

作业2
代码源:https://gitee.com/wsmlhqqwwn/LH/tree/master/作业2
作业①:
要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
1.1作业代码和图片:
import requests
from bs4 import BeautifulSoup
import sqlite3
def get_beijing_weather():
beijing_code = '101010100'
url = f"http://www.weather.com.cn/weather/{beijing_code}.shtml"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
try:
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
weather_data = []
weather_list = soup.find('ul', class_='t clearfix')
if not weather_list:
print("没找到天气列表")
return []
days = weather_list.find_all('li')
for day in days:
try:
date_tag = day.find('h1')
weather_tag = day.find('p', class_='wea')
temp_tag = day.find('p', class_='tem')
wind_tag = day.find('p', class_='win')
if not all([date_tag, weather_tag, temp_tag, wind_tag]):
continue
date = date_tag.text
weather = weather_tag.text
high_temp = temp_tag.find('span')
low_temp = temp_tag.find('i')
temperature = ""
if high_temp:
temperature += high_temp.text
if low_temp:
temperature += "/" + low_temp.text
wind = wind_tag.find('i')
wind_text = wind.text if wind else ""
weather_data.append({
'date': date,
'weather': weather,
'temperature': temperature,
'wind': wind_text
})
except Exception as e:
print(f"解析某天数据出错: {e}")
continue
return weather_data
except Exception as e:
print(f"请求出错:{e}")
return []
def create_db():
conn = sqlite3.connect('weather.db')
cursor = conn.cursor()
cursor.execute('''
CREATE TABLE IF NOT EXISTS weather (
id INTEGER PRIMARY KEY AUTOINCREMENT,
city TEXT,
date TEXT,
weather TEXT,
temp TEXT,
wind TEXT
)
''')
conn.commit()
conn.close()
def save_to_db(data):
conn = sqlite3.connect('weather.db')
cursor = conn.cursor()
for item in data:
cursor.execute('''
INSERT INTO weather (city, date, weather, temp, wind)
VALUES (?, ?, ?, ?, ?)
''', ('北京', item['date'], item['weather'], item['temperature'], item['wind']))
conn.commit()
conn.close()
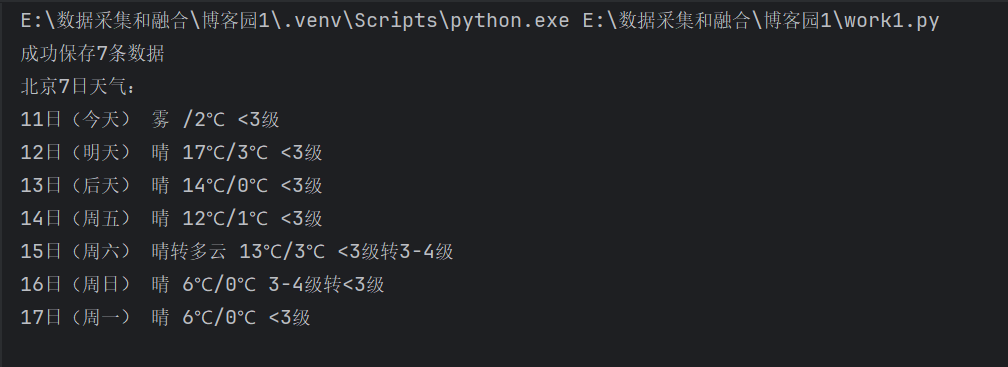
print(f"成功保存{len(data)}条数据")
def main():
create_db()
weather_data = get_beijing_weather()
if weather_data:
save_to_db(weather_data)
print("北京7日天气:")
for item in weather_data:
print(f"{item['date']} {item['weather']} {item['temperature']} {item['wind']}")
else:
print("没拿到数据")
if __name__ == "__main__":
main()
1.2 作业1:心得体会
这次爬取中国气象网,我主要解决了三个问题:首先用requests.get()加User-Agent头绕过反爬,然后用BeautifulSoup的find_all()定位天气数据所在的div标签,最难的是解析温度数据时发现格式不统一,有的带“℃”符号有的没有,最后用re.findall(r'\d+', text)提取纯数字解决了问题。
作业②:
– 要求:用requests和BeautifulSoup库方法定向爬取股票相关信息,并存储在数据库中。
– 网站:东方财富网:https://www.eastmoney.com/
– 技巧:在谷歌浏览器中进入F12调试模式进行抓包,查找股票列表加载使用的url,并分析api返回的值,并根据所要求的参数可适当更改api的请求参数。根据URL可观察请求的参数f1、f2可获取不同的数值,根据情况可删减请求的参数。
2.1作业代码和图片:
import requests
import re
import json
import time
def format_volume(vol_raw):
""" 将 '成交量(手)' 转换为 'xx.xx万' [cite: 6] """
if vol_raw is None: return "N/A"
return f"{vol_raw / 10000:.2f}万"
def format_turnover(turnover_raw):
""" 将 '成交额(元)' 转换为 'xx.xx亿' [cite: 6] """
if turnover_raw is None: return "N/A"
return f"{turnover_raw / 100000000:.2f}亿"
def fetch_stock_data_from_api(page):
"""
(Plan C) 使用你找到的正确API获取数据。
"""
# 这是你找到的URL
base_url = "https://push2delay.eastmoney.com/api/qt/clist/get?np=1&fltt=1&invt=2&cb=jQuery37106028979929363425_1761725264988&fs=m%3A0%2Bt%3A6%2Bf%3A!2%2Cm%3A0%2Bt%3A80%2Bf%3A!2%2Cm%3A1%2Bt%3A2%2Bf%3A!2%2Cm%3A1%2Bt%3A23%2Bf%3A!2%2Cm%3A0%2Bt%3A81%2Bs%3A262144%2Bf%3A!2&fields=f12%2Cf13%2Cf14%2Cf1%2Cf2%2Cf4%2Cf3%2Cf152%2Cf5%2Cf6%2Cf7%2Cf15%2Cf18%2Cf16%2Cf17%2Cf10%2Cf8%2Cf9%2Cf23&fid=f3&pn=1&pz=20&po=1&dect=1&ut=fa5fd1943c7b386f172d6893dbfba10b&wbp2u=%7C0%7C0%2C0%7Cweb&_=1761725265102"
# 替换页码 'pn=1' 为 'pn={page}'
request_url = base_url.replace("pn=1", f"pn={page}")
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Referer': 'http://quote.eastmoney.com/'
}
try:
response = requests.get(request_url, headers=headers, timeout=10)
response.raise_for_status()
# 解析JSONP数据
match = re.search(r'\((.*)\)', response.text)
if not match:
print(f"第 {page} 页 - 未能解析JSONP响应")
return []
json_string = match.group(1)
data = json.loads(json_string)
if not data.get("data") or not data["data"].get("diff"):
print(f"第 {page} 页 - 返回的数据中没有 'data.diff' 字段")
return []
stock_list = data["data"]["diff"]
processed_data = []
for stock in stock_list:
# (fN字段的含义是我们F12分析得出的)
data_tuple = (
stock.get("f12"), # 股票代码
stock.get("f14"), # 股票名称
stock.get("f2") / 100.0 if stock.get("f2") is not None else 0.0, # 最新股价
f"{stock.get('f3') / 100.0:.2f}%" if stock.get("f3") is not None else "0.00%", # 涨跌幅
stock.get("f4") / 100.0 if stock.get("f4") is not None else 0.0, # 涨跌额
format_volume(stock.get("f5")) if stock.get("f5") is not None else "N/A", # 成交量 (格式化)
format_turnover(stock.get("f6")) if stock.get("f6") is not None else "N/A", # 成交额 (格式化)
f"{stock.get('f7') / 100.0:.2f}%" if stock.get("f7") is not None else "0.00%", # 振幅
stock.get("f15") / 100.0 if stock.get("f15") is not None else 0.0, # 最高
stock.get("f16") / 100.0 if stock.get("f16") is not None else 0.0, # 最低
stock.get("f17") / 100.0 if stock.get("f17") is not None else 0.0, # 今开
stock.get("f18") / 100.0 if stock.get("f18") is not None else 0.0 # 昨收
)
processed_data.append(data_tuple)
return processed_data
except requests.RequestException as e:
print(f"请求失败: {e}。")
return []
except json.JSONDecodeError:
print(f"第 {page} 页 - JSON解析失败。")
return []
except Exception as e:
print(f"处理第 {page} 页时发生未知错误: {e}")
return []
# --- 主程序入口 ---
if __name__ == "__main__":
all_stocks_to_print = []
total_pages_to_fetch = 5 # 你可以改成任意页数
for page_num in range(1, total_pages_to_fetch + 1):
print(f"--- 正在爬取第 {page_num} 页 ---")
stock_data = fetch_stock_data_from_api(page_num)
if stock_data:
print(f"第 {page_num} 页爬取成功,获取 {len(stock_data)} 条数据。")
all_stocks_to_print.extend(stock_data)
time.sleep(1) # 礼貌性延迟,防止被封
else:
print(f"第 {page_num} 页没有返回数据,停止爬取。")
break
# --- 统一打印所有结果 (包含所有12个字段) ---
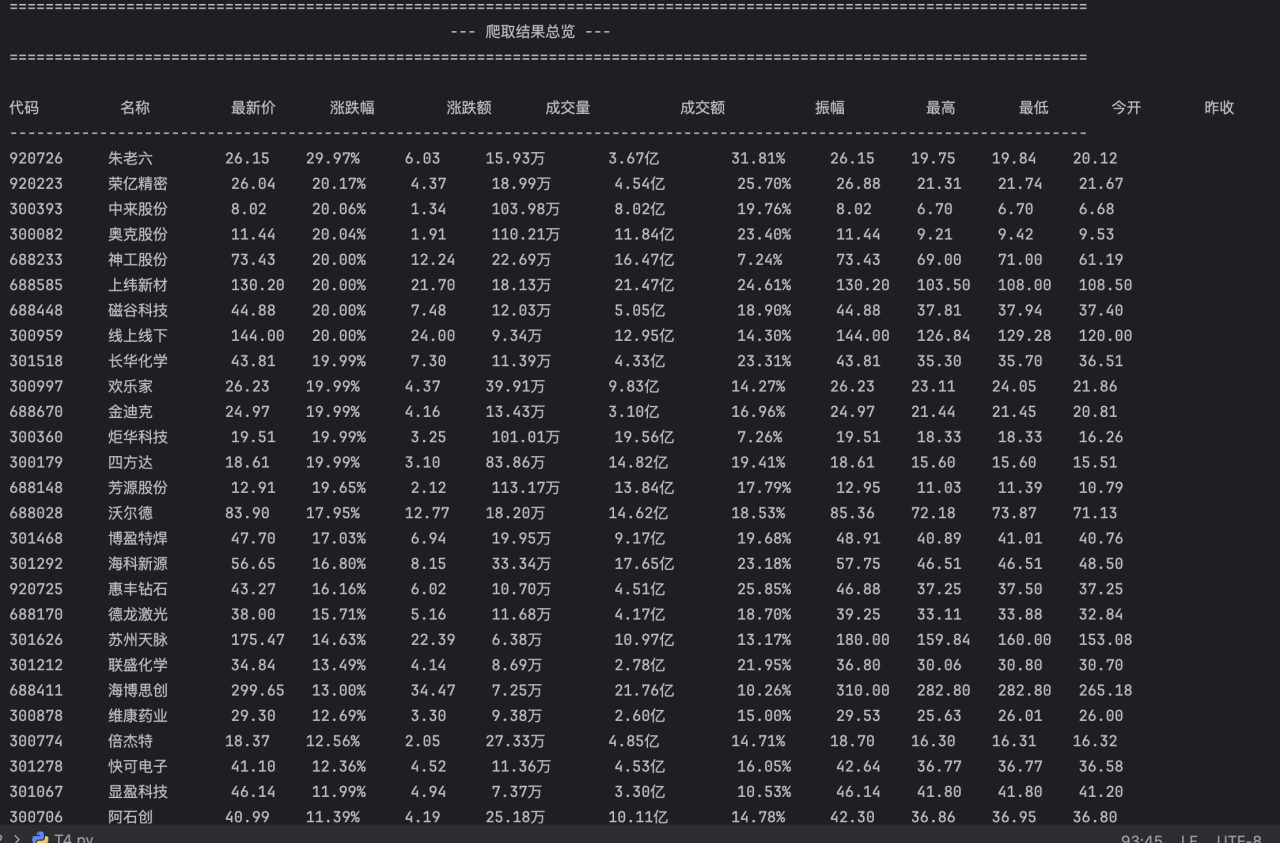
if all_stocks_to_print:
print("\n" + "=" * 120)
print(" --- 爬取结果总览 ---")
print("=" * 120 + "\n")
# 打印一个完整的表头,使其更易读
print(
f"{'代码':<10} {'名称':<10} {'最新价':<8} {'涨跌幅':<10} {'涨跌额':<8} {'成交量':<12} {'成交额':<12} {'振幅':<10} {'最高':<8} {'最低':<8} {'今开':<8} {'昨收':<8}")
print("-" * 120)
# 循环打印每一条数据
for stock in all_stocks_to_print:
# stock[0] 到 stock[11] 对应全部12个字段
print(
f"{str(stock[0]):<10} {str(stock[1]):<10} {stock[2]:<8.2f} {str(stock[3]):<10} {stock[4]:<8.2f} {str(stock[5]):<12} {str(stock[6]):<12} {str(stock[7]):<10} {stock[8]:<8.2f} {stock[9]:<8.2f} {stock[10]:<8.2f} {stock[11]:<8.2f}")
else:
print("\n未能爬取到任何数据。请检查网络或API是否已更改。")
print("\n作业② (完整打印版) 执行完毕!")
2.2心得体会
本次作业最大的收获是深刻理解了 F12 调试的重要性。我在提到的BeautifulSoup库中找到了作业并不适用,因为通过Network抓包分析,数据不是来自静态HTML,而是来自一个push2delay动态JSONP接口。我学会了如何通过requests请求这个API,并使用re和json库解析其返回的数据,还分析了如f12(代码)、f14(名称)等字段的含义这个“预告”过程是完成任务的关键。
作业③:
– 要求:爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021 )所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。
– 技巧:分析该网站的发包情况,分析获取数据的api
3.1作业代码和图片:
import requests
import sqlite3
import json
def get_university_data():
url = "https://www.shanghairanking.cn/api/pub/v1/bcur?bcur_type=11&year=2021"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
try:
response = requests.get(url, headers=headers, timeout=10)
if response.status_code == 200:
data_dict = json.loads(response.text)
ranking_data = data_dict["data"]["rankings"]
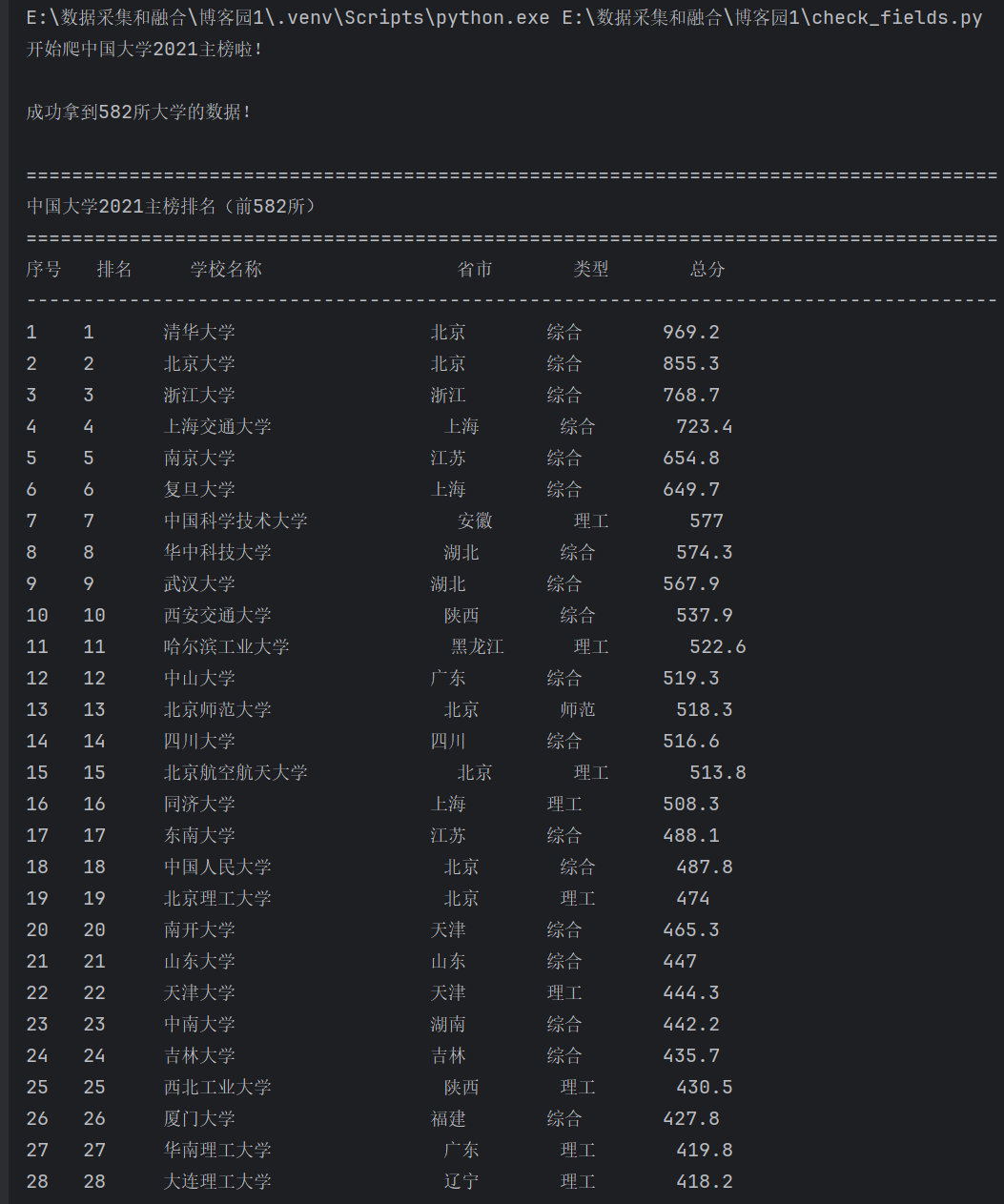
print(f"成功拿到{len(ranking_data)}所大学的数据!\n")
return ranking_data
else:
print(f"请求失败,状态码:{response.status_code}")
return None
except Exception as e:
print(f"爬取出错了:{str(e)}")
return None
def print_ranking(data):
print("="*85)
print("中国大学2021主榜排名(前582所)")
print("="*85)
print(f"{'序号':<4} {'排名':<6} {'学校名称':<20} {'省市':<8} {'类型':<8} {'总分':<6}")
print("-"*85)
for i in range(len(data)):
school = data[i]
seq = i + 1
rank = school["ranking"]
name = school["univNameCn"]
province = school["province"]
type_ = school["univCategory"]
score = school["score"]
print(f"{seq:<4} {rank:<6} {name:<20} {province:<8} {type_:<8} {score:<6}")
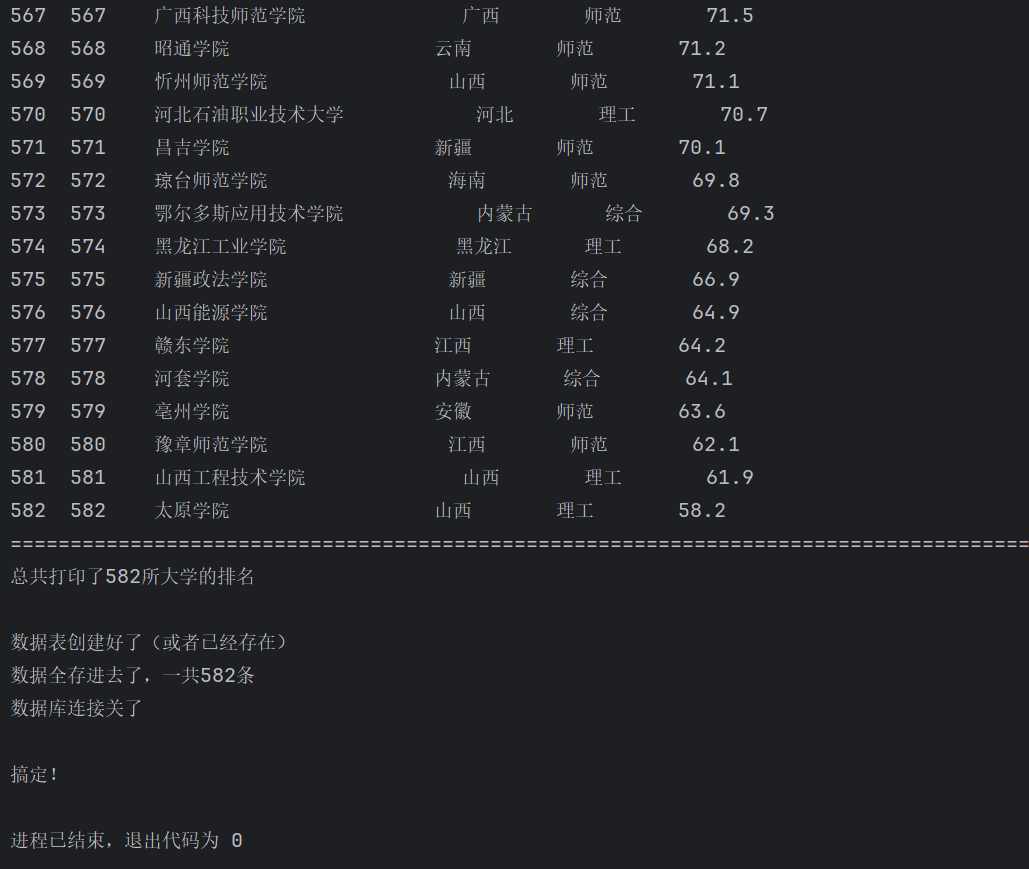
print("="*85)
print(f"总共打印了{len(data)}所大学的排名\n")
def save_to_db(data):
try:
conn = sqlite3.connect("university_rank_2021.db")
cursor = conn.cursor()
create_table_sql = """
CREATE TABLE IF NOT EXISTS university (
id INTEGER PRIMARY KEY AUTOINCREMENT,
ranking INTEGER NOT NULL,
school_name TEXT NOT NULL,
province TEXT NOT NULL,
school_type TEXT NOT NULL,
total_score REAL NOT NULL
)
"""
cursor.execute(create_table_sql)
print("数据表创建好了(或者已经存在)")
cursor.execute("DELETE FROM university")
for school in data:
insert_sql = """
INSERT INTO university (ranking, school_name, province, school_type, total_score)
VALUES (?, ?, ?, ?, ?)
"""
cursor.execute(insert_sql, (
school["ranking"],
school["univNameCn"],
school["province"],
school["univCategory"],
school["score"]
))
conn.commit()
print(f"数据全存进去了,一共{len(data)}条")
except Exception as e:
print(f"存数据库出错了:{str(e)}")
conn.rollback()
finally:
cursor.close()
conn.close()
print("数据库连接关了\n")
if __name__ == "__main__":
print("开始爬中国大学2021主榜啦!\n")
university_data = get_university_data()
if university_data:
print_ranking(university_data)
save_to_db(university_data)
print("搞定!")
3.2心得体会
这次爬取中国大学 2021 主榜的作业,让我对动态网页爬取和数据存储有了实际掌握。一开始我想直接解析网页 HTML,后来用 Chrome F12 调试,在 Network 的 XHR 里找到了返回 JSON 数据的 API 接口,省了很多解析麻烦,还发现排名字段是 “ranking” 而非一开始猜的 “rank”,这让我明白先确认数据结构的重要性。
存储方面,我用了 SQLite,不用装额外服务,代码里创建表时把字段和 API 返回对应上,插入前先清空表避免重复,最后记得 commit 提交事务 —— 之前忘写 commit 导致数据没存上,踩过这个坑后印象很深。打印排名时,我用左对齐格式让学校名、省市等字段对齐,看着更清晰。整个过程从找接口到解决字段错误、存储问题,每步都需要细心,也让我对爬虫流程和数据库操作更熟练了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号