Data Pipelines with Apache Airflow机翻-4.使用Airflow上下文来模板化任务
4.使用Airflow上下文来模板化任务
本章涵盖
- 在运行时使用模板渲染变量
- 使用PythonOperator与其他运算符进行变量模板
- 渲染模板变量以进行调试
- 在外部系统上执行操作
在前面的章节中,我们谈到了DAG和operators如何协同工作以及如何在Airflow中调度工作流。在本章中,我们将深入介绍operators代表什么,它们是什么,它们如何工作,以及它们何时以及如何执行。我们还将演示如何使用operators通过挂钩与远程系统进行通信,这使您可以执行任务,例如将数据加载到数据库中,在远程环境中运行命令以及在Airflow之外的其他地方执行工作负载。
4.1 Airflow处理的检验数据
在本章中,我们将通过一个(虚构的)应用情绪分析的股票市场预测工具(我们称之为“ StockSense”) ,计算出运营商的几个组成部分。维基百科是互联网上最大的公共信息资源之一,除了维基页面之外,其他条目如页面浏览量也是公开的。为了本例的目的,我们将应用这样一个公理: 公司页面浏览量的增加显示了积极的情绪,公司的股票也可能会增加。另一方面,页面浏览量的减少告诉我们利息的损失,股票价格可能会下跌。
4.1.1 确定如何加载增量数据
维基百科背后的组织维基媒体基金会提供了自2015年以来所有机器可读格式的页面浏览量。页面浏览量可以以 gzip 格式下载,并按每页每小时计算。每小时转储大约50mb 的压缩文本文件,大小在200mb 到250mb 之间。
处理任何类型的数据时,这些都是必不可少的细节。任何大小的数据都可能很复杂,在建立管道之前制定技术方案很重要。解决方案总是取决于您或其他用户想要对数据做什么,所以问问自己和其他人诸如“我们是否希望在未来的某个时间再次处理这些数据?如何接收数据(例如,频率、大小、格式、来源类型) 以及“我们要用这些数据建立什么?”在知道这些问题的答案之后,我们才可以考虑技术细节。
让我们下载一个小时的转储文件,并手动检查数据。为了开发一个数据管道,我们必须了解如何以增量方式加载它,以及如何处理数据:
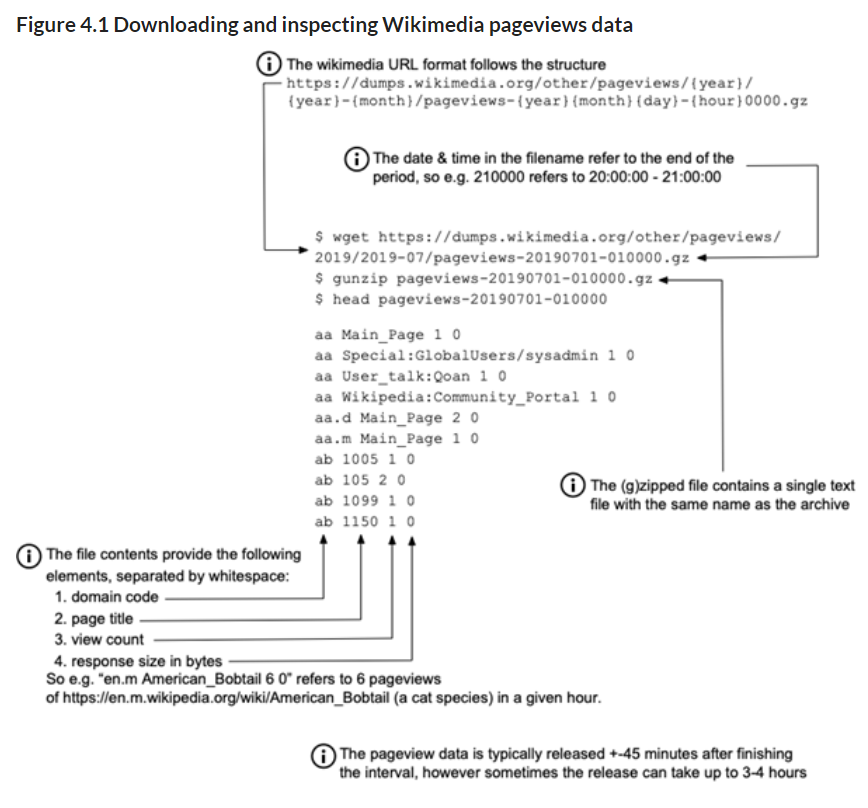
我们看到 url 遵循一个固定的模式,我们可以利用这个模式批量下载数据,就像第3章中简要提到的那样。作为一个思想实验,为了验证数据,让我们看看7月7日10:00-11:00最常用的域名代码:
图4.2首先对 Wikimedia 页面浏览量数据进行简单分析

看top的结果“1061202 en”和“995600 en.m”,这告诉我们7月7日10:00到11:00之间浏览最多的域名是“ en”和“ en.m”(en的移动版本), 考虑到英语是世界上使用最广泛的语言,这很有意义。此外,结果会按照我们预期的方式返回,这就证实了没有意外字符或列不对齐,这意味着我们不需要执行任何额外的处理来清理数据。通常,清理数据并将其转换为一致的状态占据了工作的很大一部分。
4.2 任务上下文和Jinja模板
图4.3 StockSense工作流程的第一个版本

第一步是下载,每个间隔的 zip 文件。该网址由各种日期和时间组件构成:
https://dumps.wikimedia.org/other/pageviews/{year}/{year}-{month}/pageviews-{year}{month}{day}-{hour}0000.gz
对于每个间隔,我们都必须在URL中插入该特定间隔的日期和时间。在第3章中,我们讨论了调度以及(简要地)如何在代码中使用执行日期,以使其在一个特定的间隔内执行,让我们更深入地研究它的工作方式。有多种下载页面浏览量的方法, 但是,让我们专注于BashOperator和PythonOperator。在这些operators 中插入变量的方法可以推广到所有其他operators 。
4.2.1 模板operator参数
首先,让我们使用BashOperator下载Wikipedia浏览量。 BashOperator接受一个参数“ bash_command”,我们向其提供一个Bash命令来执行。在 URL 的所有组件中,我们需要在运行时以双花括号开始和结束时插入一个变量
清单4.1使用BashOperator下载Wikipedia页面浏览量
import airflow
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
dag = DAG(
dag_id="stocksense_bashoperator",
start_date=airflow.utils.dates.days_ago(3),
schedule_interval="@hourly",
)
get_data = BashOperator(
task_id="get_data",
bash_command=(
"curl -o /tmp/wikipageviews.gz "
"https://dumps.wikimedia.org/other/pageviews/"
"{{ execution_date.year }}/"
"{{ execution_date.year }}-{{ '{:02}'.format(execution_date.month) }}/"
"pageviews-{{ execution_date.year }}{{ '{:02}'.format(execution_date.month) }}{{ '{:02}'.format(execution_date.day) }}-"
"{{ '{:02}'.format(execution_date.hour) }}0000.gz"
),
dag=dag,
)
如第3章所述,execution_date是在任务运行时“神奇”可用的变量之一。 双花括号表示Jinja模板字符串。 Jinja是一个模板引擎,它在运行时替换模板字符串中的变量和/或表达式。当您作为程序员在编写时不知道某些东西的价值,但是在运行时知道某些东西的价值时,就会使用模板。例如,当你有一个表单,你可以在其中插入你的名字,代码打印插入的名字:

在编程时不知道 name 的值,因为用户将在运行时在表单中输入他/她的名字。我们只知道插入的值被分配给一个名为 name 的变量,然后我们可以提供一个模板化的字符串“ Hello { name } !”在运行时呈现和插入 name 的值。
在 Airflow 中,你可以在运行时从任务上下文中获得许多变量。其中一个变量是 execution _ date。 Airflow将Pendulum [10]库用于日期时间,execution_date就是这样的Pendulum对象。它是 Python 原生日期时间的直接替代,因此所有可以应用于Python日期时间的方法也可以应用于Pendulum日期时间。因此,就像可以执行datetime.now().year一样,使用pendulum.now().year也可以得到相同的结果:
清单4.2 Pendulum的行为等同于本机Python日期时间
>>> from datetime import datetime
>>> import pendulum
>>> datetime.now().year
2019
>>> pendulum.now().year
2019
维基百科页面浏览量 URL 需要零填充的月份、天数和时数(例如“07”表示小时7)。因此,在Jinja模板化字符串中,我们将字符串格式应用于填充:
哪些参数已被模板化?
重要的是要知道并非所有的运算符参数都是可模板化的!每个operator都可以保留一个可模板化属性的白名单。 默认情况下,它们不是,因此字符串“ {{name}}”将被解释为字面“ {{name}}”,并且不会被Jinja模板化,除非包含在可模板化属性列表中。 该列表由每个operator上的属性template_fields设置。您可以在文档中检查可模板化的属性:https://airflow.readthedocs.io/en/stable/_api/airflow/operators,单击您选择的运算符并查看“ template_fields”项。
注意template_fields中的元素是类属性的名称。通常,提供给__init__的参数名称与类属性名称匹配,因此template_fields中列出的所有内容都将1:1映射到__init__参数。但是从技术上讲,它们可能没有,因此应记录参数映射到哪个类属性。
4.2.2 有哪些可用的模板?
既然我们已经了解了运算符的哪些参数可以模板化,那么我们可以使用哪些变量进行模板化呢?我们已经在许多示例中看到过使用 execution _ date,但是还有更多的变量可用。在 PythonOperator的帮助下,我们可以打印完整的任务上下文并检查它:
清单4.3打印任务上下文
def _print_context(**kwargs):
print(kwargs)
print_context = PythonOperator(
task_id="print_context",
python_callable=_print_context,
provide_context=True,
dag=dag,
)
运行此任务将打印任务上下文中所有可用变量的字典:
清单4.4中的代码4.3列出了给定执行日期的所有上下文变量
{
'dag': <DAG: print_context>,
'ds': '2019-07-04',
'next_ds': '2019-07-04',
'next_ds_nodash': '20190704',
'prev_ds': '2019-07-03',
'prev_ds_nodash': '20190703',
...
}
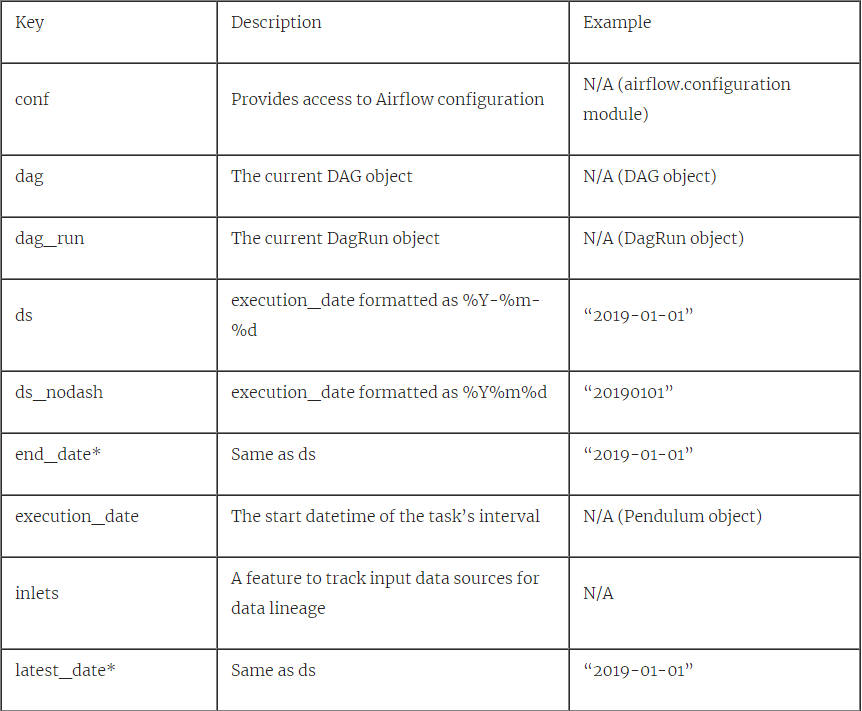
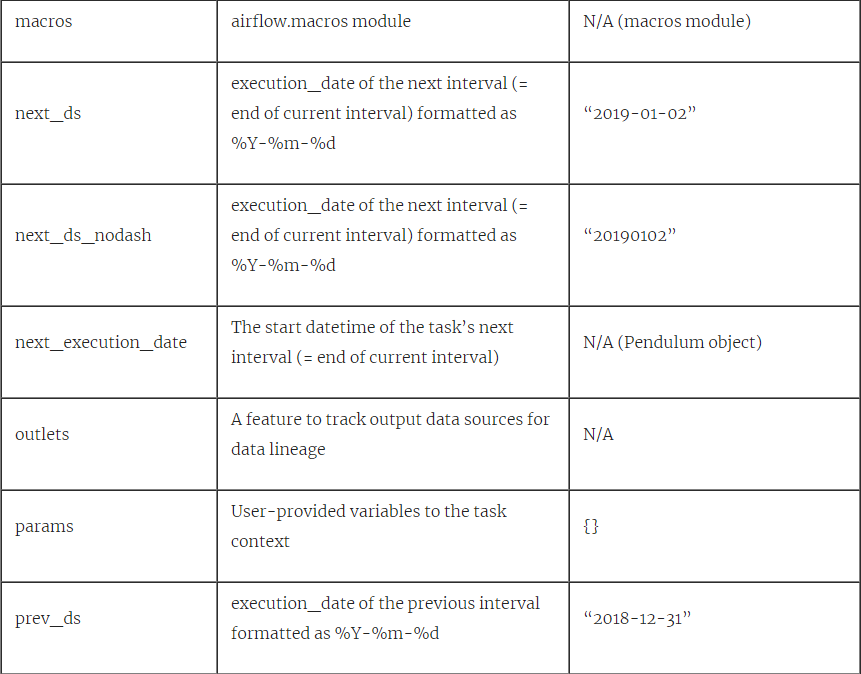
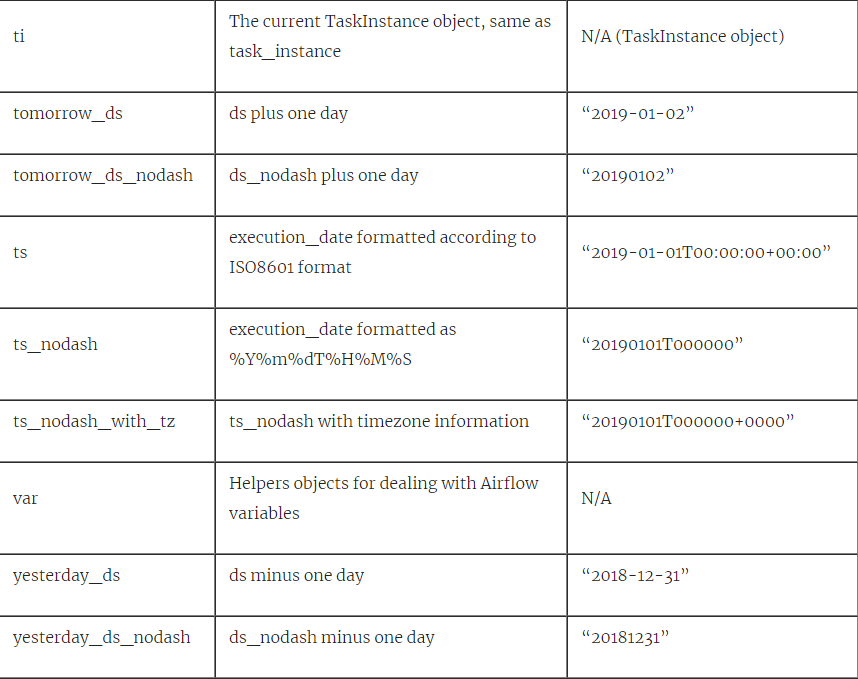
所有变量都在** kwargs中“捕获”,并传递给print()函数。 所有这些变量都可以在运行时使用。 下表提供了所有可用任务上下文变量的描述:
表4.1所有任务上下文变量。 使用PythonOperator打印在DAG中手动运行,执行日期为2019-01-01T00:00:00,@daily interval。 * =不建议使用,因为已在Airflow 2.0中删除

4.2.3 模板化PythonOperator
PythonOperator 是前面部分所示模板的一个例外。通过 BashOperator (以及 Airflow 中的所有其他operators) ,您可以向 bash _ command 参数(或其他operators中命名的参数)提供一个字符串,该参数在运行时自动模板化。PythonOperator是这个标准的一个例外,因为它没有采用可以在运行时上下文中进行模板化的参数,而是采用了可以在其中应用运行时上下文的python_callable参数。
让我们检查一下下载 Wikipedia 页面视图的代码,如上所示,它是用 BashOperator 实现的,但现在是用 PythonOperator 实现的。从功能上讲,这是同样的行为:
清单4.5使用PythonOperator下载Wikipedia浏览量
from urllib import request
import airflow
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
dag = DAG(dag_id="stocksense", start_date=airflow.utils.dates.days_ago(1), schedule_interval="@hourly")
def _get_data(execution_date, **_):
year, month, day, hour, *_ = execution_date.timetuple()
url = (
"https://dumps.wikimedia.org/other/pageviews/"
f"{year}/{year}-{month:0>2}/pageviews-{year}{month:0>2}{day:0>2}-{hour:0>2}0000.gz"
)
output_path = "/tmp/wikipageviews.gz"
request.urlretrieve(url, output_path)
get_data = PythonOperator(task_id="get_data", python_callable=_get_data, provide_context=True, dag=dag)
函数是Python中的一等公民,我们为PythonOperator的python_callable参数提供了callable [11](函数是可调用对象)。 在执行时,PythonOperator执行提供的可调用对象,它可以是任何函数。 由于它是一个函数,而不是像其他所有运算符一样的字符串,因此该函数内的代码无法自动模板化。
相反,可以将任务上下文变量作为变量提供,以在给定功能中使用。有一点需要注意: 为了提供任务实例上下文,我们必须设置一个参数 provide _ context = True。运行PythonOperator而不设置provide_context=True将执行可调用对象,但不会将任何任务上下文变量传递给可调用的函数。
图4.4使用PythonOperator提供任务上下文

Python 允许在函数中“捕获”关键字参数。 这有多种用例,主要是
1)如果您不知道预先提供的关键字参数
2)避免必须明确写出所有预期的关键字参数名称。
清单4.6存储在kwargs中的关键字参数
def _print_context(**kwargs):
print(kwargs)
为了向您和您的Airflow代码的其他读者表明您打算在关键字参数中捕获Airflow任务上下文变量的意图,一种好的做法是适当地命名此参数(例如,“ context”):
清单4.7将 kwargs 重命名为 context,以表示存储任务上下文的意图
def _print_context(**context):
print(context)
print_context = PythonOperator(
task_id="print_context",
python_callable=_print_context,
provide_context=True,
dag=dag,
)
上下文变量是所有上下文变量的字典,它允许我们为任务运行的时间间隔提供不同的行为。例如,打印当前时间间隔的开始和结束日期:
清单4.8打印间隔的开始和结束日期
def _print_context(**context):
start = context["execution_date"]
end = context["next_execution_date"]
print(f"Start: {start}, end: {end}")
print_context = PythonOperator(
task_id="print_context", python_callable=_print_context, provide_context=True, dag=dag
)
# Prints e.g.:
# Start: 2019-07-13T14:00:00+00:00, end: 2019-07-13T15:00:00+00:00
现在我们已经看到了一些基本的示例,让我们来分析PythonOperator,下载每小时的Wikipedia页面视图,如清单4.4所示。
图4.5 PythonOperator使用函数而不是字符串参数,因此不能被Jinja模板化。在这个被调用的函数中,我们从execution_date中提取datetime组件来动态地构造URL。

PythonOperator调用的_get_data函数有一个参数:**context。正如我们之前看到的,我们可以接受名为 * * kwargs 的单个参数中的所有关键字参数(双星号表示所有关键字参数,kwargs 是实际变量的名称)。为了表明我们期望任务上下文变量,我们可以将其重命名为** context。不过 Python 中还有另一种接受关键字参数的方式。
清单4.9显式地期望变量execution_date
def _get_data(execution_date, **context):
year, month, day, hour, *_ = execution_date.timetuple()
# ...
实际上,调用_get_data函数时,所有上下文变量都作为关键字参数:
清单4.10
_get_data(conf=..., dag=..., dag_run=..., execution_date=..., ...)
然后Python会检查函数签名中是否有给定的参数:
图4.6 Python确定是否将给定的关键字参数传递给函数中的一个特定参数,如果没有找到匹配的名称,则传递给**参数。

检查第一个参数conf,但未在_get_data的签名(预期参数)中找到该参数,因此将其添加到** context中。dag和dag_run重复此操作,因为两个参数均不在函数的预期参数中。
接下来是我们希望接收的execution_date,因此它将其值传递给_get_data()中的execution_date参数:
图4.7 _get_data需要一个名为execution_date的参数。没有设置默认值,因此如果没有提供它将失败

这个给定示例的最终结果是将名称为execution_date的关键字传递给execution_date参数,而所有其他变量均传递给** context,因为在函数签名中未明确要求它们:
图4.8任何命名参数都可以给_get_data。必须显式提供Execution_date,因为它是作为参数列出的,所有其他参数都由**kwargs捕获。

现在,我们可以直接使用execution_date变量,而不必从带有context [“ execution_date”]的** context中提取变量。此外,您的代码将更具有自解释性,而诸如linters和类型提示之类的工具也将受益于显式参数定义。
4.2.4 为 PythonOperator 提供变量
既然我们已经了解了任务上下文在运算符中的工作方式以及Python如何处理关键字参数,那么想象一下我们想从多个数据源下载数据。_get_data()函数可以复制并稍作更改以支持第二个数据源。 但是,PythonOperator也支持为可调用函数提供其他参数。 例如,假设我们首先将output_path配置为可配置的,以便根据任务,我们可以配置output_path,而不必重复整个功能以更改输出路径:
图4.9现在可以通过参数配置output_path

可以通过两种方式提供output_path的值。 首先通过参数op_args:
清单4.11向可调用的PythonOperator提供用户定义的变量
get_data = PythonOperator(
task_id="get_data",
python_callable=_get_data,
provide_context=True,
op_args=["/tmp/wikipageviews.gz"],
dag=dag,
)
在执行操作符时,列表中提供给 op _ args 的每个值都被传递给可调用函数,即与直接调用函数的效果相同:
_get_data("/tmp/wikipageviews.gz")
由于图4.9中的output_path是_get_data函数中的第一个参数,因此在运行时它的值将设置为“ /tmp/wikipageviews.gz”(我们将其称为非关键字参数)。 第二种方法是使用op_kwargs参数:
清单4.12为可调用的PythonOperator提供用户定义的关键字参数
get_data = PythonOperator(
task_id="get_data",
python_callable=_get_data,
provide_context=True,
op_kwargs={"output_path": "/tmp/wikipageviews.gz"},
dag=dag,
)
与op_args相似,op_kwargs中的所有值都传递给callable函数,但这一次是作为关键字参数。 对_get_data的等效调用为:
_get_data(output_path="/tmp/wikipageviews.gz")
请注意,这些值可以包含字符串,因此可以作为模板! 这意味着我们可以避免在可调用函数本身中提取datetime组件,而将模板化字符串传递给我们的可调用函数:
清单4.13提供可模板化的字符串作为可调用函数的输入
def _get_data(year, month, day, hour, output_path, **context):
url = (
"https://dumps.wikimedia.org/other/pageviews/"
f"{year}/{year}-{month:0>2}/pageviews-{year}{month:0>2}{day:0>2}-{hour:0>2}0000.gz"
)
request.urlretrieve(url, output_path)
get_data = PythonOperator(
task_id="get_data",
python_callable=_get_data,
provide_context=True,
op_kwargs={
"year": "{{ execution_date.year }}",
"month": "{{ execution_date.month }}",
"day": "{{ execution_date.day }}",
"hour": "{{ execution_date.hour }}",
"output_path": "/tmp/wikipageviews.gz",
},
dag=dag,
)
4.2.5 检查模板参数
Airflow UI是调试模板参数问题的有用工具。 您可以在运行任务后通过在“图形”视图或“树形视图”中选择任务并单击“渲染”按钮来检查模板化的参数值:
图4.10运行任务后检查渲染的模板值

“渲染模板”视图显示给定运算符的所有可渲染属性,并在此处显示值。 “渲染模板”视图在每个任务实例中可见。 因此,必须先由Airflow安排任务,然后才能检查给定任务实例的渲染属性。
UI的一个缺点是必须先由Airflow安排任务(即,您必须等待Airflow安排下一个任务实例)。 在开发过程中,这可能是不切实际的。 Airflow命令行界面(CLI)允许我们在希望看到的任何日期时间呈现模板化值:
清单4.14渲染给定执行日期的模板值
# airflow render stocksense get_data 2019-07-19T00:00:00
# ----------------------------------------------------------
# property: templates_dict
# ----------------------------------------------------------
None
# ----------------------------------------------------------
# property: op_args
# ----------------------------------------------------------
[]
# ----------------------------------------------------------
# property: op_kwargs
# ----------------------------------------------------------
{'year': '2019', 'month': '7', 'day': '19', 'hour': '0', 'output_path': '/tmp/wikipageviews.gz'}
CLI为我们提供了与Airflow UI中显示的信息完全相同的信息,而无需运行任务,这使检查结果变得更加容易。 使用CLI呈现模板的命令为[12]:
airflow render [dag id] [task id] [desired execution date]
您可以输入任何日期时间,并且Airflow CLI将呈现所有模板化的属性,就像任务将在所需的日期时间运行一样。 使用CLI不会在metastore中注册任何内容,因此是一种“轻量级”且灵活的操作。
4.3 连接其他系统
现在我们已经弄清楚了模板的工作原理,让我们通过处理每小时的Wikipedia浏览量来继续用例。对于该记录,下面两个operators将提取存档并处理提取的文件,方法是扫描该文件并为给定的页面名称选择页面视图计数。然后在日志中输出结果:
清单4.15阅读给定页名的页面浏览量
extract_gz = BashOperator(
task_id="extract_gz",
bash_command="gunzip --force /tmp/wikipageviews.gz",
dag=dag,
)
def _fetch_pageviews(pagenames):
result = dict.fromkeys(pagenames, 0)
with open(f"/tmp/wikipageviews/{ts_nodash}/wikipageviews", "r") as f:
for line in f:
domain_code, page_title, view_counts, _ = line.split(" ")
if domain_code == "en" and page_title in pagenames: #C
result[page_title] = view_counts
print(result)
# Prints e.g. "{'Facebook': '778', 'Apple': '20', 'Google': '451', 'Amazon': '9', 'Microsoft': '119'}"
fetch_pageviews = PythonOperator(
task_id="fetch_pageviews",
python_callable=_fetch_pageviews,
op_kwargs={"pagenames": {"Google", "Amazon", "Apple", "Microsoft", "Facebook"}},
dag=dag,
)
此打印例如 {“ Apple”:“ 31”,“ Microsoft”:“ 87”,“ Amazon”:“ 7”,“ Facebook”:“ 228”,“ Google”:“ 275”}。 作为第一个改进,我们希望将这些计数写入我们自己的数据库中。 这将使我们能够使用SQL进行查询,并提出诸如“ Google Wikipedia页面上的每小时平均综合浏览量是多少?”之类的问题。
图4.11工作流的概念图。 提取综合浏览量后,将综合浏览量写入SQL数据库。

我们有一个Postgres数据库来存储每小时的页面浏览量。 保留数据的表包含三列:
清单4.16用于存储输出的CREATE TABLE语句
CREATE TABLE pageview_counts (
pagename VARCHAR(50) NOT NULL,
pageviewcount INT NOT NULL,
datetime TIMESTAMP NOT NULL
);
其中pagename和pageviewcount列分别保存Wikipedia页面的名称和给定小时内该页面的浏览量。datetime列将保存计数的日期和时间,该间隔等于Airflows执行日期。 INSERT查询示例如下所示:
清单4.17 INSERT语句将输出存储在pageview_counts表中
INSERT INTO pageview_counts VALUES ('Google', 333, '2019-07-17T00:00:00');
上面的代码当前打印了找到的pageview计数,们现在想通过将这些结果写入Postgres表来连接这些点。PythonOperator目前只是打印结果,但不写入数据库,所以我们需要第二个任务来写入结果。在Airflow中,有两种方式在任务之间传递数据:
- 通过使用元存储在任务之间写和读结果。这便是《XCom》,我们将在第5章中介绍它。
- 通过在任务之间向一个持久化位置(例如磁盘或数据库)写入结果。
Airflow任务彼此独立运行,可能根据您的设置在不同的物理计算机上运行,因此无法共享内存中的对象。因此,任务之间的数据必须持久化到其他地方,在一个任务完成后它驻留在那里,可以被另一个任务读取。
Airflow提供了一种现成的名为XCom的机制,该机制允许存储和稍后读取Airflow元存储库中的任何可拾取对象。Pickle是Python的序列化协议。 序列化意味着将内存中的对象转换为可以存储在磁盘上的格式,以便以后可能由其他进程再次读取。默认情况下,所有由基本Python类型(例如,字符串,整数,字典,列表)构建的对象都可以被pickled。不可拾取对象的示例是数据库连接和文件处理程序。使用XComs存储pickled 的对象仅适用于较小的对象。 由于Airflow的metastore(通常是MySQL或Postgres数据库)的大小是有限的,并且pickled 的对象存储在metastore的blob中,因此通常建议仅将XComs应用于传输少量数据(例如少数几个字符串)(例如列表) 名称)。
在任务之间传输数据的另一种方法是将数据保留在Airflow之外。存储数据的方法是无限的,但通常会在磁盘上创建一个文件。 在上面的用例中,我们获取了一些本身并不占用空间的字符串和整数。考虑到以后可能会添加更多的页面,因此数据大小将来可能会增加,我们将提前考虑,将结果保存在磁盘上,而不是使用 xcom。
为了决定如何存储中间数据,我们必须知道将在哪里以及如何再次使用数据。由于目标数据库是Postgres数据库,因此我们将使用PostgresOperator将数据插入数据库中。
PostgresOperator将运行您提供的任何查询。 由于无法向Postgres查询提供CSV数据,因此我们将首先编写SQL查询作为中间数据:

运行此任务将为给定间隔生成一个文件/tmp/postgres_query.sql,其中包含要由PostgresOperator运行的所有SQL查询。 例如:
清单4.18多个INSERT查询提供给PostgresOperator
INSERT INTO pageview_counts VALUES ('Facebook', 275, '2019-07-18T02:00:00+00:00');
INSERT INTO pageview_counts VALUES ('Apple', 35, '2019-07-18T02:00:00+00:00');
INSERT INTO pageview_counts VALUES ('Microsoft', 136, '2019-07-18T02:00:00+00:00');
INSERT INTO pageview_counts VALUES ('Amazon', 17, '2019-07-18T02:00:00+00:00');
INSERT INTO pageview_counts VALUES ('Google', 399, '2019-07-18T02:00:00+00:00');
现在我们已经生成了查询,是时候连接拼图的最后一块了:
清单4.19调用PostgresOperator
from airflow.operators.postgres_operator import PostgresOperator
dag = DAG(..., template_searchpath="/tmp")
write_to_postgres = PostgresOperator(
task_id="write_to_postgres",
postgres_conn_id="my_postgres",
sql="postgres_query.sql",
dag=dag,
)
相应的“图形视图”如下所示:
图4.13 DAG每小时获取Wikipedia页面浏览量并将结果写入Postgres

一旦一系列的 DAG 运行完成后,Postgres 数据库将进行一些计数:
"Amazon",12,"2019-07-17 00:00:00"
"Amazon",11,"2019-07-17 01:00:00"
"Amazon",19,"2019-07-17 02:00:00"
"Amazon",13,"2019-07-17 03:00:00"
"Amazon",12,"2019-07-17 04:00:00"
"Amazon",12,"2019-07-17 05:00:00"
"Amazon",11,"2019-07-17 06:00:00"
"Amazon",14,"2019-07-17 07:00:00"
"Amazon",15,"2019-07-17 08:00:00"
"Amazon",17,"2019-07-17 09:00:00"
在这最后一步中,有许多事情需要指出。 DAG有一个附加参数“ template_searchpath”。除了字符串之外,文件的内容也可以模板化。每个operator 都可以通过向operator提供文件路径来对具有特定扩展名的文件进行模板化。对于 PostgresOperator,参数“ SQL”是模板化的,因此也可以提供一个包含 SQL 查询的文件路径。 任何以“ .sql”结尾的文件路径都将被读取,文件中的模板将被渲染,文件中的查询将由PostgresOperator执行。同样,请参考操作符[13]的文档,并检查“template_ext”字段,该字段包含可由operator模板化的文件扩展名。
Jinja要求您提供搜索模板文件的路径。 默认情况下,仅在DAG文件的路径中搜索“ postgres_query.sql”,但是由于我们将其存储在/ tmp中,因此Jinja找不到该文件。要为Jinja添加搜索路径,请在DAG上设置参数template_searchpath,Jinja将遍历默认路径以及要搜索的其他提供的路径,在本例中为postgres_query.sql。
Postgres是一个外部系统,在Airflow生态系统中的许多operators 的帮助下,Airflow支持连接到各种外部系统。这确实有一定的含义; 连接到外部系统通常需要安装特定的依赖项,这些依赖项允许与外部系统进行连接和通信。这也适用于 Postgres; 我们必须使用pip install apache-airflow [postgres]安装Airflow才能在我们的Airflow安装中安装其他Postgres依赖项。许多依赖关系是任何业务流程系统的特征之一-为了与许多外部系统进行通信,不可避免的是在您的系统上安装许多依赖关系。
尽管在使用BashOperator和PythonOperator时我们自己提供了几行代码,但是连接到外部系统的operators 通常是一个练习,例如 提供SQL查询或提供要发送的消息和电子邮件地址。 以PostgresOperator为例:

PostgresOperator 只需要填写两个参数就可以对 Postgres 数据库运行查询。复杂的操作,例如建立到数据库的连接并在完成后关闭数据库,都是在引擎盖下处理的。 postgres_conn_id参数指向保存到Postgres数据库的凭据的标识符。 Airflow可以管理此类凭据(在metastore中存储加密),operators 可以在需要时获取其中一个凭据。 无需赘述,我们可以借助CLI在Airflow中添加“ my_postgres”连接:

然后,该连接在UI中可见(也可以在其中创建)。 转到管理->连接以查看存储在Airflow中的所有连接:
图4.14 Airflow UI中列出的连接

在执行 PostgresOperator 时,会发生以下几种情况:
图4.15对Postgres数据库运行SQL脚本涉及几个组件。 为PostgresOperator提供正确的设置,PostgresHook将在后台进行工作。

PostgresOperator 将实例化一个所谓的 Hook 来与 Postgres 通信。钩子处理创建一个连接,发送查询到 Postgres,然后关闭连接。在这种情况下,operator 只是将用户的请求传递给钩子。
operator 确定必须执行的操作,钩子确定如何执行操作。
当构建这样的管道时,您将只处理运算符,而没有任何钩子的概念,因为钩子是在运算符内部使用的
在一系列 DAG 运行之后,Postgres 数据库将包含从 Wikipedia 页面浏览中提取的一些记录。每小时一次,Airflow现在自动下载新的每小时综合浏览量数据集,将其解压缩,提取所需的计数并将其写入Postgres数据库。 现在,我们可以问诸如“每个页面哪个小时最受欢迎”之类的问题。
清单4.20 SQL查询询问每个页面中哪个小时最受欢迎
SELECT x.pagename, x.hr AS "hour", x.average AS "average pageviews"
FROM (
SELECT
pagename,
date_part('hour', datetime) AS hr,
AVG(pageviewcount) AS average,
ROW_NUMBER() OVER (PARTITION BY pagename ORDER BY AVG(pageviewcount) DESC)
FROM pageview_counts
GROUP BY pagename, hr
) AS x
WHERE row_number=1;
向我们展示了查看给定页面的最受欢迎时间是在16:00和21:00之间:
表4.2查询结果显示每页哪个小时最受欢迎
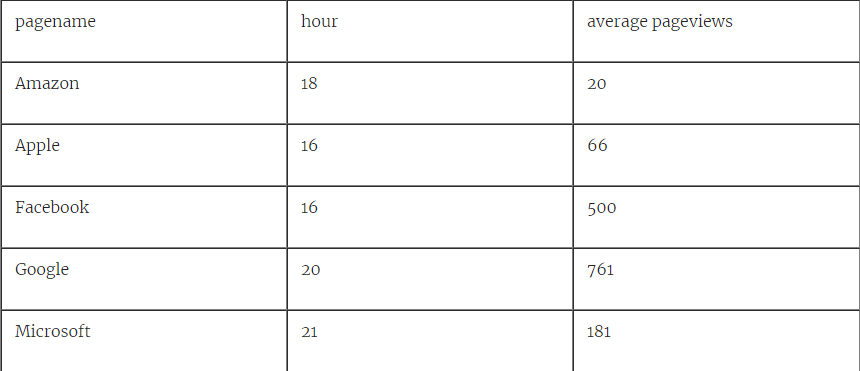
通过此查询,我们现在已经完成了预想的Wikipedia工作流程,并将执行下载小时浏览量数据,处理数据并将结果写入Postgres数据库以进行将来分析的完整周期。Airflow负责安排启动任务的正确时间和顺序。在任务运行时上下文和模板的帮助下,使用该间隔附带的datetime值,按照给定的间隔执行代码。如果所有设置都正确,工作流现在可以无限运行。
4.4 摘要
-
operators 的某些参数可以模板化
-
模板在运行时发生
-
模板化PythonOperator的工作方式不同于其他运算符; 变量被传递到提供的可调用对象
-
可以使用airflow render测试模板化参数的结果
-
Operators 可以通过钩子与其他系统进行通信
-
Operators 描述做什么,钩子决定如何做工作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号