

2025面试题汇总
一、K8S相关
1、k8s证书过期怎么处理
2、k8s如何滚动更新和回滚
3、pod中出现cpu飙升100%问题怎么解决
1)、快速诊断
# 查看节点资源使用情况 kubectl top nodes # 查看Pod资源使用情况 kubectl top pods -A # 查看特定Pod的详细信息 kubectl describe pod <pod-name> -n <namespace>
2)、深入分析
2.1、进入pod内部检查
kubectl exec -it <pod-name> -n <namespace> -- /bin/bash
2.2、在容器内运行诊断命令
# 查看进程CPU使用情况 top -H # 或使用htop(如果已安装) htop # 查看Java进程(如果是Java应用) jstack <pid> > thread_dump.log jmap -heap <pid>
3)、临时解决方案
3.1、扩缩容
# 水平扩展(如果适用) kubectl scale deployment <deployment-name> --replicas=<new-replicas> -n <namespace> # 调整资源限制(需要修改yaml并重新应用) kubectl edit deployment <deployment-name> -n <namespace>
3.2、重启pod
# 删除Pod让控制器重建 kubectl delete pod <pod-name> -n <namespace>
4)、长期解决方案
4.1、优化应用代码:
分析CPU使用高的原因,优化算法或逻辑
4.2、调整资源请求和限制:合理设置requests和limits
resources:
requests:
cpu: "500m"
memory: "512Mi"
limits:
cpu: "1000m"
memory: "1Gi"
4.3、实施HPA(水平Pod自动伸缩)
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: myapp-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
4.4、使用监控告警系统:配置Prometheus + Alertmanager监控CPU使用率
4、pod中出现oomKilled问题怎么解决
核心原因分析

4.1、直接触发条件
-
容器内存使用超过
spec.containers[].resources.limits.memory -
Linux内核OOM Killer强制终止进程(退出码137)
4.2、优化排查流程
4.2.1、快速诊断命令
# 1. 查看Pod状态(确认OOM事件)
kubectl get pod <pod-name> -o wide
kubectl describe pod <pod-name> | grep -A 10 "State"
# 2. 检查资源限制
kubectl get pod <pod-name> -o jsonpath='{.spec.containers[].resources}'
# 3. 查看节点内存压力
kubectl top node
kubectl describe node <node-name> | grep -A 10 "Allocated resources"
# 4. 获取历史内存监控数据(需Prometheus)
rate(container_memory_usage_bytes{pod="<pod-name>"}[5m])
4.2.2、内存泄漏排查(以Java为例)
# 1. 进入容器获取堆转储(需提前配置JVM参数) kubectl exec -it <pod-name> -- jmap -dump:live,format=b,file=/tmp/heap.hprof 1 # 2. 拷贝到本地分析 kubectl cp <namespace>/<pod-name>:/tmp/heap.hprof ./heap.hprof # 3. 使用MAT/Eclipse Memory Analyzer分析 # 重点检查: # - 占用最大的对象 # - 未关闭的资源(如Connection、Stream) # - 静态集合增长趋势
4.2.3、非jvm应用排查
# 1. 检查容器内进程内存 kubectl exec -it <pod-name> -- sh -c "ps aux --sort -rss | head -5" # 2. 分析Golang应用的pprof数据 kubectl exec -it <pod-name> -- curl http://localhost:6060/debug/pprof/heap > heap.pprof go tool pprof heap.pprof # 3. 检查Python内存使用 kubectl exec -it <pod-name> -- pip install memray kubectl exec -it <pod-name> -- python -m memray run -o out.bin app.py
4.3、解决方案与优化
4.3.1、紧急恢复措施
# 临时方案:增加内存限制(需重建Pod)
kubectl patch deployment <deploy-name> -p \
'{"spec":{"template":{"spec":{"containers":[{"name":"<container>","resources":{"limits":{"memory":"4Gi"}}}]}}}}'
# 快速扩容分担负载
kubectl scale deployment <deploy-name> --replicas=3
4.3.2、长期优化方案
jvm应用配置案例
# 确保堆内存小于容器限制(预留25%给堆外) ENV JAVA_OPTS="-XX:+UseContainerSupport -XX:MaxRAMPercentage=75.0 -XX:+HeapDumpOnOutOfMemoryError"
内存限制最佳实践
resources:
limits:
memory: "4Gi" # 必须设置
requests:
memory: "2Gi" # 建议=limits的50-70%
配置pod内存告警
# Prometheus规则示例
- alert: PodMemoryNearLimit
expr: (container_memory_working_set_bytes{container!="POD"} / container_spec_memory_limit_bytes) > 0.85
for: 5m
labels:
severity: warning
5、集群中pod中出现大量重启的问题怎么解决
常见原因分析
Pod 大量重启通常由以下几种原因导致: 1、应用崩溃:应用程序自身存在bug导致崩溃退出 2、资源不足:内存不足(OOMKilled)或CPU资源耗尽 3、健康检查失败:Liveness/Readiness探针配置不当 4、节点问题:节点资源耗尽或节点不健康 5、镜像问题:镜像损坏或启动命令错误 6、配置错误:错误的资源请求/限制或安全上下文配置
排查步骤
1)、查看pod的状态和事件
kubectl get pods -o wide kubectl describe pod <pod-name> kubectl get events --sort-by=.metadata.creationTimestamp
重点关注:
Restart Count Last State Reason Exit Code Events中的警告和错误信息
2)、检查pod日志
kubectl logs <pod-name> --previous # 查看前一个容器的日志 kubectl logs -f <pod-name> # 查看实时日志
3)、检查资源使用情况
kubectl top pods kubectl top nodes
4)、检查探针配置
kubectl get pod <pod-name> -o yaml | grep -A 10 "livenessProbe" kubectl get pod <pod-name> -o yaml | grep -A 10 "readinessProbe"
常见问题及解决方案
1.、OOMKilled (内存不足)
表现:Exit Code 137,Reason显示OOMKilled
解决方案:
-
增加Pod的内存限制
-
优化应用程序内存使用
-
添加适当的资源请求和限制
resources:
requests:
memory: "256Mi"
limits:
memory: "512Mi"
2、 应用崩溃 (Exit Code非0)
表现:Exit Code为非0值(如1, 127等)
解决方案:
-
检查应用日志定位崩溃原因
-
确保应用正确处理信号(SIGTERM)
-
添加适当的异常处理机制
-
考虑使用进程管理器(如supervisord)
3、探针配置不当
表现:频繁重启但应用实际正常运行
解决方案:
-
调整livenessProbe的initialDelaySeconds
-
放宽failureThreshold
-
确保探针检查的是应用真实健康状态
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 30
periodSeconds: 10
failureThreshold: 3
4.、节点资源不足
表现:多个Pod在不同节点上重启,节点资源使用率高
解决方案:
-
扩容集群节点
-
重新平衡Pod分布
-
优化资源请求和限制
二、数据库相关
1、sql中出现慢查询怎么优化
三、网络相关
1、http和https有什么区别
2、dns解析的完整链路
四、项目相关
1、使用K8S部署之后,如何使得部署效率提升60%,资源管理成本降低40%
2、支撑日均百万级请求,如何保证系统稳定性99.95%
1.1 架构设计原则:

核心策略:
-
全局负载均衡:多可用区部署,采用elb负载均衡,az1和az4的模式,分别部署到北京1和北京4两个region
-
弹性伸缩:HPA+VPA组合应对流量波动
-
服务降级:非核心功能可快速关闭
1.2 资源规划与调度优化,对pod设置limit和requests:
# Pod资源模板示例(必须设置limits)
resources:
limits:
cpu: "2"
memory: "4Gi"
requests:
cpu: "500m"
memory: "2Gi"
# 节点预留资源(防止系统进程饥饿)
kubelet:
--system-reserved=cpu=1,memory=2Gi
--kube-reserved=cpu=500m,memory=1Gi
1.3 Pod 水平自动扩缩(HPA):基于 CPU、内存或自定义指标自动调整副本数:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-app
minReplicas: 3 # 至少3个副本保证高可用
maxReplicas: 30
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70 # CPU利用率达70%时扩容
1.4 Pod 亲和性引入:避免调度到同一节点:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
app: my-app
topologyKey: "kubernetes.io/hostname" # 分散在不同Node
1.5 引入健康检查和自愈能力:
探针配置:合理设置 livenessProbe 和 readinessProbe
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 30 # 启动后30秒开始检查
periodSeconds: 10 # 每10秒检查一次
failureThreshold: 3 # 连续3次失败才重启
1.6、 监控、告警与应急响应
1.6.1、全方位监控体系
1.6.2 告警阈值设定
1.6.3 自动化应急响应
1.7 变更管理

-
每次变更影响范围<5%
-
回滚阈值(任一指标):
-
错误率>1%
-
延迟P99>1s
-
Linux内核OOM Killer强制终止进程(退出码137)
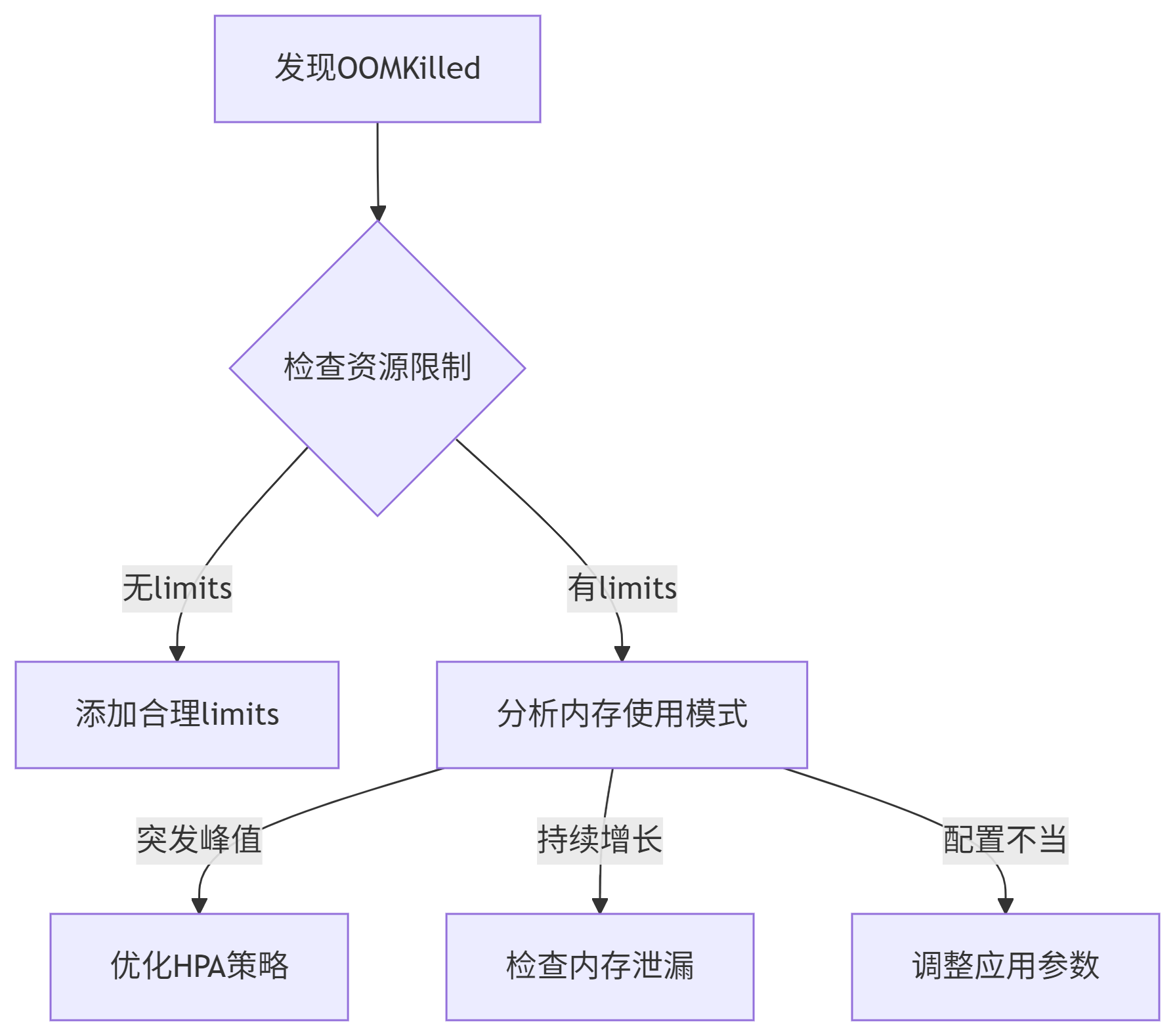
1.2 典型场景分类场景类型特征示例突发负载短期内存飙升大流量请求导致缓存膨胀内存泄漏内存持续增长不释放未关闭的数据库连接池配置错误资源限制不合理JVM堆大于容器内存限制外部依赖依赖服务异常递归调用导致栈溢出二、系统化排查流程图表代码下载无limits
有limits
突发峰值
持续增长
配置不当
发现OOMKilled
检查资源限制
添加合理limits
分析内存使用模式
优化HPA策略
检查内存泄漏
调整应用参数
2.1 快速诊断命令bash复制下载# 1. 查看Pod状态(确认OOM事件)kubectl get pod <pod-name> -o widekubectl describe pod <pod-name> | grep -A 10 "State"
# 2. 检查资源限制kubectl get pod <pod-name> -o jsonpath='{.spec.containers[].resources}'
# 3. 查看节点内存压力kubectl top nodekubectl describe node <node-name> | grep -A 10 "Allocated resources"
# 4. 获取历史内存监控数据(需Prometheus)rate(container_memory_usage_bytes{pod="<pod-name>"}[5m])2.2 内存泄漏排查(以Java为例)bash复制下载# 1. 进入容器获取堆转储(需提前配置JVM参数)kubectl exec -it <pod-name> -- jmap -dump:live,format=b,file=/tmp/heap.hprof 1
# 2. 拷贝到本地分析kubectl cp <namespace>/<pod-name>:/tmp/heap.hprof ./heap.hprof
# 3. 使用MAT/Eclipse Memory Analyzer分析# 重点检查:# - 占用最大的对象# - 未关闭的资源(如Connection、Stream)# - 静态集合增长趋势2.3 非JVM应用排查bash复制下载# 1. 检查容器内进程内存kubectl exec -it <pod-name> -- sh -c "ps aux --sort -rss | head -5"
# 2. 分析Golang应用的pprof数据kubectl exec -it <pod-name> -- curl http://localhost:6060/debug/pprof/heap > heap.pprofgo tool pprof heap.pprof
# 3. 检查Python内存使用kubectl exec -it <pod-name> -- pip install memraykubectl exec -it <pod-name> -- python -m memray run -o out.bin app.py三、解决方案与优化3.1 紧急恢复措施bash复制下载# 临时方案:增加内存限制(需重建Pod)kubectl patch deployment <deploy-name> -p \'{"spec":{"template":{"spec":{"containers":[{"name":"<container>","resources":{"limits":{"memory":"4Gi"}}}]}}}}'
# 快速扩容分担负载kubectl scale deployment <deploy-name> --replicas=33.2 长期优化方案JVM应用配置示例:
dockerfile复制下载# 确保堆内存小于容器限制(预留25%给堆外)ENV JAVA_OPTS="-XX:+UseContainerSupport -XX:MaxRAMPercentage=75.0 -XX:+HeapDumpOnOutOfMemoryError"内存限制最佳实践:
yaml复制下载resources: limits: memory: "4Gi" # 必须设置 requests: memory: "2Gi" # 建议=limits的50-70%Pod内存监控告警:
yaml复制下载# Prometheus规则示例- alert: PodMemoryNearLimit expr: (container_memory_working_set_bytes{container!="POD"} / container_spec_memory_limit_bytes) > 0.85 for: 5m labels: severity: warning3.3 应用层优化缓存控制:限制本地缓存大小(Guava/Caffeine)
java复制下载Cache<String, Object> cache = Caffeine.newBuilder() .maximumSize(10_000) .expireAfterWrite(10, TimeUnit.MINUTES) .build();流式处理:避免全量加载数据
python复制下载# 错误方式:data = pd.read_csv("huge_file.csv")# 正确方式:for chunk in pd.read_csv("huge_file.csv", chunksize=10_000): process(chunk)四、典型案例解析案例1:JVM堆外内存泄漏现象:
容器内存增长但堆使用稳定
kubectl exec -- cat /proc/<pid>/smaps 显示Native内存占用高
解决方案:
使用Native Memory Tracking排查:
bash复制下载kubectl exec <pod-name> -- jcmd 1 VM.native_memory summary常见原因:未释放的JNI调用、DirectByteBuffer堆积
案例2:PHP-FPM进程膨胀现象:
每个请求内存小幅增加,最终OOM
kubectl exec -- ps auxf 显示数百个PHP-FPM子进程
优化方案:
ini复制下载; php-fpm.confpm = dynamicpm.max_children = 50 # 根据limits.memory调整pm.start_servers = 5pm.min_spare_servers = 2pm.max_spare_servers = 10五、预防体系搭建混沌测试:定期模拟内存压力
bash复制下载# 使用stress-ng测试kubectl run mem-test --image=polinux/stress-ng -- \ stress-ng --vm 2 --vm-bytes 2G --vm-keepCI/CD检查:在Pipeline中验证资源限制
yaml复制下载# GitLab CI示例lint_k8s: image: k8s-validator script: - kubeval --strict --ignore-missing-schemas deployment.yaml - grep "memory: [0-9]Gi" deployment.yaml || exit 1策略治理:通过OPA强制要求资源限制
rego复制下载# OPA策略示例deny[msg] { container := input.spec.containers[_] not container.resources.limits.memory msg := sprintf("Container %v missing memory limits", [container.name])}通过以上方法,可系统解决和预防OOMKilled问题,关键点在于:
资源限制必须合理配置(limits ≈ 应用峰值内存 × 1.2)
应用需适配容器化环境(特别是JVM/GLIBC等)
建立内存监控-告警-优化闭环
开启新对话

 浙公网安备 33010602011771号
浙公网安备 33010602011771号