离线数仓和实时数仓区别?
这里有一个很具体的例子。
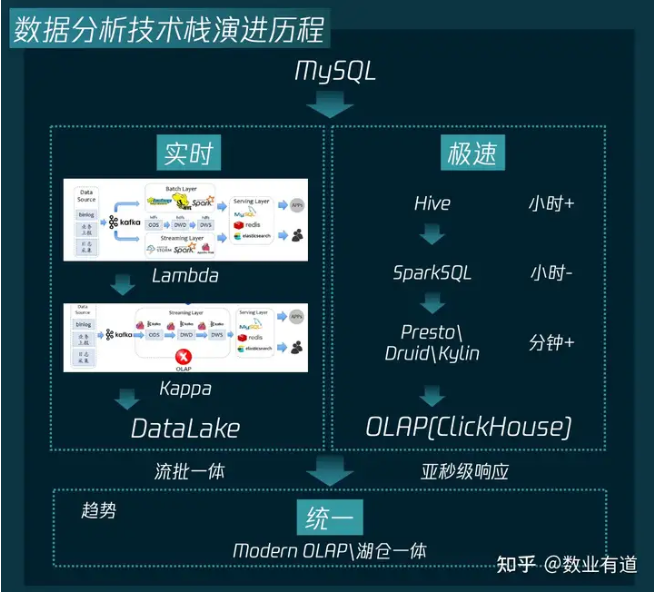
很久很久以前,微信的数据分析架构还是完全基于 Hadoop 生态的,查询非常慢,数据延迟高,数据开发也很慢,另外在架构方面采用的是流批分离,整体非常臃肿。
这也算是Hadoop生态的通病了,大厂也不能幸免。
后来随着业务发展,视频号等推荐系统对个性化体验的强烈诉求,微信基于 ClickHouse 内核打造了亚秒级的 OLAP 实时数仓,广泛用于 A/B 实验平台、BI 分析、实时指标计算等场景中。
在基于 ClickHouse 的实时数仓中,做到了亿行数据的亚秒级响应,海量数据的低延迟、精确一次接入,实现了流批一体架构。
在微信的数据分析场景中,数据规模很大,单表日增万亿,单次查询扫描数据量在10亿以上;查询耗时要求极高,TP 90 需要在5秒以内,同时要求数据低时效(秒/分钟);希望能够实现计算侧和存储侧的统一。
在基于 ClickHouse 的实时数仓中,已经解决了海量数据和极速的挑战,但还有一个统一的需求没有解决。
另外,通用大数据计算引擎处理 OLAP 数仓体验割裂、存储多份的问题。过去,无论是在湖上面还是仓上面,都存在着相应的困境。
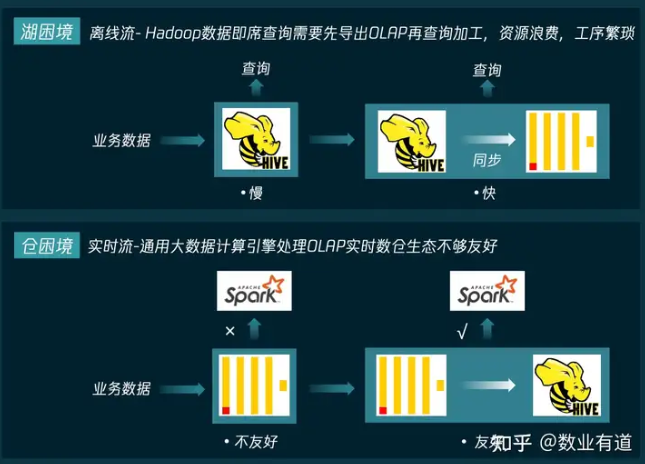
湖上面面临的主要问题是查询性能太慢,如果需要对 Hadoop 中的数据进行即席查询,则需要先将数据导出到 OLAP 数据库中再进行查询加工,造成了资源的浪费,工序繁琐。
而仓上面,存在着通用大数据计算引擎处理 OLAP 实时数仓生态不够友好的问题,例如,Spark 无法直接分析 ClickHouse 中的数据,如果要进行查询分析,则需要先将数据从 ClickHouse 落回 Hive 中。
所以后来开始做湖仓一体。
实现湖仓一体的第一种技术路线是湖上建仓,即在数据湖基础上实现数仓的功能,代替传统数仓,构建 Lakehouse。
具体来说,在传统 Hadoop 系统中引入 Delta lake、Hudi、Iceberg 或 Hive 3.0 等更新技术;引入 Presto、Impala 等 SQL on Hadoop 查询引擎;引入 Hive Meta Store 进行统一元数据和权限管理;引入对象存储作为底层存储等数仓特性,形成湖仓一体。
这方面比较有代表性的是 Databricks 提出的湖仓一体架构。
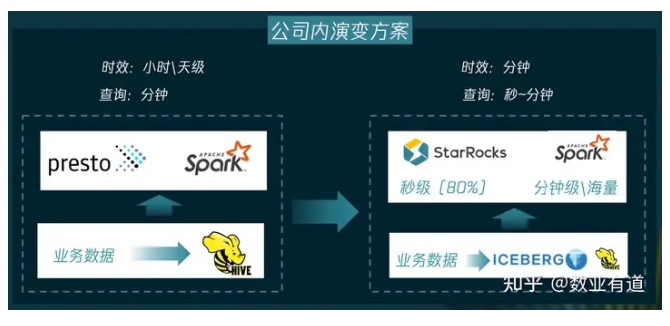
在微信内部,湖上建仓的架构经历了从 Presto+Hive 到 StarRocks + Iceberg 的演变过程,通过使用 StarRocks 替代 Presto,数据的时效性从小时/天级提高到了分钟级,同时查询效率从分钟级提高到了秒级/分钟级,其中80%的大查询用 StarRocks解决,秒级返回,剩下的超大查询通过 Spark 来解决。
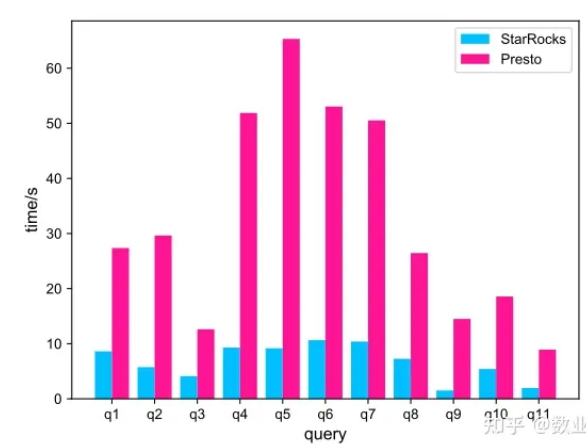
与 Presto 相比,StarRocks 直接查湖的性能提升 3-6 倍以上。
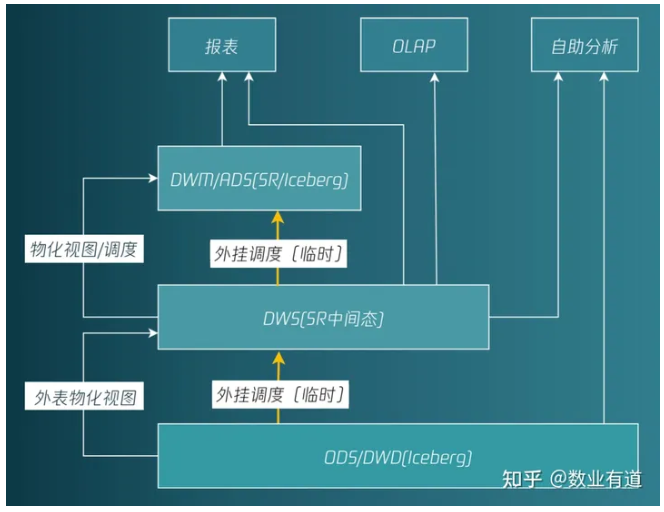
目前,湖上建仓的方案主要通过外挂调度的方式来实现,这个方案成本低,实现简单,同时 Hadoop 生态兼容性更好。但数据延迟较高,需要5-10分钟左右;另外,ODS、DWD 层的查询会比较慢,需要通过本地缓存等方式来进行加速。
综合来看,湖上建仓的方案主要还是湖为主,更适合于离线分析为主的场景。
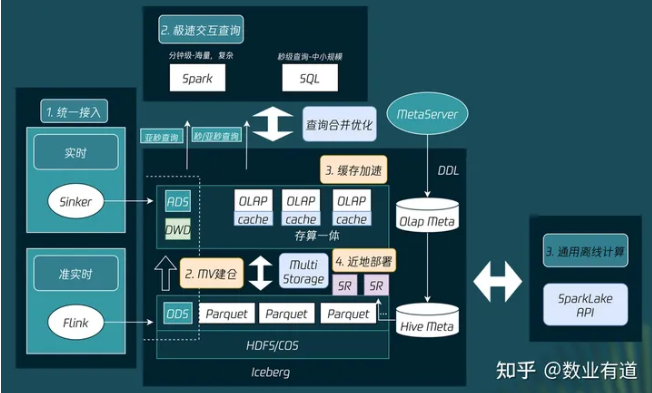
实现湖仓一体的第二种技术路线是仓湖融合,通过在数仓中加入跨源融合联邦查询的功能,打通内容存储,从而不需要经过 ETL 能够直接分析数据湖。

链接:https://www.zhihu.com/question/512215713/answer/3333698512
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
这个方案中,数据会先实时接入仓,之后,冷存经过转换下沉到湖,通过 Meta Server 实现仓湖元数据的统一管理,在查询时,能够合并冷热数据读取,同时,通过 SparkLake API 提供对通用离线计算的支持。
在该方案中,由于数据是先落仓的,因此数据的实时性会更高,在秒级到2分钟以内,同时 DWD 层的查询响应会更快。但其缺点是成本高(热数据TTL),Hadoop 生态兼容性不如湖上建仓的方案。
综合来看,仓湖融合的方案主要还是考虑仓为主,更适合于实时分析为主的场景。
当前,仓湖融合、冷存下沉的湖仓一体方案已经在微信安全的业务场景中落地,接入的大表每日数据量达数十亿,超大表每日数据量千亿以上。小时分区降冷耗时分钟级,天分区降冷耗时小时级;在内存消耗方面,单任务最大消耗 5GB 左右,对集群无明显影响。
湖上建仓和仓湖融合两种方案各有优缺点,分别适用于湖为主和仓为主的业务场景,而在微信的业务场景中,两种路线都有需求。
因此,微信湖仓一体方案,采用的是湖上建仓和仓下沉湖的融合方案。
该方案同时支持实时接入和准实时接入,用户可以根据自身对成本、性能和数据时效性的要求来选择通过哪种方式进行接入,并且是可切换的。
例如,刚开始时,用户对性能、数据时效性要求不是特别高,那么可以选择通过湖接入的方式,这样成本较低,当后续该用户对性能和数据时效性要求变高了,那么他可以切换到仓接入的方式,这样就可以满足需求。
这个套路既能够支持极速 BI 分析的场景,也能够满足通用离线计算的需求。
https://www.zhihu.com/question/512215713/answer/3333698512

 浙公网安备 33010602011771号
浙公网安备 33010602011771号