Redis的三种持久化方式-快照持久化(RDB)、AOF持久化、混合持久化及容灾备份、优化方案
Redis为了内部数据的安全考虑,会把本身的数据以文件形式保存到硬盘中一份,在服务器重启之后会自动把硬盘的数据恢复到内存(redis)的里边,数据保存到硬盘的过程就称为“持久化”效果。
redis有两种持久化功能,一种是“快照持久化(RDB)”,一种是“AOF持久化”。
一、RDB持久化,默认持久化方式
Redis数据持久化是将内存中的数据保存到磁盘里,避免数据意外丢失。RDB持久化会生成一个RDB文件,这个RDB文件是一个经过压缩的二进制文件。通过该文件可以还原出Redis数据库中的数据。RDB的持久化可以手动执行,也可以根据服务器配置项定期自动执行。
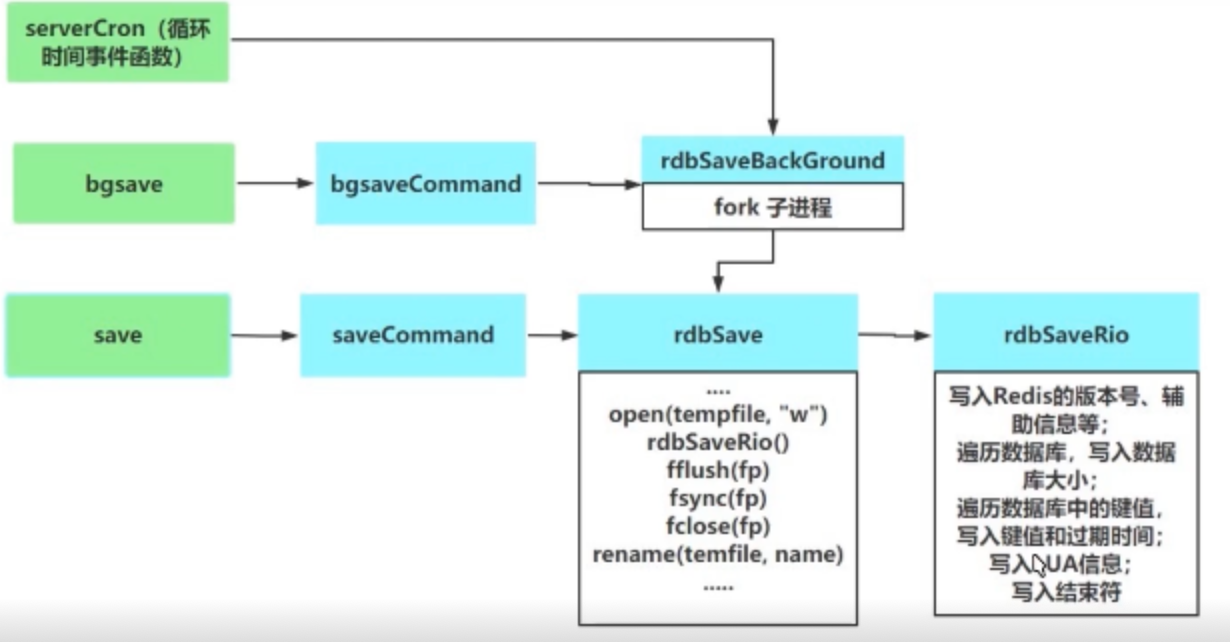
有两个命令可以创建RDB文件,一个是SAVE,另一个是BGSAVE。
执行SAVE命令会阻塞Redis服务器进程,直到RDB文件创建完成为止,在服务器进程被阻塞期间,服务器不能处理任何命令请求。
执行BGSAVE命令会派生出一个子进程,然后由子进程负责创建RDB文件,服务器父进程继续处理命令请求。
SAVE命令和BGSAVE命令的底层调用的函数都是同一个函数rdbSave,只不过SAVE命令是直接调用这个函数,而BGSAVE会fork()出子进程来调用这个函数。
RDB文件的载入工作是在服务器启动时自动执行的,只要Redis服务器在启动时检测到RDB文件存在,就会自动载入RDB文件。值得一提的是,Redis服务器在载入RDB文件的期间,会一直处于阻塞状态,直到载入工作完成为止。
BGSAVE命令在不阻塞服务器进程的情况下执行,所以Redis允许用户通过设置服务器的save选项来让服务器每隔一段时间自动执行一次BGSAVE命令
步骤
先创建配置/数据/日志目录
我这边已经配置好了,在redis目录下分别创建,然后redis.conf复制备份了一份
wangteng@192 redis % pwd /Applications/MxSrvs/bin/redis wangteng@192 redis % ls bin data log conf dump.rdb redis.conf.bak
编辑redis.conf文件,找到以下配置项并暂时设定。
#放行IP限制 bind 0.0.0.0 //这里不做任何限制 #后台启动 daemonize yes #日志存储目录及日志文件名 logfile "/Applications/MxSrvs/bin/redis/log/redis.log" #rdb数据文件名 dbfilename dump.rdb #rdb数据文件和aof数据文件的存储目录 dir /Applications/MxSrvs/bin/redis/data #设置密码 requirepass 123456
启动redis
//指定配置文件,后台运行redis wangteng@wangtengdeMacBook-Pro redis % pwd /Applications/MxSrvs/bin/redis wangteng@wangtengdeMacBook-Pro redis % ./bin/redis-server conf/redis.conf
wangteng@wangtengdeMacBook-Pro redis % ps -ef | grep redis 501 22617 1 0 9:36上午 ?? 0:00.41 ./bin/redis-server 127.0.0.1:6379 501 22639 473 0 9:38上午 ttys000 0:00.01 grep redis 501 22636 22438 0 9:37上午 ttys002 0:00.01 ./bin/redis-cli
然后连接redis客户端,随意设置key =>val
wangteng@wangtengdeMacBook-Pro redis % kill -9 22617
重新启动redis,然后连接客户端,执行keys*命令,发现key全部丢失,因为之前的配置没有开启持久化操作。因为这个时间比较短,短与900秒,接下来看下面的配置。
继续编辑redis.conf,找到save关键字
save 900 1 save 300 10 save 60 10000
- 第一条的意思是:服务器在900秒内对数据库执行过至少1次修改,就会执行BGSAVE命令
- 第二条的意思是:服务器在300秒内对数据库执行过至少10次修改,就会执行BGSAVE命令
- 第三条的意思是:服务器在60秒内对数据库执行过至少10000次修改,就会执行BGSAVE命令
以上三个save的意思都有了相应的说明,数据修改的频率非常高,备份的频率也高,数据修改的频率低,备份的频率也低。
这里可以把数字调整小一点,比如5,那么然后重启redis,操作命令,5秒中内的所有操作都会被保存。这里可以测试一下,然后data目录下会生成文件,编辑看看
redis-bitsÀ@ú^EctimeÂb:5bú^Hused-memÂо^P^@ú^Laof-preambleÀ^@þ^@û^B^@^@^Bbb^Cbbb^@^Caaa^Caaaÿþ×<93>©^ZÙ<9f><81>
文件有了,那么就算redis重启之后,它会加载文件,自然就不会丢失了.
其实这个文件也可以说是redis快照。产生快照的情况有以下几种
- 连接客户端,或者redis-cli bgsave 手动bgsave执行,非阻塞
- 手动save执行,阻塞
- 根据配置文件自动执行
- 客户端发送shutdown,系统会先执行save命令阻塞客户端,然后关闭服务器
- 当有主从架构时,从服务器向主服务器发送sync命令来执行复制操作时,主服务器会执行bgsave操作。
如果发现dump.rdb文件缺少了最近的记录,那么在这补充一种手动持久化方式,可以立即看到效果,执行此命令
./redis-cli bgsave #异步保存
其次还包括一些其他的手动命令
./redis-cli shutdown #同步保存到服务器并关闭redis服务器
./redis-cli lastsave #返回上次成功保存到磁盘的unix时间戳
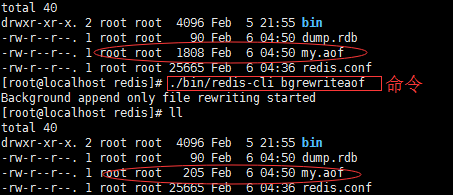
./redis-cli bgrewriteaof #当日志文件过长时优化AOF日志文件存储
由于快照方式是在一定间隔时间做一次的,所以如果redis意外down掉的话,就会丢失最后一次快照后的所有修改。如果应用要求不能丢失任何修改的话,可以采用aof持久化方式
rdb原理图
rdb优点
- 紧凑压缩的二进制文件
- fork子进程想能最大化
- 启动效率高
rdb缺点
- 生成快照的时机问题,频率会造成数据丢失
- fork子进程的开销问题,数据很大的情况下会频繁fork子进程生成快照,会造成很大开销,影响性能,如果数据非常多(10-20G)就不合适频繁操作该持久化操作。
由于快照方式是在一定间隔时间做一次的,所以如果redis意外down掉的话,就会丢失最后一次快照后的所有修改。如果应用要求不能丢失任何修改的话,可以采用aof持久化方式
二、AOF持久化,默认关闭
除了RDB持久化之外,Redis还提供了AOF持久化功能,两者的实现方式有着很大的不同。RDB持久化是通过保存数据库中的键值对来记录数据库状态,而AOF持久化是通过保存Redis服务器所执行的写命令来记录记录数据库状态。
AOF持久化是如何实现的呢?AOF持久化分文三个步骤:命令追加、文件写入、文件同步。
- 命令追加:当AOF持久化功能打开时,服务器在执行完一个写命令后,会以一定的格式将被执行的写命令追加到服务器中的aof缓冲区中。aof缓冲区是redisServer结构体维护的一个SDS结构的属性。
- 文件写入:文件写入是指从Redis的aof缓冲区写入到操作系统的内存缓冲区。这个过程是为了提高文件的写入效率,但是带来的风险是服务器出现故障时,内存缓冲区中的数据会丢失掉。
- 文件同步:这个过程是将内存缓冲区中的数据写入到硬盘中的AOF文件中
Redis中默认执行的是RDB持久化,如何打开AOF持久化呢?我们先来看看AOF的配置项:
步骤
编辑配置文件,增加配置,dir目录可以确保aof和rdb文件都保存在指定目录,所以只需要哦配置一次
#AOF持久化开启 appendonly yes #AOF文件名称 appendfilename "appendonly.aof"
配置好之后启动redis,那么data目录下就会出现aof文件。
aof同步策略有三种,appendfsync : always、everysec、no三种配置
- 每秒同步(默认,每秒调用一次fsync,这种模式想能并不是很糟糕),这个操作由一个线程来负责,性能很高, 每一秒中备份一次。不管一秒钟变化了多少key,只备份一次,性能得到一定的保护。推荐使用。
- 每修改同步(会极大削弱redis性能,因为这种模式下每次write后都会调用fsync),可以确保数据不会丢失。一写指令就备份一次。这样做虽然安全,但是系统性能会降低。不推荐使用
- 不主动同步(由操作系统自动调度刷磁盘,性能是最好的),这种操作在服务器出现异常时会丢失一部分数据。会查看当前服务器状态,如果状态良好,就进行备份(随机)。这种备份方式数据是没有保证的。
对比下来,性能:always<everysec<no,而数据安全:always>everysec>no。
aof还原数据:服务器只要读入并重新执行一遍AOF文件里保存的写命令,就可以还原服务器关闭之前的数据库内容。

aof数据是基于命令追加,那么假如不小心flushdb的话,找到aof的文件,那么删除最后一行flushdb命令,重启一下redis还是可以恢复数据的。
aof支持重写
redis可以在aof文件体积变得过大时,自动地在后台对aof进行rewrite。即redis以append模式不断的将需改数据写入到老的磁盘文件中,同时redis还会创建一个新的文件用于记录此期间有哪些修改命令被执行。
因为redis在创建新的aof文件过程中,会继续将命令追加到现有的aof文件里面,即使重写过程中发生停机,现有的aof文件也不会丢失。
而一旦aof文件创建完毕,redis就会从旧aof文件切换新的aof文件,并开始对新的aof文件进行追加操作。
为什么要重写?
比如业务很简单,就来回delete set同一个key,就这个业务反复运行了10年,那么aof文件将记录无数个 delete k1,set k1操作,其实都是重复的,但每次追加,文件就越来越大,这个时候假如redis宕机, 需要恢复,那么假如1T的aof文件去恢复,就卡死了。所以压缩重写就是为了减少命令个数,两个命令即可完成。
rewrite触发条件
- 客户人为执行端执行bgrewriteaof命令
- auto-aof-rewrite-min-size 64mb,意思是当文件超过64M,redis就开始重写,也可以配置的大一点,可以记录更多内容
- auto-aof-rewrite-percentage 100,这是配置百分比,意思就是大于上次重写大小2倍的时候重写
常用配置
#fsync 持久化策略 appendfsync everysec #aof重写期间是否禁止fsync:如果开启该选项,可以减轻文件重写时CPU和硬盘的负载(尤其是硬盘),但是可能会丢失aof重写期间的数据,小在负载和安全性之间进行平衡。如果是yes,那么重写期间是不会记录写入命令,可能会导致重写期间的数据 no-appendfsync-on-rewrite no #当aof文件大于多少字节后才触发重写 auto-aof-rewrite-min-size 64mb #当前写入日志文件的大小超过上一次rewrite之后的文件大小的百分之100时,也就是2倍时触发rewrite #auto-aof-rewrite-percentage 100 #如果aof文件结尾损坏,redis启动时是否载入aof文件,如果文件坏了,会先去修复,再去启动,相当于提示 aof-load-truncated yes
aof优点
- 数据不易丢失
- 自从重写机制
- 易懂易恢复
aof缺点
- aof文件恢复数据慢
- aof持久化效率低,因为每秒都会记录操作
三、RDB和AOF区别和联系,以及同时工作时的情况
区别和联系:
RDB持久化:默认开启;全量备份,一次性保存整个数据库;体积小,数据恢复快;服务器异常时可能会丢失部分数据;SAVE操作会阻塞,BGSAVE不阻塞。类似于mysql的dump备份文件
AOF持久化:默认关闭;增量备份,一次保存一个修改数据库的命令;体积大,数据恢复慢;备份频率可以自己设置;不会出现阻塞。类似mysql的binlog。
RDB与AOF混合使用
同时开启
redis先加载aof文件来恢复原始数据,因为aof数据比rdb更完整,但是aof存在潜在bug,如把错误的操作记录写入了aof,会导出数据恢复失败,所以可以把rdb作为后备数据。
为了考虑性能,可以只在slave上开启rdb,并且15min备份一次,如果为了避免aof rewrite的IO以及阻塞,可以在redis集群中不开启aof,靠集群的备份机制来保证可用性,在启动时选择较新的rdb文件,如果集群全部崩溃,会丢失15min前的数据。
混合模式
设置redis4.0开始的新特性,在混合使用中AOF读取RDB数据重建原始数据集,集二者优势为一体。
解决问题:redis在重启时通常加载aof文件,但是加载速度慢,因为rdb数据不完整,所以加载aof。
开启方式:aof-use-rdb-preamble true
开启后,aof在重写时会直接读取rdb的内容
运行过程:通过bgwriteaof完成,不同的是当开启混合持久化后
- 子进程会把内存中的数据以rdb方式写入aof中
- 把重写缓存区中的增量命令以aof方式写入到文件
- 将含有rdb和aof的aof数据覆盖旧的aof文件
新的aof文件中,一部分数据来自rdb文件,一部分来自redis运行过程时的增量数据
数据恢复
当开启了混合持久化,启动redis依然优先加载aof文件,aof文件加载可能有两种情况
aof文件开头是rdb的格式,先加载rdb内容再加载剩余的aof
aof文件开头不是rdb格式,直接以aof格式加载整个文件
优点:技能快速备份又能避免大量数据丢失
缺点:rdb是压缩格式,aof在读取它时可读性较差
二者动态切换
redis在2.2或者以上版本,可在不重启的情况下,通过config set 从rdb动态切换aof。
假设我们的环境rdb是开启的,没有开启aof,现在想把rdb关掉,然后使用aof的持久化。那么首先我们先把rdb文件备份,放在安全的地方,不要删除文件。因为开启aof之后,如果aof是混合使用的状态,可能需要加载rdb的数据,然后紧接着执行下面两条命令。首先开启aof的模式,然后set置空,关闭rdb的持久化方式。
#开启aof redis-cli config set appendonly yes #关闭rdb redis-cli config set save ""
然后写入命令,确保写命令会被正确的追加到aof文件的末尾,这样aof文件就算是创建成功。当然在创建aof文件的过程中会有一些阻塞,这个是会影响redis性能的,因为创建aof直到命令追加写入完成这个过程会阻塞服务,所以建议不要在高峰期做这样的事情。那么后续的命令就可以写到aof文件。
四、redis容灾备份
首先开启了rdb和aof
创建一个脚本
#!bin/bash cur_date=$(data "+%Y%m%d%H%M%S") rm -rf /usr/local/redis/snapshotting/$cur_date mkdir -p /usr/local/redis/snapshotting/$cur_date cp /usr/local/redis/data/dump.rdb /usr/local/redis/snapshotting/$cur_date del_date=$(date -d -48hour "+%Y%m%d%H%M") //把48小时之前的删除掉 rm -rf /usr/local/redis/snapshotting/$del_date
然后使用crontab定时执行,以下为每10秒执行一次,生成环境可以调整每小时一次
*/1 * * * * sh /usr/local/redis/bin/redis-rdb-copy-per-hour.sh */1 * * * * sleep 10; sh /usr/local/redis/bin/redis-rdb-copy-per-hour.sh */1 * * * * sleep 20; sh /usr/local/redis/bin/redis-rdb-copy-per-hour.sh */1 * * * * sleep 30; sh /usr/local/redis/bin/redis-rdb-copy-per-hour.sh */1 * * * * sleep 40; sh /usr/local/redis/bin/redis-rdb-copy-per-hour.sh */1 * * * * sleep 50; sh /usr/local/redis/bin/redis-rdb-copy-per-hour.sh
五、优化方案
独立部署,硬盘优化
redis的rdb和aof文件生成的过程,除了会对内存和硬盘有压力,属于cpu密集型的操作,最好把redis单独部署在一台服务器,不要和其他服务部署在一起,因为本来有大量的磁盘io,再加上redis那么磁盘和cpu可能会受不了,其实就是为了解决子进程频繁的创建开销问题。
硬盘可以根据写入了决定,比如redis有大量写入操作,那么可以考虑使用性能更高的ssd硬盘。
缓存禁用持久化
如果redis定位就是做缓存,那么缓存的数据肯定是在别的地方都有,及时丢失了不要紧。比如有两套缓存,有a缓存和b缓存两套,假如a缓存失效了,可以立马把b缓存顶上去,把这种方案做好就可以了。再说缓存肯定在关系型数据库也有,那么就可以把持久化禁用,直接从关系型数据库拿数据再写入缓存就可以了。
主从模式,从持久化
因为从节点是从主节点读的数据,从节点是从主节点复制的,从节点是不会开启写模式的,只读的,数据都是从主节点复制过去的,每次从主节点复制数据的时候,首先会主节点进行一次bgsave操作,然后和磁盘交互一下,生成rdb快照,然后再把快照发给从节点。假如从节点和主节点进行频繁的复制,那么主节点这边的压力会增大,以为频繁fork子进程进行rdb快照生成。既然是主从模式了,那么可不可以把主节点的持久化方式关闭掉,交给从节点,比如从节点15分钟备份一次,只需在从节点添加一个save 900 1就可以了,甚至可以把aof也给禁用掉,以为master主从已经高可用,数据是不可能丢失的,因为15分钟内数据丢失了,可能只是某一个节点丢失了,但是还有其他节点工作着,所以不可能像以前单节点的数据丢失,所以aof都可以禁用,那么又节省了一大批IO的行为。
优化fork处理
其实就是降低aof的重写频率,因为rdb虽然是子进程fork在做这件事,但是rdb有一个非常长的时间窗口期才会做这件事。开起来aof情况下,比如说文件大小已经超过了64M,那么就会重写,在重写过程中肯定会有影响到性能,那么假如把重写的时间给拉长,比如之前是大于64M会重写,那么把大小的上线调大点,比如3G甚至5G,这样就降低了频率,也会提高性能,降低fork子进程的创建。
还可以修改配置
no-appendfsync-on-rewrite no
改为yes,意思就是aof重写期间不去执行接收正常命令追加的行为,这样它会专心做重写,然后继续接收命令。不好的地方就是重写期间的数据可能会丢失,这样也是根据当前具体生成环境的服务器CPU硬盘等各方面因素来决定的,如果硬盘是能扛得住,服务器应能比较好的,那么就可以忽略,那么就可以不要禁用,正常追加就可以了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号