论文-PromDA: Prompt-based Data Augmentation for Low-Resource NLU Tasks
论文地址:https://arxiv.org/abs/2202.12499
代码地址:https://github.com/GaryYufei/PromDA
0.摘要
本文主要研究低资源自然语言理解(NLU)任务的数据扩充。我们提出了基于Prompt的数据增强模型(PromDA),该模型仅在冻结的预训练语言模型(PLMs)中训练小规模的软提示(即一组可训练向量)。这避免了人工收集未标记的in-domain数据,并保持了生成的合成数据的质量。此外,PromDA通过两种不同的视图生成合成数据,并使用NLU模型过滤掉低质量的数据。在四个基准上的实验表明,PromDA生成的合成数据成功地提高了NLU模型的性能,这些模型的性能始终优于几个竞争性基线模型,包括使用未标记领域内数据的最先进的半监督模型。PromDA的合成数据也与未标记的域内数据互补。当NLU模型结合起来进行训练时,可以进一步改进它们。
1.引言
深度神经网络通常需要大规模高质量的标记训练数据来实现最先进的性能(Bowman等人,2015)。然而,在许多情况下,构建标记数据可能具有挑战性(Feng等人,2021年)。在本文中,我们研究了低资源自然语言理解(NLU)任务,包括句子分类和序列标记任务,其中只有少量标记数据可用。以前的工作通常会产生额外的标记数据,供NLU模型学习。
Wang et al.(2021a)部署了自训练框架,以从未标记的域内数据中生成伪标记的训练数据,这可能需要昂贵的获取成本。徐等人(2021年)研究表明,从通用语料库中提取特定领域(域内)的未标记数据并非易事。魏和邹(2019);Dai和Adel(2020)使用自动启发式规则(如随机同义词替换)扩展了原始的小训练数据,有效地创建了新的训练实例。然而,这些过程可能会扭曲文本,使生成的语法数据在语法和语义上都不正确。
为了解决上述困境,许多现有的研究(丁等人,2020年;杨等人,2020年;阿纳比塔沃等人,2020年)都求助于在低资源环境下应用语言模型(LMs)或预先训练的语言模型(PLM)进行数据扩充。给定标记的数据,可以直接微调PLM以生成新的合成数据,而无需额外的人力。然而,我们认为,在低资源NLU任务中,使用较小的训练数据(尤其是当样本少于100个时)直接微调PLM的所有参数可能会导致过度拟合,PLM只会记住训练实例。因此,生成的合成数据可能与原始训练实例非常相似,无法向NLU模型提供新的训练信号。最近,一些作品(李斯特等人,2021;李和梁,2021)提出了快速调整,它只向后传播错误到软提示上(软提示即一个连续的向量序列的PLMS的输入)【冻结其他参数,只调整软提示?】,而不是整个模型。它们表明,快速调整足以与全模型调整竞争,同时显著减少要调整的参数数量。因此,快速调整非常适合解决上述低资源生成性微调中的过拟合问题,在保证生成质量的前提下,相对于小标记数据生成更多新样本。
基于此,我们提出了基于提示的数据扩充模型(PromDA)。具体来说,我们冻结了整个预先训练的模型,只允许在微调小的标记训练数据时调整额外的软提示。此外,我们还观察到,软提示的初始化对微调有重大影响,尤其是在资源不足的情况下达到极端程度时。为了更好地初始化数据扩充任务的提示参数,我们提出了“任务不可知同义词关键字语句task-agnostic Synonym Keyword to Sentence”预训练任务,直接在预训练语料库上pre-train PLMs的提示参数。
此任务模拟从部分片段信息(例如关键字)生成整个训练样本的过程。与之前的工作(丁等人,2020年;杨等人,2020年;阿纳比·塔弗等人,2020年)类似,我们可以微调PLM,以根据输出标签生成完整的合成数据。我们称之为输出视图生成Output View Generation。
为了提高生成样本的多样性,我们引入了另一个微调生成任务“输入视图生成Input View Generation”,该任务将从样本中提取的关键字作为输入,将样本作为输出。
由于从小训练数据训练的NLG模型仍然有一定的机会生成低质量样本,我们利用NLU一致性过滤(Anaby Tavor等人,2020)来过滤生成的样本。
我们在四个基准上进行了实验:序列标记任务CoNLL03(Tjong Kim Sang and De Meulder,2003)和Wikiann(Pan等人,2017),句子分类任务SST-2(Socher等人,2013)和RT(Pang and Lee,2005)。实验结果表明,基于PromDA合成数据训练的NLU模型在序列标记任务上始终优于几种竞争性基线模型,包括最先进的半监督NLU模型MetaST(Wang等人,2021a)。此外,我们发现PromDA的合成数据与未标记的域内数据也是互补的。将两者结合起来,可以进一步提高NLU模型的性能。最后,我们进行了多样性分析和案例研究,以进一步确认PromDA的合成数据质量。
2.相关工作
①Prompt Learning
基于提示学习的概念始于GPT3模型(Brown等人,2020)。之前的工作设计了不同的提示,以查询语言模型,以提取知识三元组(Petroni等人,2019年)或在few-shot设置下将句子分类为预定义类别(Schick和Sch tze,2021年)。他们为这些任务手动构建各种离散的提示。为了减少人类在这个选择过程中的努力,(Gao等人,2021年)建议使用预先训练过的语言模型来扩展提示。然而,离散提示的选择仍然是一个独立的过程,很难与下游任务一起以端到端的方式进行优化。Ben David等人(2021年)提出了一个复杂的两阶段模型来连接即时生成和下游任务。为了解决这个问题,(李斯特等人,2021;李和梁,2021)提出使用软提示,这是可训练向量的集合,在冻结的预训练语言模型中。与硬提示不同,这些向量与任何实际单词都不对应。它允许以端到端的方式对下游任务进行优化。如Li和Liang(2021)所示,带有软提示的PLM通常在低资源设置下表现更好。
②Generative Data Augmentation
Hou等人(2018年)生成不同的话语,以改进对话理解模型。Xia等人(2019)使用双语词典和无监督机器翻译模型来扩展低资源机器翻译训练数据。吴等(2019);Kumar等人(2020年)在许多PLM预训练目标函数(例如BERT(Devlin等人,2019年)、BART(Lewis等人,2020年))中使用掩码机制,并通过掩码原始训练实例中随机选择的单词来生成新的合成数据。丁等人(2020);杨等人(2020年);Anaby Tavor等人(2020年)应用LMs和PLM直接学习为NLU任务生成新的合成数据(即,在对相对较大的训练数据进行训练(微调)后,序列标记和常识推理任务)。这些工作通常直接应用现成的LMs或PLM生成合成数据。Wang等人(2021b)建议使用未标记的数据作为硬提示,在无需任何训练的情况下生成合成数据,从而限制了其在复杂NLP任务中的应用。据我们所知,PromDA是第一款带有软提示的PLM,专门为数据增强任务而设计。
3.Prompt-based Data Augmentation
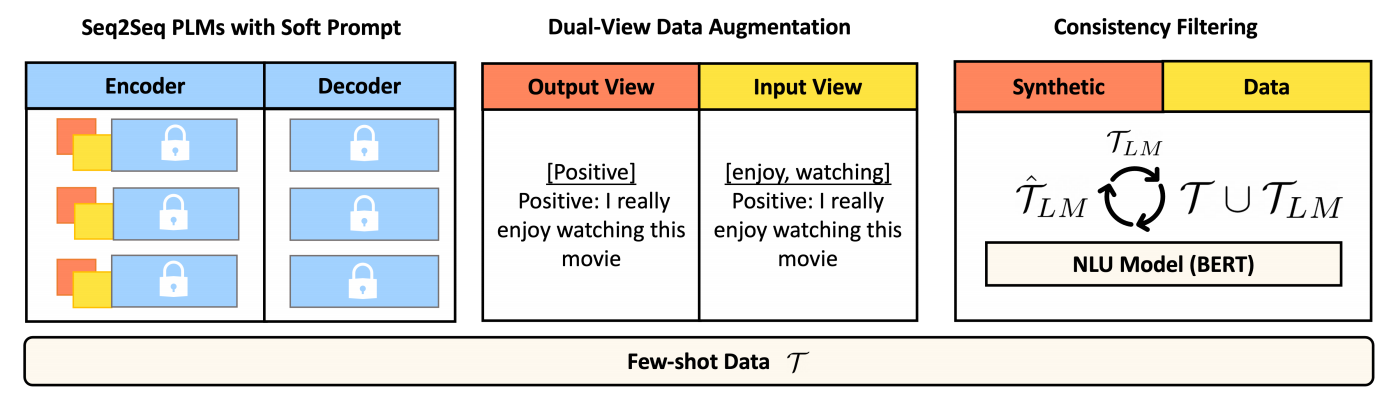
本节首先阐述了低资源NLU任务的数据扩充。然后,我们介绍了我们提出的基于提示的数据增强方法(PromDA)的三个重要组成部分,包括i)在预先训练的语言模型中基于提示的学习;ii)双合成数据生成视图和iii)一致性过滤。图1显示了PromDA的总体结构。
图1:PromDA的总体情况。软提示是预先设定一个可训练向量序列,冻结PLM的每一层。白色储物柜代表冻结的参数。我们有独立的软提示集来支持DaulView数据扩充,其中Output View基于output tags和Input View基于输入句子中的关键字。最后,我们使用NLU模型来迭代过滤低质量的合成数据,并使用剩余的合成数据,结合T来训练更强的NLU模型。
3.1Data Augmentation For NLU tasks
在低资源NLU任务中,只有一组标记的训练数据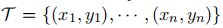 在n相对较小(即小于100)的情况下可用。数据增强生成综合标记训练数据
在n相对较小(即小于100)的情况下可用。数据增强生成综合标记训练数据
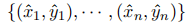 来自使用语言模型的原始标记训练数据T。目标是,使用
来自使用语言模型的原始标记训练数据T。目标是,使用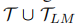 训练的NLU模型优于仅使用
训练的NLU模型优于仅使用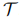 训练的NLU模型。
训练的NLU模型。
3.2Prompt-based learning
微调是使PLM适应特定下游任务的普遍方式(Devlin等人,2019年)。然而,对于低资源数据扩充,我们期望生成的合成训练数据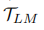 不同于,并为NLU模型提供新的学习信息。微调PLM(偏向于少量训练实例)可能不是最佳解决方案。
不同于,并为NLU模型提供新的学习信息。微调PLM(偏向于少量训练实例)可能不是最佳解决方案。
基于提示的学习,从GPT3中的zero-shot指令开始(Brown et al.,2020),将整个PLMs参数冻结,并且仅在任务输入之前预先准备离散的自然语言任务指令(例如翻译成英语)。冻结PLMs参数可能有助于训练期间的泛化。然而,找到合适的离散任务介绍并不能以端到端的方式轻松优化,需要额外的人力。在本文中,灵感来自最近的工作(李斯特等人,2021;李和梁,2021),我们用软提示替换任务介绍(即,连续和可训练向量的序列)。在培训期间,我们只更新此软提示的参数,并修复所有PLMs参数。我们主要关注使用基于seq2seq Transformer的PLM生成合成训练数据。
与Lester等人(2021年)只在输入层预先设置了软提示不同,Lester等人(2021年)受Adapter(Houlsby等人,2019年)的启发,在每个transformer层添加了可训练多层感知器(MLP Multi-layer Perceptron),我们在每个transformer层预先设置了一系列可训练向量。我们表示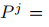
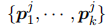 作为第j层的软提示。transformer模型中第j层的第i个隐藏状态为
作为第j层的软提示。transformer模型中第j层的第i个隐藏状态为 ,定义如下:
,定义如下:
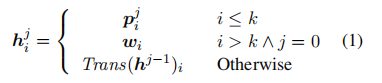
其中Trans()是transformer层的前向函数,wi是输入层的固定字嵌入向量。与(Lester等人,2021年)相比,这允许在每一层更新梯度,更好地完成学习任务。
3.3Pre-training for Prompt Initialization
软提示P的参数初始化对生成的合成数据质量有重要影响,尤其是在低资源数据扩充任务中。Lester等人(2021年)建议在不使用提示参数的情况下,进一步预训练完整的PLMs参数,以增强提示能力。然而,这种策略(即,完整的PLM预训练)引入了大量的计算开销,并且没有提供任何关于快速初始化的见解。相反,我们建议用冻结的PLM直接预训练软提示的参数。鉴于数据扩充从部分信息(如输出标记和关键字)生成完整的语法数据,我们提出了同义词关键字来完成句子预训练任务。给定一段文本,我们使用无监督的关键词提取算法Rake(Rose等人,2010)提取关键词。我们通过WordNet(Fellbaum,2010)将一些提取的关键词随机替换为同义词。给定这些同义词关键字,对软提示进行预训练,以重建原始文本块。当应用此软提示进行数据扩充时,我们只需要使用标记为data T的few-shot微调软提示。这种预培训过程只发生一次。我们只使用任务不可知的通用预训练语料库。
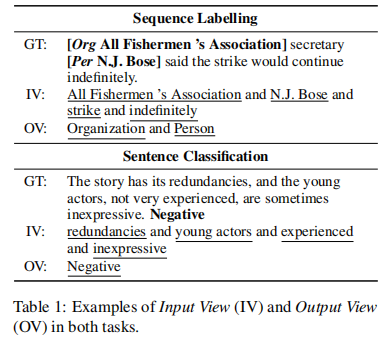
3.4Dual-View Data Augmentation
以前的工作通常将编码器输入限制为固定关键字或有限标签,例如无条件生成(Yang等人,2020年)和label-conditional生成(Anaby Tavor等人,2020年)。相对较小的输入空间可能会产生类似的输出。为了丰富输入空间,我们提出了双视图数据扩充,它从输入视图(以输入句子中的关键字为条件)和输出视图(以输出标签为条件)生成合成数据。表1显示了这两种视图的示例。如算法1(第2行至第7行)所示,在PLMs中微调软提示后,PromDA首先分别从输入视图和输出视图生成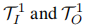 。PromDA然后从T1 I中提取输出标签,从T1 O中提取关键字。这些新的输出标签和关键字被输入到MLM的输出视图和输入视图中,以生成另外两组新的合成数据T2 O和T2 I。这样,生成的输出文本应该保持更高水平的多样性,并包含更多新颖的单词/短语/知识。
。PromDA然后从T1 I中提取输出标签,从T1 O中提取关键字。这些新的输出标签和关键字被输入到MLM的输出视图和输入视图中,以生成另外两组新的合成数据T2 O和T2 I。这样,生成的输出文本应该保持更高水平的多样性,并包含更多新颖的单词/短语/知识。

①Dual View via Prompt Ensemble
通过不同神经模型的快速集成,双视图通常可以获得更好的性能(Hansen和Salamon,1990)。基于Prompt的学习提供了一种有效的集成建模方法。通过训练K组软提示,我们创建了K个共享相同冻结PLM的模型。在我们的例子中,经过提示预训练后,我们将输入视图和输出视图视为两个独立的模型,并使用软提示参数P初始化Pinput和Poutput的参数。在PromDA微调过程中,来自输入视图和输出视图训练实例的梯度仅分别应用于参数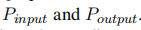 。该提示集成允许两个视图独立生成合成数据。因此,最终输出应该包括各种现实世界的知识。
。该提示集成允许两个视图独立生成合成数据。因此,最终输出应该包括各种现实世界的知识。
由于PromDA是从较小的训练数据中训练出来的,因此有可能生成低质量的样本。我们利用NLU一致性过滤(Anaby Tavor等人,2020年)来过滤生成的样本。具体地说,给定PromDA生成的带有标签的合成数据,我们使用NLU模型再次标记这些数据,并且只保留PromDA和NLU模型输出一致的实例。如算法1(第8行至第12行)所示,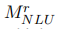 将原始合成数据
将原始合成数据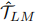 过滤成
过滤成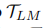 ,并与few-shot标记数据T组合,以训练新的NLU模型
,并与few-shot标记数据T组合,以训练新的NLU模型 。由于
。由于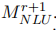 通常比
通常比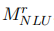 更好,我们将此过程迭代N次,以获得更强的NLU模型。
更好,我们将此过程迭代N次,以获得更强的NLU模型。
4.实验
本节首先介绍第4.1节中的实验设置,然后介绍第4.2节中的主要实验结果。第4.3节进行消融研究。在第4.4节中,我们比较了PromDA和未标记的数据,给出了多样性分析和案例研究。
4.1实验设置
我们对句子分类任务SST2(Socher等人,2013年)和RT(Pang和Lee,2005年)以及序列标记任务CoNLL03(Tjong Kim Sang和De Meulder,2003年)和Wikiann(Pan等人,2017年)进行了实验。对于每个基准,我们进行了shot-10、20、50、100实验。在Shot-K中,我们从完整的训练数据中为每个输出标记采样K个标记实例。我们重复实验5次,并报告了平均的micro-F1。基线模型是仅使用few-shot训练数据训练的基于BERT的模型。给定新生成的合成数据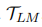 ,我们使用相同的超参数集训练相同的BERT-BASE模型。在序列标记任务中,我们使用基于规则的数据增强方法SDANER(Dai和Adel,2020)和MetaST(Wang等人,2021a),这是一种最先进的自我训练方法,需要额外的未标记领域内数据。对于句子分类任务,基于规则的EDA(Wei和Zou,2019),反向翻译(BackT.)采用了基于bert的CBERT方法。我们采用LAMBADA(Anaby Tavor等人,2020年)作为所有任务的基于PLM的方法。
,我们使用相同的超参数集训练相同的BERT-BASE模型。在序列标记任务中,我们使用基于规则的数据增强方法SDANER(Dai和Adel,2020)和MetaST(Wang等人,2021a),这是一种最先进的自我训练方法,需要额外的未标记领域内数据。对于句子分类任务,基于规则的EDA(Wei和Zou,2019),反向翻译(BackT.)采用了基于bert的CBERT方法。我们采用LAMBADA(Anaby Tavor等人,2020年)作为所有任务的基于PLM的方法。
①实施细节
PromDA建立在T5大型模型的基础上(Raffel等人,2020年)。PromDA需要对下游任务进行及时的预训练和微调。在这两个阶段中,我们使用Adafactor优化器(Shazeer和Stern,2018),学习率为1e-3,权重衰减为1e-5,以训练软提示参数。对于预训练,我们使用T5预训练语料库C4中的realnewslike分割作为输入。预训练批量为72,我们对PromDA进行了10万步的预训练。我们将realnewslike数据集拆分为训练和开发拆分(即10000页)。我们将每5000步检查一次dev的PPL。我们以最低的PPL保存模型。在对few-shot数据T进行微调时,我们将批量大小设置为32,并对PromDA进行1000步的训练。我们只将Wikiann和CoNLL03的shot50和shot-100的微调步骤升级到5000。更多实验设置见附录A部分。
4.2实验结果
①Sequence Labeling Tasks序列标记任务
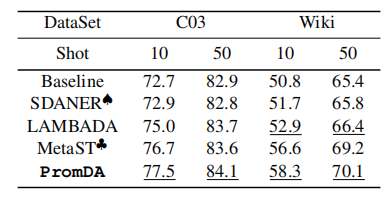
表2总结了shot-10和shot-50中的实验结果。在这两种情况下,使用PromDA的合成数据训练的NLU模型的性能都大幅提高(即CoNLL03和Wikiann分别为4.8%和7.5%)。PromDA也优于基于规则的SDANER和完全微调的PLM-LAMBADA方法。总的来说,基于PLM的方法比SDANER产生更好的合成数据。令人惊讶的是,PromDA支持的NLU模型比使用未标记域内数据的MetaST实现的性能稍好。这表明PromDA可能会减少为低资源NLU任务收集未标记域内数据的额外人力。图2显示了shot-10、20、50、100设置中的性能。PromDA支持的NLU型号在所有设置中都始终优于其他系统。与Wikiann相比,CoNLL03的改进幅度更小。这可能是因为CoNLL03基线的性能相对较高。
表2:序列标记任务的实验结果。结果取自(Wang等人,2021a)。我们运行Dai和Adel(2020)的源代码。C03指的是CoNLL03,Wiki指的是Wikiann。下划线是与基线模型相比的显著结果(配对student's t-test,p<0.05)。
②Sentence Classification Tasks句子分类任务
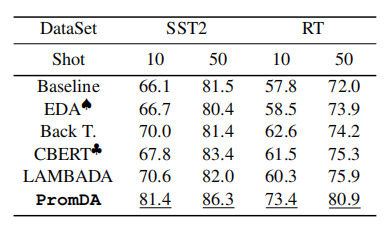
表3显示了shot-10和shot-50的实验结果。与序列标记任务中的结果类似,添加来自PromDA的合成数据显著提高了NLU模型的性能(在shot10的两个基准测试中都超过10%)。PromDA也优于各种竞争方法,包括BackT, CBERT和LAMBADA。尽管LAMBADA具有更高级别的灵活性,并从输出标签生成合成数据,但它的性能与CBERT类似。这可能是因为在使用较小的训练数据进行微调时存在过度拟合问题。Promp-Empowered PromDA成功地避免了这个问题,并生成高质量的合成数据来支持NLU模型训练。图2显示了shot-10、20、50、100设置中的性能。PromDA支持的NLU型号在所有设置中都始终优于所有其他系统。
表3:句子分类任务的实验结果。我们运行Wei和Zou(2019)的源代码。我们运行Wu等人(2019)的源代码。下划线是与基线模型相比的显著结果(配对student's t-test,p<0.05)。
③讨论
LAMBADA的表现一直比PromDA差(例如,在SST2和RT实验中F1成绩差距超过10%)。这是因为完全微调的PLM可以轻松记住有限的标记训练数据,并生成类似的合成数据。相比之下,基于提示的学习允许PromDA保持较高的泛化能力,并为NLU模型提供新的训练信号。与基线模型相比,PromDA的结果均具有统计学意义(配对student's t-test,p<0.05)。
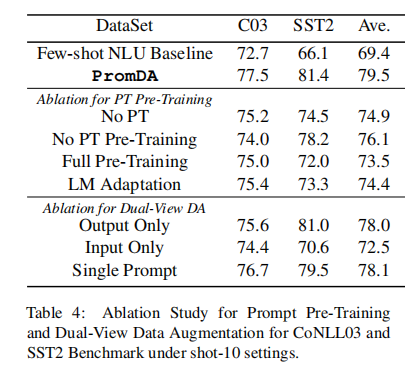
4.3消融实验
我们在SOOT-10环境下对CoNLL03和SST2基准上的组件进行了消融研究,包括Prompt Pre-Training、双视图数据增强和一致性过滤。
①Prompt Pre-Training
在无PT的提示预训练中,我们直接微调两个独立的PLM,以学习输入视图和输出视图。在无PT预训练中,我们删除提示预训练任务(同义词到句子)。在完全预训练中,我们应用提示预训练任务来微调整个PLMs参数。最后,在LM改编中:我们用Lester等人(2021年)的解决方案取代PromDA。如表4所示,完全微调PLMs(无PT)的性能比我们提出的PromDA方法差(F1分数低4.6%),表明软提示对低资源NLU数据增强的积极贡献。此外,取消PT预训练(无PT预训练)或应用PT预训练微调所有PLMs参数(完全预训练)也会将PT预训练成绩分别委派3.1%和6.0%的F1分数,表明使用PT预训练学习合理的提示初始化的重要性。同样,LM Adaption也会对整个PLM进行微调,并实现与完全预训练类似的性能。建议直接训练提示参数。
②Dual-View Data Augmentation
接下来,我们将展示PromDA中双视图数据扩充的效果。仅输入和仅输出分别通过输入视图和输出视图生成合成数据。这两个单视图模型生成的合成数据数量与PromDA相同。如表4所示,来自这两个单视图模型的合成数据成功地提高了NLU模型的性能。然而,它们相应的NLU模型的性能比PromDA支持的模型差。这表明,来自不同视图的合成数据为NLU模型提供了有意义且不同的训练信号。有趣的是,在输出视图上训练的NLU模型比在输入视图上训练的NLU模型表现得更好,这表明输出标签是更具表现力的信号,可以引导PLM生成高质量的合成数据。最后,我们在单个提示中针对相同的提示参数训练两个视图,而不是针对独立的提示参数训练两个视图。在单一提示合成数据上训练的NLU模型的性能比PromDA支持的NLU模型差,这表明提示集成对于双视图数据增强的重要性
③Consistency Filtering
最后,我们检验了PromDA中一致性过滤的效果。在表5中,我们展示了无任何过滤(w/o过滤)和k迭代(Iter-1、Iter-2和Iter-3)的NLU模型性能。过滤对NLU性能有重要影响。如果不删除低质量的合成数据,性能差距几乎消失。迭代过滤对NLU性能也有积极影响。特别是在SST2基准测试中,NLU模型性能在三次迭代后提高了4%的F1分数。
4.4讨论
①PromDA与T5 Base
我们验证PromDA是否可以与不同的预先训练的语言模型一起工作。我们用T5基础模型替换T5大型模型。新的PromDA还可以大幅度改进few-shot的基线模型。在SST2 shot-10设置中,NLU模型的F1分数从66.1提高到76.3,这也优于表3中列出的其他模型。
②PromDA in the high-resource setting
为了展示PromDA在高资源环境下的优势,我们用完整的训练数据替换了few-shot训练数据。我们发现PromDA仍然可以提高基线模型的性能。在SST2中,添加语法数据后,NLU的F1成绩从90.8分提高92.3分。
③Improvement Margin Difference改善差额
如表2和表3所示,句子分类任务的改进幅度(即F1得分超过15%)一般大于序列标记任务的改进幅度(即F1得分低于10%)。这可能是因为i)序列标记任务比句子分类任务是一个更细粒度和知识密集型的任务;ii)序列标记任务的合成数据包括实体类型和边界,与句子分类任务相比,plm的生成更具挑战性,特别是在资源设置较低的情况下。
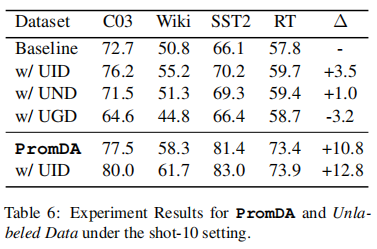
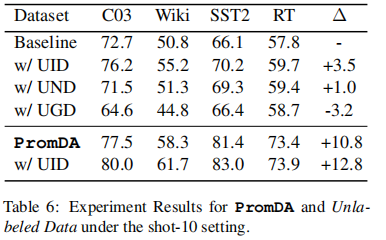
④PromDA and Unlabeled Data
上述实验基于没有未标记数据的假设。在本节中,我们将探讨PromDA与未标记数据之间的联系。为了将未标记的数据纳入我们的NLU模型,我们将经典的自我训练框架(Scudder,1965)应用于NLU模型。具体来说,对于每个未标记的实例,我们使用NLU模型对其进行标记,并记录输出标记和相应的似然分数。低可能性分数意味着预测的可信度较低。我们根据可能性得分对所有未标记的实例进行排序,并删除底部20%的实例。表6显示了四个基准在shot-10设置下的实验结果。
⑤The Effect of Unlabeled Data Domain未标记数据域的影响
未标记数据域的影响我们设计了三种设置:未标记的域内数据(UID)、未标记的近域数据(UND)和未标记的通用域数据(UGD),其中未标记的数据来自完全相同、相似和通用的域。我们在CoNLL03和Wikiann之间以及SST2和RT之间交换训练数据,以模拟类似的域。我们从PLM预训练语料库中随机抽取句子来模拟通用领域。我们注意到,未标记的数据域对自我训练性能有很大影响。即使是轻微的域转移(即UND),NLU的性能也会降低2.5%。使用来自通用语料库的未标记数据训练的NLU模型的性能甚至比仅使用fewshot标记数据训练的NLU基线模型低3.2%。序列标记任务和句子分类任务遵循这一趋势,但序列标记任务对未标记的数据域更敏感。对于半监督学习,仍然需要额外的人力来选择合适的域来收集未标记的数据。
⑥Combining Unlabeled In-domain Data with PromDA将未标记的域内数据与PromDA相结合
我们将上述自训练算法应用于PromDA支持的具有未标记的域内数据的最终NLU模型(PromDA)。由此产生的NLU模型平均进一步改进了2.0%(最后一行为w\/UID)。更复杂的半监督学习算法可能会带来更多的改进。这表明a)来自PromDA和未标记indomain数据的合成数据为NLU模型提供了不同的信息;b) PromDA成功地提取了PLMs中的嵌入知识,并将其呈现在生成的合成数据中。
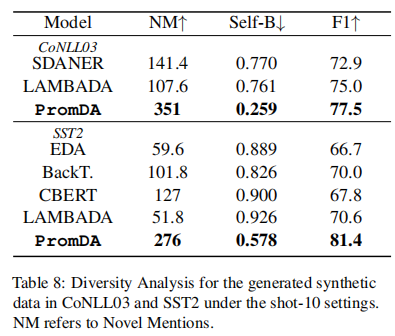
⑦多样性分析
在表8中,我们展示了PromDA和其他基线模型生成的合成数据的多样性。我们从每个训练实例中抽取10个新的合成数据。我们使用新颖提及(实体提及次数或未出现在培训数据中的关键词)和自我BLEU评分(Zhu等人,2018)来衡量多样性。一般来说,简单的生成性数据扩充方法(即BackT.和CBERT)很容易产生新的提及,但它们生成的合成数据缺乏多样性(相对较低的自我BLEU分数)。基于即时的学习有助于PromDA生成最多样化的合成数据,并在两个基准中都有最新颖的提及。由于过度拟合问题,LAMBADA生成的合成数据与其他基线方法相比差异较小或相等。有趣的是,根据这些合成数据训练的NLU模型取得了第二好的性能。这可能是因为LAMBADA连贯地生成整个合成句子,而其他人则根据随机和\/或启发式规则进行回复。
⑧合成数据案例研究
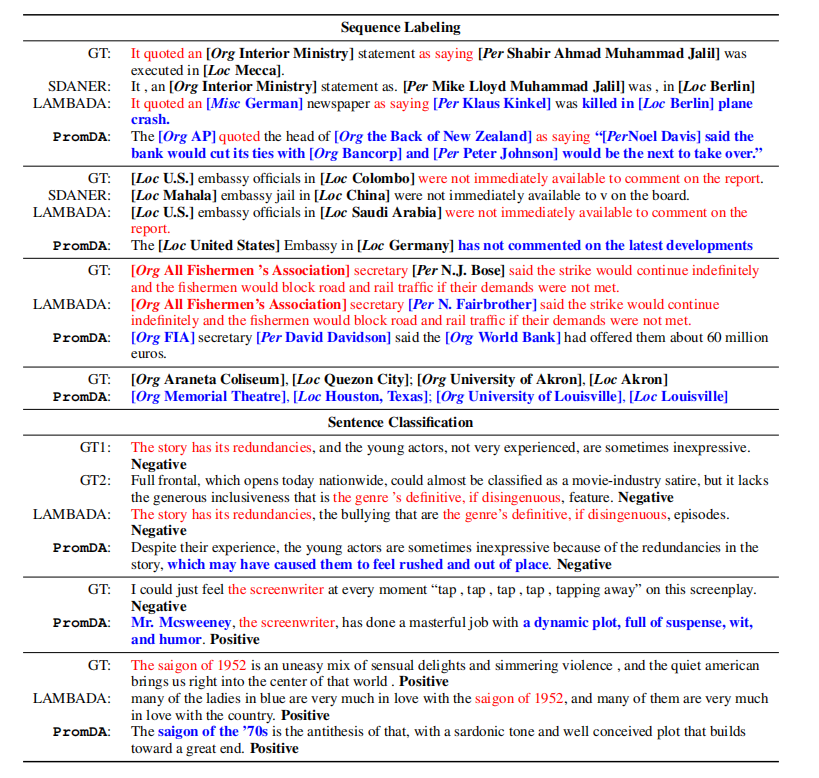
表7显示了由我们提出的PromDA和方法生成的代表性示例。在序列标签示例中,基于规则的SDANER会解析原始词序并创建低质量的文本。LAMBADA模型通过修改原始训练实例中的三个文本跨度(例如,将语句更改为报纸),生成一个新的合成实例。相比之下,我们的PromDA方法在银行中生成一个全新且合理的事件,并在生成的合成数据中生成正确且新颖的地理位置。类似地,在句子分类任务中,LAMBADA天真地结合了第二个例子中两个训练实例的文本块。PromDA在训练数据中提到了一些关键字,但在输出中添加了更多信息。在另一个例子中,PromDA用一系列连贯的单词对编剧(没有出现在培训数据中)进行评论。最后,PromDA成功地将主题从1952年的电影《西贡》转移到了70年代的西贡。总之,PromDA可以从PLM中提取嵌入的真实世界知识,并以有效的方式将这些知识引入相对较长的句子中。
表7:根据我们提出的PromDA和其他基线方法生成的合成数据。红色文本块与few-shot训练数据重复。蓝色的文本块是新颖的单词\/短语。
5.结论和未来的工作
在本文中,我们提出了第一个用于低资源NLU数据扩充的基于提示的预训练语言模型PromDA。在四个基准上的实验表明了我们提出的PromDA方法的有效性。未来,我们计划将PromDA扩展到其他NLP任务,包括问答、机器阅读理解和文本生成任务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号