Linux Hadoop2.7.3 安装(单机模式) 二
Linux Hadoop2.7.3 安装(单机模式) 一
Linux Hadoop2.7.3 安装(单机模式) 二
YARN是Hadoop 2.0中的资源管理系统,它的基本设计思想是将MRv1中的JobTracker拆分成了两个独立的服务:一个全局的资源管理器ResourceManager和每个应用程序特有的ApplicationMaster。
其中ResourceManager负责整个系统的资源管理和分配,而ApplicationMaster负责单个应用程序的管理。
创建一个words.txt 文件并上传
vi words.txt
Hello World
Hello Tom
Hello Jack
Hello Hadoop
Bye hadoop
将words.txt上传到hdfs的根目录
/home/xupanpan/hadoop/hadoop/bin/hadoop fs -put /home/xupanpan/hadoop/word.txt /

1、配置etc/hadoop/mapred-site.xml:
mv /home/xupanpan/hadoop/hadoop/etc/hadoop/mapred-site.xml.template /home/xupanpan/hadoop/hadoop/etc/hadoop/mapred-site.xml
vim /home/xupanpan/hadoop/hadoop/etc/hadoop/mapred-site.xml
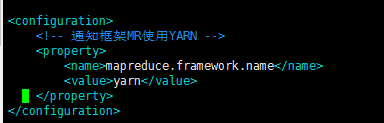
<configuration>
<!-- 通知框架MR使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2、配置etc/hadoop/yarn-site.xml:
vim /home/xupanpan/hadoop/hadoop/etc/hadoop/yarn-site.xml

3、YARN的启动
/home/xupanpan/hadoop/hadoop/sbin/start-yarn.sh

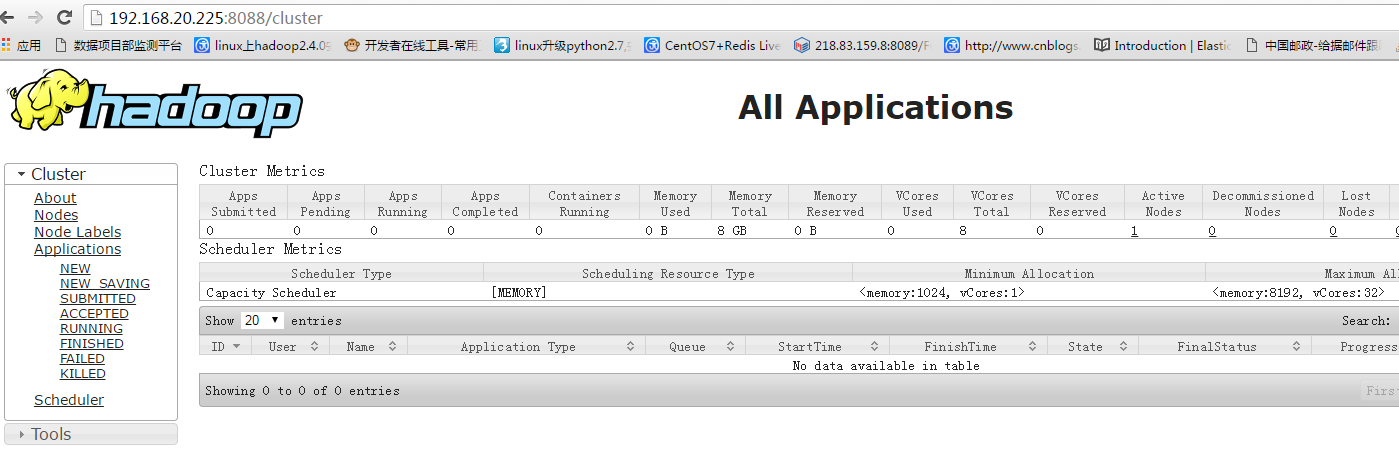
http://192.168.20.225:8088/cluster
3、YARN的停止
sbin/stop-yarn.sh
现在我们的hdfs和yarn都运行成功了,我们开始运行一个WordCount的MP程序来测试我们的单机模式集群是否可以正常工作。
运行一个简单的MP程序
我们的MapperReduce将会跑在YARN上,结果将存在HDFS上:
用hadoop执行一个叫 hadoop-mapreduce-examples.jar 的 wordcount 方法,其中输入参数为 hdfs上根目录的words.txt 文件,而输出路径为 hdfs跟目录下的out目录,运行过程如下:
/home/xupanpan/hadoop/hadoop/bin/hadoop jar /home/xupanpan/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar wordcount hdfs://127.0.0.1:9000/word.txt hdfs://127.0.0.1:9000/out
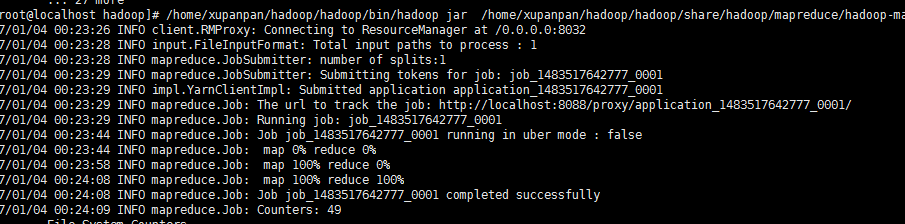


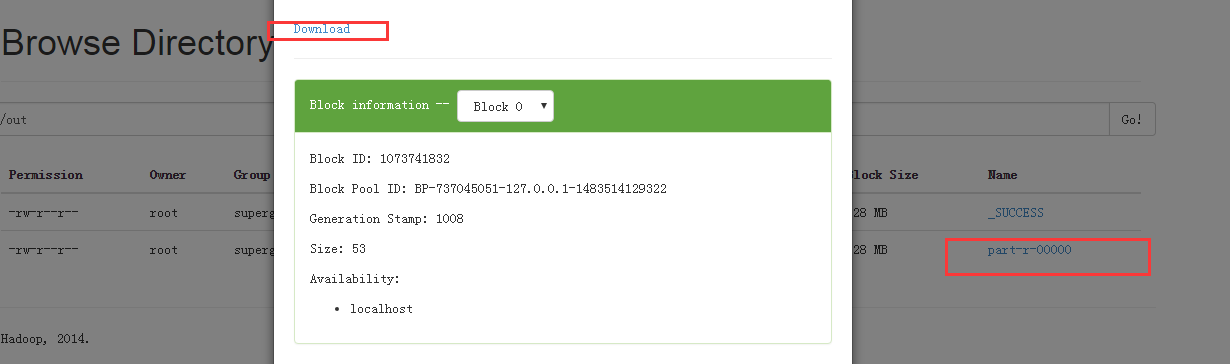

说明我们已经计算出了,单词出现的次数。
至此,我们Hadoop的单机模式搭建成功。
参考 http://blog.csdn.net/uq_jin/article/details/51451995
生活不易,五行缺金,求打点


 浙公网安备 33010602011771号
浙公网安备 33010602011771号