Kafka线上Gc overhead limit exceeded排查
show me your bugs
报错部分截图,其中上面定位到报错点,将其他服务导致异常问题
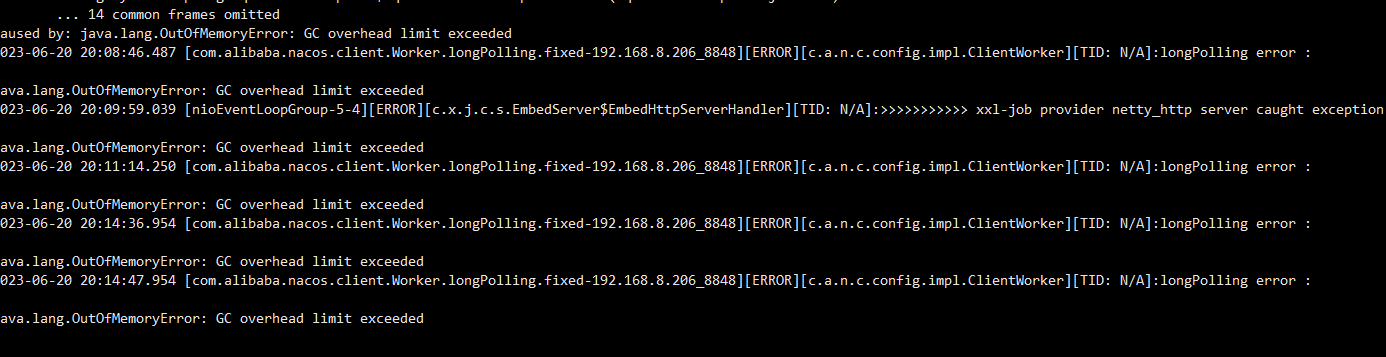
含义: JVM花费了98%以上的时间进行垃圾回收,但只回收了不到2%的堆内存
触发条件: 连续多次GC都无法有效释放内存
结果: JVM认为继续GC没有意义,抛出此错误
部分源码
@Slf4j
public class KafkaOffsetTools {
//主题
public static final String TOPIC_NAME = "parking_io";
//消费者组
public static final String GROUP_ID_CONFIG = "docking_config";
//如果是集群,则用逗号分隔。
public static final String KAFKA_BROKER_LIST = "192.168.8.200:9092";
public static OffsetVo getKafkaLag(String topic, String broker, int port, String group) {
OffsetVo offsetVo = new OffsetVo();
// String topic = "parking_io";
// String broker = "192.168.3.103";
// int port = 9092;
// String group = "docking_config";
BlockingChannel channel = null;
SimpleConsumer consumer = null;
try {
String clientId = "app-log-all-beta2";
int correlationId = 0;
channel = new BlockingChannel(broker, port,
BlockingChannel.UseDefaultBufferSize(),
BlockingChannel.UseDefaultBufferSize(),
5000);
channel.connect();
List<String> seeds = new ArrayList<String>();
seeds.add(broker);
KafkaOffsetTools kot = new KafkaOffsetTools();
TreeMap<Integer, PartitionMetadata> metadatas = kot.findLeader(seeds, port, topic);
long sum = 0l;
long sumOffset = 0l;
long lag = 0l;
List<TopicAndPartition> partitions = new ArrayList<TopicAndPartition>();
for (Entry<Integer, PartitionMetadata> entry : metadatas.entrySet()) {
int partition = entry.getKey();
TopicAndPartition testPartition = new TopicAndPartition(topic, partition);
partitions.add(testPartition);
}
OffsetFetchRequest fetchRequest = new OffsetFetchRequest(
group,
partitions,
(short) 0,
correlationId,
clientId);
for (Entry<Integer, PartitionMetadata> entry : metadatas.entrySet()) {
int partition = entry.getKey();
channel.send(fetchRequest.underlying());
OffsetFetchResponse fetchResponse = OffsetFetchResponse.readFrom(channel.receive().payload());
TopicAndPartition testPartition0 = new TopicAndPartition(topic, partition);
OffsetMetadataAndError result = fetchResponse.offsets().get(testPartition0);
short offsetFetchErrorCode = result.error();
if (offsetFetchErrorCode == ErrorMapping.NotCoordinatorForConsumerCode()) {
} else {
long retrievedOffset = result.offset();
sumOffset += retrievedOffset;
}
String leadBroker = entry.getValue().leader().host();
String clientName = "Client_" + topic + "_" + partition + partition;
consumer = new SimpleConsumer(broker, port, 100000,
64 * 1024, clientName);
long readOffset = getLastOffset(consumer, topic, partition,
kafka.api.OffsetRequest.LatestTime(), clientName);
sum += readOffset;
log.debug(partition + ":" + readOffset);
}
log.debug("logSize:" + sum);
log.debug("offset:" + sumOffset);
offsetVo.setSum(sum);
offsetVo.setSumOffset(sumOffset);
return offsetVo;
} catch (Exception e) {
log.error("失败", e);
} finally {
if (null != channel) {
channel.disconnect();
}
if (consumer != null) {
consumer.close();
}
}
return new OffsetVo();
}
public KafkaOffsetTools() {
}
public static long getLastOffset(SimpleConsumer consumer, String topic,
int partition, long whichTime, String clientName) {
TopicAndPartition topicAndPartition = new TopicAndPartition(topic,
partition);
Map<TopicAndPartition, PartitionOffsetRequestInfo> requestInfo = new HashMap<TopicAndPartition, PartitionOffsetRequestInfo>();
requestInfo.put(topicAndPartition, new PartitionOffsetRequestInfo(
whichTime, 1));
kafka.javaapi.OffsetRequest request = new kafka.javaapi.OffsetRequest(
requestInfo, kafka.api.OffsetRequest.CurrentVersion(),
clientName);
OffsetResponse response = consumer.getOffsetsBefore(request);
if (response.hasError()) {
System.out
.println("Error fetching data Offset Data the Broker. Reason: "
+ response.errorCode(topic, partition));
return 0;
}
long[] offsets = response.offsets(topic, partition);
return offsets[0];
}
private TreeMap<Integer, PartitionMetadata> findLeader(List<String> a_seedBrokers,
int a_port, String a_topic) {
TreeMap<Integer, PartitionMetadata> map = new TreeMap<Integer, PartitionMetadata>();
SimpleConsumer consumer = null;
try{
for (String seed : a_seedBrokers) {
consumer = new SimpleConsumer(seed, a_port, 100000, 64 * 1024,
"leaderLookup" + System.currentTimeMillis());
List<String> topics = Collections.singletonList(a_topic);
TopicMetadataRequest req = new TopicMetadataRequest(topics);
kafka.javaapi.TopicMetadataResponse resp = consumer.send(req);
List<TopicMetadata> metaData = resp.topicsMetadata();
for (TopicMetadata item : metaData) {
for (PartitionMetadata part : item.partitionsMetadata()) {
map.put(part.partitionId(), part);
}
}
}
return map;
}catch(Exception e){
log.error("失败",e);
}finally {
if(null != consumer){
consumer.close();
}
}
return null;
}
private static final int ZOOKEEPER_TIMEOUT = 30000;
private final CountDownLatch latch = new CountDownLatch(1);
public ZooKeeper getZookeeper(String connectionString) {
ZooKeeper zk = null;
try {
zk = new ZooKeeper(connectionString, ZOOKEEPER_TIMEOUT, new Watcher() {
@Override
public void process(WatchedEvent event) {
if (Watcher.Event.KeeperState.SyncConnected.equals(event.getState())) {
latch.countDown();
}
}
});
latch.await();
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
return zk;
}
public static Properties getConsumerProperties(String groupId, String bootstrap_servers) {
Properties props = new Properties();
props.put("group.id", groupId);
props.put("bootstrap.servers", bootstrap_servers);
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
return props;
}
/**
* 获取logSize, offset, lag等信息
*
* @param zk
* @param bootstrap_servers
* @param groupId
* @param topics null查询groupId消费过的所有topic
* @param sorted
* @return
* @throws Exception
*/
public List<Map<String, Object>> getLagByGroupAndTopic(ZooKeeper zk, String bootstrap_servers, String groupId,
String[] topics, boolean sorted) throws Exception {
List<Map<String, Object>> topicPatitionMapList = new ArrayList<>();
// 获取group消费过的所有topic
List<String> topicList = null;
if (topics == null || topics.length == 0) {
try {
topicList = zk.getChildren("/consumers/" + groupId + "/offsets", false);
} catch (KeeperException | InterruptedException e) {
log.error("从zookeeper获取topics失败:zkState: {}, groupId:{}", zk.getState(), groupId);
throw new Exception("从zookeeper中获取topics失败");
}
} else {
topicList = Arrays.asList(topics);
}
Properties consumeProps = getConsumerProperties(groupId, bootstrap_servers);
log.info("consumer properties:{}", consumeProps);
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(consumeProps);
// 查询topic partitions
for (String topic : topicList) {
List<PartitionInfo> partitionsFor = consumer.partitionsFor(topic);
//由于有时延, 尽量逐个topic查询, 减少lag为负数的情况
List<TopicPartition> topicPartitions = new ArrayList<>();
// 获取topic对应的 TopicPartition
for (PartitionInfo partitionInfo : partitionsFor) {
TopicPartition topicPartition = new TopicPartition(partitionInfo.topic(), partitionInfo.partition());
topicPartitions.add(topicPartition);
}
// 查询logSize
Map<TopicPartition, Long> endOffsets = consumer.endOffsets(topicPartitions);
for (Entry<TopicPartition, Long> entry : endOffsets.entrySet()) {
TopicPartition partitionInfo = entry.getKey();
// 获取offset
String offsetPath = MessageFormat.format("/consumers/{0}/offsets/{1}/{2}", groupId, partitionInfo.topic(),
partitionInfo.partition());
byte[] data = zk.getData(offsetPath, false, null);
long offset = Long.valueOf(new String(data));
Map<String, Object> topicPatitionMap = new HashMap<>();
topicPatitionMap.put("group", groupId);
topicPatitionMap.put("topic", partitionInfo.topic());
topicPatitionMap.put("partition", partitionInfo.partition());
topicPatitionMap.put("logSize", endOffsets.get(partitionInfo));
topicPatitionMap.put("offset", offset);
topicPatitionMap.put("lag", endOffsets.get(partitionInfo) - offset);
topicPatitionMapList.add(topicPatitionMap);
}
}
consumer.close();
if (sorted) {
Collections.sort(topicPatitionMapList, new Comparator<Map<String, Object>>() {
@Override
public int compare(Map<String, Object> o1, Map<String, Object> o2) {
if (o1.get("topic").equals(o2.get("topic"))) {
return ((Integer) o1.get("partition")).compareTo((Integer) o2.get("partition"));
}
return ((String) o1.get("topic")).compareTo((String) o2.get("topic"));
}
});
}
return topicPatitionMapList;
}
}
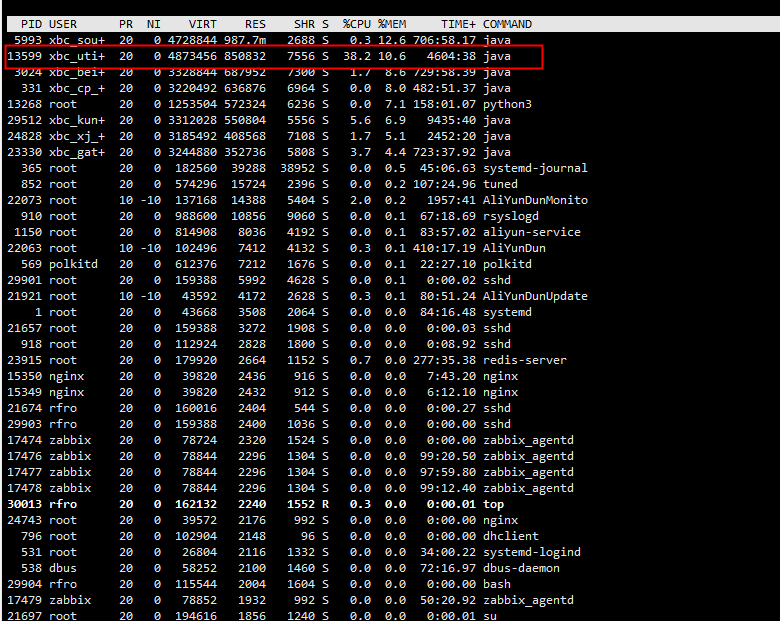
dump文件分析,heap.hprof
使用工具有Jrofiler,MAT等,发现火焰图中类对象过大
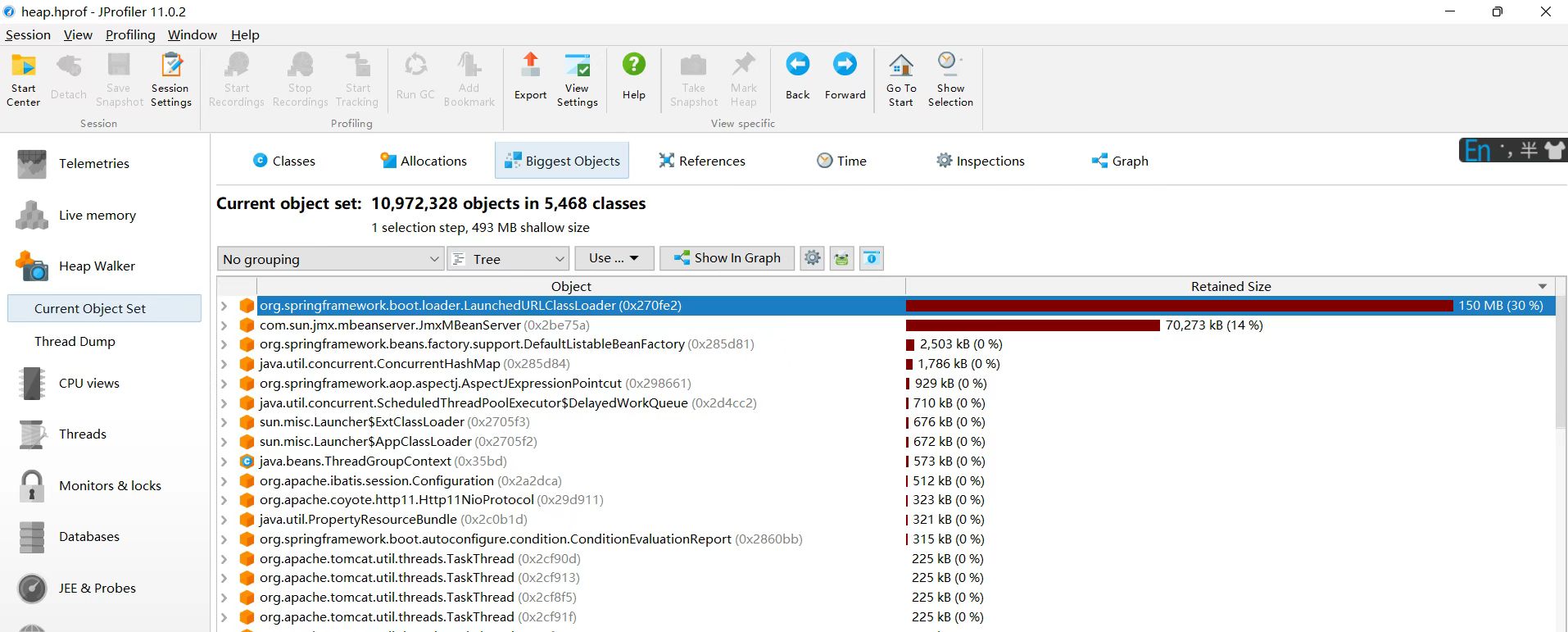
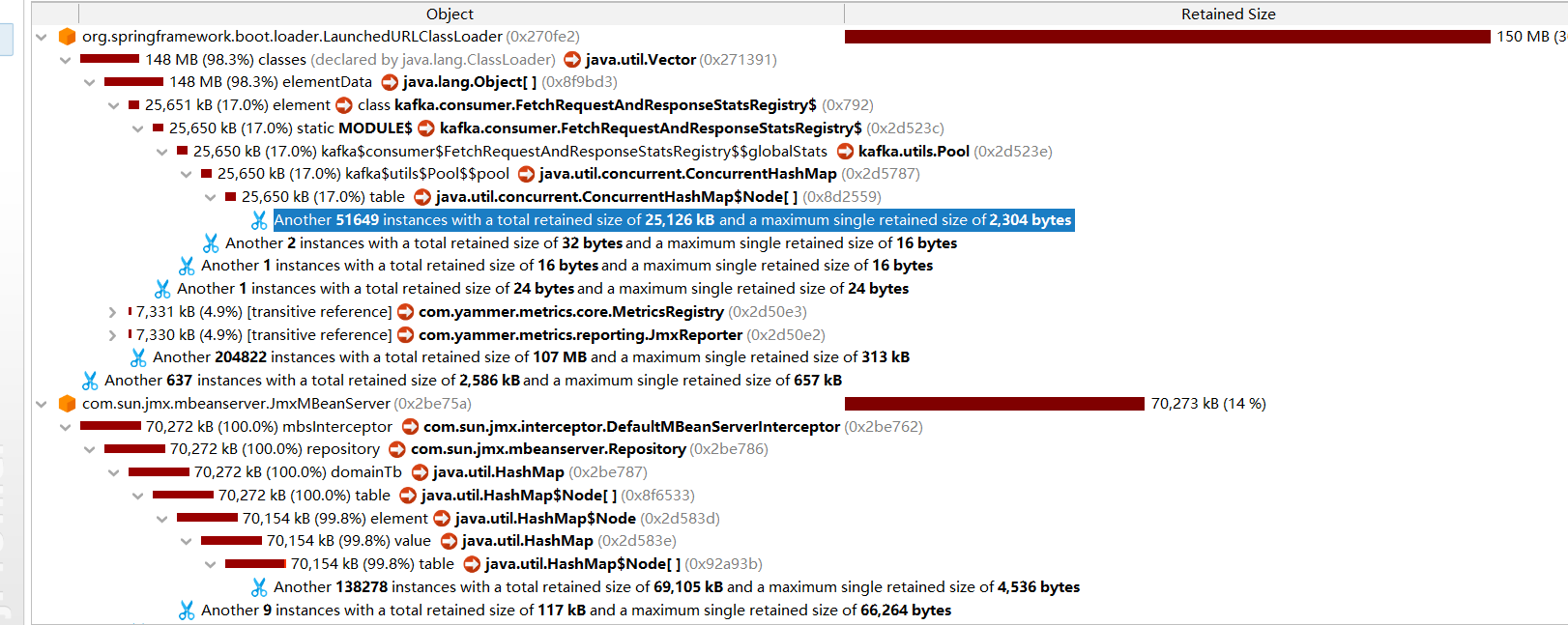
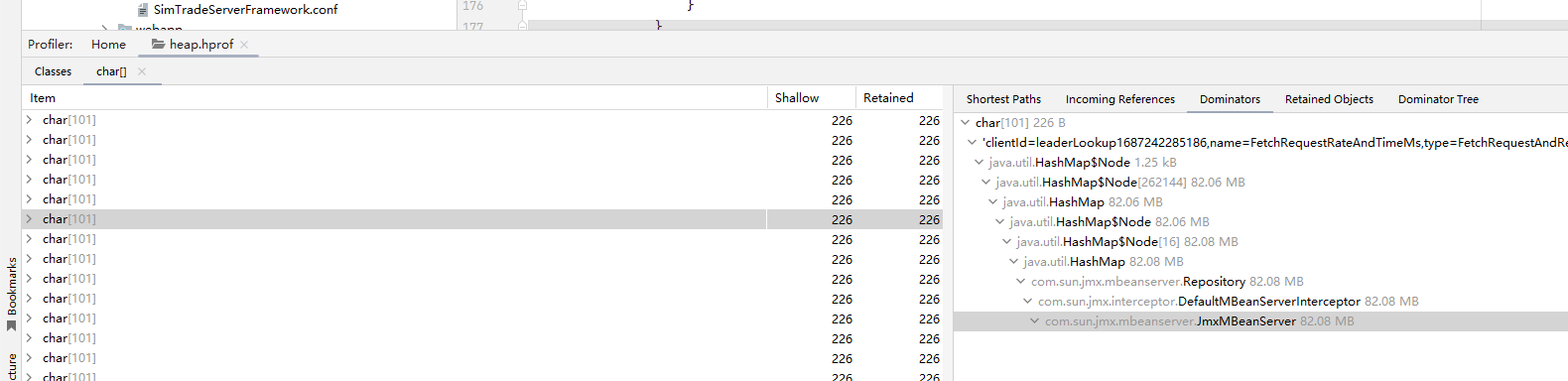
Kafka的统计注册表占用了17%的堆内存
每个SimpleConsumer都会创建统计对象
由于连接没有正确关闭,这些统计对象无法被回收
Kafka客户端会注册JMX MBean,如果连接不关闭,这些MBean会一直积累。
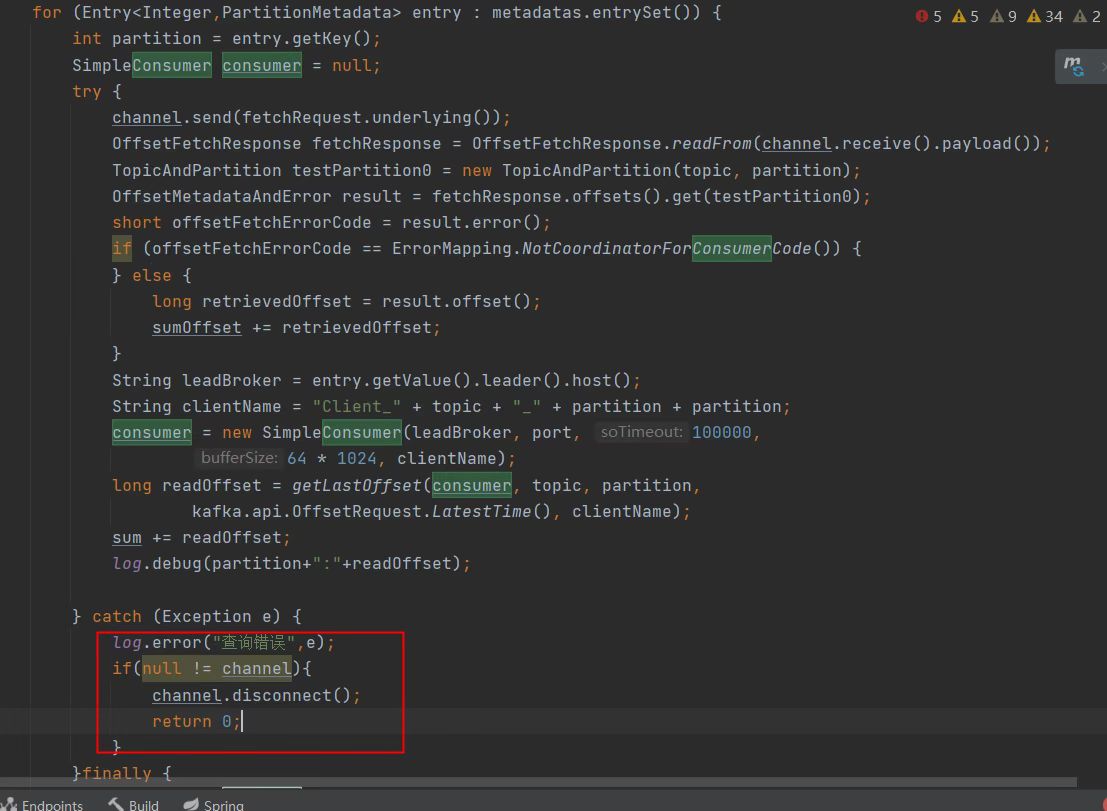
连接泄露的具体问题
getKafkaLag 方法中的泄露
public static OffsetVo getKafkaLag(String topic, String broker, int port, String group) {
BlockingChannel channel = null;
SimpleConsumer consumer = null; // 这个consumer在循环中重复创建
try {
// ...
for (Entry<Integer, PartitionMetadata> entry : metadatas.entrySet()) {
int partition = entry.getKey();
// 每次循环都创建新的SimpleConsumer,但只关闭最后一个!
consumer = new SimpleConsumer(broker, port, 100000, 64 * 1024, clientName);
long readOffset = getLastOffset(consumer, topic, partition,
kafka.api.OffsetRequest.LatestTime(), clientName);
// 这里应该立即关闭consumer,或者收集起来统一关闭
}
} finally {
// 只关闭最后一个consumer,前面的都泄露了!
if (consumer != null) {
consumer.close();
}
}
}
解决办法使用
List<SimpleConsumer> allConsumers = new ArrayList<>();
try {
for (Entry<Integer, PartitionMetadata> entry : metadatas.entrySet()) {
SimpleConsumer consumer = new SimpleConsumer(broker, port, 100000, 64 * 1024, clientName);
allConsumers.add(consumer); // 收集所有consumer
// 使用consumer...
}
} finally {
// 关闭所有consumer
for (SimpleConsumer consumer : allConsumers) {
try {
if (consumer != null) consumer.close();
} catch (Exception e) {
log.warn("关闭consumer失败", e);
}
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号