爬虫
爬虫
1.xpath的使用定位标签
-
索引的定位[]
tree.xpath('//li[index]')定位Li标签下的第一个,xpath是从1开始定位的 -
属性定位
tree.xpath('//div[@class="song"]') 先定位标签为div再定位属性class=song -
标签定位
tree.xpath('//head') tree.xpath('/html/head') 标签的定位如果是/开头表示从根标签开始定位,如果是//则表示为任意位置开始 -
模糊定位
tree.xpath('div[contains(@class,"ng")]') 先定为标签div,然后div中属性class中包含ng的标签 tree。xpath('div[starts-with(@class,"ta"]') 表示为div标签中属性class以他开头的标签
2.xpath中属性的提取
-
提取标签中的文本内容
tree.xpath('//a[@id="feng"]/text()')取直系的文本内容 //text()所有的文本内容-
提取标签中属性的内容
tree.xpath('//a[@id="feng"]/@href')
-
-
requests中的高级用法,更换cookie
import requests from lxml import etree kv={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.98 Safari/537.36 LBBROWSER"} sess=requests.session() url='https://xueqiu.com/' sess.get(url=url,headers=kv) url="https://xueqiu.com/statuses/hot/listV2.json?since_id=-1&max_id=55593&size=15" respones=sess.get(url=url,headers=kv).json() print(respones)
3.问题
再发送大量的请求的时候,经常会报出这样的一个错误:httpconnectionpoll
原因:
1. 每次数据传输前客户端和服务端会建立tcp连接,为了节省连接消耗默认为长连接keep——alive,即连接一次,传输多次
2. IP被封(可以使用代理IP池解决)
3. 请求的次数过多
解决的办法:
- 更换请求的ip
- 将请求头headers中的connection的值设置为close,表示请求成功后断开
headers={
'connection':"close"
}
- 每次请求之间用sleep进行间隔
4.爬虫的始终反爬机制
-
模拟登陆中涉及的反爬:
-
验证码
-
验证码的识别:
-
云打码
-
超级鹰
1.
2.下载实例文档
3.编辑示例代码
#!/usr/bin/env python # coding:utf-8 import requests from hashlib import md5 class Chaojiying_Client(object): def __init__(self, username, password, soft_id): self.username = username password = password.encode('utf8') self.password = md5(password).hexdigest() self.soft_id = soft_id self.base_params = { 'user': self.username, 'pass2': self.password, 'softid': self.soft_id, } self.headers = { 'Connection': 'Keep-Alive', 'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)', } def PostPic(self, im, codetype): """ im: 图片字节 codetype: 题目类型 参考 http://www.chaojiying.com/price.html """ params = { 'codetype': codetype, } params.update(self.base_params) files = {'userfile': ('ccc.jpg', im)} r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers) return r.json() def ReportError(self, im_id): """ im_id:报错题目的图片ID """ params = { 'id': im_id, } params.update(self.base_params) r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers) return r.json() def transform_code_img(imgpath,imgtype): chaojiying = Chaojiying_Client('超级鹰用户名', '超级鹰用户名的密码', '96001') #用户中心>>软件ID 生成一个替换 96001 im = open(imgpath, 'rb').read() #本地图片文件路径 来替换 a.jpg 有时WIN系统须要// return chaojiying.PostPic(im, imgtype)['pic_str'] -
打码兔
-
-
-
动态变化的请求参数
-
cookie
-
-
UA
-
robots
-
动态加载
-
图片的懒加载
-
代理
-
js加密
-
js混淆
![]()

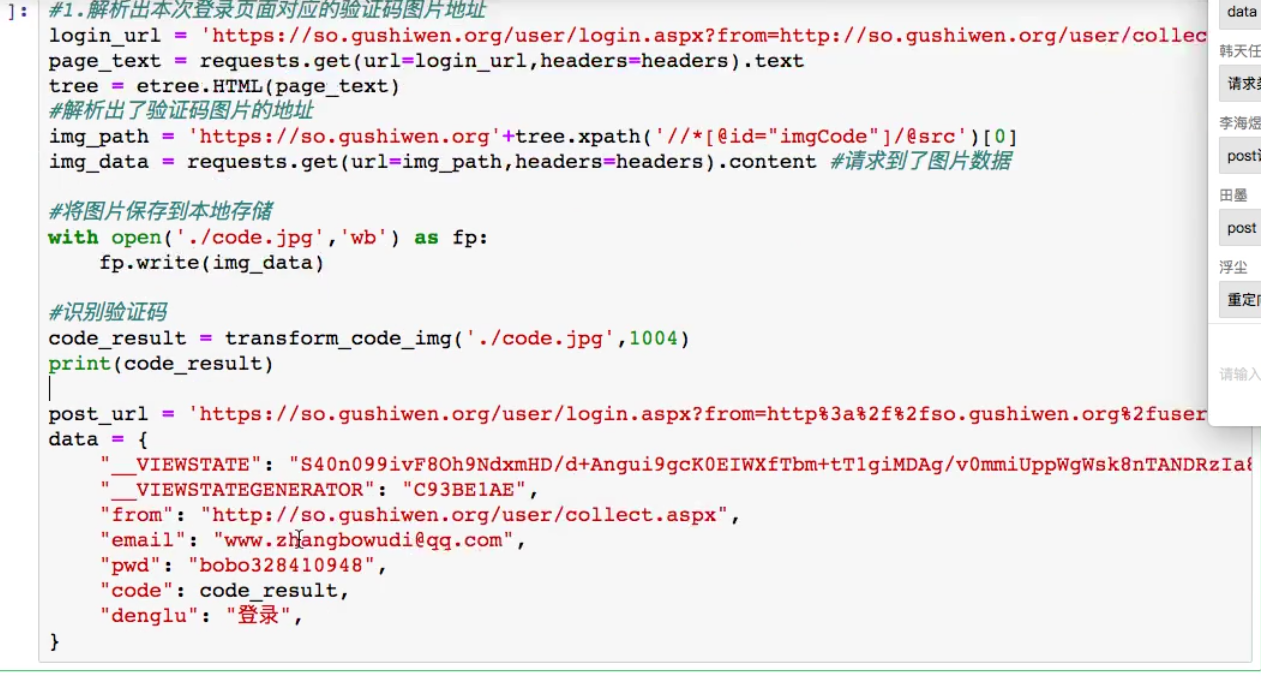
5.示例

 浙公网安备 33010602011771号
浙公网安备 33010602011771号