前端面试题(综合部分)
webpack:
一、对webpack的理解
1.WebPack 是一个模块打包工具,你可以使用WebPack管理你的模块依赖,并编绎输出模块们所需的静态文件。它能够很好地管理、打包Web开发中所用到的HTML、JavaScript、CSS以及各种静态文件(图片、字体等),让开发过程更加高效。对于不同类型的资源,webpack有对应的模块加载器。webpack模块打包器会分析模块间的依赖关系,最后 生成了优化且合并后的静态资源。
2.webpack的两大特色:代码分割和模块处理
二、热重启
1.热重启原理:eventsource sse,一旦服务器资源有更新,能够及时通知到客户端,从而实时的反馈到用户界面上。本质上是一个http,通过response流实时推送服务器信息到客户端。链接断开后会持续出发重连。_webpack_hmr:每隔10s推送一条在消息到浏览器
2.实现:
client:创建new EventSource (“/message”),
Server:需要返回类型为text/event-stream的响应头,发送数据以data开头,\n\n结尾;
webpack-dev-server是一个机遇express的web server,监听8080,server内部调用webpack,这样的好处是提供了热加载和热替换的功能;
webpack-hot-middleware和webpack-dev-middleware
3.EventSource和websocket的区别:
(1).eventSource本质仍然是http,仅提供服务器端到浏览器端的单向文本传输,不需要心跳链接,链接断开回持续重发链接;
(2).websocket是基于TCP的协议,提供双向数据传输,支持二进制,需要心跳链接,断开链接不会重链;
(3).EventSource更简洁轻量,WebSocket支持行更好(IE10+)。后者功能更强大一点。
三、webpack特性
所有的资源都可以当作一个模块来处理,热替换(不用刷新整个页面),代码拆分和按需加载,拥有灵活的可扩展plugin库和loader模块加载器;
四、如何使用常用插件?
1.HtmlWebpackPlugin的用法及多入口文件配置:作用是依据一个html模版,生成html文件,并将打包后的资源文件自动引入(title:;template:’‘,fileName:‘’,inject:js插入位置等);
2.webpack.optimize.commonsChunkPlugin:抽取公共模块,减小打包体积,例如:vue的源码、jquery的源码等:entry:vendor:[‘react’];plugin:new web pack.optimize.CommonsChunkPlugin({name:’vendor’})
3.loader:
css:解析css代码,在js中通过require方式引入css文件
style:通过style的方式引入 {test:/\.css$/,loader:’style-loader!css-loader’},二者组合能将css代码写入到js文件中
4.将样式抽取成单独的文件,extract-text-webpack-plugin(filename:‘’):
5.url-loader:实现图片文字等的打包,有一个option选项limit属性表示,少于这个限制,则打包成base64,大于的话,就使用file-loader去打包成图片;
6.postcss:实现浏览器兼容,autoprefixer
7.babel:转es
8.hot module replacement:修改代码后,自动刷新实时预览修改后的效果。devServer:{hot:true,inline:true(实时刷新)}
9.ugliifyJsPlugin:压缩js代码
五、webpack与gulp的比较
1.gulp是工具链,可以配合各种插件做js、css压缩,less编译等;而webpack能把项目中的各种js、css文件等打包合并成一个或者多个文件,主要用于模块化方案,
2.侧重点不同,gulp侧重于整个过程的控制管理(像是流水线),通过配置不同的task,构建整个前端开发流程;webpack则侧重于模块打包;并且gulp的打包功能是通过安装gulp-webpack来实现的
3.webpack能够按照模块的依赖关系构建文件组织结构;
六、webpack多页面打包
web-webpack-plugin里的AutoWebPlugin可以方便的解决这些问题。
module.exports = {
plugins: [
// 所有页面的入口目录
new AutoWebPlugin('./src/'),
]
};
AutoWebPlugin会把./src/目录下所有每个文件夹作为一个单页页面的入口,自动为所有的页面入口配置一个WebPlugin输出对应的html。要新增一个页面就在./src/下新建一个文件夹包含这个单页应用所依赖的代码,AutoWebPlugin自动生成一个名叫文件夹名称的html文件。
七、webpack打包原理
核心思想:
一切皆模块:
正如js文件可以是一个“模块(module)”一样,其他的(如css、image或html)文件也可视作模 块。因此,你可以require(‘myJSfile.js’)亦可以require(‘myCSSfile.css’)。这意味着我们可以将事物(业务)分割成更小的易于管理的片段,从而达到重复利用等的目的。
按需加载:
传统的模块打包工具(module bundlers)最终将所有的模块编译生成一个庞大的bundle.js文件。但是在真实的app里边,“bundle.js”文件可能有10M到15M之大可能会导致应用一直处于加载中状态。因此Webpack使用许多特性来分割代码然后生成多个“bundle”文件,而且异步加载部分代码以实现按需加载。
文件管理
每个文件都是一个资源,可以用require/import导入js
每个入口文件会把自己所依赖(即require)的资源全部打包在一起,一个资源多次引用的话,只会打包一份
对于多个入口的情况,其实就是分别独立的执行单个入口情况,每个入口文件不相干(可用CommonsChunkPlugin优化)
打包原理
把所有依赖打包成一个bundle.js文件,通过代码分割成单元片段并按需加载。
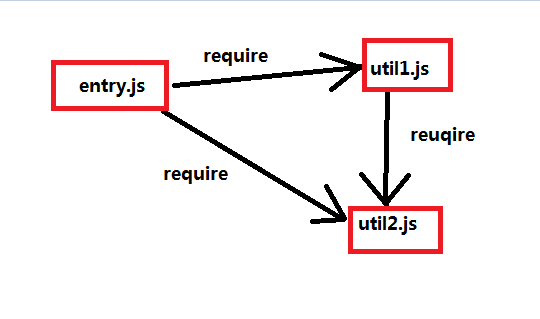
如图,entry.js是入口文件,调用了util1.js和util2.js,而util1.js又调用了util2.js。
打包后的bundle.js例子
/******/ ([ /* 0 */ //模块id /***/ function(module, exports, __webpack_require__) { __webpack_require__(1); //require资源文件id __webpack_require__(2); /***/ }, /* 1 */ /***/ function(module, exports, __webpack_require__) { //util1.js文件 __webpack_require__(2); var util1=1; exports.util1=util1; /***/ }, /* 2 */ /***/ function(module, exports) { //util2.js文件 var util2=1; exports.util2=util2; /***/ } ... ... /******/ ]);
1、bundle.js是以模块 id 为记号,通过函数把各个文件依赖封装达到分割效果,如上代码 id 为 0 表示 entry 模块需要的依赖, 1 表示 util1模块需要的依赖
2、require资源文件 id 表示该文件需要加载的各个模块,如上代码_webpack_require__(1) 表示 util1.js 模块,__webpack_require__(2) 表示 util2.js 模块
3、exports.util1=util1 模块化的体现,输出该模块
八、webpack构建流程
从启动webpack构建到输出结果经历了一系列过程,它们是:
1、解析webpack配置参数,合并从shell传入和webpack.config.js文件里配置的参数,生产最后的配置结果。
2、注册所有配置的插件,好让插件监听webpack构建生命周期的事件节点,以做出对应的反应。
3、从配置的entry入口文件开始解析文件构建AST语法树,找出每个文件所依赖的文件,递归下去。
4、在解析文件递归的过程中根据文件类型和loader配置找出合适的loader用来对文件进行转换。
5、递归完后得到每个文件的最终结果,根据entry配置生成代码块chunk。
6、输出所有chunk到文件系统。
需要注意的是,在构建生命周期中有一系列插件在合适的时机做了合适的事情,比如UglifyJsPlugin会在loader转换递归完后对结果再使用UglifyJs压缩覆盖之前的结果。
九、webpack构建优化
方案一、合理配置 CommonsChunkPlugin
webpack的资源入口通常是以entry为单元进行编译提取,那么当多entry共存的时候,CommonsChunkPlugin的作用就会发挥出来,对所有依赖的chunk进行公共部分的提取,但是在这里可能很多人会误认为抽取公共部分指的是能抽取某个代码片段,其实并非如此,它是以module为单位进行提取。
方案二、通过 externals 配置来提取常用库
简单来说external就是把我们的依赖资源声明为一个外部依赖,然后通过script外链脚本引入。这也是我们早期页面开发中资源引入的一种翻版,只是通过配置后可以告知webapck遇到此类变量名时就可以不用解析和编译至模块的内部文件中,而改用从外部变量中读取,这样能极大的提升编译速度,同时也能更好的利用CDN来实现缓存。
方案三、利用 DllPlugin 和 DllReferencePlugin 预编译资源模块
我们的项目依赖中通常会引用大量的npm包,而这些包在正常的开发过程中并不会进行修改,但是在每一次构建过程中却需要反复的将其解析,如何来规避此类损耗呢?这两个插件就是干这个用的。
简单来说DllPlugin的作用是预先编译一些模块,而DllReferencePlugin则是把这些预先编译好的模块引用起来。这边需要注意的是DllPlugin必须要在DllReferencePlugin执行前先执行一次,dll这个概念应该也是借鉴了windows程序开发中的dll文件的设计理念。
方案四、使用 Happypack 加速你的代码构建
以上介绍均为针对webpack中的chunk计算和编译内容的优化与改进,对资源的实际体积改进上也较为明显,那么除此之外,我们能否针对资源的编译过程和速度优化上做些尝试呢?
众所周知,webpack中为了方便各种资源和类型的加载,设计了以loader加载器的形式读取资源,但是受限于node的编程模型影响,所有的loader虽然以async的形式来并发调用,但是还是运行在单个 node的进程以及在同一个事件循环中,这就直接导致了当我们需要同时读取多个loader文件资源时,比如babel-loader需要transform各种jsx,es6的资源文件。在这种同步计算同时需要大量耗费cpu运算的过程中,node的单进程模型就无优势了,那么happypack就针对解决此类问题而生。
方案五、增强 uglifyPlugin
uglifyJS凭借基于node开发,压缩比例高,使用方便等诸多优点已经成为了js压缩工具中的首选,但是我们在webpack的构建中观察发现,当webpack build进度走到80%前后时,会发生很长一段时间的停滞,经测试对比发现这一过程正是uglfiyJS在对我们的output中的bunlde部分进行压缩耗时过长导致,针对这块我们推荐使用webpack-uglify-parallel来提升压缩速度。
十、谈谈你对预加载的理解?
Web预加载指的是在网页全加载完成之前,在页面优先显示一些主要内容,以提高用户体验。对于一个较庞大的网站,如果没有使用预加载技术,用户界面就会长时间显示一片空白,直到资源加载完成,页面才会显示内容。
例如,可以通过js预先从服务加载图片资源(动态创建Image,设置src属性),只要浏览器把图片下载到本地,就会被缓存,再次请求相当的src时就会优先寻找浏览器缓存,提高访问速度。
十一、缓存和预加载的区别是什么?
缓存就是把请求过的数据缓存起来,下次请求的时候直接使用缓存内容,提高响应速度
预加载指的是提前把需要的内容加载完成,访问的时候可以明天提高响应效率,比如图片的预加载(可以提前加载一定数量的图片,当用户访问图片的时候一般只看前几张,由于是预加载好的,所以速度比较快)
十二、CDN是啥?
CDN的全称:是Content DeliveryNetwork,即内容分发网络,加速的意思,那么网站CND服务就是网站加速服务。
CDN加速原理:CDN加速将网站的内容缓存在网络边缘(离用户接入网络最近的地方),然后在用户访问网站内容的时候,通过调度系统将用户的请求路由或者引导到离用户接入网络最近或者访问效果最佳的缓存服务器上,有该缓存服务器为用户提供内容服务;相对于直接访问源站,这种方式缩短了用户和内容之间的网络距离,从而达到加速的效果。
CDN的特点:
1、本地加速 提高了企业站点(尤其含有大量图片和静态页面站点)的访问速度,并大大提高以上性质站点的稳定性
2、镜像服务 消除了不同运营商之间互联的瓶颈造成的影响,实现了跨运营商的网络加速,保证不同网络中的用户都能得到良好的访问质量。
3、远程加速 远程访问用户根据DNS负载均衡技术 智能自动选择Cache服务器,选择最快的Cache服务器,加快远程访问的速度
4、带宽优化 自动生成服务器的远程Mirror(镜像)cache服务器,远程用户访问时从cache服务器上读取数据,减少远程访问的带宽、分担网络流量、减轻原站点WEB服务器负载等功能。
5、集群抗攻击 广泛分布的CDN节点加上节点之间的智能冗于机制,可以有效地预防黑客入侵以及降低各种D.D.o.S攻击对网站的影响,同时保证较好的服务质量。
十三、ajax请求的时候get 和post方式的区别?
1. GET请求会将参数跟在URL后进行传递,而POST请求则是作为HTTP消息的实体内容发送给WEB服务器。当然在Ajax请求中,这种区别对用户是不可见的
2、GEt传输数据容量小,不安全,post传输数据内容大,更加安全;
十四、AJAX的工作原理
Ajax的工作原理相当于在用户和服务器之间加了—个中间层(AJAX引擎),使用户操作与服务器响应异步化。并不是所有的用户请求都提交给服务器,像—些数据验证和数据处理等都交给Ajax引擎自己来做, 只有确定需要从服务器读取新数据时再由Ajax引擎代为向服务器提交请求。
十五、创建ajax过程
(1)创建XMLHttpRequest对象,也就是创建一个异步调用对象.
(2)创建一个新的HTTP请求,并指定该HTTP请求的方法、URL及验证信息.
(3)设置响应HTTP请求状态变化的函数.
(4)发送HTTP请求.
(5)获取异步调用返回的数据.
(6)使用JavaScript和DOM实现局部刷新.
十六、从地址栏输入URL到页面加载完成发生了什么?
1.域名解析,首先浏览器会解析域名为对应的IP地址(解析的过程是依次浏览器搜索自身DNS缓存->浏览器搜索操作系统DNS缓存->读取hosts文件->浏览器向DNS服务器发送请求,其中任何一个环节解析成功,解析就会终止);
2.发起TCP的3次握手(握手过程中传送的包里不包含数据,三次握手完毕后,客户端与服务器才正式开始传送数据);
3.建立TCP连接后发起http请求(常用get/post);
4.服务器响应请求,返回数据,浏览器得到html代码;
5.浏览器解析html代码,并请求html代码中的资源;
6.浏览器对页面进行渲染呈现给用户。
总结:
域名解析—> 发起TCP3次握手 —>建立TCP链接后发起Http请求 —>服务器响应Http请求,浏览器得到html代码 —> 浏览器解析Html代码,并请求Html代码中的资源(如:图片,js,css等) —> 浏览器对页面进行渲染呈现给用户。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号