
spark连接mysql数据库
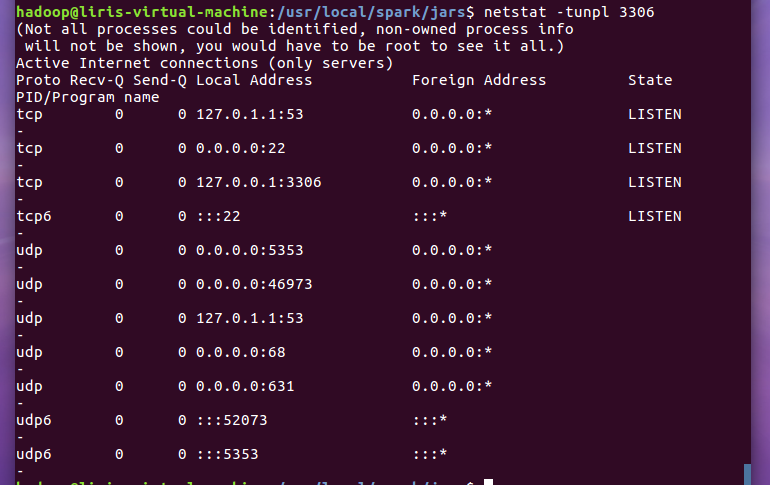
1.安装启动检查Mysql服务。
netstat -tunlp (3306)
2.spark 连接mysql驱动程序。
–cp /usr/local/hive/lib/mysql-connector-java-5.1.40-bin.jar /usr/local/spark/jars

3.启动 Mysql shell,新建数据库spark,表student。
select * from student;
create database spark; use spark; create table student (id int(4), name char(20), gender char(4), age int(4)); insert into student values(1,'Xueqian','F',23); insert into student values(2,'Weiliang','M',24); select * from student;

4.spark读取MySQL数据库中的数据
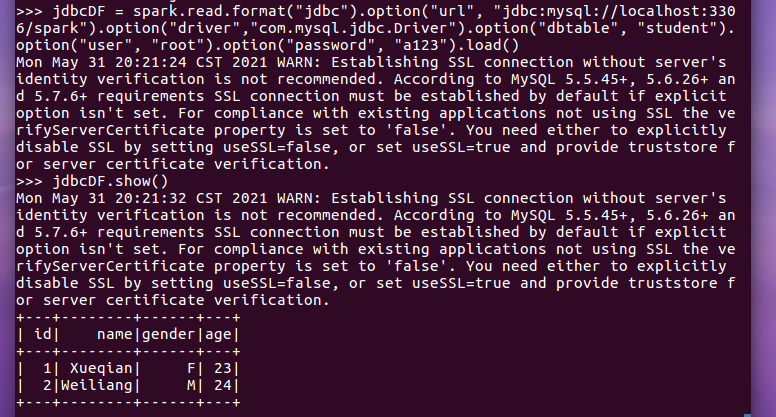
spark.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306/spark?useSSL=false") ... .load()
jdbcDF = spark.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306/spark").option("driver","com.mysql.jdbc.Driver").option("dbtable", "student").option("user", "root").option("password", "a123").load()
jdbcDF.show()
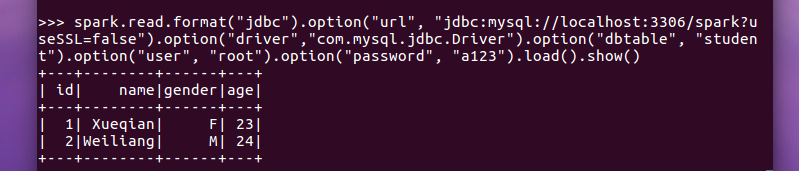
spark.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306/spark?useSSL=false").option("driver","com.mysql.jdbc.Driver").option("dbtable", "student").option("user", "root").option("password", "a123").load().show()
5.spark向MySQL数据库写入数据
studentDF.write.format(‘jdbc’).option(…).mode(‘append’).save()
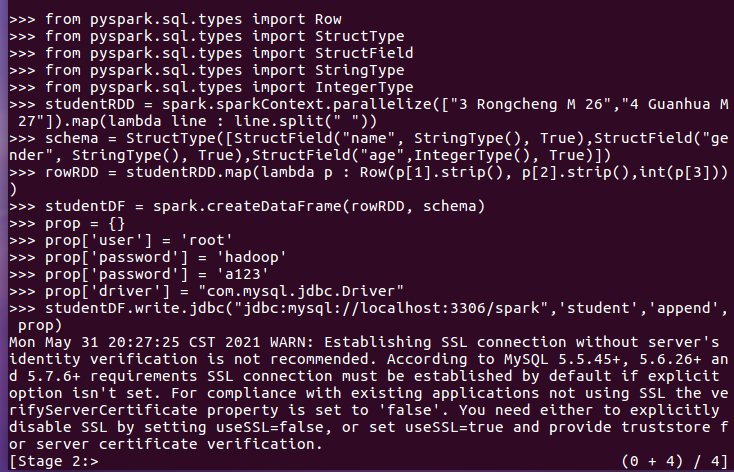
from pyspark.sql.types import Row
from pyspark.sql.types import StructType
from pyspark.sql.types import StructField
from pyspark.sql.types import StringType
from pyspark.sql.types import IntegerType
studentRDD = spark.sparkContext.parallelize(["3 Rongcheng M 26","4 Guanhua M 27"]).map(lambda line : line.split(" "))
schema = StructType([StructField("name", StringType(), True),StructField("gender", StringType(), True),StructField("age",IntegerType(), True)])
rowRDD = studentRDD.map(lambda p : Row(p[1].strip(), p[2].strip(),int(p[3])))
studentDF = spark.createDataFrame(rowRDD, schema)
prop = {}
prop['user'] = 'root'
prop['password'] = 'a123'
prop['driver'] = "com.mysql.jdbc.Driver"
studentDF.write.jdbc("jdbc:mysql://localhost:3306/spark",'student','append', prop)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号