Java基础篇——JUC初步
1.基础知识
-
java默认的两个线程:Main线程+GC守护线程
-
java并不能开启线程,需要调用底层用c语言写的本地方法
-
wait和sleep的区别:
wait方法会释放线程锁,并且只能在同步代码块中使用,sleep带锁睡眠,可以在任一地方睡眠
-
Synchronized锁和lock锁的区别
Synchronized会自动释放锁,lock需手动释放,不然会造成死锁
Synchronized线程会持续等待直到获得锁,而lock锁的tryLock()方法避免了死等
Synchronized(可重入锁、公平锁、非中断锁)
Lock(可重入锁、默认非公平锁(可设置公平)、可中断锁)
-
java对象布局
1.对象的实例属性
2.对象头(12byte)
- MarkWord
- Class Metadata Address(Class Pointer)
3.数据对齐 (1+2的总大小不是8byte的倍数使用于补齐)
-
Condition监视器
与lock配套为了代替原wait和notify
Condition con = lock.newCondition();//创建监视器对象 con.await();//线程等待 con.signal();//线程唤醒condition监视器可以创建多个监视器对象同时监视多个线程,可以达到控制线程执行的效果
-
集合的线程不安全
线程不安全的集合在进行线程修改时会几率报出并发修改异常ConcurrentModificationException
线程安全的集合:Vector、Hashtable、ConcurrentHashMap、Stack
集合线程不安全的解决办法
1.用线程安全的集合替代
2.用Collections.synchronized+集合名系列集合,如:
List list = Collections.synchronizedList(new ArrayList<>());3.用CopyOnWrite系列集合(写时复制)
相比1、2方法,方法3使用的是lock锁,效率要高于synchronized锁,其次写时复制的意思是多个线程修改的是原集合的副本,在修改完成后再写回原集合,所以lock锁是加在副本上的,原集合此时依然可以被只读线程获取,加快了读写效率,代价是副本内存占用和数据实时性。
map集合没有CopyOnWrite,但有一个等效的ConcurrentHashMap
这里推荐一个CSDN博主!(https://blog.csdn.net/weixin_44460333/article/details/86770169)
-
常用辅助类
CountDownLatch 减法计数器
CountDownLatch latch = new CountDownLatch(10);//初始化为10 for (int i = 0; i < 10; i++) { new Thread(()->{ latch.countDown();//计数器减一 }).start(); } latch.await();//等待计数器归零 System.out.println("执行完毕");CyclicBarrier 线程加计数器
CyclicBarrier barrier = new CyclicBarrier(10,()->{ System.out.println("顶级线程执行");//线程计数达到10之后执行该线程 }); for (int i = 0; i < 10; i++) { new Thread(()->{ barrier.await();//线程计数器加一 }).start(); }Semaphore信号量
Semaphore semaphore = new Semaphore(5); //同一时间内只能有5个线程“执行”,并发限流 for (int i = 0; i < 10; i++) { new Thread(()->{ try { semaphore.acquire(); System.out.println(Thread.currentThread().getName()+"抢到车位"); TimeUnit.SECONDS.sleep(5); semaphore.release(); System.out.println(Thread.currentThread().getName()+"离开车位"); } catch (InterruptedException e) { e.printStackTrace(); } },""+i).start(); -
ReadWriteLock 读写锁
private ReadWriteLock lock = new ReentrantReadWriteLock(); //读锁 lock.readLock().lock(); ...//业务代码 lock.readLock().unlock(); //写锁 lock.writeLock().lock(); ...//业务代码 lock.writeLock().unlock(); } -
Blocking Queue 阻塞队列
- 队列的四组API
方法功能 抛出异常 不抛出异常,返回值 阻塞等待 超时等待 添加元素 add() offer() put 重载offer 删除元素 remove() poll() take 重载poll 判断队列头 elment() peek() 重载offer(Object,long timeOut(等待时间),TimeUnit(时间单位))
重载poll(long timeOut(等待时间),TimeUnit(时间单位))
- SynchronousQueue同步队列
队列中只能有一个元素,当队列中有元素时,不允许添加其他元素,只有当该元素被移除,才能继续添加
2.线程池
-
Executors
ExecutorService threadpool = Executors.newCachedThreadPool();//伸缩池 //ExecutorService threadpool = Executors.newFixedThreadPool(5);//固定大小的池 //ExecutorService threadpool = Executors.newSingleThreadExecutor();//单个线程的池 for (int i = 0; i < 100; i++) { threadpool.execute(()->{//创建线程 System.out.println(Thread.currentThread().getName()+" is Running"); }); } threadpool.shutdown(); //一般不使用executors创建线程池,高并发下容易报出oom -
七大参数
public ThreadPoolExecutor(int corePoolSize,//核心线程池大小 int maximumPoolSize,//最大线程数量 long keepAliveTime,//线程存活时间 TimeUnit unit,//时间单位 BlockingQueue<Runnable> workQueue,//阻塞队列 ThreadFactory threadFactory,//线程工厂 RejectedExecutionHandler handler) {//拒绝策略 ... } ``` -
四种拒绝策略
ThreadPoolExecutor executor = new ThreadPoolExecutor(3,5,2,//自定义线程池 TimeUnit.SECONDS,new ArrayBlockingQueue<>(3), Executors.defaultThreadFactory(), //拒绝策略 //new ThreadPoolExecutor.AbortPolicy()//阻塞队列满,抛出异常 //new ThreadPoolExecutor.CallerRunsPolicy()//由原调用线程执行(哪来回哪去) //new ThreadPoolExecutor.DiscardPolicy()//阻塞队列满,不会抛出异常 new ThreadPoolExecutor.DiscardOldestPolicy()//阻塞队列满,不会抛出异常,和最早进入阻塞队列的线程竞争 ); -
最大线程数该如何定义
cpu密集型,最大线程数=内核数
Runtime.getRuntime().availableProcessors();//获取计算机核数io密集型,最大线程数>占用IO大的线程数
3.接口
-
四大函数式接口
public interface Function<T, R> { //输入T型,返回R型 R apply(T t);//需实现apply方法 }public interface Predicate<T> { //输入T型,返回布尔型 boolean test(T t);//需实现test方法 }//断定型接口public interface Consumer<T> { //只有输入、没有输出 void accept(T t);//需实现accept方法 }//消费型接口public interface Supplier<T> { //只有返回值,没有输入 T get();//需实现get方法 }//供给型接口 -
Stream流式计算
//存储交给集合,计算交给流 list.stream() .filter(u->{return u.getId()%2==0;})//筛选偶数id的用户 .filter(u->{return u.getAge()>22;})//筛选年龄大于22的用户 .map(u->{return u.getName().toUpperCase();})//将用户名转换为大写 .sorted((uu1,uu2)->{return uu2.compareTo(uu1);})//将用户名倒序排序 .limit(1)//限制输出个数为1 .forEach(System.out::println);//便利打印
4.JMM
-
JMM内存模型
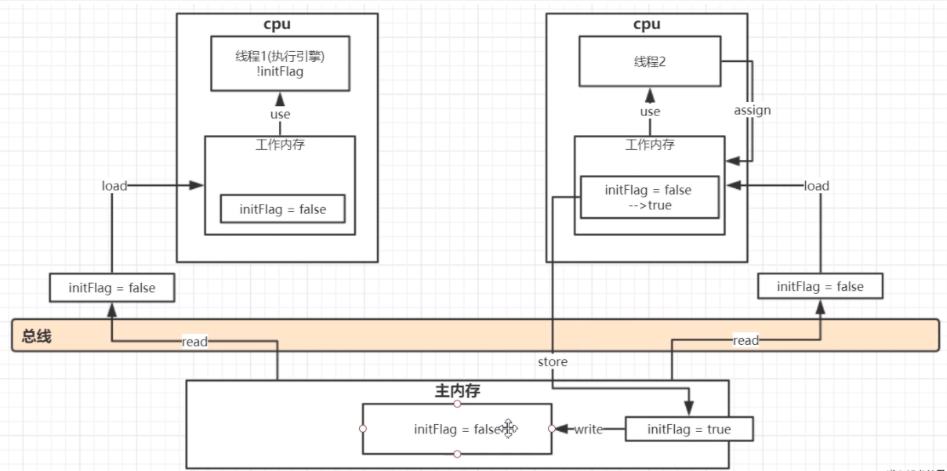
-
内存交互八大操作及其约束
1.lock (锁定):作用于主内存的变量,把一个变量标识为线程独占状态
2.unlock (解锁):作用于主内存的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定
3.read (读取):作用于主内存变量,它把一个变量的值从主内存传输到线程的工作内存中,以便随后的load动作使用
4.load (载入):作用于工作内存的变量,它把read操作从主存中变量放入工作内存中
5.use (使用):作用于工作内存中的变量,它把工作内存中的变量传输给执行引擎,每当虚拟机遇到一个需要使用到变量的值,就会使用到这个指令
6.assign (赋值):作用于工作内存中的变量,它把一个从执行引擎中接受到的值放入工作内存的变量副本中
7.store (存储):作用于主内存中的变量,它把一个从工作内存中一个变量的值传送到主内存中,以便后续的write使用
8.write (写入):作用于主内存中的变量,它把store操作从工作内存中得到的变量的值放入主内存的变量中
JMM对这八种指令的使用,制定了如下规则:
1.不允许read和load、store和write操作之一单独出现。即使用了read必须load,使用了store必须write
2.不允许线程丢弃他最近的assign操作,即工作变量的数据改变了之后,必须告知主存
3.不允许一个线程将没有assign的数据从工作内存同步回主内存
4.一个新的变量必须在主内存中诞生,不允许工作内存直接使用一个未被初始化的变量。就是怼变量实施use、store操作之前,必须经过assign和load操作
5.一个变量同一时间只有一个线程能对其进行lock。多次lock后,必须执行相同次数的unlock才能解锁
6.如果对一个变量进行lock操作,会清空所有工作内存中此变量的值,在执行引擎使用这个变量前,必须重新load或assign操作初始化变量的值
7.如果一个变量没有被lock,就不能对其进行unlock操作。也不能unlock一个被其他线程锁住的变量
8.对一个变量进行unlock操作之前,必须把此变量同步回主内存
-
volatile关键字
1.保证线程可见性,不保证原子性(保证原子性可以用Lock、synchronized、Semaphore(信号量)、原子类(java.util.concurrent.atomic))
2.禁止指令重排(内存屏障)
-
CAS
CAS(Compare And Swap)比较并替换。
CAS机制当中使用了3个基本操作数:内存地址V,旧的预期值A,要修改的新值B。
更新一个变量的时候,只有当变量的预期值A和内存地址V当中的实际值相同时,才会将内存地址V对应的值修改为B,预期值不一样时,将会通过循环获取预期值进行CAS(底层用自旋锁实现)。
CAS会导致ABA问题(即内存地址中的值可能在该线程执行过程中被修改之后再改回来,导致CAS提交时预期值和内存地址中的值相同,修改成功)
可以通过原子引用解决这个问题:
AtomicStampedReference<T> stampedReference = new AtomicStampedReference(T,version版本号); stampedReference.compareAndSet(T_预期值,T_修改值,原始版本号,新版本号); stampedReference.getReference();//获取当前版本号

 浙公网安备 33010602011771号
浙公网安备 33010602011771号