IK分词器 整合solr4.7 含同义词、切分词、停止词
转载请注明出处!
IK分词器如果配置成
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
本人测试切分词可以,但是同义词,扩展词库用不了,
网上查各种资料说IK分词器有个BUG,要自己把jar文件改一下,于是找到IK的源码,里面只有IKAnalyzer的源码,代码如下
package org.wltea.analyzer.lucene;
import java.io.Reader;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.Tokenizer;
/**
* IK分词器,Lucene Analyzer接口实现
* 兼容Lucene 4.0版本
*/
public final class IKAnalyzer extends Analyzer{
private boolean useSmart;
public boolean useSmart() {
return useSmart;
}
public void setUseSmart(boolean useSmart) {
this.useSmart = useSmart;
}
/**
* IK分词器Lucene Analyzer接口实现类
*
* 默认细粒度切分算法
*/
public IKAnalyzer(){
this(false);
}
/**
* IK分词器Lucene Analyzer接口实现类
*
* @param useSmart 当为true时,分词器进行智能切分
*/
public IKAnalyzer(boolean useSmart){
super();
this.useSmart = useSmart;
}
/**
* 重载Analyzer接口,构造分词组件
*/
@Override
protected TokenStreamComponents createComponents(String fieldName, final Reader in) {
Tokenizer _IKTokenizer = new IKTokenizer(in , this.useSmart());
return new TokenStreamComponents(_IKTokenizer);
}
}
自己加了一个IKAnalyzerSolrFactory,代码如下
package org.wltea.analyzer.lucene;
import java.io.Reader;
import java.util.Map;
import org.apache.lucene.analysis.Tokenizer;
import org.apache.lucene.analysis.util.TokenizerFactory;
import org.apache.lucene.util.AttributeSource.AttributeFactory;
public class IKAnalyzerSolrFactory extends TokenizerFactory{
private boolean useSmart;
public boolean useSmart() {
return useSmart;
}
public void setUseSmart(boolean useSmart) {
this.useSmart = useSmart;
}
public IKAnalyzerSolrFactory(Map<String,String> args) {
super(args);
assureMatchVersion();
this.setUseSmart(args.get("useSmart").toString().equals("true"));
}
@Override
public Tokenizer create(AttributeFactory factory, Reader input) {
Tokenizer _IKTokenizer = new IKTokenizer(input , this.useSmart);
return _IKTokenizer;
}
}
这样一来就能在配置文件中配置成IKAnalyzerSolrFactory 的列子
下面是具体的配置描述:
1。修改IK的jar文件,加入IKAnalyzerSolrFactory (如果不会改的自行下载 http://pan.baidu.com/s/1gfLOIL9)
2.修改solrconfig.xml文件,加入
<lib dir="/contrib/analysis-extras/lib" regex=".*\.jar" />
3.修改schema.xml文件,加入
<!--IK分词器-->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKAnalyzerSolrFactory" useSmart="true"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKAnalyzerSolrFactory" useSmart="true"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
</analyzer>
</fieldType>
4.在solr的webINFO 下的classes(没有新建)加入如下图,IK压缩文件中的部分文件,如图所示:
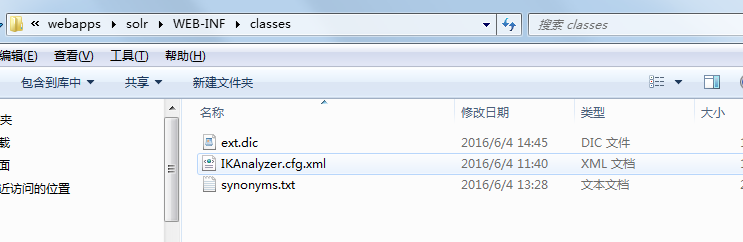
5.在ext.dic配置自定义词库,不需要切分词的词语配置在此,同义词写在synonyms.txt中即可。格式为: 通知,通告
注意每次改变词库或者同义词需要重启服务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号