C++进阶知识汇总
知识来源:https://www.imooc.com/learn/1305
二进制在计算机中的意义:
计算机如何存负整数:

原码:符号位变为1
反码:除符号位其余取反
补码:=反码+1 是-7的表示方法,计算机用补码来存储负数,这样可以使得负数的加减法操作和正数一样
计算机中存储浮点数:
首先是10进制在现实生活中表现小数

可以见得当使用:± 尾数 基数 指数 时就可以表示一个浮点数了,在计算机中也是如此,不过基数从10变为了2,我们会根据IEEE 754标准来表示浮点数(在32位系统中1位表示符号位8位表示指数位剩下23位表示尾数)

不过在计算机中,因为小数的特殊性,因此存储时会和整数不一样,且精度(误差现象)比整数要严重,因此在现实中涉及对精度要求很高的项目中就不应该使用浮点数,因此浮点数结构复杂,导致运算速度也很慢,一般计算机中有专门的浮点数计算电路。因此我们在编程中为追求效率性能应尽可能地追求整数,少用浮点数。
大端字节序(big endian)与小端字节序(little endian)
字节序就是大于一个字节在内存中存放的顺序
例:十进制256,十六进制为0x0102,拆成两部分则是0x01和0x02,分别存放在两个字节中。将其换成二进制则是0000 0001与0000 0010。其分别在计算机内存中存储的样子为:
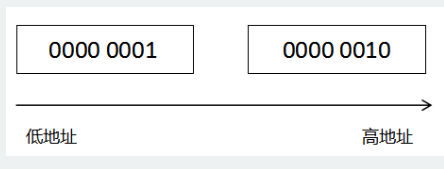 小端字节序
小端字节序
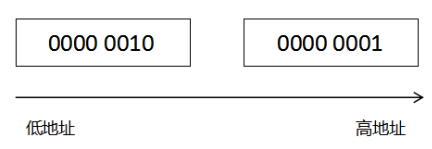 大端字节序
大端字节序
现在大部分机器采用的是小端字节序,但是IO方面则大部分采用大端字节序(例如网络通信),因此大端字节序又被称为网络字节序。
例2:验证自己电脑上采用的是大端字节序还是小端字节序
#include <stdio.h>
int main()
{
int i = 0x1122;
char* p = (char*)&i;
if (p[0] == 0x22 && p[1] == 0x11) {
printf("Little Endian\n");
}
else if (p[0] == 0x11 && p[1] == 0x22) {
printf("Big Endian\n");
}
}
#include <stdio.h>
int main()
{
int i = 0x1122;
char* p = (char*)&i; //将i的地址(整数)转化为char类型指针再传给*p
if (p[0] == 0x22 && p[1] == 0x11) {
printf("Little Endian\n");
}
else if (p[0] == 0x11 && p[1] == 0x22) {
printf("Big Endian\n");
}
指针:
*:解引用运算符,可以将指针进行翻译成指向数据(即通过地址找到具体内存中的内容)
&:取地址运算符,可以根据变量获取地址(解引用运算符的逆操作)
加法:p+1(地址+类型大小*1),例int*指针,则p+1意味着原地址+4
指针与结构体

函数指针:方便在任意地方(如函数中)插入代码块(即函数)
声明规则:类型 (*指针名)(参数列表) = 函数名;
例:int (*funcP)(int a) = func1;
使用(调用)方法:(*指针名)(参数)
例:(*funcP)(5); , 也可取其值,例如 int ret = (*funcP)(5);
回调函数/钩子函数使用(函数中插入函数)方法: //多用于函数中插入代码or多线程
#include <stdio.h>
int dowork(int a,int (*callback)()) //函数指针调用主要体现在这里
{
int ret = (*callback)();
int c = ret + a;
printf("This is %d\n",c);
return 0;
}
int funcA(){
return 1;
}
int funcB(){
return 2;
}
int main()
{
dowork(1, funcA); //在使用的时候看着与普通函数无异,只需要传入适当的参数
dowork(2, funcB);
return 0;
}
当使用mallo()来进行堆式声明存放指针时,如普通的free只会free掉数据,并不会抹除指针内指向的内容,因此会带来后患。故我们在使用动态分配的指针时应该先赋值为nullptr再进行释放操作。
int * p = (int *)malloc(2 * sizeof(int));
if(p != nullptr){
free(p); //首先释放p指针指向的内存而非指针本身
p = nullptr;
}
free(p); //此时再free掉p指针本身,若无前面赋值p为nullpttr操作则会因为先释放掉指针指向内存中数据后,让指针化身为野指针,再free也是p指向的内存数据。因此会发生没有权限操作的访问异常报错,赋值为空指针后再释放则是释放空指针,是合法的。
C++函数返回指针示例:
- #include <stdio.h>
- #include <iostream>
- #include <assert.h>
- int* func() {
- int* p = (int*)malloc(20 * sizeof(int));
- assert(p); //通过assert函数判断p是否为空指针,为空则报错
- for (int i = 0; i < 20; i++) {
- *p = 60 + i;
- // printf("%d\n",*p);
- p++;
- }
- return p-20;
- }
- int main(int argc, char** argv)
- {
- int* p = func();
- for (int i = 0; i < 20; i++) {
- int grade = *p;
- printf("%d\n", *p);
- p++;
- }
- }
C++面向对象编程
1.类的定义
class Staff
{
};
int main(int argc,char **argv)
{
Staff st;
return 0;
}
2.实例化:根据类产生对象的过程叫做实例化。
#include "Staff.h"
int main(int argc,char **argv)
{
// 我们就这样实例化了三个员工
Staff st1;
Staff st2;
Staff st3;
return 0;
}
3.类中的权限修饰符
Private(私有类,只允许在类中自己使用
Public(共有类,允许在任何地方访问
- class A
- {
- private:
- int a;
- public:
- int b;
- }
Protected(保护类,一般允许在子类中访问
4.分文件编程:
我们在此之前都是把代码放到一个文件里,但是这样在实际工程中肯定是不行的,我们不可能把所有的代码都写到一个文件夹里面。而在 C++ 中我们就常常把类定义到不同的文件里面,把每个类都独立起来,这样代码的耦合性就会降低,方便维护。
在 C++ 中,我们可以把一个类写到两个文件里面,一个是后缀为 .h 或者 .hpp 的头文件,一个是后缀为 .cpp 的实现文件。我们先在开发环境里新建一个类。输入类名是 Staff。
可以看到 VS 为我们创建类两个文件,Staff.h 和 Staff.cpp。Staff.h 文件为定义,Staff.cpp 为实现(例如6成员函数则是在.h中定义在.cpp中实现)。
在分了文件之后,我们想要在 main 函数中引用这个类,就需要使用 #include “Staff.h” 将头文件引入进来。
5.将对象分配到堆内存上:
同于malloc和free的方式,将对象分配到堆内存上时使用new(返回指针)和delete
#include "Staff.h"
int main(int argc,char **argv)
{
// 我们就这样实例化了三个员工
Staff * st1 = new Staff();
Staff * st2 = new Staff();
Staff * st3 = new Staff();
// 记得释放
delete st1;
delete st2;
delete st3;
return 0;
}
6.成员函数(同样收到约束字符限制,私有的成员函数只能被该对象的其他成员函数调用)
定义在类头文件中的函数,为整个类的专属函数。
以下是在头文件中的,先定义了一个头文件
- #include <string>
- class Staff
- {
- public:
- std::string name;
- int age;
- int PrintStaff();
- };
然后再.cpp文件中做具体实现
- #include "Staff.hpp"
- int Staff::PrintStaff()
- {
- printf("Name: %s\n", name.c_str());
- printf("Age: %d\n", age);
- return 0;
- }
最后即可在main函数中直接使用了
- #include <stdio.h>
- #include "Staff.hpp"
- int main(int argc,char **argv)
- {
- Staff staff1;
- staff1.PrintStaff();
- Staff staff2;
- staff2.PrintStaff();
- return 0;
- }
7.成员函数重载
在同一个类中如果出现名字完全相同的两个函数,但他们所拥有的参数不相同,则这两个函数称为重载的函数,C++会根据传入的参数自行匹配相应的实现。
- #include <string>
- class Staff
- {
- public:
- void FuncA();
- void FuncA(int a);
- };
8.构造函数和析构函数
通俗地讲构造函数就是在对象实例化时自动调用的函数,一般用来对对象进行初始化,而析构函数则是在调用结束栈内存对对象进行销毁时自动使用的函数。
例:Staff.hpp 定义了一个构造函数Staff()和一个析构函数~Staff()
- #include <string>
- class Staff
- {
- public:
- Staff(std::string _name, int _age);
- ~Staff();
- public:
- std::string name;
- int age;
- };
Staff.cpp 在cpp中分别构造函数和析构函数做出了实现
- #include "Staff.hpp"
- #include <stdio.h>
- Staff::Staff(std::string _name, int _age)
- {
- name = _name;
- age = _age;
- printf("构造函数被调用\n");
- }
- Staff::~Staff()
- {
- printf("析构函数被调用\n");
- }
9.赋值构造函数(另类的构造函数——进行拷贝专用函数——深拷贝)
浅拷贝:直接讲一个对象拷贝给另一个对象,缺点体现在如果一个类中有指针变量,则两个对象的指针会指向同一个地方
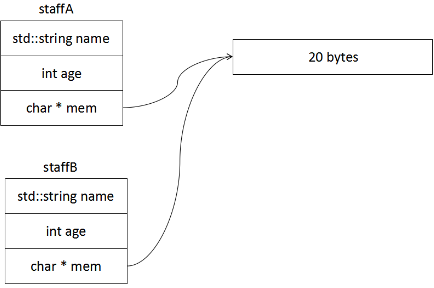
赋值拷贝函数示例:
.hpp中
- #include <string>
- class Staff
- {
- public:
- Staff(std::string _name, int _age);
- Staff& operator = (const Staff & staff);
- ~Staff();
- public:
- std::string name;
- int age;
- char * mem = nullptr;
- };
.cpp中
- #include "Staff.hpp"
- #include <stdio.h>
- Staff::Staff(std::string _name, int _age)
- {
- mem = (char *)malloc(20);
- name = _name;
- age = _age;
- printf("构造函数被调用\n");
- }
- Staff& Staff:: operator = (const Staff & staff)
- {
- name = staff.name;
- age = staff.age;
- mem = (char *)malloc(20);
- memcpy(mem, staff.mem, 20);
- }
- Staff::~Staff()
- {
- if(mem != nullptr){
- free(mem);
- mem = nullptr;
- }
- printf("析构函数被调用\n");
- }
拷贝代码:
Staff staffB = staffA;
如果Staff中没有拷贝函数则会直接浅拷贝,有拷贝函数则会
10.运算符重载
在类的运算中可以将我们根据常识定义的一些关于运算的函数重载为符号的形式,以此来简化类的使用
例:重载金钱计算的加法
.hpp文件
- class RMB {
- public:
- RMB(int _yuan, int _jiao, int _fen);
- ~RMB();
- // RMB & Add(const RMB & rmb);
- RMB operator + (const RMB & rmb);
- private:
- int yuan = 0;
- int jiao = 0;
- int fen = 0;
- };
.cpp文件
- #include "RMB.h"
- RMB::RMB(int _yuan, int _jiao, int _fen)
- {
- yuan = _yuan;
- jiao = _jiao;
- fen = _fen;
- }
- RMB::~RMB()
- {
- }
- // RMB & RMB::Add(const RMB & rmb)
- RMB RMB::operator + (const RMB & rmb)
- {
- RMB rmbRes(0, 0, 0);
- // 分
- int f = rmb.fen + fen;
- int f_ = f / 10;
- rmbRes.fen = f % 10;
- // 角
- int j = rmb.jiao + jiao + f_;
- int j_ = j / 10;
- rmbRes.jiao = j % 10;
- // 元
- int y = rmb.yuan + yuan + j_;
- int y_ = y / 10;
- rmbRes.yuan = y % 10;
- return rmbRes;
- }
main函数中使用
- int main(int argc,char **argv)
- {
- RMB rmbA(1, 9, 0);
- RMB rmbB(2, 5, 0);
- RMB rmbC = rmbA + rmbB;
- return 0;
- }
11.类的继承
在员工的类下我们可以衍生出不同的职业类,如程序员和会计等
继承方式如下所示
class Coder : public Staff
{
public:
void code()
{
printf("Coding!!!\n");
}
};
12.类的多态: 一个函数名对应多个不同的函数实现
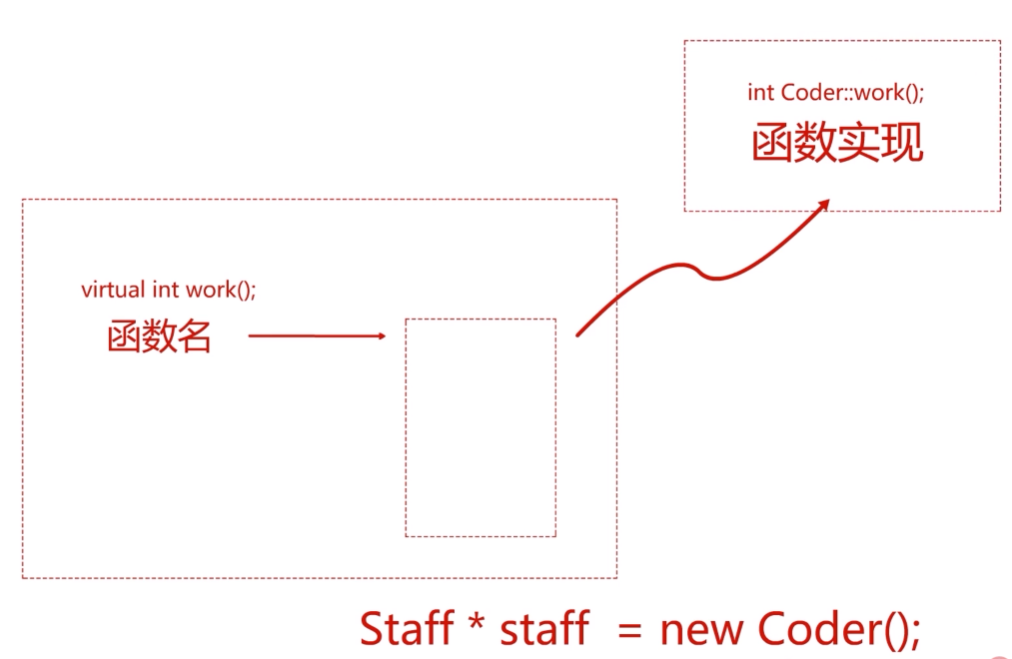
编译阶段只实现了函数名到虚函数表的部分,后面实际的函数实现指定是在运行时选定的。
子类和父类中出现的相同名称的函数:
直接实例化子类并执行函数会运行子类函数,但是当示例化一个子类再将指针强行转换为父类时,则会运行父类的函数。
这种根据类型变化,函数也会跟着变化的过程叫做编联。而编联又可以分为两种,即静态编联和动态编联。
静态编联(也叫早绑定):在编译阶段就将函数实现和函数调用联系起来,在执行时会根据早就编译好的函数实现来执行。
例:
Child * obj = new Child();
Base * baseobj = (Base *)obj;
baseobj->func(); //会根据类型执行父类的函数
delete obj;
return 0;
动态编联:在程序运行的过程中决定函数调用具体是哪个
虚函数:在父类函数名之前加上virtual关键字,则会将父类函数设置为虚函数,当我们按下述方法去调用函数的时候则会根据实际的类型去实现函数
- Staff* staff = new Coder();
- staff->work(); //会执行coder中的work()函数
纯虚函数:在父类中一些函数并不会有太大的作用,因此我们可以设置为纯虚函数,即在前面加上virtual关键字在后面赋值为0;
- class Staff
- {
- public:
- virtual int work() = 0;
- };
纯虚函数不需要在.cpp中写实现,他只会根据子类函数执行,因此纯虚函数也无法被实例化。
13.类的转换
子类转父类可以用隐式,但是父类转子类则必须使用显式转换,如同longlong转int,大转小要用隐式,小转大没问题
int main(int argc,char **argv)
{
Coder * coder = new Coder(); //coder为staff的子类
Staff * staff = coder; // 隐式转换就可以 coder转staff
Coder * coder = (Coder *)staff; // 必须显式转换 staff转coder
return 0;
}
14.C++ 内存管理
C++不同于java和C#的最大区别即它没有Garbage Collection功能,所有的内存管理工作丢给了程序员,因此也能带来更大的性能,C++的内存管理需要遵循RAII原则,即Resource Acquisition Is Initialization(资源获取就是初始化)
15.C++引用
一种特殊的变量,独立于普通变量和指针变量之外。可以理解为指针的限制版,也可以理解为对变量的别名。操作应用也会使得普通变量发生改变。在汇编代码中引用和指针没有区别。但在功能上又有所不同,首先,引用也是一个地址型变量,但使用的时候和普通变量一样,例如在操作的时候不同于指针的->操作符,引用将使用 . 操作,使得程序更加美观简洁。
A *pa = &a;
pa -> data = 20;
A &ra = a;
ra.data = 20;
16.C++之const
修饰普通变量时表示该变量为常量不可变
修饰指针时则根据所在位置定义如下几种情况:
(const) int * (const) p = &a;
前面()中的const限制变量,如果在*前面出现const则表示指针指向的数据不允许修改(即不能通过解引用操作去给变量赋值)
后面()中的const限制指针本身,如果在*后面出现const则表示指针是不可变的,即不可修改指针指向。
修饰函数内变量
使变量在函数内不可变,若传入的参数本身可变,即使在函数内用const修饰则离开函数后仍可变
修饰成员函数
使成员函数不能修改任何成员变量,也不能调用任何其他非const成员函数
- class A
- {
- public:
- int aaa;
- int funcA() const
- {
- aaa = 20; // 这行代码会报错
- funcB(); // 这行代码会报错
- return 0;
- }
- int funcB()
- {
- return 0;
- }
- }
修饰函数返回值
A aaa;
const A & getA(){ //const修饰 类型为A;返回为&引用类型;名称叫getA的函数的返回值
return aaa;
}
int main(int argc,char **argv)
{
A bbb;
getA() = bbb; // 这行代码会报错
return 0;
}
17.向函数中传入一个对象
1.普通传入,直接向函数中传入一个普通对象,则函数会先调用拷贝函数将对象拷贝下来,然后放进函数中运行,函数结束后再调用析构函数进行释放。
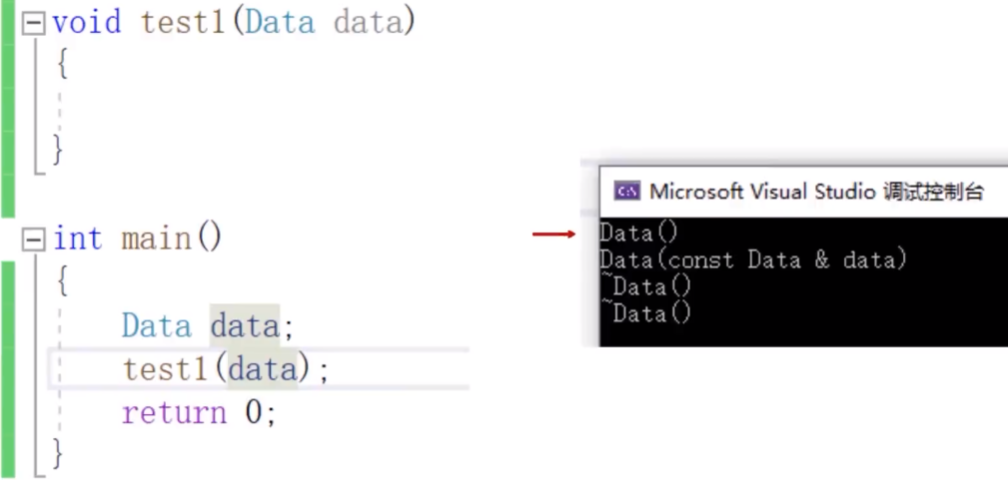
产生两个问题:1.这样调用没法直接对传入的对象进行修改;2.这样调用会进行以此额外的拷贝工作,浪费性能
2.指针传入:将对象的地址以指针的方式传入,这样就可以在函数中修改对象,并且不会通过复制再传入,二十直接传入。

产生一个问题:可能存在传入的是空指针的情况,我们需要对空指针进行处理来使程序更加健壮

3.引用传入:因为引用本身不能为空,因此不需要考虑传空的情况,效果与指针传入一样
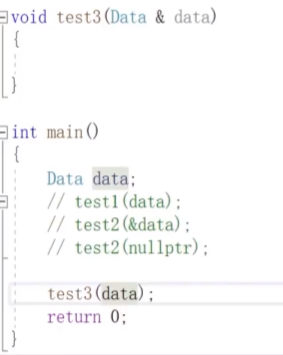
产生问题:当我们不想让函数对引用传入的对象做出修改时需要在函数调用参数中加上const修饰

4..函数返回一个对象再传入
普通返回再传入:这里调用getData()函数生成了一个data对象,该对象会在执行完
Data data =getData();后销毁,然后由main中的 Data data对象拷贝继承,再发生对象传入函数如test3(data);时,会再将main中的data拿出来拷贝之后放入函数,这里main中的data即为多余的一次拷贝操作。
- Data getData()
- {
- Data data;
- return data;
- }
- int main()
- {
- Data data = getData();
- test3(data);
- return 0;
- }
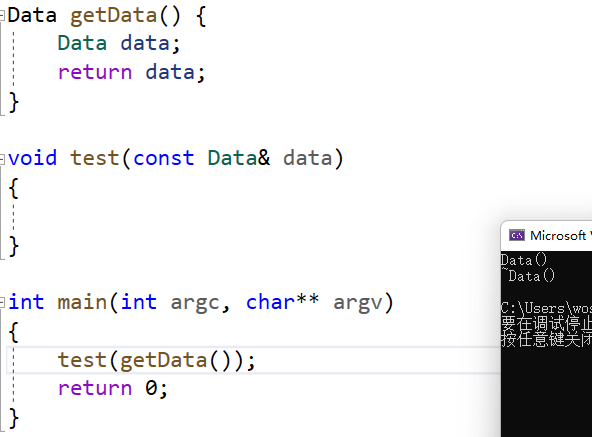
解决方法,我们可以使用引用来使Data getData()中创建返回的对象寿命更长一些。
在main中使用(C++规定这个特殊的引用必须使用const修饰)
- const Data & data = getData();
来建立这样一个引用,引用类似于指针,它不会重新拷贝函数返回对象,而是通过保留对象生存的情况下,记录它的指针来使用这个对象。
(特别注意,这里使用的是引用对象,因此test3()函数中如果要使用该对象,则参数应该传入引用类型)
- void test3(const Data& data)
- {
- }
最后调用也可以简写为
- test3(getData());
直接略过在main中创建引用,而改为在调用函数时创建该传入对象的引用
19.从函数中取出一个对象
1.古老的程序员使用参数来返回对象
- int getData(Data & data) {
- data.a = 100;
- return 0;
- }
- int main(int argc, char** argv)
- {
- Data data; //先创建一个初试对象,然后将对象传入函数中来做修改,再在函数返回时,对象已成函数返回对象
- int ret = getData(data); //使用参数来接收返回值,由此判断函数返回对象是否成功
- return 0;
- }
2.现代化的编译器会自动解决我们的冗余代码
只需要在配置管理器上选择Release
然后即可根据我们习惯的方式来使用函数返回对象,这里也不会造成性能浪费,因为编译器会很智能地将栈内存上声明的对象丢给我们的对象。
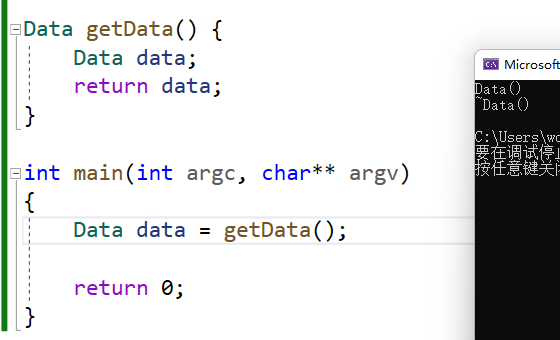
在这个例子中可以很清晰地看到,在使用release配置管理后,编译器会(编译优化)很智能化地配置我们的函数返回对象——编译器在发现我们在函数中试图返回一个对象时,会将该对象分配到调用者(main中的data变量)的栈内存中,然后函数结束后直接给调用者使用。
20.智能指针
1.unique_ptr:用于不能被多个实例共享的内存管理。它将普通的指针封装为一个栈对象(在声明时需要伴随着对象的构造函数,而随着对象的析构函数的调用该指针也会被释放掉),
- std::unique_ptr<Staff> p1(new Staff());
//p1为指针名,Staff为类,new Staff()的意思是从堆上分配一个Staff型变量,然后我们让p1指向申请的内存。<Staff>的意思是模板——限定类型为Staff类型。
2.shared_ptr:与unique_ptr的区别在于shared_ptr存在引用计数的整型变量,当该指针被赋值给其他指针时,引用计数+1,当其他智能指针被销毁时,该智能指针析构函数调用,引用则销毁一个,计数-1,当计数为0时,没有引用,就可以销毁这个对象了。
具体用法如下:
- std::shared_ptr<A> p1 = std::make_shared<A>();
- std::shared_ptr<A> p2 = p1;
但是shared_ptr会因为互相引用的现象而发生死锁。

3.weak_ptr:在相互引用的时候使用weak_ptr就可以防止死锁
- class A{
- public:
- A()
- {
- printf("A()\n");
- }
- ~A()
- {
- printf("~A()\n");
- }
- int aaa(){
- return 0;
- }
- std::weak_ptr<A> a;
- };

 浙公网安备 33010602011771号
浙公网安备 33010602011771号