

爬虫系列(十) 用requests和xpath爬取豆瓣电影
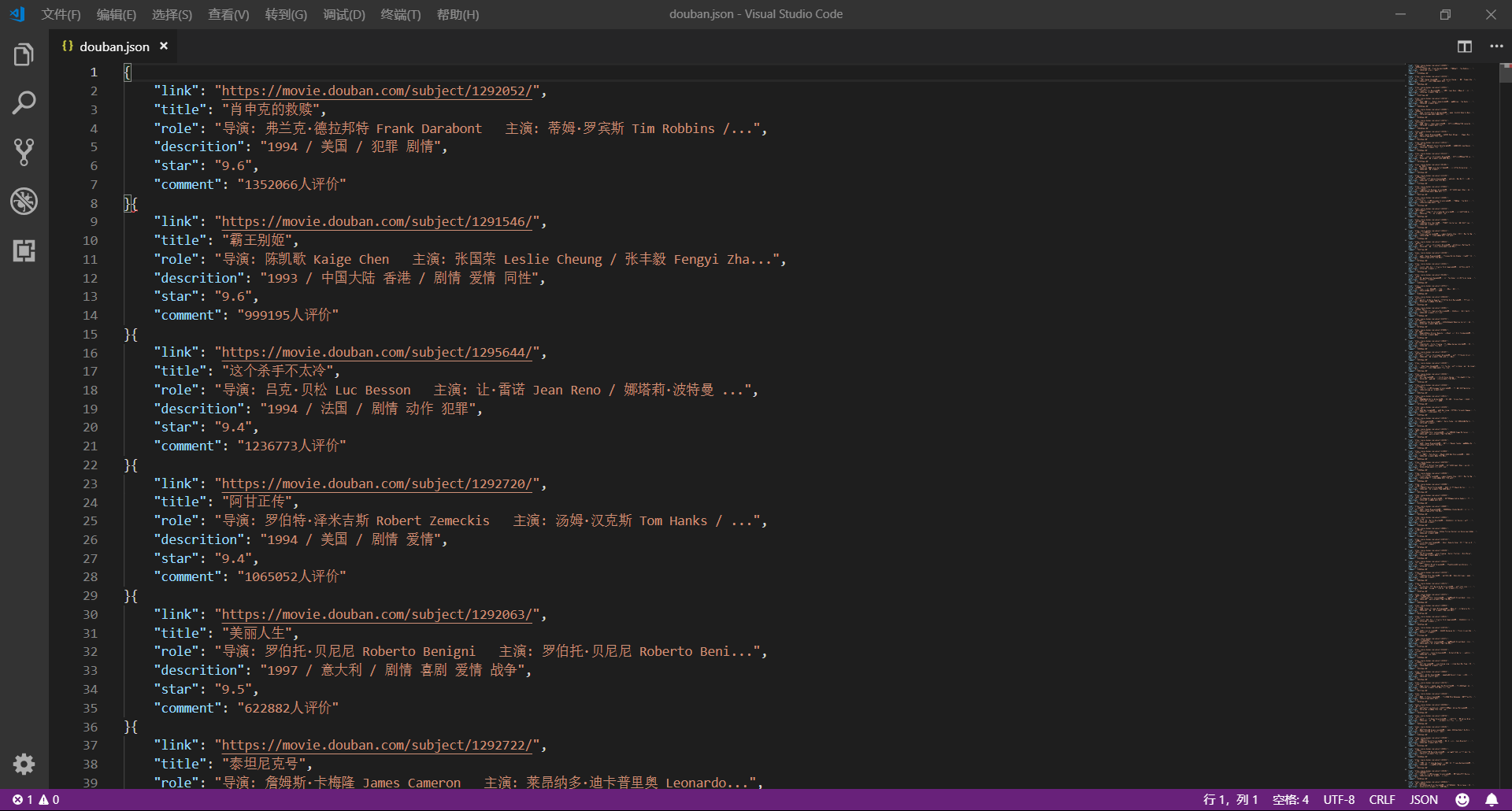
这篇文章我们将使用 requests 和 xpath 爬取豆瓣电影 Top250,下面先贴上最终的效果图:
1、网页分析
(1)分析 URL 规律
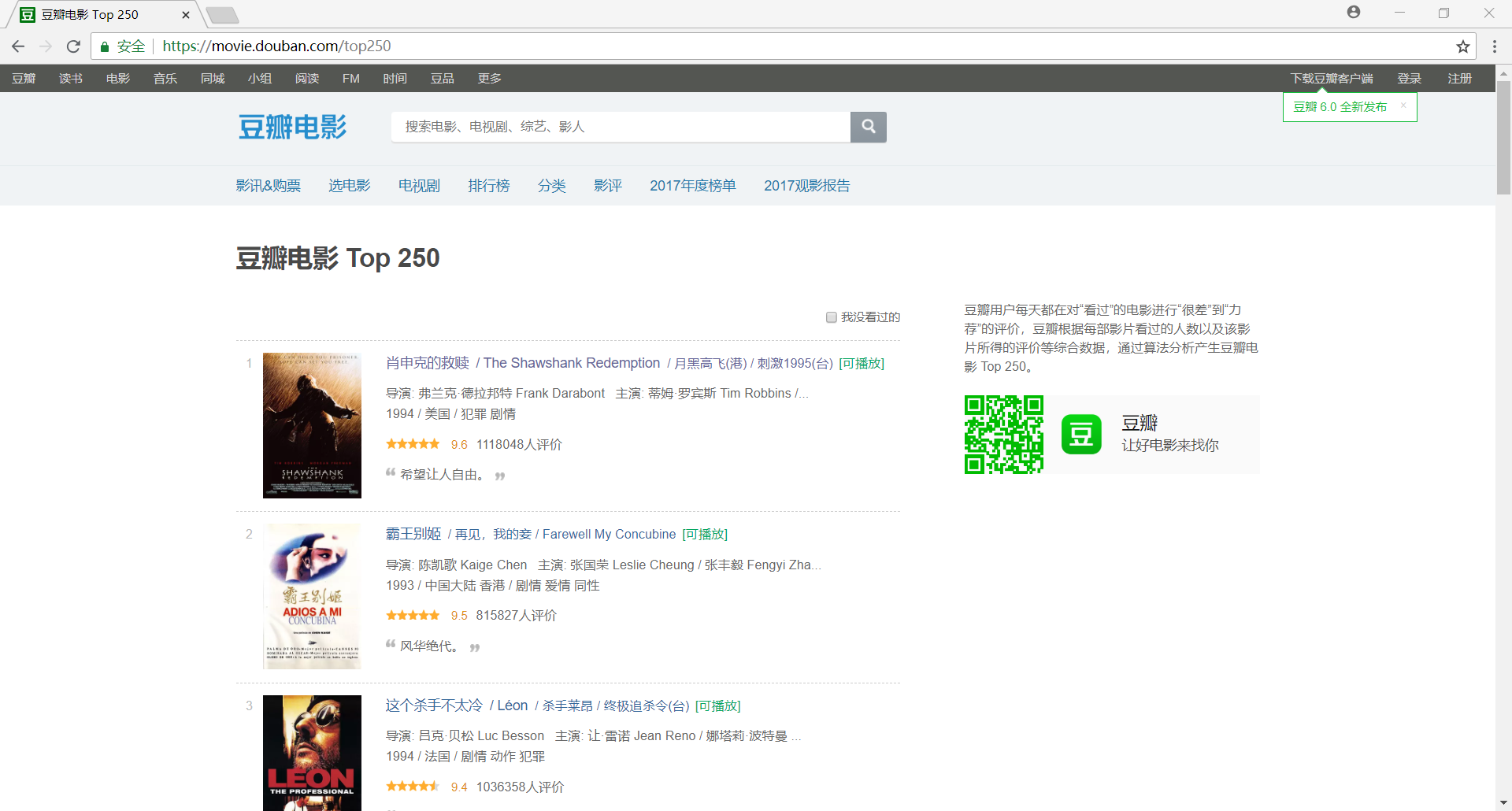
我们首先使用 Chrome 浏览器打开 豆瓣电影 Top250,很容易可以判断出网站是一个静态网页
然后我们分析网站的 URL 规律,以便于通过构造 URL 获取网站中所有网页的内容
首页:https://movie.douban.com/top250
第二页:https://movie.douban.com/top250?start=25&filter=
第三页:https://movie.douban.com/top250?start=50&filter=
...
不难发现,URL 可以泛化为 https://movie.douban.com/top250?start={page}&filter=,其中,page 代表页数
最后我们还需要验证一下首页的 URL 是否也满足规律,经过验证,很容易可以发现首页的 URL 也满足上面的规律
核心代码如下:
import requests
# 获取网页源代码
def get_page(url):
# 构造请求头部
headers = {
'USER-AGENT':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
# 发送请求,获得响应
response = requests.get(url=url,headers=headers)
# 获得网页源代码
html = response.text
# 返回网页源代码
return html
(2)分析内容规律
接下来我们开始分析每一个网页的内容,并从中提取出需要的数据
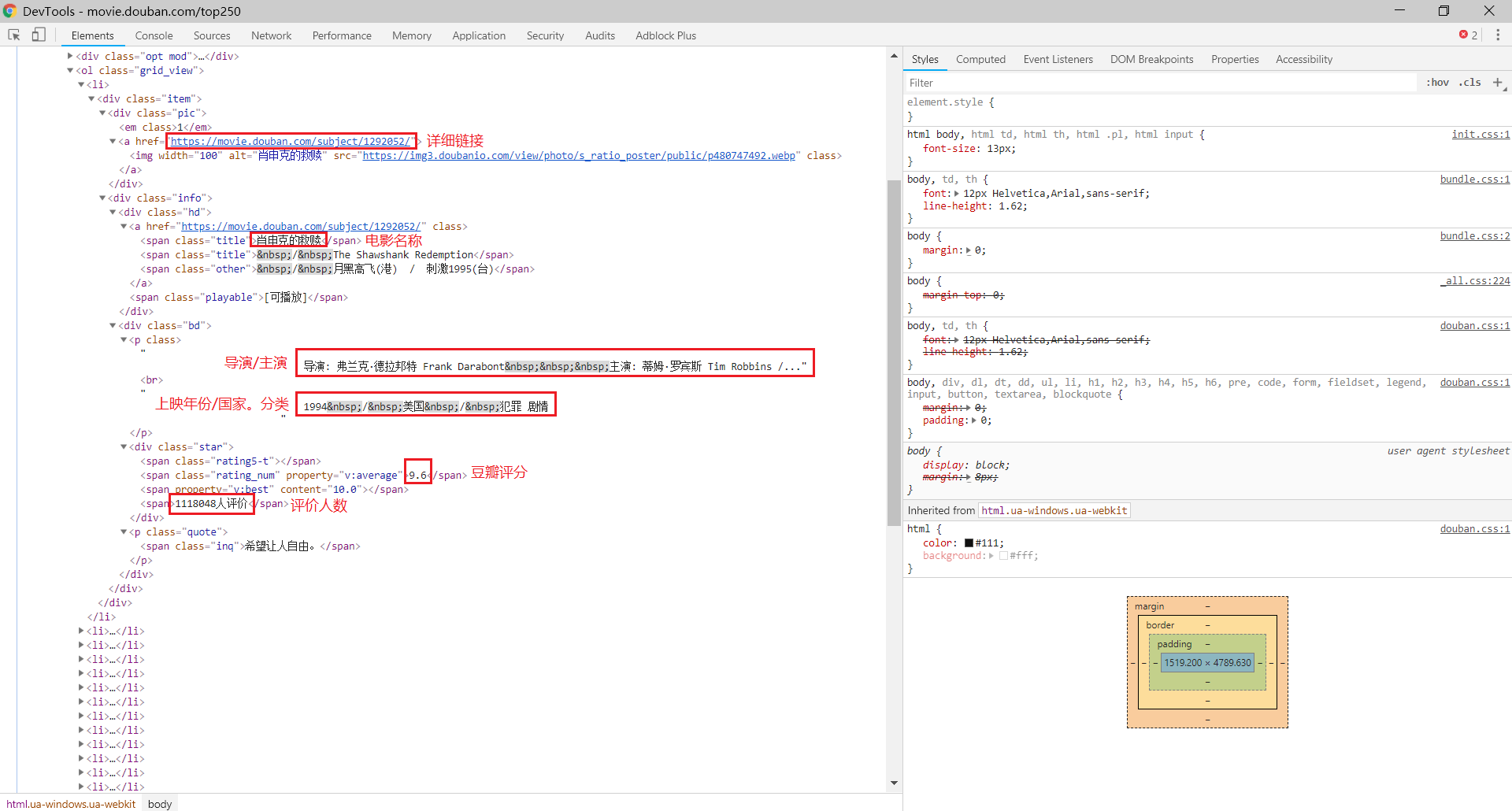
使用快捷键 Ctrl+Shift+I 打开开发者工具,选中 Elements 选项栏分析网页的源代码
需要提取的数据包括(可以使用 xpath 进行匹配):
- 详细链接:
html.xpath('//div[@class="hd"]/a/@href') - 电影名称:
html.xpath('//div[@class="hd"]/a/span[1]/text()') - 导演/主演、上映年份/国家/分类:
html.xpath('//div[@class="bd"]/p[1]//text()') - 豆瓣评分:
html.xpath('//div[@class="bd"]/div/span[2]/text()') - 评价人数:
html.xpath('//div[@class="bd"]/div/span[4]/text()')
核心代码如下:
from lxml import etree
# 解析网页源代码
def parse_page(html):
# 构造 _Element 对象
html_elem = etree.HTML(html)
# 详细链接
links = html_elem.xpath('//div[@class="hd"]/a/@href')
# 电影名称
titles = html_elem.xpath('//div[@class="hd"]/a/span[1]/text()')
# 电影信息(导演/主演、上映年份/国家/分类)
infos = html_elem.xpath('//div[@class="bd"]/p[1]//text()')
roles = [j for i,j in enumerate(infos) if i % 2 == 0]
descritions = [j for i,j in enumerate(infos) if i % 2 != 0]
# 豆瓣评分
stars = html_elem.xpath('//div[@class="bd"]/div/span[2]/text()')
# 评论人数
comments = html_elem.xpath('//div[@class="bd"]/div/span[4]/text()')
# 获得结果
data = zip(links,titles,roles,descritions,stars,comments)
# 返回结果
return data
(3)保存数据
下面将数据分别保存为 txt 文件、json 文件和 csv 文件
import json
import csv
# 打开文件
def openfile(fm):
fd = None
if fm == 'txt':
fd = open('douban.txt','w',encoding='utf-8')
elif fm == 'json':
fd = open('douban.json','w',encoding='utf-8')
elif fm == 'csv':
fd = open('douban.csv','w',encoding='utf-8',newline='')
return fd
# 将数据保存到文件
def save2file(fm,fd,data):
if fm == 'txt':
for item in data:
fd.write('----------------------------------------\n')
fd.write('link:' + str(item[0]) + '\n')
fd.write('title:' + str(item[1]) + '\n')
fd.write('role:' + str(item[2]) + '\n')
fd.write('descrition:' + str(item[3]) + '\n')
fd.write('star:' + str(item[4]) + '\n')
fd.write('comment:' + str(item[5]) + '\n')
if fm == 'json':
temp = ('link','title','role','descrition','star','comment')
for item in data:
json.dump(dict(zip(temp,item)),fd,ensure_ascii=False)
if fm == 'csv':
writer = csv.writer(fd)
for item in data:
writer.writerow(item)
2、编码实现
下面是完整代码,也是几十行可以写完
import requests
from lxml import etree
import json
import csv
import time
import random
# 获取网页源代码
def get_page(url):
headers = {
'USER-AGENT':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
response = requests.get(url=url,headers=headers)
html = response.text
return html
# 解析网页源代码
def parse_page(html):
html_elem = etree.HTML(html)
links = html_elem.xpath('//div[@class="hd"]/a/@href')
titles = html_elem.xpath('//div[@class="hd"]/a/span[1]/text()')
infos = html_elem.xpath('//div[@class="bd"]/p[1]//text()')
roles = [j.strip() for i,j in enumerate(infos) if i % 2 == 0]
descritions = [j.strip() for i,j in enumerate(infos) if i % 2 != 0]
stars = html_elem.xpath('//div[@class="bd"]/div/span[2]/text()')
comments = html_elem.xpath('//div[@class="bd"]/div/span[4]/text()')
data = zip(links,titles,roles,descritions,stars,comments)
return data
# 打开文件
def openfile(fm):
fd = None
if fm == 'txt':
fd = open('douban.txt','w',encoding='utf-8')
elif fm == 'json':
fd = open('douban.json','w',encoding='utf-8')
elif fm == 'csv':
fd = open('douban.csv','w',encoding='utf-8',newline='')
return fd
# 将数据保存到文件
def save2file(fm,fd,data):
if fm == 'txt':
for item in data:
fd.write('----------------------------------------\n')
fd.write('link:' + str(item[0]) + '\n')
fd.write('title:' + str(item[1]) + '\n')
fd.write('role:' + str(item[2]) + '\n')
fd.write('descrition:' + str(item[3]) + '\n')
fd.write('star:' + str(item[4]) + '\n')
fd.write('comment:' + str(item[5]) + '\n')
if fm == 'json':
temp = ('link','title','role','descrition','star','comment')
for item in data:
json.dump(dict(zip(temp,item)),fd,ensure_ascii=False)
if fm == 'csv':
writer = csv.writer(fd)
for item in data:
writer.writerow(item)
# 开始爬取网页
def crawl():
url = 'https://movie.douban.com/top250?start={page}&filter='
fm = input('请输入文件保存格式(txt、json、csv):')
while fm!='txt' and fm!='json' and fm!='csv':
fm = input('输入错误,请重新输入文件保存格式(txt、json、csv):')
fd = openfile(fm)
print('开始爬取')
for page in range(0,250,25):
print('正在爬取第 ' + str(page+1) + ' 页至第 ' + str(page+25) + ' 页......')
html = get_page(url.format(page=str(page)))
data = parse_page(html)
save2file(fm,fd,data)
time.sleep(random.random())
fd.close()
print('结束爬取')
if __name__ == '__main__':
crawl()
2020.06.25 补充
最近因为项目需要,也爬取了一下豆瓣读书,思路和爬取豆瓣电影差不多,这里也把代码贴出来,供大家参考
import requests
from lxml import etree
from string import Template
import time
import random
import json
import re
def get_page(url):
headers = {
'USER-AGENT':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
response = requests.get(url = url, headers = headers)
html = response.text
return html
def parse_page(html):
html_elem = etree.HTML(html)
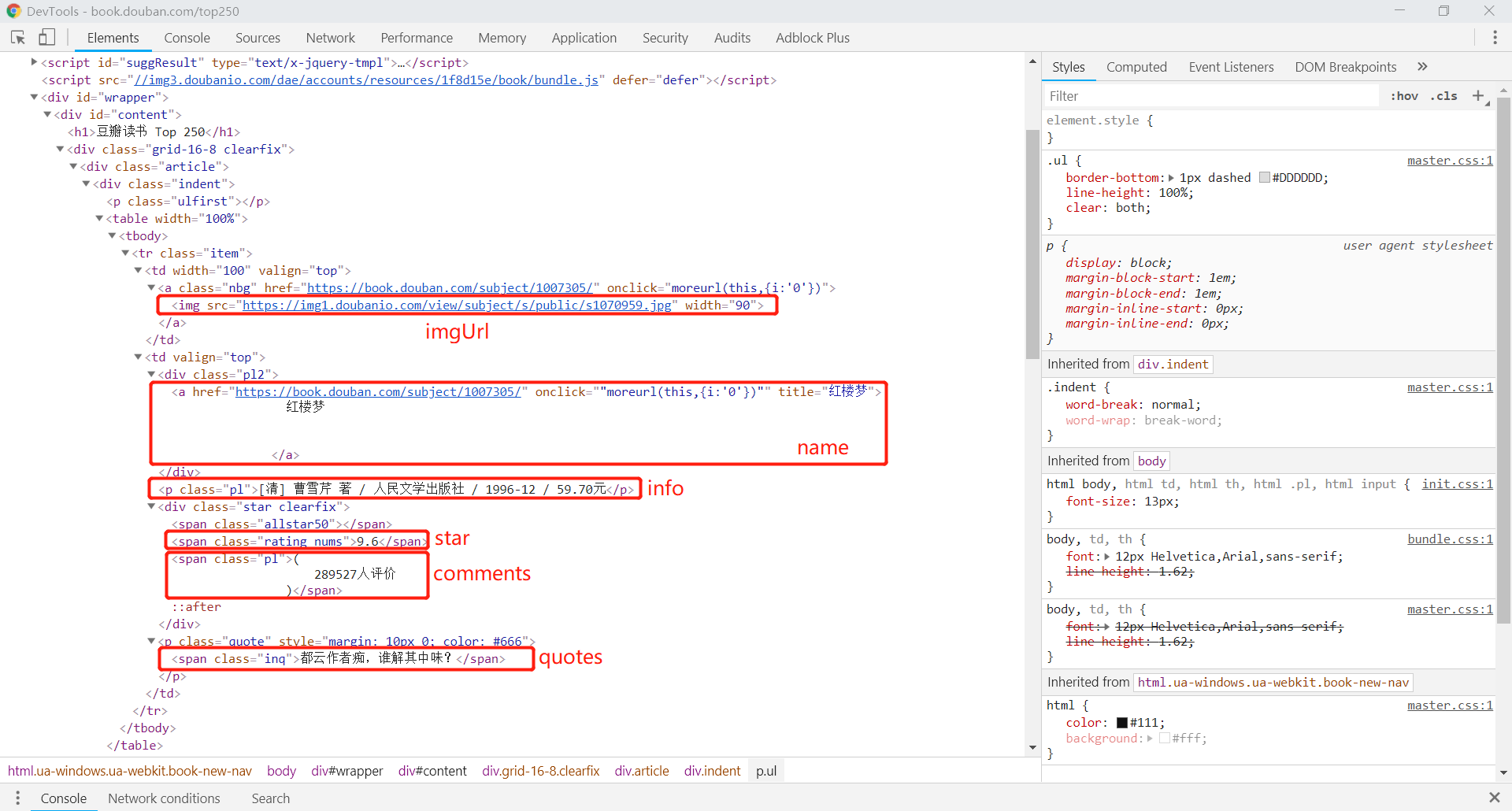
# 封面
imgUrl = html_elem.xpath('//tr[@class="item"]/td[1]/a/img/@src')
# 书名
name = html_elem.xpath('//tr[@class="item"]/td[2]/div[@class="pl2"]/a/@title')
# 介绍
info = html_elem.xpath('//tr[@class="item"]/td[2]/p[@class="pl"]/text()')
# 评价
star = html_elem.xpath('//div[contains(@class, "star")]/span[@class="rating_nums"]/text()')
# 评论人数
comments = html_elem.xpath('//div[contains(@class, "star")]/span[@class="pl"]/text()')
# 摘要
quotes = html_elem.xpath('//span[@class="inq"]/text()')
# 将介绍拆分为:作者、译者、价格、出版日期、出版社
author, translator, price, pubdate, press = [], [], [], [], []
for item in info:
splits = item.split('/')
splits = [item.strip() for item in splits]
# 特判
if item == '[英] 阿·柯南道尔 / 丁钟华 等 / 群众出版社 / 1981-8 / 53.00元/68.00元':
author.append(splits[0])
translator.append(splits[1])
press.append(splits[2])
pubdate.append(splits[3])
price.append(splits[4])
# 特判
elif item == 'S.A.阿列克谢耶维奇 / 方祖芳 / 花城出版社/铁葫芦图书 / 2014-6-15 / 34.80元':
author.append(splits[0])
translator.append(splits[1])
press.append(splits[2])
pubdate.append(splits[4])
price.append(splits[5])
# 常规处理
else:
author.append(splits[0])
translator.append('' if len(splits) == 4 else splits[1])
price.append(splits[-1])
pubdate.append(splits[-2])
press.append(splits[-3])
# 匹配整数和浮点数
pattern = r'[+-]?([0-9]*\.?[0-9]+|[0-9]+\.?[0-9]*)([eE][+-]?[0-9]+)?'
star = [float(re.search(pattern, item).group()) for item in star]
comments = [int(re.search(pattern, item.lstrip('(').rstrip(')').strip()).group()) for item in comments]
price = [float(re.search(pattern, item).group()) for item in price]
data = list(zip(imgUrl, name, star, comments, quotes, author, translator, price, pubdate, press))
return data
def save2file(data):
meta = ('imgUrl', 'name', 'star', 'comments', 'quotes', 'author', 'translator', 'price', 'pubdate', 'press')
wrapper = [dict(zip(meta, item)) for item in data]
fd = open('douban.json', 'w', encoding = 'utf-8')
json.dump(wrapper, fd, ensure_ascii = False)
fd.close()
def crawl():
# 网址模板,其参数待替换
init_url = Template('https://book.douban.com/top250?start=$page')
# 所有数据
all_data = []
# 遍历网页
for page in range(0, 250, 25):
# 当前网址
curr_url = init_url.substitute(page = str(page))
# 获取页面
html = get_page(curr_url)
# 解析页面
data = parse_page(html)
# 将每一个页面的数据存起来
all_data.extend(data)
# 随机睡眠
time.sleep(random.random())
# 一次性将所有数据写入文件
save2file(all_data)
if __name__ == '__main__':
crawl()
- 网页分析
- 最终结果
【爬虫系列相关文章】
版权声明:本博客属于个人维护博客,未经博主允许不得转载其中文章。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号