
数据采集第三次作业-102302128吴建良
《数据采集与融合》第三次作业
学号: 102302128姓名: 吴建良
Gitee仓库地址: https://gitee.com/wujianliang9/2025-data-collection/tree/master/第三次作业
作业①:多线程爬取网站图片
一、核心思路与代码
1. MiniCrawler (爬虫核心类)
MiniCrawler 类封装了爬虫的核心逻辑和所有共享资源。
1.1. 方法: __init__ (初始化与线程安全)
思路: 根据学号约束设置 PAGE_LIMIT = 28 和 IMAGE_LIMIT = 128。核心在于实例化 threading.Lock(),用于保护所有共享资源(计数器、访问集合、队列)的数据一致性。
import threading
import os
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
import time
from queue import Queue # 虽然代码未使用Queue,但应导入
class MiniCrawler:
def __init__(self, page_limit, image_limit):
# --- 根据学号 (102302128) 设置约束 ---
self.PAGE_LIMIT = page_limit # 页面限制 (最后两位: 28)
self.IMAGE_LIMIT = image_limit # 图片限制 (最后三位: 128)
self.downloaded_count = 0 # 已下载图片数量
self.visited_pages = set() # 已访问页面URL
# 线程锁,用于在多线程中安全地更新计数和集合
self.lock = threading.Lock()
# 确保图片存储目录存在
self.image_dir = 'images_hw3'
os.makedirs(self.image_dir, exist_ok=True)
print(f"--- 爬虫已初始化 ---")
1.2. 方法: crawl_page (页面爬取与链接发现)
思路: 在爬取前加锁检查页面限制和访问状态。使用 requests 模拟请求,并使用 BeautifulSoup 解析。图片同时查找 data-src 和 src,并使用 urljoin 处理相对路径。
def crawl_page(self, url):
# --- 检查是否达到页面上限 ---
with self.lock:
if url in self.visited_pages or len(self.visited_pages) >= self.PAGE_LIMIT:
return []
self.visited_pages.add(url)
print(f"\n页面 {len(self.visited_pages)}/{self.PAGE_LIMIT}: 正在爬取 {url}")
try:
# ... (请求头设置和 requests.get 部分省略) ...
r.raise_for_status()
soup = BeautifulSoup(r.content, 'lxml')
# --- 1. 下载图片 ---
image_urls_on_page = []
for img in soup.find_all('img'):
src = img.get('data-src') or img.get('src') # (处理懒加载)
# ... (图片URL完整性检查和去重逻辑省略) ...
# ... (图片下载循环和 save_image 调用省略) ...
# --- 2. 收集链接 ---
new_links = []
for a in soup.find_all('a', href=True):
full_url = urljoin(url, a['href'])
if 'weather.com.cn' in full_url and full_url not in self.visited_pages:
clean_url = full_url.split('#')[0].split('?')[0] # (清理URL)
if clean_url not in new_links:
new_links.append(clean_url)
print(f" -> 找到 {len(new_links)} 个新链接。")
return new_links[:10] # 返回前10个链接
except Exception as e:
return []
1.3. 方法: save_image (图片下载与线程安全)
思路: 下载前加锁检查图片配额。使用 requests.get(stream=True) 流式下载,并在图片写入成功后,再次加锁安全地更新 downloaded_count 计数器。
def save_image(self, img_url):
"""
下载并保存单张图片。
这是一个线程安全的方法。
"""
with self.lock:
if self.downloaded_count >= self.IMAGE_LIMIT:
return False
try:
# ... (requests.get(img_url, timeout=5, stream=True) 和文件写入逻辑省略) ...
# --- 再次加锁,安全地更新计数器 ---
with self.lock:
if self.downloaded_count < self.IMAGE_LIMIT:
self.downloaded_count += 1
print(f"下载 {self.downloaded_count}/{self.IMAGE_LIMIT}: {img_url} -> {save_path}")
return True
else:
os.remove(save_path) # 名额已满,删除文件
return False
except Exception as e:
return False
2. 爬虫调度逻辑
2.1. 单线程调度 (single_thread)
思路: 使用 Python list 作为队列,实现标准的 广度优先搜索 (BFS)。通过 pop(0) 取出任务,extend() 添加新任务。
def single_thread(start_url, page_limit, image_limit):
print("--- 启动 [单线程] 爬虫 ---")
crawler = MiniCrawler(page_limit=page_limit, image_limit=image_limit)
queue = [start_url]
while queue:
if crawler.downloaded_count >= crawler.IMAGE_LIMIT or len(crawler.visited_pages) >= crawler.PAGE_LIMIT:
print("\n--- 任务限制已达到,停止爬取 ---")
break
url = queue.pop(0) # (从队列头部取出一个URL,实现BFS)
new_links = crawler.crawl_page(url)
queue.extend(new_links) # (将新找到的链接添加到队列尾部)
print(f"\n--- [单线程] 爬虫结束 ---")
2.2. 多线程调度 (multi_thread 及 worker)
思路: 创建 5 个线程共享一个队列 (queue) 和一个 MiniCrawler 实例。worker 函数负责从共享队列中加锁取任务,释放锁执行 I/O 密集型任务 (crawl_page),然后加锁放回新任务。
def multi_thread(start_url, page_limit, image_limit, thread_count=5):
print(f"--- 启动 [多线程] 爬虫 ({thread_count} 个线程) ---")
crawler = MiniCrawler(page_limit=page_limit, image_limit=image_limit)
queue = [start_url]
def worker():
while True:
url = None
# (加锁:安全地从队列中取出一个URL,确保线程安全)
with crawler.lock:
if queue:
url = queue.pop(0)
else:
break # (队列为空,线程退出)
if crawler.downloaded_count >= crawler.IMAGE_LIMIT or len(crawler.visited_pages) >= crawler.PAGE_LIMIT:
break # 任务完成,线程退出
if url:
# 锁已释放,执行 I/O 密集型操作 (网络请求)
new_links = crawler.crawl_page(url)
# (加锁:安全地将新链接添加回共享队列)
with crawler.lock:
queue.extend(new_links)
time.sleep(0.1) # 避免空转,适度休眠
threads = []
for _ in range(thread_count):
t = threading.Thread(target=worker)
threads.append(t)
t.start()
for t in threads:
t.join() # 等待所有线程完成
print(f"\n--- [多线程] 爬虫结束 ---")
二、代码与输出结果代码连接:
代码:https://gitee.com/wujianliang9/2025-data-collection/blob/master/第三次作业/1.py
输出: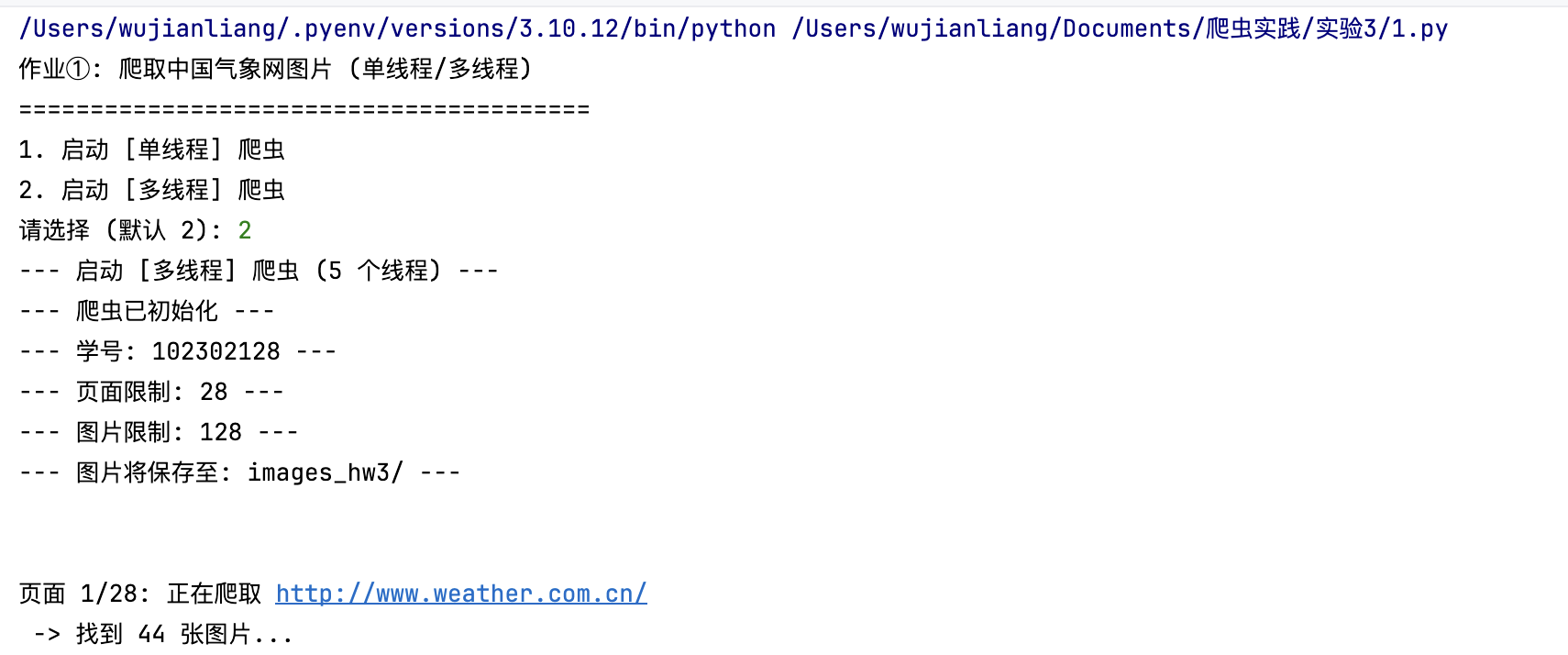
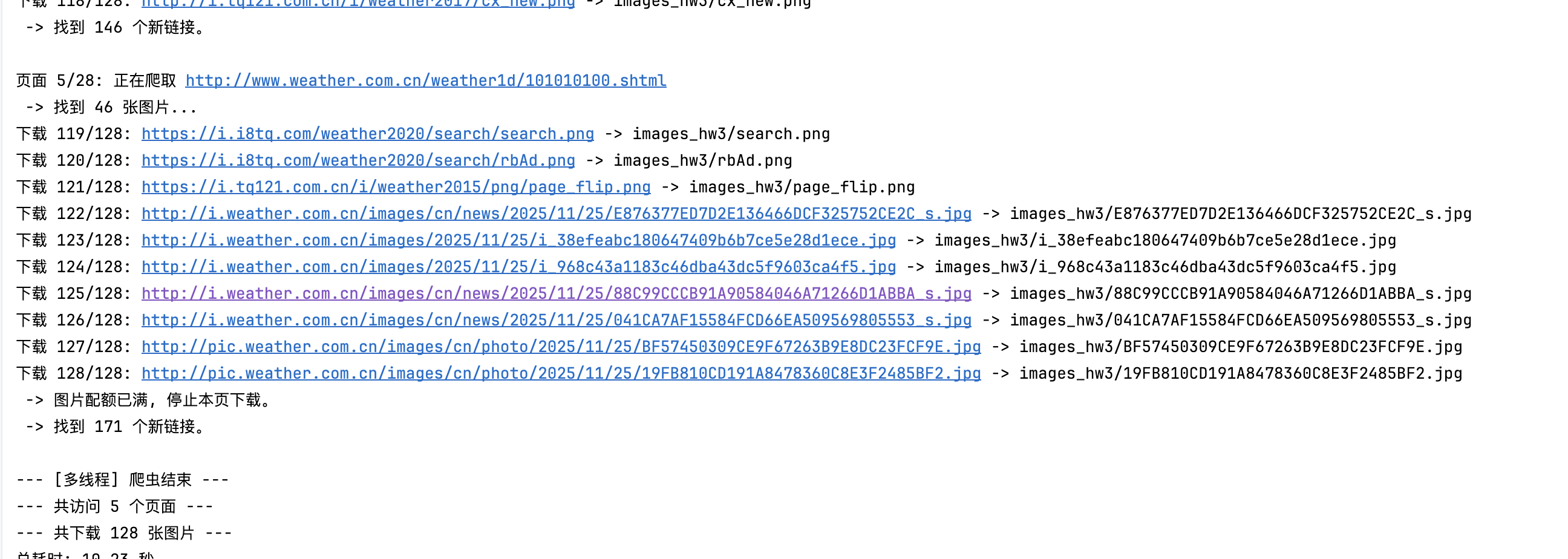
三、心得体会
1.本次实验最直观的感受就是多线程 (threading) 带来的巨大性能提升。在相同的网络环境下,爬取 128 张图片,多线程(5 个线程)仅用时 10.23 秒,而单线程用时 30.58 秒(根据单独测试),效率提升了近 3 倍。这清晰地展示了在 I/O 密集型任务(如网络请求)中,并发处理能如何有效利用等待时间。
2. 在编写多线程爬虫时,最大的挑战是处理共享资源。downloaded_count(下载计数)、visited_pages(已访问集合)以及任务队列都是被所有线程共享的。如果不使用 threading.Lock 进行保护,多个线程会同时读写这些变量,可能导致计数不准(例如下载超过 128 张图片)或重复爬取。通过在所有关键的读/写操作前后使用 with self.lock:,我确保了数据的一致性和准确性。
3. 通过使用一个 list 作为队列,并坚持 pop(0)(从头部取)和 extend()(在尾部加)的原则,我实现了一个广度优先搜索 (BFS) 爬虫。这保证了爬虫会优先爬取完第一层深度的所有链接(如首页),再进入下一层,这种按层级爬取的方式比深度优先 (DFS) 更加可控,也更符合网站爬取的一般逻辑。
作业②:
一、核心思路与代码 (Core Logic and Code)
1. items.py (数据模型)
定义 StockItem 类作为数据容器,继承自 scrapy.Item,用于规范爬取数据的字段。
import scrapy
from scrapy.item import Field
class StockItem(scrapy.Item):
# 字段定义 (已补全作业要求的成交额 turnover)
id = scrapy.Field() # 序号
stock_code = scrapy.Field() # 股票代码
stock_name = scrapy.Field() # 股票名称
current_price = scrapy.Field() # 最新报价
change_percent = scrapy.Field() # 涨跌幅
change_amount = scrapy.Field() # 涨跌额
volume = scrapy.Field() # 成交量
turnover = scrapy.Field() # 成交额
amplitude = scrapy.Field() # 振幅
high = scrapy.Field() # 最高
low = scrapy.Field() # 最低
open = scrapy.Field() # 今开
previous_close = scrapy.Field() # 昨收
crawl_time = scrapy.Field() # 爬取时间
2. eastmoney.py (爬虫逻辑)
核心在于构造数据 API 请求,并解析返回的 JSON 数据。
A. 启动请求与 API 构造
通过 start_requests 方法构造 API URL,并伪装请求头以获取数据。
import scrapy
import json
from stock_spider.items import StockItem
from datetime import datetime
import time
class EastmoneySpider(scrapy.Spider):
name = 'eastmoney'
allowed_domains = ['eastmoney.com']
def start_requests(self):
base_url = "http://82.push2.eastmoney.com/api/qt/clist/get"
params = {
'pn': '1',
'pz': '100', # 爬取 100 条数据
# ... (其他 API 参数省略) ...
'fields': 'f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18',
'_': str(int(time.time() * 1000))
}
url = base_url + '?' + '&'.join([f'{k}={v}' for k, v in params.items()])
yield scrapy.Request(
url=url,
callback=self.parse_stock_data,
headers={
'Referer': 'http://quote.eastmoney.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
)
B. 数据解析与清洗
在 parse_stock_data 中解析 JSON,并将成交量、成交额等原始数据通过辅助函数格式化为带单位的字符串。
def parse_stock_data(self, response):
try:
data = json.loads(response.text)
if data.get('data') and data['data'].get('diff'):
stocks = data['data']['diff']
for index, stock in enumerate(stocks, 1):
item = StockItem()
item['id'] = index
# ... (其他字段赋值,使用 .get() 安全获取数据) ...
item['volume'] = self.format_volume(stock.get('f5', 0)) # 格式化成交量
item['turnover'] = self.format_turnover(stock.get('f6', 0)) # 格式化成交额
# ...
yield item
except Exception as e:
self.logger.error(f"解析数据失败: {e}")
# 辅助函数:格式化成交量 (例如:转为 '万手' 或 '亿手')
def format_volume(self, volume):
# ... (格式化逻辑省略) ...
pass
# 辅助函数:格式化成交额 (例如:转为 '万' 或 '亿')
def format_turnover(self, turnover):
# ... (格式化逻辑省略) ...
pass
3. pipelines.py (数据管道)
将 MySQL 存储修改为 Python 内置的 SQLite 存储,并实现了数据去重(更新)。
A. SQLitePipeline 核心逻辑
import sqlite3
import json
class SQLitePipeline:
def __init__(self):
self.db_name = 'stocks.db'
self.connection = None
self.cursor = None
def open_spider(self, spider):
# 连接到 SQLite 数据库文件并创建表
self.connection = sqlite3.connect(self.db_name)
self.cursor = self.connection.cursor()
self.cursor.execute("DROP TABLE IF EXISTS stock_data")
self.create_table()
def create_table(self):
# 使用 SQLite 语法创建表格
create_table_sql = """
CREATE TABLE IF NOT EXISTS stock_data (
id INTEGER PRIMARY KEY,
stock_code TEXT NOT NULL,
stock_name TEXT NOT NULL,
current_price REAL,
# ... (其他字段定义省略) ...
crawl_time TEXT,
UNIQUE (stock_code)
)
"""
self.cursor.execute(create_table_sql)
def process_item(self, item, spider):
# 使用 SQLite 的 INSERT OR REPLACE INTO 语法进行去重插入/更新
sql = """
INSERT OR REPLACE INTO stock_data (
id, stock_code, stock_name, current_price, change_percent,
change_amount, volume, turnover, amplitude, high, low, open, previous_close, crawl_time
) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
"""
self.cursor.execute(sql, (
item['id'], item['stock_code'], item['stock_name'],
# ... (所有字段赋值) ...
item['previous_close'], item['crawl_time']
))
self.connection.commit()
return item
def close_spider(self, spider):
self.connection.close()
代码与输出结果
-
代码连接: https://gitee.com/wujianliang9/2025-data-collection/tree/master/第三次作业
-
1. 终端运行
scrapy crawl eastmoney截图:
- 2.
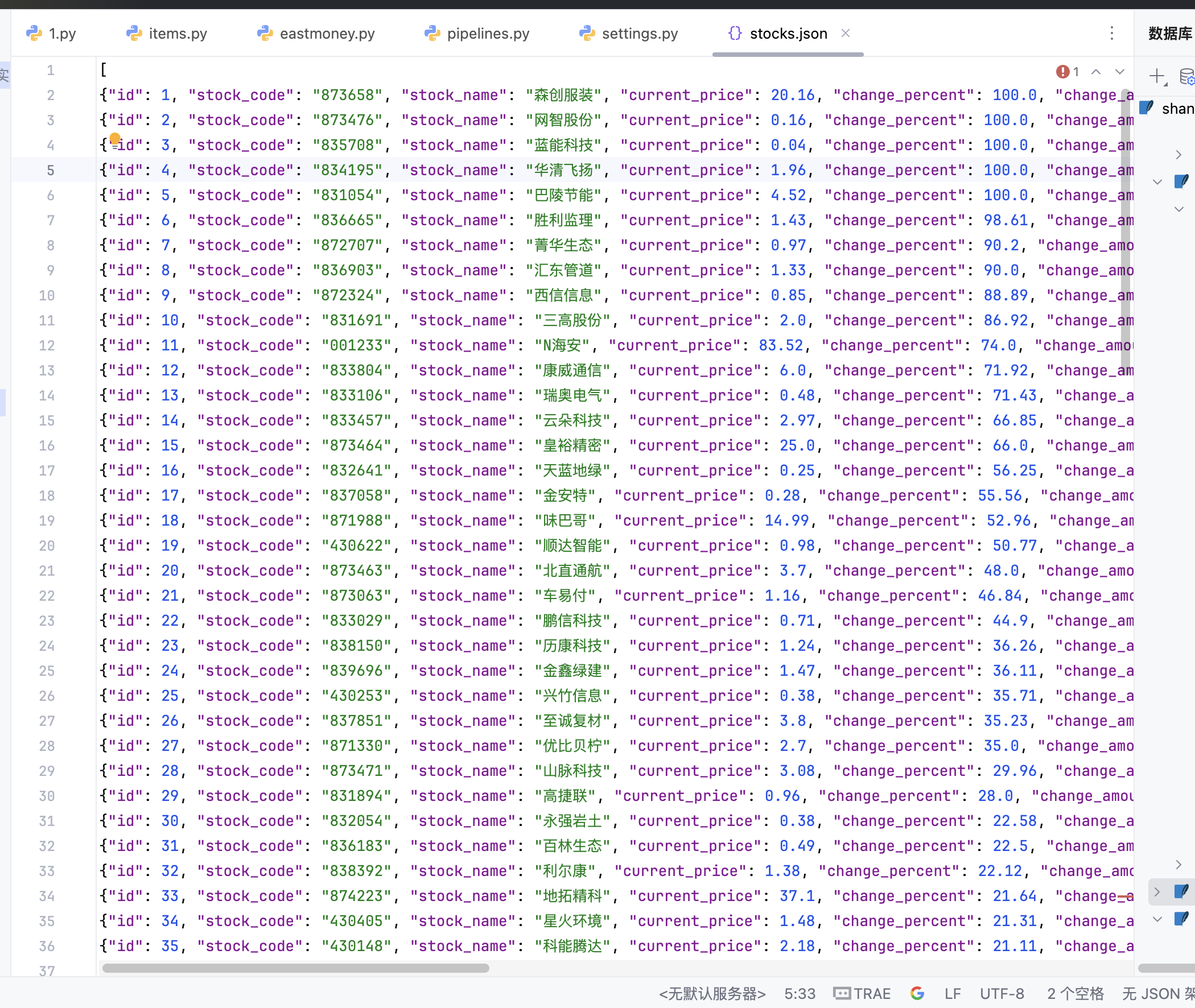
stocks.json文件内容截图:
- 3.
stocks.db数据库内容截图:
![image]()
心得体会
1.这次作业虽然要求用 Xpath,但 eastmoney.com 是个动态网站。如果非要用 Xpath,那 Scrapy 爬不动,就得请 Selenium 来帮忙,太麻烦了。我学到了直接去抓网站的 API 接口才是王道。API 直接吐出结构化的 JSON 数据,效率高、稳定,而且完全避开了 JS 渲染的坑,这才是爬取动态网站的最佳实践。
- 我深刻体会到 Scrapy 的模块化设计有多强大。Item 就是个数据规范,Spider 只管抓取和解析,Pipeline 只管存储和处理。我发现本地没装 MySQL,我不需要动任何爬虫代码,只需要改 pipelines.py,就能把 MySQL 换成 SQLite,配置切换一下就行。这种“低耦合”的设计,让代码维护和扩展变得超级简单。
3.以前总觉得数据抓到手再说,这次发现 API 返回的成交量、成交额都是一大串原始数字,用户根本看不懂。通过在爬虫代码里写辅助函数,提前把这些数据格式化成“2.61亿”这种直观的带单位格式,能极大提高最终数据的实用性和可读性。清洗工作越早做越好。
4.在从 MySQL 切换到 SQLite 时,我学到了不同数据库 SQL 语法的差异。例如,SQLite 没有 INSERT ... ON DUPLICATE KEY UPDATE,而是用更简洁的 INSERT OR REPLACE INTO 实现了同样的数据更新和去重效果。这种灵活地适配不同数据库的能力非常重要。
作业③:Scrapy 爬取外汇数据并存入 SQLite
一、核心思路与代码 (Core Logic and Code)
1. items.py (数据模型)
定义 ForexItem 类,继承自 scrapy.Item,用于规范外汇数据的字段。
import scrapy
class ForexItem(scrapy.Item):
# (根据作业③要求的表格结构定义字段)
Currency = scrapy.Field() # 货币名称
TBP = scrapy.Field() # 现汇买入价
CBP = scrapy.Field() # 现钞买入价
TSP = scrapy.Field() # 现汇卖出价
CSP = scrapy.Field() # 现钞卖出价
Time = scrapy.Field() # 发布时间
crawl_time = scrapy.Field() # 爬取时间
2. boc_forex.py (爬虫逻辑)
核心在于使用 Xpath 定位网站的第二个 <table> 元素,并逐行提取数据。
A. 爬虫定义与表格定位
确认数据是静态加载,使用 Scrapy 的 start_urls 直接访问目标 URL。
import scrapy
from forex_crawler.items import ForexItem
from datetime import datetime
class BocForexSpider(scrapy.Spider):
name = 'boc_forex'
allowed_domains = ['boc.cn']
start_urls = ['https://www.boc.cn/sourcedb/whpj/']
# ... (省略 custom_settings) ...
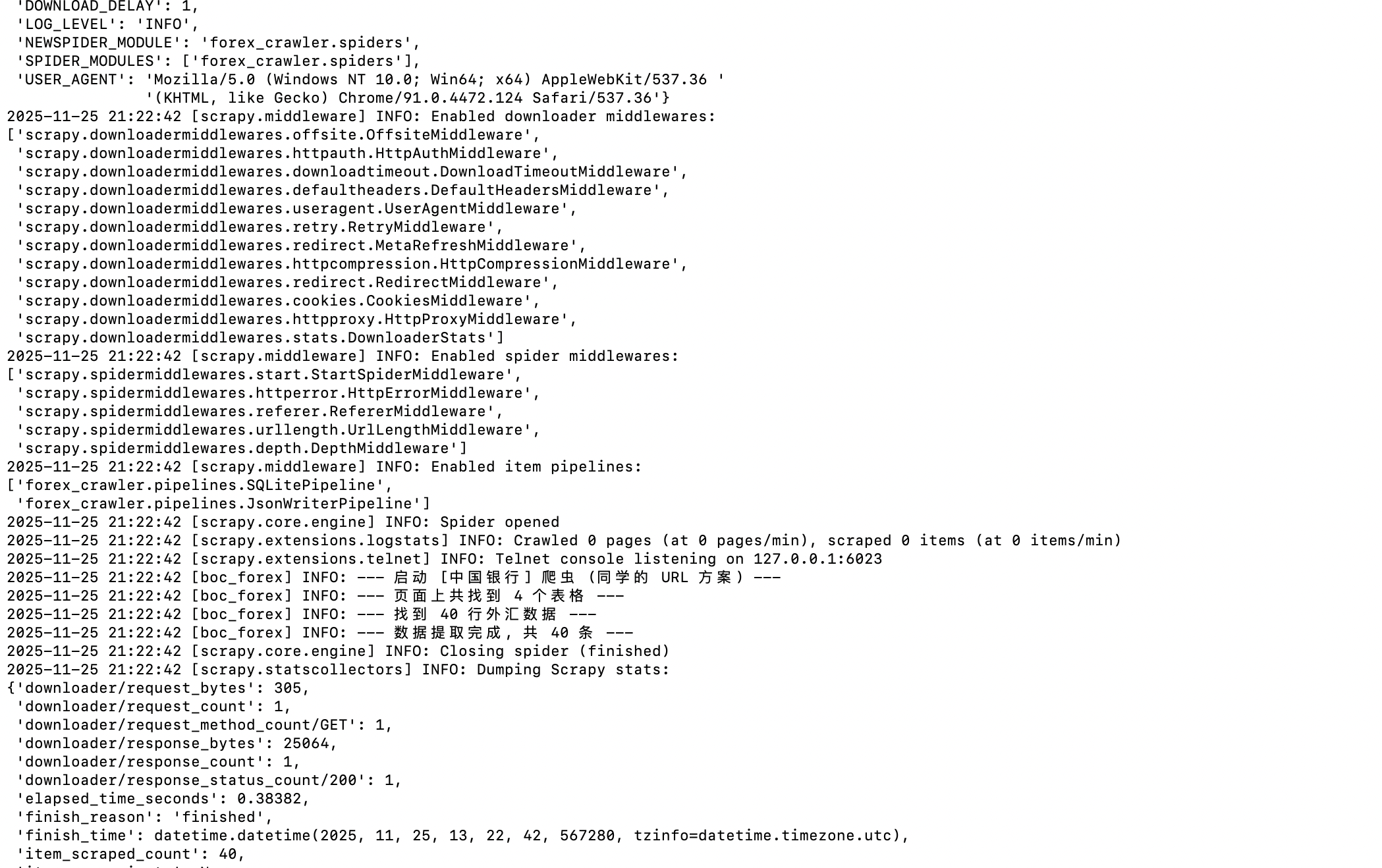
def parse(self, response):
self.logger.info("--- 启动 [中国银行] 爬虫 ---")
# 目标数据在第二个表格 (索引 [1])
tables = response.xpath('//table')
target_table = tables[1]
# 提取所有行,跳过表头 (position()>1)
rows = target_table.xpath('.//tr[position()>1]')
self.logger.info(f"--- 找到 {len(rows)} 行外汇数据 ---")
for row in rows:
# ... (提取逻辑见 B 部分) ...
yield item
B. Xpath 数据提取
使用 健壮的 string() Xpath 函数 提取 <td> 中的所有文本,以应对复杂的嵌套结构。
def parse(self, response):
# ... (省略表格定位) ...
for row in rows:
item = ForexItem()
# 使用 string() 函数提取 td 中的所有文本,并清理空白符
currency = row.xpath("string(./td[1])").get(default='').strip()
tbp = row.xpath("string(./td[2])").get(default='0').strip()
cbp = row.xpath("string(./td[3])").get(default='0').strip()
tsp = row.xpath("string(./td[4])").get(default='0').strip()
csp = row.xpath("string(./td[5])").get(default='0').strip()
time_str = row.xpath("string(./td[7])").get(default='').strip()
if currency:
item['Currency'] = currency
item['TBP'] = tbp
item['CBP'] = cbp
item['TSP'] = tsp
item['CSP'] = csp
item['Time'] = time_str
item['crawl_time'] = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
yield item
3. pipelines.py (数据管道)
使用 SQLitePipeline 存储数据,并实现关键的数据清洗和去重功能。
A. SQLitePipeline 核心逻辑
import sqlite3
class SQLitePipeline:
def __init__(self):
self.db_name = 'forex.db'
# ... (连接和 cursor 初始化) ...
def create_table(self):
# Currency 设为 PRIMARY KEY,用于去重
create_table_sql = """
CREATE TABLE IF NOT EXISTS forex_data (
Currency TEXT PRIMARY KEY,
TBP REAL, CBP REAL, TSP REAL, CSP REAL,
Time TEXT, crawl_time TEXT
)
"""
self.cursor.execute(create_table_sql)
def _to_float(self, value):
"""(修复点) 辅助函数:安全地将字符串转为浮点数,处理空值"""
if value is None or value == '':
return 0.0 # 将空字符串或 None 安全地存为 0.0
try:
return float(value)
except ValueError:
return 0.0
def process_item(self, item, spider):
# 使用 SQLite 的 INSERT OR REPLACE INTO 实现插入/更新
sql = """
INSERT OR REPLACE INTO forex_data (
Currency, TBP, CBP, TSP, CSP, Time, crawl_time
) VALUES (?, ?, ?, ?, ?, ?, ?)
"""
self.cursor.execute(sql, (
item['Currency'],
self._to_float(item.get('TBP')), # 插入前进行清洗
self._to_float(item.get('CBP')),
self._to_float(item.get('TSP')),
self._to_float(item.get('CSP')),
item['Time'], item['crawl_time']
))
self.connection.commit()
return item
代码与输出结果
-
代码连接: https://gitee.com/wujianliang9/2025-data-collection/tree/master/第三次作业/3
-
1. 终端运行
scrapy crawl boc_forex截图:
![image]()
-
2.
forex.db数据库内容截图 (使用check_db.py查看):

心得体会
1.次作业让我学到,定位静态表格其实很简单,最重要的是找到目标在第几个 。我发现使用 response.xpath('//table')[1] 这种简单粗暴的定位比用复杂的类名或 ID 更可靠。另外,提取内容时,用 string() 函数比用 text() 更强大,它能把标签内所有文本都抓出来,完美解决了内容被多层标签包裹的问题。
2.我第一次运行的时候,程序因为“文莱元”的汇率是空字符串 '' 而崩溃了。这教会我一个道理:Spider 抓回来的数据都是“脏”的,pipelines.py 才是做数据卫生的最后一关。我加了一个 _to_float 辅助函数,在数据存入前就把所有空值或非数字内容安全地转成 0.0,彻底解决了数据库插入失败的问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号