
数据采集技术 - 第三次作业:Scrapy框架与数据库存储
作业①
1)、图片爬取实验
1. 实验描述
指定一个网站(以中国气象网为例),爬取该网站下的所有图片。
难点:需分别实现单线程和多线程两种方式,并控制总下载数量不超过学号后3位(130张)。
2. 核心代码
(1) 单线程爬取的实现
首先做的是单线程版本。我的思路是先用 requests 库把网页源代码拿下来,然后BeautifulSoup 去找所有的 img 标签。为了满足作业要求的“下载数量限制”,我在遍历图片的时候加了一个计数器 current_count。每成功下载一张图,计数器就加 1,一旦数量达到了 130(我的学号后三位),程序就会打印提示并直接退出循环,这样就不会超标了。另外,我在请求头里加了 User-Agent 伪装成浏览器,不然有些网站不给爬。
import os
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
STUDENT_ID = '102302130'
MAX_IMAGES = int(STUDENT_ID[-3:]) # 限制 130 张
TARGET_URL = '[http://www.weather.com.cn/](http://www.weather.com.cn/)'
SAVE_DIR = 'images'
def main():
# 创建文件夹
if not os.path.exists(SAVE_DIR):
os.makedirs(SAVE_DIR)
# 设置请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
# 请求网页
response = requests.get(TARGET_URL, headers=headers, verify=False)
response.encoding = 'utf-8'
# 解析网页
soup = BeautifulSoup(response.text, 'html.parser')
img_tags = soup.find_all('img')
current_count = 0
for index, img in enumerate(img_tags):
# 实时检查是否达到限制
if current_count >= MAX_IMAGES:
print(f"【限制触发】已达到学号限制的 {MAX_IMAGES} 张图片,停止下载。")
break
src = img.get('src')
if src:
full_url = urljoin(TARGET_URL, src)
if not full_url.startswith('http'): continue
# 简单的文件命名
ext = os.path.splitext(full_url)[-1]
if not ext or len(ext) > 5: ext = '.jpg'
file_name = f"image_{index}{ext}"
# 下载图片
res = requests.get(full_url, headers=headers, timeout=10, verify=False)
if res.status_code == 200:
with open(os.path.join(SAVE_DIR, file_name), 'wb') as f:
f.write(res.content)
print(f"[下载成功] {file_name}")
current_count += 1
(2) 多线程并发的优化
单线程跑起来确实有点慢,要等一张下完才能下下一张。所以第二步我用 ThreadPoolExecutor 搞了个多线程版本。
这次我换了个思路控制数量:与其在下载时计数,不如在开始下载前就把任务列表准备好。我先遍历所有图片链接存到 download_list 里,然后直接用切片 [:MAX_IMAGES] 把多余的砍掉,只保留前 130 个。最后把这些任务丢给线程池,让 10 个线程同时干活。
from concurrent.futures import ThreadPoolExecutor
# 构建下载任务列表
download_list = []
for index, img in enumerate(img_tags):
src = img.get('src')
if src:
full_url = urljoin(TARGET_URL, src)
if not full_url.startswith('http'): continue
ext = os.path.splitext(full_url)[-1]
if not ext or len(ext) > 5: ext = '.jpg'
file_name = f"multi_img_{index}{ext}"
download_list.append((full_url, file_name))
# 根据我的学号限制截取任务列表
if len(download_list) > MAX_IMAGES:
print(f"发现图片数量超过限制,仅下载前 {MAX_IMAGES} 张")
download_list = download_list[:MAX_IMAGES]
# 开启 10 个线程并发下载
MAX_WORKERS = 10
with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor:
executor.map(download_task, download_list)
3. 运行结果


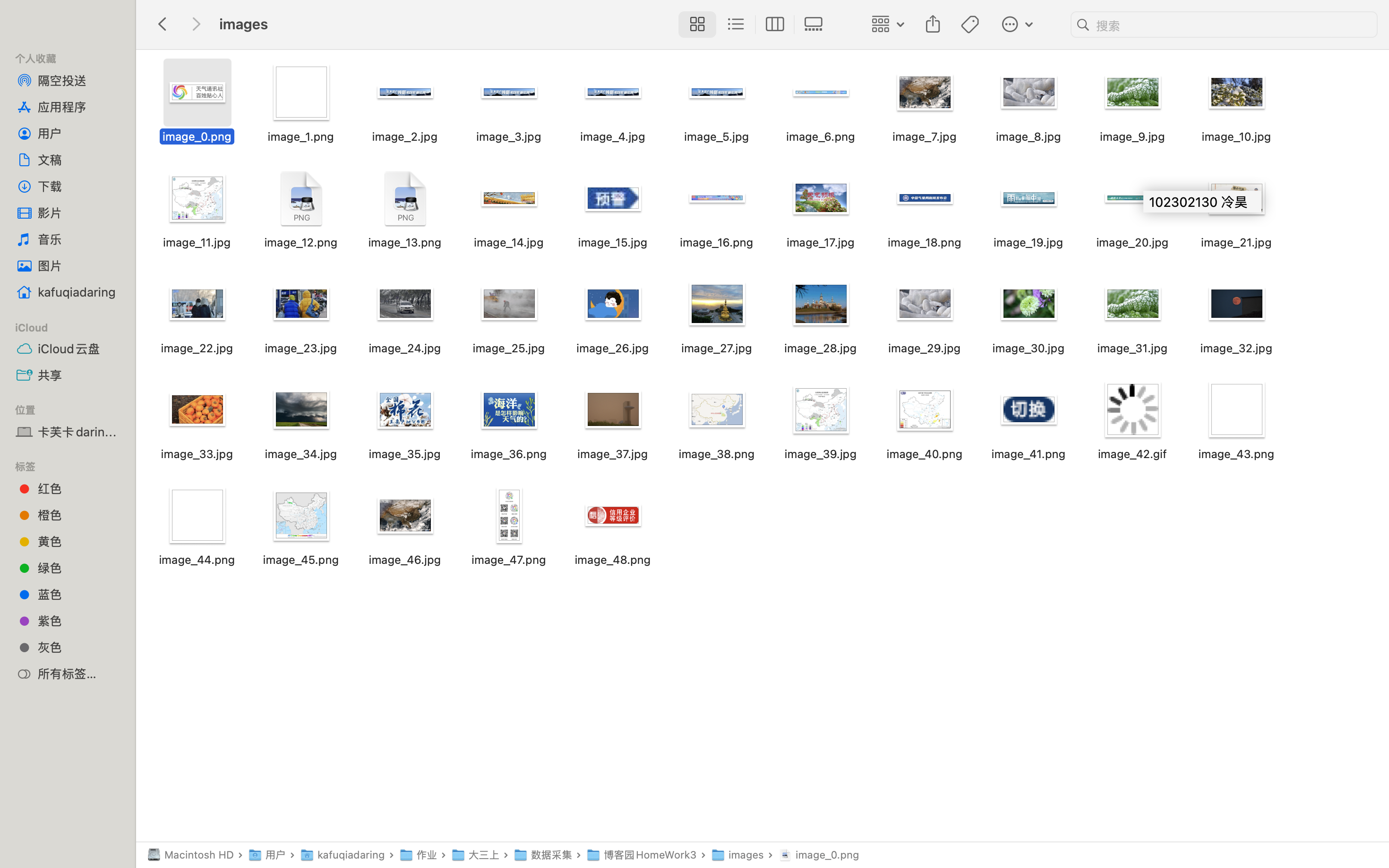


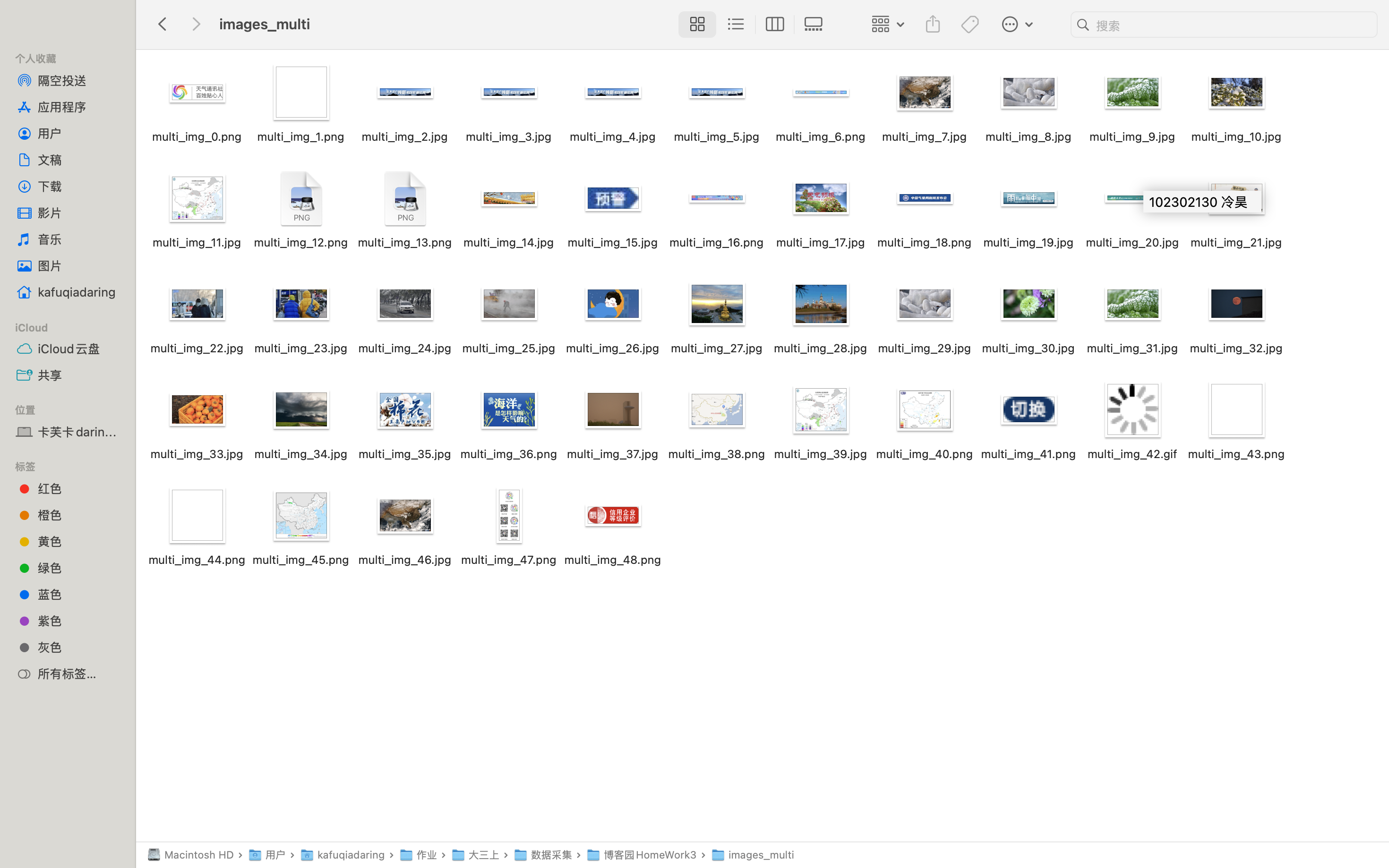
2)、心得体会
-
效率对比:做完对比实验感觉很明显。单线程就像一个人搬砖,搬完一块才能搬下一块;多线程就像请了10个人一起搬,带宽利用率高多了,速度快了一大截。
-
控制逻辑:为了满足“学号限制”这个要求,我学会了两种方法:一种是在循环里加 if 判断计数,另一种是直接对列表进行切片。感觉切片的方法更简洁一点,先把任务排好队,再让线程去跑,不容易出错。
作业②
1)、股票数据爬取实验
1. 实验描述
使用 Scrapy + MySQL 技术路线,爬取东方财富网的股票相关信息(代码、名称、最新价、涨跌幅等),并存储至本地数据库。
2. 核心代码
(1)数据结构定义 (Items)
首先我得告诉 Scrapy 我要抓哪些数据。我在 items.py 里定义了一个 StockItem 类,里面的字段(比如代码、名称、最新价、涨跌幅)跟我在数据库里建的表是一一对应的,这样后面存数据库就方便了。
import scrapy
class StockItem(scrapy.Item):
stock_code = scrapy.Field() # 股票代码
stock_name = scrapy.Field() # 股票名称
latest_price = scrapy.Field() # 最新报价
change_percent = scrapy.Field() # 涨跌幅
change_amount = scrapy.Field() # 涨跌额
volume = scrapy.Field() # 成交量
turnover = scrapy.Field() # 成交额
amplitude = scrapy.Field() # 振幅
high = scrapy.Field() # 最高
low = scrapy.Field() # 最低
open_price = scrapy.Field() # 今开
prev_close = scrapy.Field() # 昨收
(2) 爬虫逻辑 (Spider)
这里我遇到了一个坑。我一开始想用 XPath 去提取网页里的表格,结果怎么爬都是空的。后来按 F12 看了 Network 面板才发现,东方财富网的数据是通过 JS 动态加载的(Ajax),HTML 源码里根本没有股票数据。
所以我改变了策略,找到了它加载数据的真实 API 接口。这个接口返回的是 JSON 格式的数据,我只需要把外面包着的一层 jQuery 回调字符去掉,就能拿到纯净的 JSON 列表,然后遍历提取字段就行了。虽然没用到 XPath,但我觉得能分析出 API 也是解决问题的一种办法。
import scrapy
import json
from homework2.items import StockItem
class StockSpider(scrapy.Spider):
name = 'stock'
allowed_domains = ['eastmoney.com']
# 真实的 JSON 数据接口
start_urls = [
'[http://82.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124&pn=1&pz=50&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=](http://82.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124&pn=1&pz=50&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=)|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152'
]
def parse(self, response):
# 清洗 jQuery 包裹字符,提取 JSON
data_text = response.text
start_idx = data_text.find('(')
end_idx = data_text.rfind(')')
if start_idx != -1 and end_idx != -1:
json_str = data_text[start_idx+1 : end_idx]
data_json = json.loads(json_str)
if 'data' in data_json and 'diff' in data_json['data']:
for stock in data_json['data']['diff']:
item = StockItem()
item['stock_code'] = stock.get('f12')
item['stock_name'] = stock.get('f14')
# 使用简单的 if 判断进行数据处理
item['latest_price'] = self.handle_float(stock.get('f2'))
item['change_percent'] = str(stock.get('f3')) + '%'
item['change_amount'] = self.handle_float(stock.get('f4'))
item['volume'] = str(stock.get('f5'))
item['turnover'] = str(stock.get('f6'))
item['amplitude'] = str(stock.get('f7')) + '%'
item['high'] = self.handle_float(stock.get('f15'))
item['low'] = self.handle_float(stock.get('f16'))
item['open_price'] = self.handle_float(stock.get('f17'))
item['prev_close'] = self.handle_float(stock.get('f18'))
yield item
def handle_float(self, value):
# 简单处理:如果是无效值则返回 0
if value == '-' or value is None:
return 0.0
return float(value)
(3) 数据库存储 (Pipeline)
数据爬到了,最后一步是存到 MySQL。我在 pipelines.py 里写了连接数据库的逻辑,用 pymysql 库。每当 Spider yield 一个 item,这里就会执行一次 SQL 插入语句。
import pymysql
class MySQLPipeline:
def __init__(self):
self.host = 'localhost'
self.port = 3306
self.user = 'root'
self.password = 'LJ100328'
self.db = 'spider_homework'
def open_spider(self, spider):
self.conn = pymysql.connect(
host=self.host, port=self.port, user=self.user,
password=self.password, database=self.db, charset='utf8mb4'
)
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
sql = """
INSERT INTO stock_data (
stock_code, stock_name, latest_price, change_percent,
change_amount, volume, turnover, amplitude,
high, low, open_price, prev_close
) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
params = (
item.get('stock_code'), item.get('stock_name'), item.get('latest_price'),
item.get('change_percent'), item.get('change_amount'), item.get('volume'),
item.get('turnover'), item.get('amplitude'), item.get('high'),
item.get('low'), item.get('open_price'), item.get('prev_close')
)
# 直接执行插入
self.cursor.execute(sql, params)
self.conn.commit()
return item
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
3. 运行结果

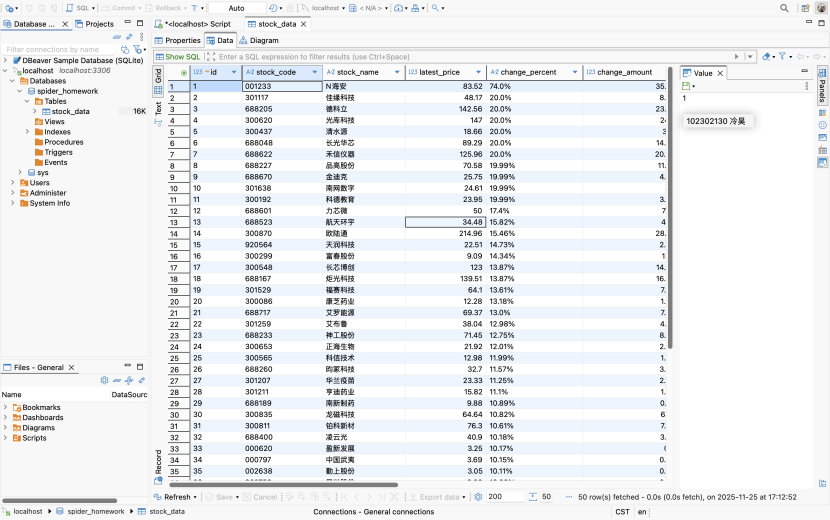

2)、心得体会
-
动态网页的坑:这次实验最大的收获就是学会了怎么处理动态网页。最开始我对着 HTML 源码写了半天 XPath,死活爬不到数据,后来查资料才知道现在的股票网站大多都是 JS 渲染的。学会用浏览器的 Network 面板找到真正的 JSON 接口,感觉像发现新大陆一样。
-
Scrapy 的分工:Scrapy 的结构真的很清晰。Spider 专门负责找数据,Item 负责定义数据长什么样,Pipeline 负责把数据存起来。这种分工让代码看起来很整洁,不像以前写单脚本那样乱糟糟的。
-
数据库连接:在使用 DBeaver 连接数据库时,我还遇到了一个“公钥检索不允许”的报错,后来上网查了下,修改了驱动属性就解决了。这个过程让我对数据库配置有了更深的印象。
作业③
1)、外汇牌价爬取实验
1. 实验描述
爬取中国银行外汇牌价(货币名称、现汇/现钞买入卖出价、发布时间),使用 XPath 技术解析数据并存储至 MySQL。
2. 核心代码
(1) 数据库建表
首先我在 MySQL 里建了一张 forex_data 表,专门用来存外汇数据。这是我的 sql 语句,主要是设计好字段类型。
CREATE TABLE IF NOT EXISTS forex_data (
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '序号',
currency VARCHAR(50) COMMENT '货币名称',
tbp DECIMAL(10, 2) COMMENT '现汇买入价',
cbp DECIMAL(10, 2) COMMENT '现钞买入价',
tsp DECIMAL(10, 2) COMMENT '现汇卖出价',
csp DECIMAL(10, 2) COMMENT '现钞卖出价',
pub_time DATETIME COMMENT '发布时间',
crawl_time DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '爬取时间'
) COMMENT '外汇牌价表';
(2) XPath 解析 (Spider)
这次我严格按照要求使用了 XPath。通过观察网页结构,我发现数据都在一个 table 标签里。所以我先用 //div[@class="publish"]/div/table/tr 找到所有的行,然后遍历每一行,再用 ./td 找到每一列的数据。这里我也加了一个数据处理的小逻辑:有些货币可能没有“现钞买入价”,数据是空的,如果直接转数字会报错,所以我写了个 parse_float 函数来兜底。
import scrapy
from homework3.items import ForexItem
class BocSpider(scrapy.Spider):
name = 'boc'
allowed_domains = ['boc.cn']
start_urls = ['[https://www.boc.cn/sourcedb/whpj/](https://www.boc.cn/sourcedb/whpj/)']
def parse(self, response):
# 使用 XPath 定位表格中的所有行 (排除表头)
rows = response.xpath('//div[@class="publish"]/div/table/tr')
for row in rows[1:]:
item = ForexItem()
# 相对路径提取单元格数据
item['currency'] = row.xpath('./td[1]/text()').get()
# 使用简单的转换逻辑
item['tbp'] = self.handle_float(row.xpath('./td[2]/text()').get())
item['cbp'] = self.handle_float(row.xpath('./td[3]/text()').get())
item['tsp'] = self.handle_float(row.xpath('./td[4]/text()').get())
item['csp'] = self.handle_float(row.xpath('./td[5]/text()').get())
item['pub_time'] = row.xpath('./td[7]/text()').get()
if item['currency']:
yield item
def handle_float(self, value):
if value and value.strip() != '':
return float(value)
return 0.0
3. 运行结果


2)、心得体会
-
XPath 实践:相比于作业②的 JSON 解析,作业③回归了经典的静态网页爬取。通过使用 //tr 定位行,再结合 ./td 相对路径提取单元格数据,我掌握了 XPath 的基本用法。
-
数据处理:网页上的外汇数据可能存在空值,我在代码中编写了简单的判断函数,防止转换数字时出错,保证了程序的稳定性。
-
全流程贯通:从建立数据库表,到编写爬虫,再到数据入库,这一系列流程让我对数据采集有了完整的认识。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号