pandas常用命令-学习整理
一、数据导入导出
1、设置最大10行:pd.options.display.max_rows = 10
2、以字典的格式生成数据框:pd.DataFrame({'var1':1,'var2':[1,2,3,],'var3':['a','b','c'],'var4':'zzzz','var5':'900})
3、以列表的格式生成数据框:pd.DataFrame(data=[['a','b','c'],['A','B','C']],columns=['var1','var2','var3'])
4、读取文本格式数据文件:
4.1 读取csv文件数据:pd.read_csv('xx.csv',encoding='utf-8',hearder=0,names=[1,2,3,4,5,6,7,8],usecols=[2,4,7])
参数解释:
filepath_or_buffer : 路径 URL 可以是http, ftp, s3, 和 file.
sep: 指定分割符,默认是’,’C引擎不能自动检测分隔符,但Python解析引擎可以
delimiter: 同sep
delimiter_whitespace: True or False 默认False, 用空格作为分隔符等价于spe=’\s+’如果该参数被调用,则delimite不会起作用
header: 指定第几行作为列名(忽略注解行),如果没有指定列名,默认header=0;
names:指定列名,如果文件中不包含header的行,应该显性表示header=None
index_col: 默认为None 用列名作为DataFrame的行标签。如果读取某文件,该文件每行末尾都有带分隔符,考虑使用index_col=False使panadas不用第一列作为行的名称。
usecols: 默认None 可以使用列序列也可以使用列名,如 [0, 1, 2] or [‘foo’, ‘bar’, ‘baz’],选取的列
as_recarray:默认False , 将读入的数据按照numpy array的方式存储,0.19.0版本后使用 pd.read_csv(…).to_records()。 注意:这种方式读入的na数据不是显示na,而是给以个莫名奇妙的值
squeeze: 默认为False, True的情况下返回的类型为Series
prefix:默认为none, 当header =None 或者没有header的时候有效,例如’x’ 列名效果 X0, X1, …
mangle_dupe_cols :默认为True,重复的列将被指定为’X.0’…’X.N’,而不是’X’…’X’。如果传入False,当列中存在重复名称,则会导致数据被覆盖。
dtype: E.g. {‘a’: np.float64, ‘b’: np.int32} 指定数据类型
engine: {‘c’, ‘python’}, optional 选择读取的引擎目前来说C更快,但是Python的引擎有更多选择的操作
skipinitialspace: 忽略分隔符后的空格,默认false,
skiprows: list-like or integer or callable, default None 忽略某几行或者从开始算起的几行
skipfooter: 从底端算起的几行,不支持C引擎
nrows: int 读取的行数
na_values: 默认None NaN包含哪些情况, ‘#N/A’, ‘#N/A N/A’, ‘#NA’, ‘-1.#IND’, ‘-1.#QNAN’, ‘-NaN’, ‘-nan’, ‘1.#IND’, ‘1.#QNAN’, ‘N/A’, ‘NA’, ‘NULL’, ‘NaN’, ‘n/a’, ‘nan’, ‘null’. 都表现为NAN
keep_default_na: 如果na_values被定义,keep_default_na为False那么默认的NAN会被改写。 默认为True
na_filter: 默认为True, 针对没有NA的文件,使用na_filter=false能够提高读取效率
skip_blank_lines 默认为True,跳过blank lines 而且不是定义为NAN
thousands 千分位符号,默认‘,’
decimal 小数点符号,默认‘.’
encoding: 编码方式
memory_map如果为filepath_or_buffer提供了文件路径,则将文件对象直接映射到内存上,并直接从那里访问数据。使用此选项可以提高性能,因为不再有任何I / O开销。
low_memory 默认为True 在块内部处理文件,导致分析时内存使用量降低,但可能数据类型混乱。要确保没有混合类型设置为False,或者使用dtype参数指定类型。请注意,不管怎样,整个文件都读入单个DataFrame中,请使用chunksize或iterator参数以块形式返回数据。 (仅在C语法分析器中有效)
4.2 读取excel文件数据:pd.read_excel("111.xlsx",sheet_name=0)
参数解释:
io :excel 路径;
sheetname:默认是sheetname为0,返回多表使用sheetname=[0,1],若sheetname=None是返回全表 。注意:int/string返回的是dataframe,而none和list返回的是dict of dataframe。
header :指定作为列名的行,默认0,即取第一行,数据为列名行以下的数据;若数据不含列名,则设定 header=None;
skiprows:省略指定行数的数据
skip_footer:省略从尾部数的行数据
index_col :指定列为索引列,也可以使用 u’string’
names:指定列的名字,传入一个list数据
4.3 读取sas文件数据:pd.read_sas("air.sas7bdat")
4.4 读取数据库数据:
from sqlalchemy import create_engine
eng = create_engine('mysql+pymysql://root:123123@47.93.148.185/lianxi_data?charset=utf8')
df1=pd.read_sql("cp",con=eng,index_col='id')
参数解释:
sql:SQL命令字符串
con:连接sql数据库的engine,一般可以用SQLalchemy或者pymysql之类的包建立
index_col: 选择某一列作为index
coerce_float:非常有用,将数字形式的字符串直接以float型读入
parse_dates:将某一列日期型字符串转换为datetime型数据,与pd.to_datetime函数功能类似。可以直接提供需要转换的列名以默认的日期形式转换,也可以用字典的格式提供列名和转换的日期格式,比如{column_name: format string}(format string:"%Y:%m:%H:%M:%S")。
columns:要选取的列。一般没啥用,因为在sql命令里面一般就指定要选择的列了
chunksize:如果提供了一个整数值,那么就会返回一个generator,每次输出的行数就是提供的值的大小。
5、保存数据
5.1 保存为csv文件:df.to_csv("111.txt")
参数解释:
filepath_or_buffer:要保存的文件路径
sep=',, :列分隔符
columns :需要导出的变量列表
header = True :指定导出数据的新变量名,可直接提供
listindex =True :是否导出索引
mode ='w' : Python写模式,读写方式:I, r+ , w, w+ , a , a+
encoding ='utf-8, :默认导出的文件编码格式)
5.2 保存为excel文件:df.to_excel("111.xlsx")
参数解释:
filepath_orbuffer:要读入的文件路径
sheet_name = 'Sheet1' :要保存的表单名称
5.3 保存到sql数据库中:df.to_sql(name="wuwu",con=eng,if_exists='append',index=False)
参数解释:
name :将要存储数据的表名称
con : SQLAlchemy引擎/DBAP12连接引擎名称
if_exists:( 'fail', 'replace', append), default fail
fail :不做任何处理(不插入新数据)
Dreplace :删除原表并重建新表
append :在原表后插入新数据
index =True :是否导出索引
二、变量列操作
1、查看数据框的大小:df.shape
2、查看数据框的基本信息:df.info()
3、查看数据框前10条记录:df.head(10)
4、查看数据框后10条记录:df.tail(10)
5、查看列表的变量名:df.columns
6、修改列名,inplace表示是否替换原数据框:df.rename(columns={'title':'title1','content':'content1'},inplace=True)
7、筛选变量列:df[ ['content','title'] ] 或者 df.iloc[:,0:2]
8、删除变量列:df.drop(columns={'content1'},inplace=True)
9、查看数据框的数据类型:df.dtypes
10、转换数据框数据类型:df.astype('str',errors='ignore')
11、转换某一列数据类型:df.id.astype('int')
三、索引操作
1、建立数据框的时候建立索引:pd.DataFrame({'var1':1,'var2':'1,2,3','var3':'qwe','var4':'asd'},index=['a','b','c','d'])
2、指定列为索引:df.set_index(keys='var2',append=True,inplace=True)
参数解释:df.set_index(
keys :被指定为索引的列名,复合索引用list格式提供
drop=True :建立索引后是否删除该列
append =False :是否在原索引基础上添加索引,默认是直接替换原索引
vinplace =False :是否直接修改原数据框)
3、将索引还原为变量列:df.reset_index(level=['var2'],inplace=True)
参数解释:df.reset_index(
drop = False:是否将索引直接删除,而不是还原为变量列
inplace = False :是否直接修改原数据框
level= None :对于多重索引,确定转换哪个级别为变量,需要之前做过索引的)
4、修改索引名:df.index.names=['id','var5']
5、修改索引值:df.index=[[1,2,4,5],[10,9,8,7]]
6、删除设置的索引:df.reset_index(inplace=True,drop=True)
7、索引排序:df.sort_index(level='id',ascending=False,inplace=True)
参数说明:df.sort index(
level : (多重索引时)指定用于排序的级别顺序号/名称
ascending = True :是否为升序排列,多列时以表形式提供
inplace = False:
naposition = 'last' :缺失值的排列顺序, first/last)
8、强行更新索引:df.reindex(['a','b','c','d','r'],method='ffill')
df.reindex(['a','b','c','d','r'],fill_value="不知道")
参数说明:df.reindex(
labels :类数组结构的数值,将按此数值重建索引,非必需
axis :针对哪个轴进行重建('index', 'columns') or number (0, 1).
copy = True :建立新对象而不是直接更改原df/series
level :考虑被重建的索引级别
缺失数据的处理方式
method :针对已经排序过的索引,确定数据单元格无数据时的填充方法,非必需
pad / ffill:用前面的有效数值填充
backfill / bfill:用后面的有效数值填充
nearest:使用最接近的数值进行填充
Fill value =np.NaN :将缺失值用什么数值替代
limit =None :向前/向后填充时的最大步长
四、行操作
1、索引排序:df.sort_index(level='id',ascending=False,inplace=True)
2、列值排序:df.sort_values(by='var2',ascending=False,inplace=True)
3、按照绝对位置进行行筛选:
1)不包括右侧边界值:df.iloc[0:1]
2)列表的形式,包含第0、1行:df.iloc[[0,1]]
3)筛选列:df.iloc[:,0:2]
4)按照索引值进行筛选,乱序则不可用:df.loc['3':'1',['var2','var3']]
5)筛选特定序列第三、四列:df1.loc[[('3'),('4')]]
6)针对多重索引的行筛选(不常用):df1.xs('1',drop_level=False)
4、条件筛选(var1列中大于2的数列):df[df.var1>2]
5、列表筛选,isin的结果是bool类型数据(找出var2列有值为1和3的行):df.var2.isin([1,3])
6、索引的列表筛选,isin的结果是bool类型数据:df.index.isin(['1','2'])
7、类sql语句筛选(id列大于等于3,var1列等于1的行):df.query("id>='3' and var1==1 ")
参数说明:df.query(
expr:类sQL语句表达式可以使用前缀,.引用环境变量等号为==,而不是=
注意:目前还不支持like语句
inplace = False :是否直接替换原数据框)
8、删除空值行:df.dropna(axis=0, how='any', inplace=True)
参数说明:
axis:0-行操作(默认),1-列操作
how:any-只要有空值就删除(默认),all-全部为空值才删除
inplace:False-返回新的数据集(默认),True-在愿数据集上操作)
9、删除行:df.drop(label=var1, axis=0, inplace=True)
参数说明:
labels 就是要删除的行列的名字,用列表给定
axis 默认为0,指删除行,因此删除columns时要指定axis=1;
index 直接指定要删除的行
columns 直接指定要删除的列
inplace=False,默认该删除操作不改变原数据,而是返回一个执行删除操作后的新dataframe;
五、变量操作
1、添加新列:df['var5']=[10,9,8,7]
2、列的四则运算:df.var5*df.var2
3、单多个列,求平方根:numpy.sqrt(df.var6)
df.var5.apply(math.sqrt)
参数说明:df.apply(
func:希望对行/列执行的函数表达式
axis =o/'index':针对每列进行计算;l/'columns :针对每行进行计算
4、多个列,求平方根,这个会形成新的表:df[['var1','var2']].applymap(math.sqrt)
5、指定插入列:df.insert(1,column="var11",value=['a','b','c','d'])
参数说明:df.insert(
1oc :插入位置的索引值, o <= loc <= len(columns)
colunn :插入的新列名称
value : Series或者类数组结构的变量值
allow_duplicates =False :是否允许新列重名)
6、查找变量:df[df.var1.isin(['1'])]
7、数值替换:
单值替换:df.loc[1,'var11']='不'
df.loc[df[df.var6<20].index,['var1','var11']]='hate'
df.loc[df.query("var2 ==4").index,['var1','var11']]='you'
df.var1.replace(1,"love",inplace = True)
多值替换-列表:df.var11.replace(['a','c'],['我','知'],inplace = True)
多值替换-字典:df.var11.replace({'我':'a','知':'c'},inplace = True)
参数说明:df.replace(
to_replace = None :将被替换的原数值,所有严格匹配的数值将被用value替换可以是str/regex/list/dict/Series/numeric/None
value =None :希望填充的新数值
inplace = False)
8、生成哑变量:pd.get_dummies(df1.var2,prefix='pre')
pd.get_dummies(df1,prefix='pre',columns=['var2'])
参数说明:pd.get dummies(
data :希望转换的数据框/变量列
prefix = None :哑变量名称前缀
prefix_sep ='.:前缀和序号之间的连接字符,设定有prefix或列名时生效
dummy_na = False :是否为NaNs专门设定一个哑变量列
columns =None :希望转换的原始列名,如果不设定,则转换所有符合条件的列
drop-first =False :是否返回k-1个哑变量,而不是k个哑变量)#返回值为数据框)
9、数值分段,相当于多一列标签:df['cls']=pd.cut(df.var2,bins=[1,3,6],right=False)
参数说明:pd.cut(
x:希望进行分段的变量列名称
bins :具体的分段设定
int :被等距等分的段数
sequence of scalars :具体的每一个分段起点,必须包括最值,可不等距
right =True :每段是否包括右侧界值
labels -None :为每个分段提供自定义标签
include_lowest = False :第一段是否包括最左侧界值,需要和right參数配合)
六、数据拆分
1、按照var1列进行分组:dfg = df.groupby(['var1'])
参数说明:df.groupby(
by:用于分组的变量名/函数
axis =o:对行作拆分
level = None :相应的轴存在多重索引时,指定用于分组的级别
as_index=True :在结果中将组标签作为索引
sort = True :结果是否按照分组关键字进行排序)
2、查看分组的详细信息:dfg.describe();筛选其中一列并输出详细信息:dfg['var1'].describe()
参数说明:df.describe(
percentiles :需要输出的百分位数,列表格式提供,如[.25, .5, .75]
include = 'None' :要求纳入分析的变量类型白名单
None (default) :只纳入数值变量列
A list-like of dtypes[] :列表格式提供希望纳入的类型
"all' :全部纳入
exclude :要求剔除出分析的变量类型黑名单,选项同上)
3、分组的平均数值:dfg.mean()
4、显示var1中值为a的数据:dfg.get_group('a')
5、分组汇总:dfg.agg('sum') == df.var1.agg(numpy.sum)
参数说明:df.agg(
count() Number of non-null observations 总个数
size () group sizes 组大小
sum() Sum of values 值总和
mean () Mean of values 值的均值
median() Arithmetic median of values 算术中位数
min() Minimum 最小值
max() Maximum 最大值
std() Unbiased standard deviation 无偏标准偏差
var() Unbiased variance 均方差
skew () Unbiased skewness (3rd moment) 无偏偏态
kurt() Unbiased kurtosis (4th moment) 无偏峰度
quantile() Sample quantile (value at 8) 样本分位数
apply() Generic apply 通用应用
cov() Unbiased covariance (binary) 无偏协方差
corre() correlation (binary))
6、分类变量的频数统计(即统计行值相同个数):pd.value_counts(df.var1)
参数说明:pd.value_counts(
normalize = False :是否返回构成比而不是原始频数
sort =True :是否按照频数排序(否则按照原始顺序排列)
ascending = False :是否升序排列
dropna =True:结果中是否包括NaN)
6、交叉表,前面的为行名,后面的为列名:pd.crosstab(df1.var2,df1.var5)
或者:df.pivot_table(index=['var1','var2'],columns='var5',values='var4',aggfunc=sum)
参数说明:df.pivot_table(
行列设定
index / columns :行变量/列变量,多个时以list形式提供
单元格设定
values :在单元格中需要汇总的变量列,可不写
aggfunc =numpy.mean:相应的汇总函数
汇总设定
normalize =0 :求百分比
margins =False :是否加入行列汇总
margins_narde ='All' :汇总行/列的名称
缺失值处理
fill-value =None :用于替换缺失值的数值
dropna = True:
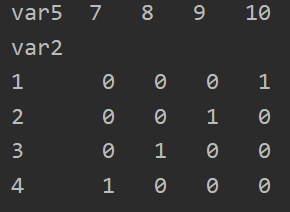
7、unstack() 方法可以快速将一个多级索引的 Series 转化为普通索引的 DataFrame(复杂),stack则可以实现将列转化为索引(简单):
参数说明:df.stack(
level=-1:需要处理的索引级别,默认为全部, int/string/list
dropna = True :是否删除为缺失值的行)
8、长型和宽型数据的互转:df.T
9、多数据的纵向合并:df.append([df2,df2[:1],df2[3:]],ignore_index=True)
参数说明:df.append(
other :希望添加的DF/series/字典/上述对象的列表使用列表方式,就可以实现一次合并多个新对象
ignore_index = False :添加时是否忽略索引
verify_integrity = False :是否检查索引值的唯一性,有重复时报错)
10、多数据的横向合并(索引对应列名的合并):pd.merge(df1s,df3s,left_index=True,right_on='var5')
参数说明:pd.merge(
left :需要合并的左侧DF
right :需要合并的右侧DF
how ='inner' :具体的连接类型('left', 'right', 'outer', 'inner')
两个DF的连接方式
on :用于连接两个DF的关键变量(多个时为列表) ,必须在两侧都出现
left-on :左侧DF用于连接的关键变量(多个时为列表)
right_on :右侧DF用于连接的关键变量(多个时为列表)
left_index = False :是否将左侧DF的索引用于连接
right_index =False :是否将右侧DF的索引用于连接
其他附加设定
sort = False :是否在合并前按照关键变量排序(会影响合并后的案例顺序)
suffixes :重名变量的处理方式,提供长度为2的列表元素,分别作为后缀suffixes=('x', 'y')
copy = True
indicator = False :在结果DF中增加'-merge'列,用于记录数据来源,也可以直接提供相应的变量列名
categorical类型,取值: 'left_only', 'right_only', 'both'
validate =None :核查合并类型是否为所指定的情况
'one_to_one' or '1:1'
'1one to many' or '1:m'
'many_to_one' or 'm:1'
'many tomany' or 'm:m'(实际上不做检查)
11、其他合并命令;纵向:pd.concat([df1s,df3s])
需要根据索引拼接,横向:pd.concat([df1s,df3s],axis=1)
七、数据清洗
1、数据框级别判断是否为空数据isna,判断为有数据notna:bj.isna() bj.notna()
2、可用numpy中的nan赋值为空值:bj.Year=np.nan
3、行列级别检查缺失值:bj.any(0)
参数说明:df.any(
axis: {index (0), columns (1)}
skipna = True :检查时是否忽略缺失值
level =None :多重索引时指定具体的级别)
4、缺失值填充:bj.fillna('未知',limit=100)
参数说明:df.fillna(
value :用于填充缺失值的数值
也可以提供dict/series/DataFrame以进一步指明哪些索引1/列会被替换
不能使用list
method = None : 默认值 None ; 在Series中使用方法填充空白
(‘backfill’, ‘bfill’向前填充,‘pad’, ‘ffill’向后填充)
limit= None :指定了method后设定具体的最大填充步长, >此步长不能填充
axis: {0 or 'index', 1 or 'columns'}
inplace = False)
5、缺失值的删除:bj.dropna(axis=0,how='all')
参数说明:df.dropna(
axis =o: {0 or 'index', 1 or 'columns'}
how = any : ('any', 'all'}
any :任何一个为NA就删除
all :所有的都是NA才删除
thresh =None :删除的数量國值, int
subset :希望在处理中包括的行/列子集
inplace = False)
6、行查重dup为bool类型:bj['dup']=bj.duplicated(['Year'])
索引查重:bj.index.duplicated()
7、删除重复的行,keep='first';(只删除第一个),'last'(只删除最后一个),'Flase'(有重复的全部都删除):bj.drop_duplicates(['Year'],keep=False)
8、利用查重标识直接删除:bj[~bj.duplicated(['Year'])]
八、日期时间
1、单列时间转换:pd.to_datetime(df['var1'],errors='ignore',format='%Y-%m-%d %H:%M')
多列时间转换:pd.to_datetime(bj[['Year','Month','Day','Hour']],errors='ignore',format='%Y-%m-%d %H:%M')
参数说明:pd.to_datetime(
arg:需要转换为Timestamp类的数值integer, float, string, datetime, list, tuple, 1-d array, series
errors ='raise': ('ignore', 'raise', 'coerce'}•
raise',抛出错误'
coerce',设定为NaT
ignore',返回原值e
then invalid parsing will return the input短日期的解释方式:类似"10/11/12"这样的数据如何解释
dayfirst ='False' :数值是否day在前
yearfirst ='False' :数值是否year在前,该设定优先
box =True :是否返回为DatetimeIndex, False时回ndarray数
format =None :需要转换的字符串格式设定
2、普通建立时间索引:bj.set_index(pd.to_datetime(bj['Date ']))
建立时间索引:pd.date_range(end='2020-12-31',periods=15,freq="M")
参数说明:pd.date_range(
start /end =None:日期时间范围的起点/终点,均为类日期时间格式的字符串1数据
periods = None :准备生成的总记录数
freg ='D' :生成记录时的时间周期,可以使用字母和数值数的组合,如'5H
name = None :生成的DatetimeIndex对象的名称)
3、按照时间的查找数据:bj["2008-11-1":'2008-11-5']
4、取索引时间的一部分:bj["2008-11-1":'2008-11-5 9:00']
5、按照三天为一个单位做一个组合的均值:bj1.resample('3D').mean()
6、序列数值的平移(总行不变在前面添加3个空白行):bj.shift(3)
参数说明:df.shif(
periods =1 :希望移动的周期数
freg :时间频度字符串
axis =o)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号