
数据采集作业1
代码源:https://gitee.com/wsmlhqqwwn/LH/tree/master/作业1
1.作业①:
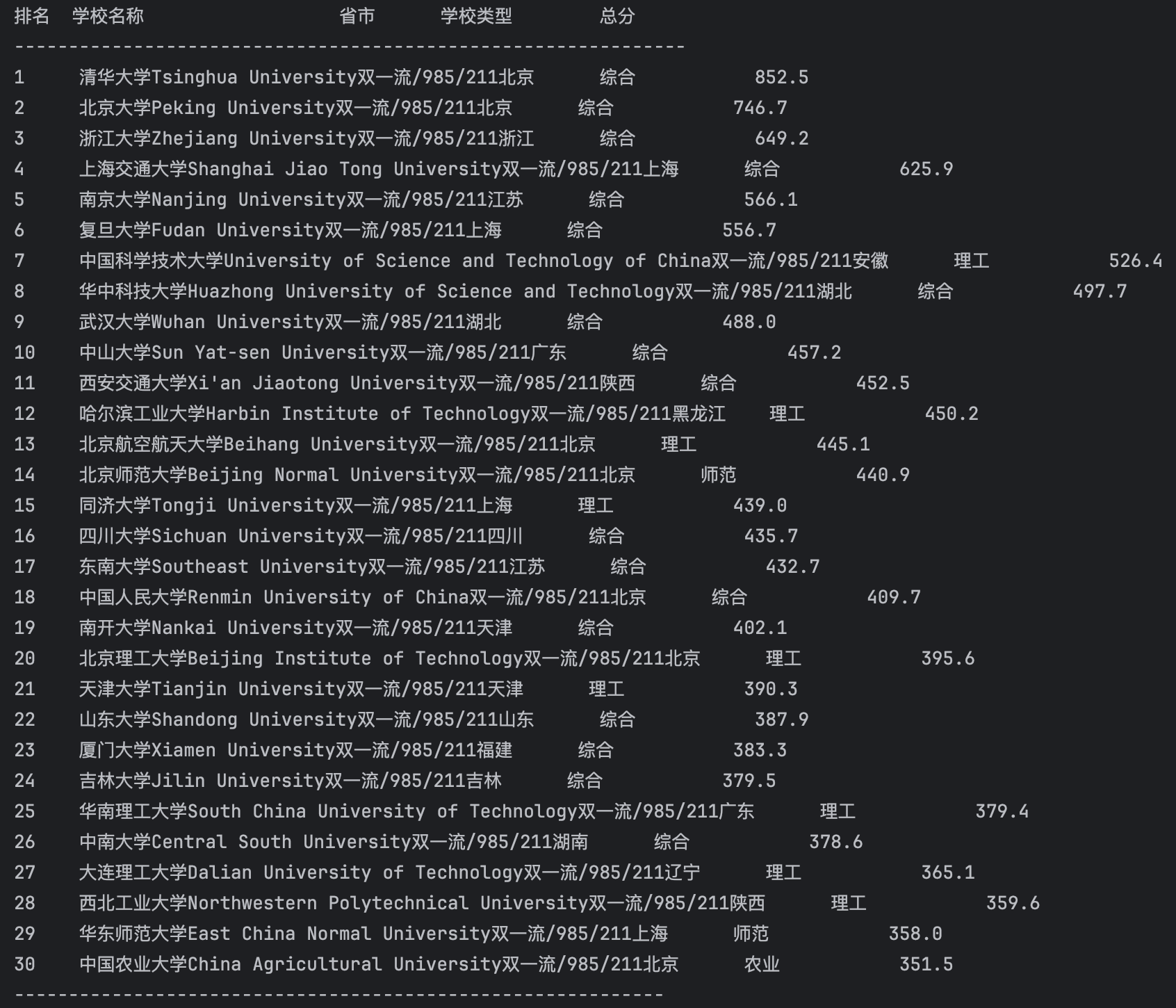
要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020) 的数据,屏幕打印爬取的大学排名信息。
1.1作业代码和图片:
import requests
from bs4 import BeautifulSoup
import sys
# --- 1. 获取网页 ---
url = 'http://www.shanghairanking.cn/rankings/bcur/2020'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
# 打印提示信息
print(f"正在抓取: {url} ...")
try:
# 发送请求
response = requests.get(url, headers=headers, timeout=10)
# 如果状态码不是200,则引发异常
response.raise_for_status()
# 设置编码 (按你之前的要求)
response.encoding = "utf-8"
data = response.text
except Exception as e:
# 打印错误并退出
print(f"错误:网页请求失败: {e}", file=sys.stderr)
sys.exit(1)
print("网页获取成功,正在解析...")
# --- 2. 解析数据 ---
# 使用 'lxml' 解析器
soup = BeautifulSoup(data, 'lxml')
# 找到表格主体 <tbody>
table_body = soup.find('tbody')
# 检查是否找到了 <tbody>
if not table_body:
print("错误:在HTML中未找到 <tbody> 标签。网站结构可能已改变。", file=sys.stderr)
sys.exit(1)
# 找到 <tbody> 中所有的 <tr> (行)
rows = table_body.find_all('tr')
if not rows:
print("错误:在 <tbody> 中未找到 <tr> 标签 (数据行)。", file=sys.stderr)
sys.exit(1)
print(f"解析成功,找到 {len(rows)} 行数据。")
print("-" * 20)
# --- 3. 按要求打印 ---
# 打印表头 (作业①要求) [cite: 5, 6]
print("排名,学校名称,省市,学校类型,总分")
# 遍历所有行
for row in rows:
# 找到行内所有 <td> 单元格
cells = row.find_all('td')
# 提取数据 (确保有5列)
if len(cells) >= 5:
rank = cells[0].text.strip()
school_name = cells[1].get_text(strip=True)
region = cells[2].text.strip()
school_type = cells[3].text.strip()
total_score = cells[4].text.strip()
# 按作业格式打印 [cite: 6]
print(f"{rank},{school_name},{region},{school_type},{total_score}")
print("-" * 20)
print("任务完成。")
1.2 作业1:心得体会
通过这次实验,我成功掌握了使用Python进行网页爬虫的基本流程。
1.分析目标网页: 首先,使用浏览器的F12开发者工具,审查了目标网址(http://www.shanghairanking.cn/rankings/bcur/2020) 的页面源代码。我发现所有的排名数据都很快地放在一个标签里面,每一行是一个标签,每一格数据都是一个标签。
2.获取网页(Requests): 我使用requests.get()方法,并设置了headers来模拟浏览器访问,成功获取到了完整的网页HTML源代码。
3.解析网页(BeautifulSoup): 接下来,我使用BeautifulSoup(html_text, 'html.parser')将获取到的 HTML 文本转换成一个 BeautifulSoup 对象。这使我能够方便地用标签来搜索数据。
4.定位与提取数据: 我利用soup.find('tbody')来定位到表格的主体,然后用find_all('tr')遍历表格中的每一行。在每一行中,我再find_all('td')用来获取所有单元格的列表。最后,我通过索引(如cells[0],cells[1])提取出排名、学校名称、省市、类型和总分,并使用.get_text(strip=True)来确保提取的数据是干净的纯文本。
5.主要收获:
我学会了requests库和BeautifulSoup库的良好工作流程:requests负责“下载”网页,BeautifulSoup负责“解析”和“查找”。掌握了如何使用浏览器F12工具来分析网页结构,这是爬虫成功的关键前提。学会了使用find()、find_all()等核心方法来精确定位并提取HTML标签中的内容。
2.作业②:
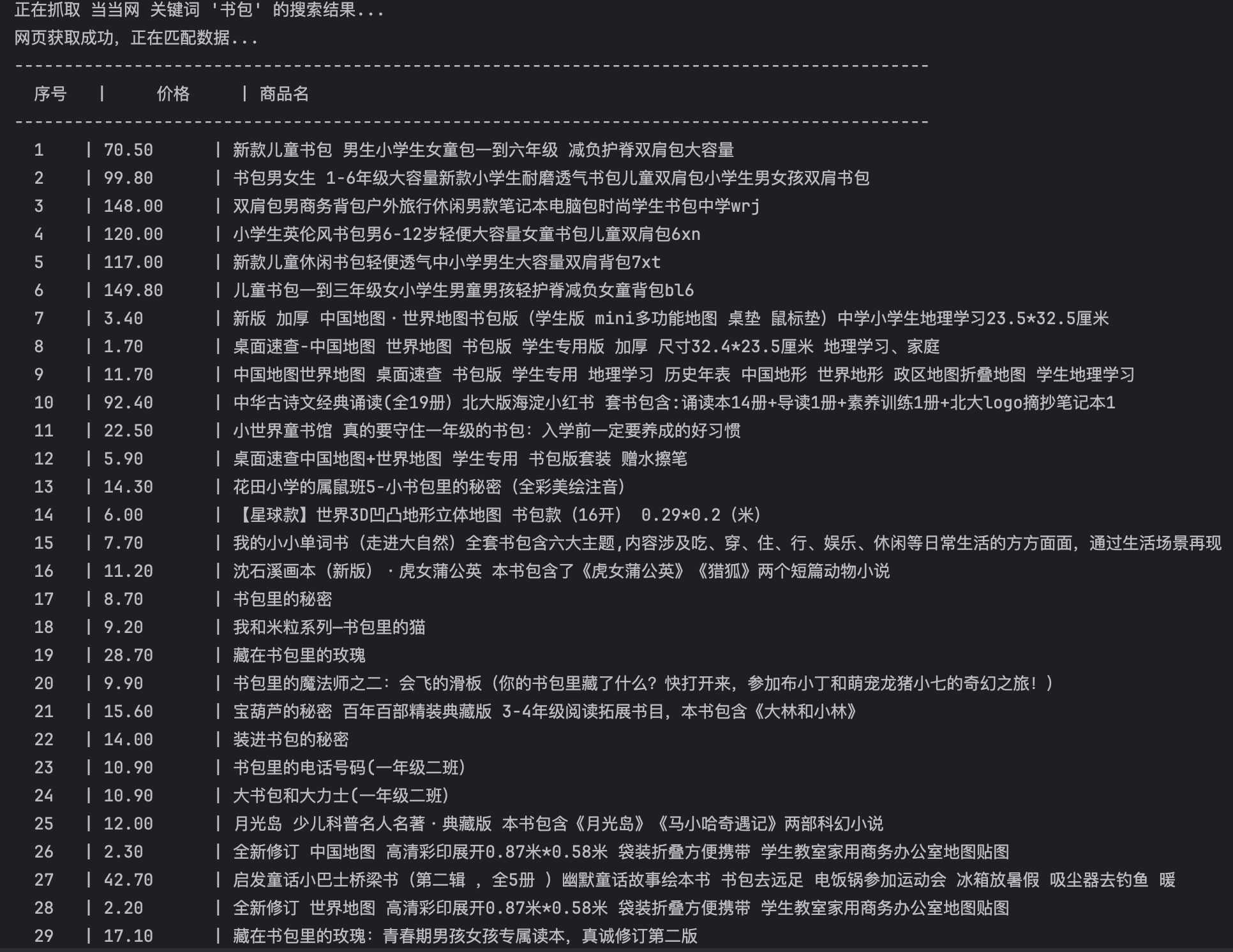
要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
2.1作业代码和图片:
import requests
import re
import sys
def get_display_width(s):
width = 0
for char in s:
width += 2 if ord(char) > 255 else 1
return width
def pad_str(s, width, align='left'):
current_width = get_display_width(s)
padding_size = max(0, width - current_width)
padding = " " * padding_size
return padding + s if align == 'right' else s + padding
# 定义请求参数和URL
url = "http://search.dangdang.com"
keyword = '书包'
params = {'key': keyword, 'page_index': 1}
# 模拟浏览器 User-Agent
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
# 1. 获取网页
try:
response = requests.get(url, headers=headers, params=params, timeout=30)
response.raise_for_status()
response.encoding = 'gb2312'
html_data = response.text
except requests.exceptions.RequestException as e:
sys.exit(1)
# 2. 正则表达式提取数据
# 定义价格和商品名的匹配规则
pattern = re.compile(
r'<span class="price_n">¥(\d+(?:\.\d+)?)</span>.*?<a title="(.+?)"'
)
# 使用 re.findall 查找所有匹配项
results = re.findall(pattern, html_data)
if not results:
sys.exit(1)
# 打印输出
W_NO = 6
W_PRICE = 10
W_NAME = 70
# 打印表格分隔线和表头
header_line = (
"序号".center(W_NO) + " | " +
"价格".center(W_PRICE) + " | " +
"商品名".ljust(W_NAME)
)
print("-" * (W_NO + W_PRICE + W_NAME + 6))
print(header_line)
print("-" * (W_NO + W_PRICE + W_NAME + 6))
# 遍历结果并格式化打印
for index, item in enumerate(results, start=1):
price = item[0].strip()
name = item[1].strip()
# 格式化每一行数据
data_line = (
str(index).center(W_NO) + " | " +
price.ljust(W_PRICE) + " | " +
name[:W_NAME].ljust(W_NAME)
)
print(data_line)
# 打印表格底部
print("-" * (W_NO + W_PRICE + W_NAME + 6))
2.2 作业2:心得体会
通过完成本次商品比价爬虫实验,我深入理解了结合使用requests库和re(正则表达式)库来定向爬取静态网页中的特定数据。
1.确定目标与参数: 我选择了稳定结构的当当网作为目标商城,并确定了搜索关键词“书包”。通过分析当当网的URL结构,我成功构建了包含key和page_index的请求参数,确保能够获取到正确的商品列表页面内容。
2.获取网页内容(请求): 我使用requests.get()方法发送HTTP请求,并设置了headers模拟浏览器访问。为了保证获取过程的稳定性,我设置了四个的超时时间。同时,为了保证中文正常显示,我将响应编码设置为gb2312。
3.核心技术:设计正则表达式(re): 本次实验的关键在于re高效使用。我编写了一个专业而的正则表达式模式,通过一个模式同时定位并提取商品名称和价格。利用非贪婪的(.+?)名称捕获了title属性中的商品。精确匹配了价格附近的HTML结构,并获取了¥符号后的数字和小数部分作为价格数据。最终,我通过re.findall()成功批量提取了所有商品的名称和价格。
4.主要收获:
掌握了requests库和re库的经典组合应用:requests负责下载原始HTML文本,然后re负责对原始文本进行精确的模式匹配和数据提取。学会了如何设计一个强大的、具有多个捕获组的正则表达式,以实现一次匹配同时提取多个数据项。掌握了通过设定headers和编码来保证爬虫的成功率和数据的正确性。学会了利用 Python 的字符串删除技巧,使最终的终端输出结果呈现出清晰、美观的表格样式。
3.作业③:
要求:爬取一个给定网页( https://news.fzu.edu.cn/yxfd.htm) 或者自选网页的所有JPEG、JPG或PNG格式图片文件
输出信息:将自选网页内的所有JPEG、JPG或PNG格式图片件保存在一个文件夹中
代码和结果:
import requests
from bs4 import BeautifulSoup
import os
import re
import sys
from urllib.parse import urljoin
# 定义目标URL和保存图片的文件夹名
TARGET_URL = "https://news.fzu.edu.cn/yxfd.htm"
SAVE_DIR = "web_images_full" # 使用新的文件夹名避免覆盖旧文件
def get_absolute_url(base_url, relative_url):
"""将相对URL转换为完整的绝对URL。"""
if relative_url.lower().startswith('http') or relative_url.lower().startswith('https'):
return relative_url
return urljoin(base_url, relative_url)
def crawl_and_save_images(url, save_directory):
# 1. 检查或创建保存图片的文件夹
if not os.path.exists(save_directory):
os.makedirs(save_directory)
print(f"创建文件夹: {save_directory}")
# 2. 获取网页内容
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
response = requests.get(url, headers=headers, timeout=15)
response.raise_for_status()
response.encoding = response.apparent_encoding
html_data = response.text
print(f"成功获取网页内容: {url}")
except requests.exceptions.RequestException as e:
print(f"错误:无法获取网页内容: {e}", file=sys.stderr)
return
# 3. 收集所有可能的图片链接
# 使用集合(set)存储链接,自动去重
image_urls = set()
# --- 策略 A: 查找 <img> 标签 (BeautifulSoup) ---
soup = BeautifulSoup(html_data, 'html.parser')
for tag in soup.find_all('img'):
src = tag.get('src')
if src:
image_urls.add(get_absolute_url(url, src))
# --- 策略 B: 使用正则表达式查找 HTML 中的所有图片链接 ---
# (关键步骤) 查找所有以 .jpg, .jpeg, .png 结尾的链接
# re.I 忽略大小写
pattern = re.compile(r'[\'\"](.*?)\.(jpe?g|png)[\'\"]', re.I)
# 在整个 HTML 文本中查找
for match in re.findall(pattern, html_data):
# match 是一个元组,第一个元素是链接主体
link = match[0] + "." + match[1]
image_urls.add(get_absolute_url(url, link))
# 4. 遍历链接并下载
download_count = 0
print(f"找到 {len(image_urls)} 个去重后的图片链接,开始下载...")
for img_url in image_urls:
filename = img_url.split('/')[-1].split('?')[0]
file_path = os.path.join(save_directory, filename)
if os.path.exists(file_path):
continue
# (关键步骤) 再次确认链接是否符合 jpg/jpeg/png 格式
if not re.search(r'\.(jpe?g|png)$', img_url, re.I):
continue
try:
# 下载图片内容 (使用 content 获取二进制数据)
img_response = requests.get(img_url, timeout=10)
img_response.raise_for_status()
# 以二进制写入模式 ('wb') 保存文件
with open(file_path, 'wb') as f:
f.write(img_response.content)
download_count += 1
except requests.exceptions.RequestException:
# 忽略下载失败的链接
continue
print("-" * 30)
print(f"作业③ 任务完成。共成功下载了 {download_count} 张新图片到 '{save_directory}' 文件夹。")
if __name__ == "__main__":
crawl_and_save_images(TARGET_URL, SAVE_DIR)


3.2 作业3:心得体会:
1.获取网页: 我使用了 requests.get() 方法,并设置了 headers 模拟浏览器,成功获取了目标网页(福大要闻)的 HTML 源代码。
2.全面提取图片链接(关键步骤): 我意识到,只抓取 标签会遗漏很多图片。为了爬取所有 JPEG、JPG 或 PNG 图片 ,我结合了两种策略:
3.使用 BeautifulSoup: 我先用 soup.find_all('img') 找到所有 标签,并提取它们的 src 属性。
4.使用 正则表达式 (re): 为了找到那些隐藏在 HTML 文本中、但不在 标签里的图片链接(例如 CSS 背景图),我额外使用 re.findall() 配合 r'.(jpe?g|png)' 规则,对整个 HTML 文本进行了全面搜索。
主要收获:
我学会了 BeautifulSoup 和 re 协同工作的爬虫策略:BeautifulSoup 擅长解析 HTML 结构(如 ),而 re 擅长在纯文本中匹配模式(如 *.jpg)。掌握了 urllib.parse.urljoin() 这个重要工具,它能帮我自动处理相对路径和绝对路径的拼接问题。理解了下载文件(如图片)和下载文本的核心区别:必须使用 response.content (二进制) 和 'wb' (二进制写入) 模式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号