李宏毅深度学习笔记-结构化学习简介
什么是结构化学习
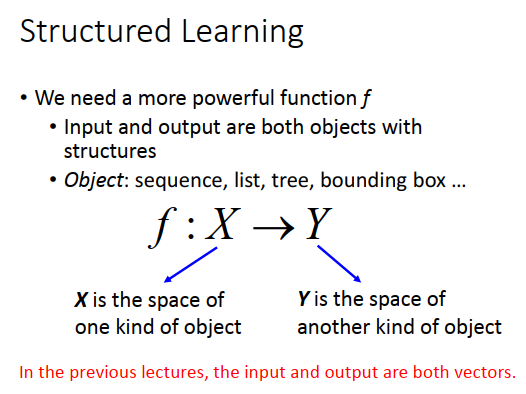
什么是结构化学习?
当目前为止,我们考虑的问题input都是一个向量,output是另外一个向量,不管我们在做SVM还是做deep learning,input和output都是向量。
实际我们真正要面对的问题,可能input或者output是一个sequence,可能希望output是一个list、tree、bounding box等等。比如在recommendation的final里面,希望output直接是一个list,而不是一个个element。当然,大原则上我们知道怎么做,就是要找一个function,它的input就是我们要的object(比如tree之类的),output就是另外一种object,只是我们不知道要怎么做。比如我们目前学过的deep learning的神经网络的架构,你可能不知道怎么兜个神经网络,它的input才会是一个tree structure,output才会是另外一个tree structure。

像这种结构化的学习,有非常多的应用。比如:
语音识别,input一个sequence,output另外一个sequence
翻译,input一个语言的sequence,output另外一个语言的sequence
句法解析,input一个sentence,output一个语法解析树
目标检测,input一张图片,output是object的位置,用一个bounding box框出来
Summarization(总结),input是一个document,output是summary的结果。input 和output都是一个sequence。
Retrieval(搜索),input是搜索的关键词,output是搜索的结果,是一个list,也是一个有结构的东西。
统一框架
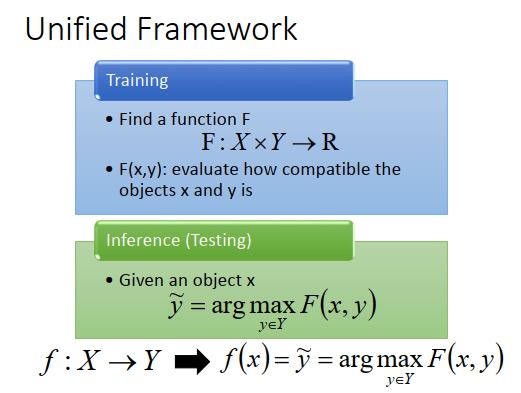
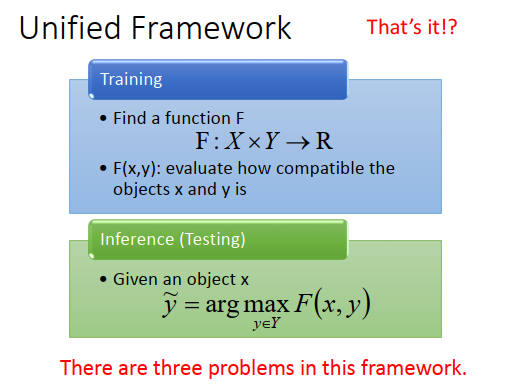
结构化学习怎么做呢?虽然这个结构化学习听起来很困难,但是实际上有个统一框架。
在训练的时候,就是找到function,写作\(F\),\(F\)的input是\(X\)和\(Y\)(之前是小写的\(f\),input是\(X\),output是\(Y\)),output是一个real number。\(F\)做的事情是衡量出输入\(x\)、输出\(y\)都是结构化对象时,\(x、y\)有多匹配,越匹配,output \(R\)的值越大。
假设我们找出\(F\)了,那testing的时候怎么做呢?
给定一个新的x,去穷举所有可能的y,一一带进大写的\(F\) function,看哪一个y可以让\(F\)函数值最大。
能让\(F\)值最大的\(\widetilde{y}\)就是最后的结果,也就是model的output。
之前我们要做的事情,是找一个小写的\(f\),input \(X\) output \(Y\),可以把它想象成\(f(x)=\widetilde{y}=arg\max\limits_{y\in Y}F(x,y)\)。这样讲可能比较抽象,讲一下实际的例子。
目标检测

现在我们要做的任务是,给一张图片,现在机器的任务是找出图片里我们要它找的对象。举例来说,我们的input是一张图片,output是一个Bounding Box,假设我们要做一个凉宫春日的检测器,input是一张图片,output一个Bounding Box,就是凉宫春日在的位置。
你可能说侦测凉宫春日有什么用,这个其实没什么作用。但是有其他的作用,比如侦测人脸呀,无人驾驶呀(有没有车子)。
在做finding Bounding Box的时候,你可以用别的方法,比如用Deep Learning。事实上,Deep Learning 和Structured Learning是有关系的,这是个人的想法。我认为GAN与Structured Learning就非常有关系,GAN就是框架的一种方法。
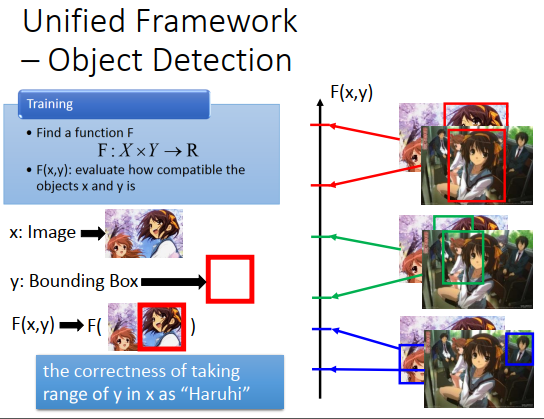
Object Detection是怎么做的呢?
你的input就是一张图片,\(y\)就是一个Bounding Box,\(F(x,y)\)就是说,假设这个张图片配上红色框框的bounding box,它有多匹配,如果是Haruhi检测的例子,就是它有多准确,有没有真的把凉宫春日框出来。所以你会期待你的model(\(F\))可以做到的事情是,给一张图,如果框地比较正确(红色框框),那么\(F(x,y)\)的值就会很高,框在绿色框框有一点不对,框在蓝色框框上就很不对,另外给一张图也是如此。
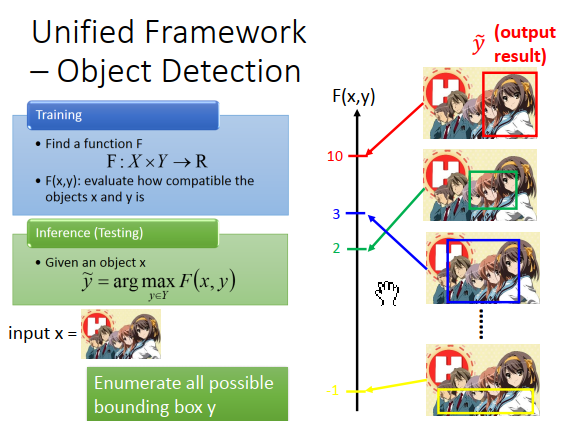
接下来testing的时候,给一张\(x\)(从来没有看过的图),穷举所有可能的bounding box(可以画在红色,绿色,蓝色,黄色框框,各个不同可能的地方)。然后看哪一个bounding box 得到的分数最高,可能红色得到10分,绿色2分,蓝色3分,黄色-1分等等。那么红色分数最高,所以红色就是model的output(\(\widetilde{y}\))
摘要提取
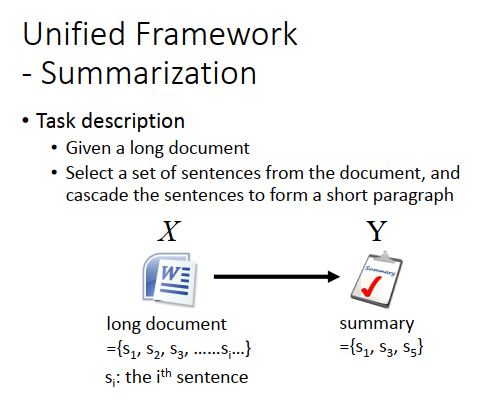
在别的task里面,其实也是差不多的。假设要做summarization,summarization task 就是input一个长的document(有很多句子),output是一个summary,summary可以从document上取几个句子出来(一个subset)。
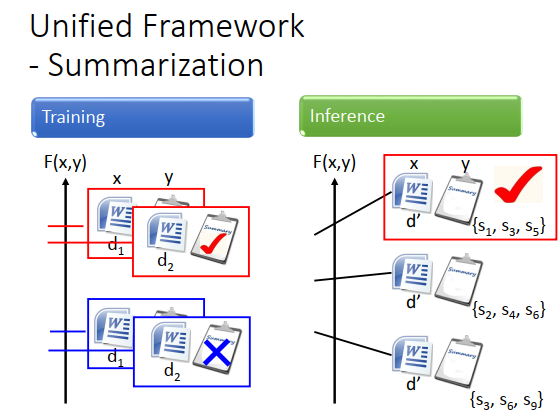
训练的时候,当document(x) 和summary(y)配成一对时,\(F(x,y)\)的值就很大,document和不正确的summary配对时,\(F(x,y)\)的值就很小,如上图左边所示,那么对每一个训练数据都这么做。
testing的时候,穷举所有可能的summary,如上图右边所示,看哪个summary让\(F\)的值最大,这个summary就是正确的output。
搜索
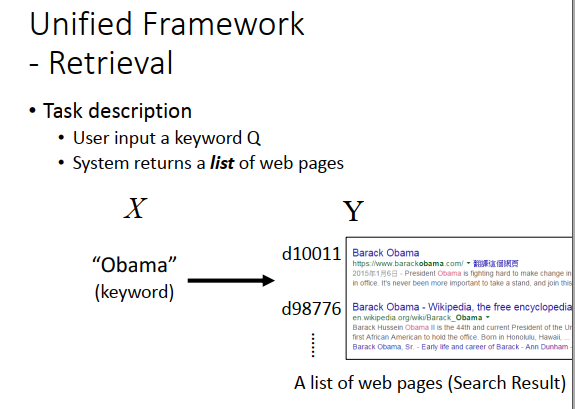
搜索的时候也一样,retrieval的task,input是一个查询集,output是一个搜索的结果(webpages的list)。
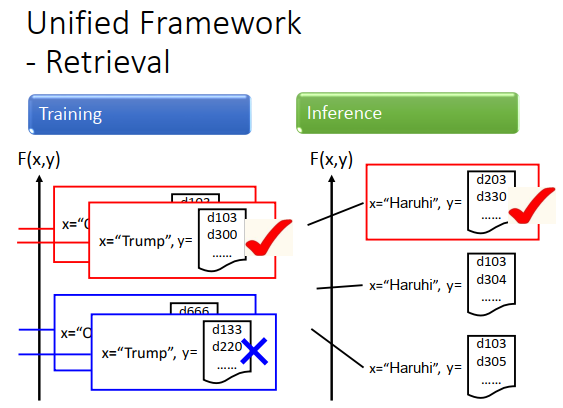
训练的时候,我们需要一些训练数据知道说input这个Query的时候,output哪一个list,才是perfect。input“Obama”的时候,output红色框框的list是perfect的,所以\(F(x,y)\)分数比较高,output蓝色框框的list是不对的,所以分数比较低。同样,input“Trump”的时候,output红色框框里的list是对的,所以分数比较高,output蓝色框框里的list是不对的,所以分数比较低。
做搜索的时候,有人输入一个“凉宫春日”,就穷举所有可能的list,看哪一个list分数最高。你可能觉得穷举所有可能太过荒谬,但这都是可以做的,你只要想一个好的演算法去解这个问题。

这个统一框架你听着可能觉得很陌生,怎么会突然出现一个\(F\),那么换一个说法。
我们在训练的时候是要估计\(x\) 和\(y\) 的联合概率\(P(x,y)\) ,这个概率也是一个函数,input就是\(X,Y\),output是介于0到1的值。在做testing的时候,给我一个object \(x\),去计算所有的\(P(y|x)\),哪一个\(y\)的概率最高就是model的输出\(\widetilde{y}\)。\(P(y|x)\)可以表示为\(\frac{P(x,y)}{P(x)}\) ,\(P(x)\)和结果没有关系,所以真正做得事情就是看\(P(x,y)\)。而\(F\)就是\(P\),inference也相同。
我们刚才讲\(F(x,y)\),你会疑惑计算\(x,y\)有多相容到底在讲什么。那把它换成计算\(x,y\)的联合概率,在testing的时候根据这个概率找最有可能出现的\(y\) ,这样会不会比较接受一点。

用概率有什么坏处?
有时候用概率很怪,比如说我们做搜索,\(x\)是查询值,\(y\)是搜索的结果,然后衡量查询值和搜索结果共同出现的概率就有点怪。
概率限定在0到1,summation over \(y\)等于1,那现在是一个有结构的东西,\(x,y\)都是一个很大的空间,要做这个summation很难。
用概率有什么好处?
概率是标准化的,比较容易想象是什么样的东西
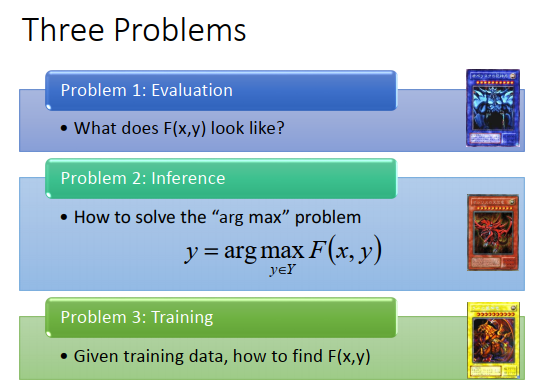
这个统一框架听起来好像很厉害,其实要做这个统一框架需要解三个问题。

第一个问题是,\(F(x,y)\)长什么样子。
你很难想象\(F(x,y)\)到底应该长什么样子。如果input是一个图片和一个bounding box,那\(F(x,y)\)应该长什么样子。input是keyword和list,\(F(x,y)\)又应该长什么样子。

第二个问题是,怎么解“arg max"。
这个\(y\)是很大的,比如说你要做目标检测,就要穷举所有可能的bounding box。

第三个问题,如何训练。
我们希望正确的\(F(x,\hat{y})\)值最大。
只要解出这三个问题,你就可以做Structured Learning。GAN可能是解这三个问题的solution,虽然你看不出来GAN跟这个有什么关系。

这三个问题,你在别的地方可能有听过,如果你学过数位语音处理。在讲HMM的时候,HMM有三个问题,这三个问题就是普通Structured Learning的三个问题。
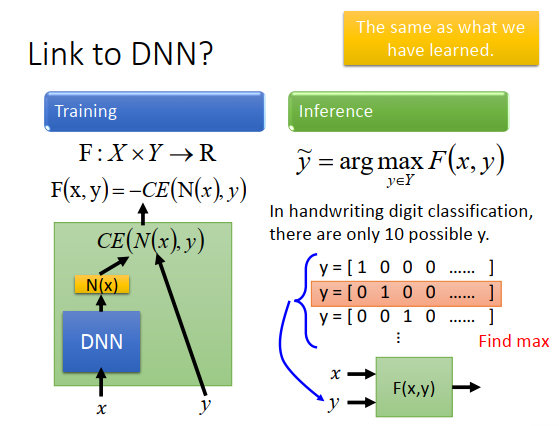
这个东西也可以跟DNN联系在一起,比如我们要做手写数字识别,input一个图片,把它分成10类。那我的\(F\)长什么样子呢,就如上图左下方所示,先把\(x\)丢进一个DNN得到一个训练\(N(x)\),接下来再input \(y\)(\(y\)是一个向量,做手写识别时是一个10维的向量),\(y\)只有一维是1,其他维都是0。把这个y和N(x)算cross entropy,negative 这个\(CE(N(x),y)\)就是\(F(x,y)\)。
在testing的时候,穷举所有可能的辨识结果(10个),每个都带进\(F(x,y)\)里面,看哪个辨识结果能够让\(F(x,y)\)最大。如果使用cross entropy定义两个向量(\(N(x),y\) )之间的差距的话,就看哪一个digit能让cross entropy最小(也就是\(CE(N(x),y)\)最小),这跟我们训练神经网络用cross entropy作为损失函数时做得事情是一模一样的。之前讲的东西是Structured Learning的一个特例。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号