20200917-2 词频统计
作业要求 https://edu.cnblogs.com/campus/nenu/2020Fall/homework/11206
老五在寝室吹牛他熟读过《鲁滨逊漂流记》,在女生面前吹牛热爱《呼啸山庄》《简爱》和《飘》,在你面前说通读了《战争与和平》。但是,他的四级至今没过。你们几个私下商量,这几本大作的单词量怎么可能低于四级,大家听说你学习《构建之法》,一致推举你写个程序名字叫wf,统计英文作品的单词量并给出每个单词出现的次数,准备用于打脸老五。
希望实现以下效果。以下效果中数字纯属编造。
功能1 小文件输入。 为表明程序能跑,结果真实而不是迫害老五,请他亲自键
盘在控制台下输入命令。
分享几个我遇到的问题以及解决方法
1 .py转 .exe 教程 https://www.cnblogs.com/hanhao970620/p/11537088.html
2. git上传到coding 教程 https://blog.csdn.net/weixin_43184774/article/details/100539466
3. git配置 教程 https://blog.csdn.net/huangqqdy/article/details/83032408 官网下载很慢,可以使用淘宝镜像下载:http://npm.taobao.org/mirrors/git-for-windows/
功能一 代码:
def count(w):
total = 0
c=collections.Counter(w)#利用计数器去重
for i in c:
total+= 1
print('total {} words\n'.format(total))#单词总数
top=c.most_common(10)#控制前十个
for i in top:
print('%-8s%5d' % (i[0], i[1]))#控制宽度显示单词数
#通过命令行输入到txt文件
def inputText(Text):
w = re.findall(r'[a-z0-9^-]+', Text.lower())
count(w)
这个最重要的是通过命令行从txt中读出来,我用了正则表达式。collection.Counter()可以单词去重,还是很方便的。
截图:
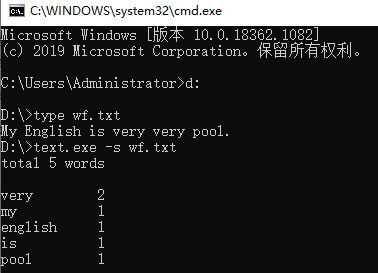
功能2 支持命令行输入英文作品的文件名,请老五亲自录入。
代码
def opentxt(filename):
s = '.txt'
if s in filename:#判断命令控制行.txt文件
path = filename
else:
path = filename + '.txt'
f=open(path, encoding='utf-8')
w= re.findall(r'[a-z0-9^-]+', f.read().lower())#通过正则读进去
count(w)
总结:功能二最重要的部分是有一个输入的时候是否有后缀,若有则直接打开,若没有我就手动帮他添加上后缀
截图

功能三支持命令行输入存储有英文作品文件的目录名,批量统计
代码
def FCount(path):
print(path)
f = open(path, encoding='utf-8')#打开
w = re.findall(r'[a-z0-9^-]+', f.read().lower())
count(w)
print('----')
def path(path1):
files = os.listdir(path1)
for file in files: #循环打开每个文件
if os.path.isfile(file):
FCount(file)
总结:功能三难点在打开文件夹后循环读取txt中的字符串,我用了os.listdir()方法,能够返回这个文件夹下的文件名字列表,我再通过循环将每个文件读取打开。
截图

功能4 从控制台读入英文单篇作品,这不是为了打脸老五,而是为了向你女朋
友炫酷,表明你能提供更适合嵌入脚本中的作品(或者如她所说,不过是更灵活
的接口)。如果读不懂需求,请教师兄师姐,或者 bing: linux 重定向,尽管
这个功能在windows下也有,搜索关键词中加入linux有利于迅速找到。
这个功能暂时没实现,我请教了上届的学长,但是我还是没实现,也是由于这周任务有很多,没有充足时间学习,下周我会借鉴其他同学的功能四,将这个功能补上。
psp
 代码链接 https://e.coding.net/wowcy/cptj/cptj.git
代码链接 https://e.coding.net/wowcy/cptj/cptj.git

 浙公网安备 33010602011771号
浙公网安备 33010602011771号