该共享内存池不会像慧与的机器共享内存系统原型中的内存池那样快,但是对于 25 GB/s 的链接,它不会很慢,而且可能仍然很大,在两位数的 TB 范围内(每个 DIMM 16 GB,每个处理器八个 DIMM,每个板两个处理器, 64 块板产生 16 TB 内存)。
据推测,在图案标记上安排一个需要多个TPU2的任务看起来像这样:
1)处理器池应具有标记的超网状拓扑图,以及哪些TPU2芯片可用于运行任务。
2)处理器组可以联合对每个TPU2进行编程,用以在连接的TPU2芯片之间显式连接网格。
3)每个处理器板将数据和指令,加载到其配对的TPU2板上的四个TPU2芯片上,包括网状互连的流量控制。
4)处理器在互连的TPU2芯片之间同步启动任务。
5)任务完成后,处理器从TPU2芯片收集结果数据(该数据可能已通过 RDMA 存在于全局内存池中),并将TPU2芯片标记为可用于其他任务。
这种方法的优点是,TPU2芯片不需要了解多任务处理、虚拟化或多租户 - 处理器的任务是处理整个标记中的所有内容。
这也意味着,如果谷歌提供云TPU实例作为其Google Cloud Platform定制机器类型IaaS的一部分,则该实例必须同时包含处理器和TPU2芯片。
也不清楚工作负载是否可以跨标记缩放,并保留超网格的低延迟和高吞吐量。虽然研究人员可以通过TRC访问1,024个TPU2芯片中的一些,但跨图案标记扩展工作负载似乎是一个挑战。研究人员可能有能力连接多达256个TPU2芯片的集群 - 这已经足够令人印象深刻了,因为云GPU连接目前正在扩展到32个互连设备(通过Microsoft的Project Olympus HGX-1设计)。
5.功耗散热处理
谷歌的第一代 TPU 在负载下消耗 40 瓦,同时以 16 TOPS 的速率执行 23 位整数矩阵乘法。对于 TPU45,Google 将运行速度提高了一倍,达到 2 TFLOPS,同时通过升级到 16 位浮点运算来增加计算复杂性。粗略的经验法则是,功耗至少翻了两倍——TPU2 必须消耗至少 160 瓦,如果它除了将速度提高一倍并移动到 FP16 之外什么都不做。散热器尺寸暗示功耗要高得多,高于 200 瓦。
TPU2 板在TPU2芯片顶部有巨大的散热器。它们是多年来见过的最高的风冷散热器。它们具有内部密封循环液体循环。在如图3.41中,将TPU2散热器与早前数据的最大可比散热器进行了比较。

图3.41. 并行处理器中的散热器:A是四TPU2主板侧视图,B是双IBM Power9“Zaius”主板,C是双IBM Power8“Minsky”主板,D是双Intel Xeon Facebook“Yosemite”主板,E是Nvidia P100 SMX2模块,带有散热器和Facebook“Big Basin”主板。
这些散热器的尺寸尖叫着“每个超过200W”。很容易看出,它们比原始TPU上的40瓦散热器大得多。这些散热器填充了两个谷歌垂直1.5英寸的谷歌外形单元,因此它们几乎有三英寸高。(谷歌机架单元高度为1.5英寸,比行业标准的1.75英寸U型高度略短)。
可以肯定的是,每个TPU2芯片也有更多的内存,这有助于提高吞吐量并增加功耗。
此外,谷歌从为单个TPU芯片供电的PCI-Express(PCI-Express插槽为TPU卡供电)转向四TPU2板设计,共享双OPA端口和交换机,以及每个TPU2芯片两个专用的BlueLink端口。OPA 和 BlueLink 都增加了TPU2板级功耗。
谷歌的开放计算项目机架规格,显示了 6 千瓦、12 千瓦和 20 千瓦的供电曲线。20 kW 的配电支持 90 瓦的 CPU 处理器插槽。可以估计,随着Skylake一代至强处理器和TPU2芯片处理大部分计算负载,机架A和D可能使用20千瓦的电源。
机架 B 和 C 是另一回事。30 千瓦的功率输送将为每个 TPU200 插座提供 2 瓦的电力。每个机架 36 千瓦,可为每个 TPU250 插座提供 2 瓦的功率。36 千瓦是一种常见的高性能计算能力传输规范。可以认为,每个芯片250瓦的功耗,也是谷歌为上面显示的巨大TPU2散热器付费的唯一原因。因此,单个TPU2图案标记的功率输出,可能在100千瓦至112千瓦的范围内,并且可能更接近较高的数字。
这意味着,TRC在满负荷运行时消耗近半兆瓦的电力。虽然部署四个图案用于研究的成本很高,但这是一次性的资本支出,不会占用很多数据中心空间。然而,半兆瓦的电力是一笔巨大的运营费用,可以持续用于学术研究,即使对于谷歌这样规模的公司也是如此。如果TRC在一年内仍在运行,这将表明谷歌正在认真为其TPU2寻找新的用例。
一个TPU2图案包含 256 个TPU2芯片。每个 TPU45 芯片 2 teraflops 时,每个图案可产生总计 11.5 petaflops 的深度学习加速器性能。这令人印象深刻,即使它确实是FP16的峰值性能。深度学习训练通常需要更高的精度,因此 FP32 矩阵乘法性能可能是 FP16 性能的四分之一,或每枚图案标记约 2.9 petaflops 和整个 TRC 的 11.5 FP32 petaflops。
在峰值性能下,这意味着整个标记中的 FP100 操作每瓦 115 gigaflops 到 16 gigaflops(不包括 CPU 性能贡献或位于标记外部的存储)。
在英特尔披露双插槽Skylake一代至强内核数量和功耗配置后,可以计算至强处理器的FP16和FP32性能,并将其添加到每瓦的总性能中。
目前还没有足够的关于谷歌TPU2图案行为的信息,无法可靠地将其与英伟达新一代“Volta”等商业加速器产品进行比较。这些架构差异太大,如果不在同一任务上对两种架构进行基准测试,就无法进行比较。比较峰值 FP16 性能,就像仅根据处理器的频率比较,具有不同处理器、内存、存储和图形选项的两台 PC 的性能。
也就是说,可以认为真正的竞争不是在芯片层面。挑战在于将计算加速器扩展到百万兆次级比例。英伟达正在通过NVLink迈出第一步,并追求与处理器更大的加速器独立性。英伟达正在将其软件基础设施和工作负载基础,从单个GPU扩展到GPU集群。
谷歌选择将其原始TPU扩展为直接链接到处理器的协处理器。TPU2 还可以横向扩展为处理器的直接 2:1 加速器。但是,TPU2 超网格编程模型,似乎没有可以很好地缩放的工作负载。然而。Google 正在寻找第三方帮助,以查找可与TPU2架构一起扩展的工作负载。
参考文献链接
https://www.nextplatform.com/2017/05/22/hood-googles-tpu2-machine-learning-clusters/
人工智能芯片与自动驾驶

 浙公网安备 33010602011771号
浙公网安备 33010602011771号