多校B层冲刺NOIP20211110 字符配对游戏
原题
问题描述
操场边,运动会没有项目的同学也没闲着,经过几天的研究,他们发明了一个很有意思的字符串配对游戏,两位同学准备两张白纸,第一个同学在纸上写一个整数N和一个由小写字母组成的字符串S,将S重复N次后产生一个更长的字符串A;相应的,第二个同学也在纸上写一个整数M,一个由小写字母组成的字符串T,接着他把T重复M次产生字符串B.并且保证字符串A和B的长度相等;这时候,如果A中的第i个字符与B中的第i个字符相同,则称为字符配对成功。给定N、M、S、T,请编写一个程序求A和B的成功配对的字符数。
输入
第一行两个用空格整数N和M。
第二行和第三行分别为S和T。
数据保证A和B的长度相等。
输出
输出为一个整数,表示A和B匹配成功的字符数。
样例
| 3 5 ababa aba | 8 |
数据范围
40%的数据满足 A<=105;
另有30%的数据满足N,M<=109 ;|S|,|T|<=10(|S|表示S的长度);
100%的数据满足 N,M<=109 ;|S|,|T|<=106。
思路
算法一 - 对于40%的数据
按题意直接生成A和B,再一个个比较Ai和Bi是否匹配,时间复杂度O(n),n表示A和B的长度;
算法二 - 对于另30%的数据
S,T的长度不大于10,我们先求出它们的循环节,循环节为 它们的最少公倍数,在循环节里比较每一对字符是否匹配,再 把匹配次数乘以循环次数即可,时间复杂度O(lcm(|S|,|T|));
算法三 - 对于100%的数
在循环节里比较每一对字符会超时,我们计算出两个字串 长度的最大公约数gcd(|S|,|T|),把S和T中的字符按所在的位 置除以gcd(|S|,|T|)的余数进行分类,同类的字符会一一比较, 不同类的字符不会进行比较,在同类字符中统计每个字母出现 的次数,再根据乘法原理计算匹配次数。时间复杂度 O(|S|+|T|));
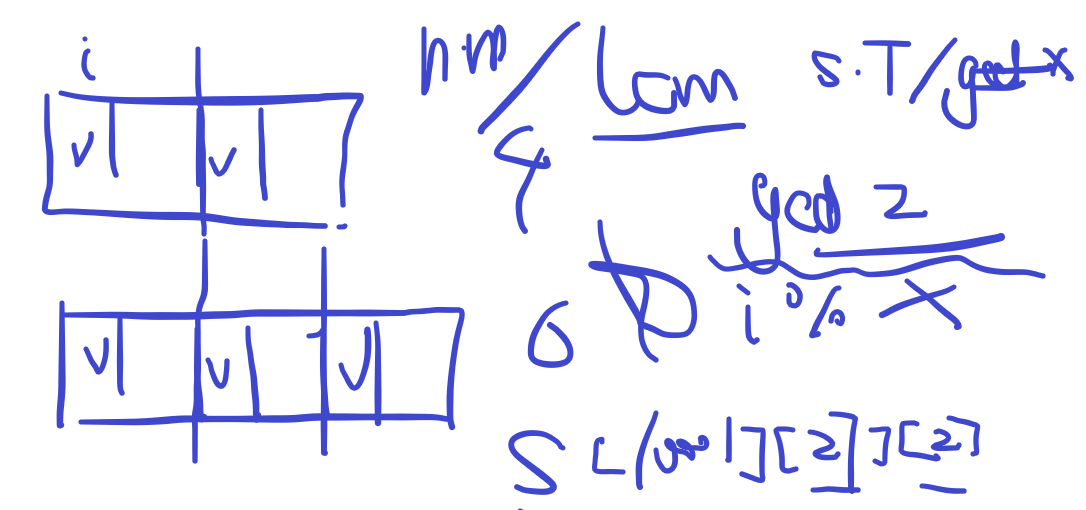
代码实现
#include <bits/stdc++.h>
using namespace std;
int sum[10001][27][2];
inline int gcd(int a, int b)
{
while (b ^= a ^= b ^= a %= b);
return a;
}
int main()
{
//freopen("string.in", "r", stdin);
//freopen("string.out", "w", stdout);
int n, m;
string s, t;
cin >> n >> m >> s >> t;
int lens = s.length();
int lent = t.length();
int x = gcd(lens, lent), y = n * x / lent;
long long tot1 = 0, tot2 = 0, ans = 0;
for (int i = 0; i < lens; ++i)
{
sum[i % x][s[i] - 'a' + 1][0]++;
}
for (int i = 0; i < lent; ++i)
{
sum[i % x][t[i] - 'a' + 1][1]++;
}
for (int i = 1; i <= 26; ++i)
{
for (int j = 0; j < x; ++j)
{
ans += (sum[j][i][0] * sum[j][i][1] );
}
}
cout << ans *y << endl;
}记得点赞加关注哦
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/hello_wangping/article/details/121249005


 浙公网安备 33010602011771号
浙公网安备 33010602011771号