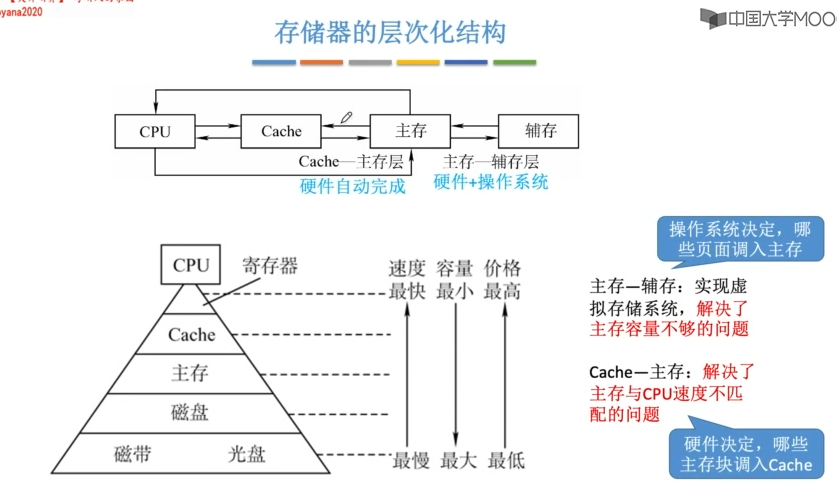
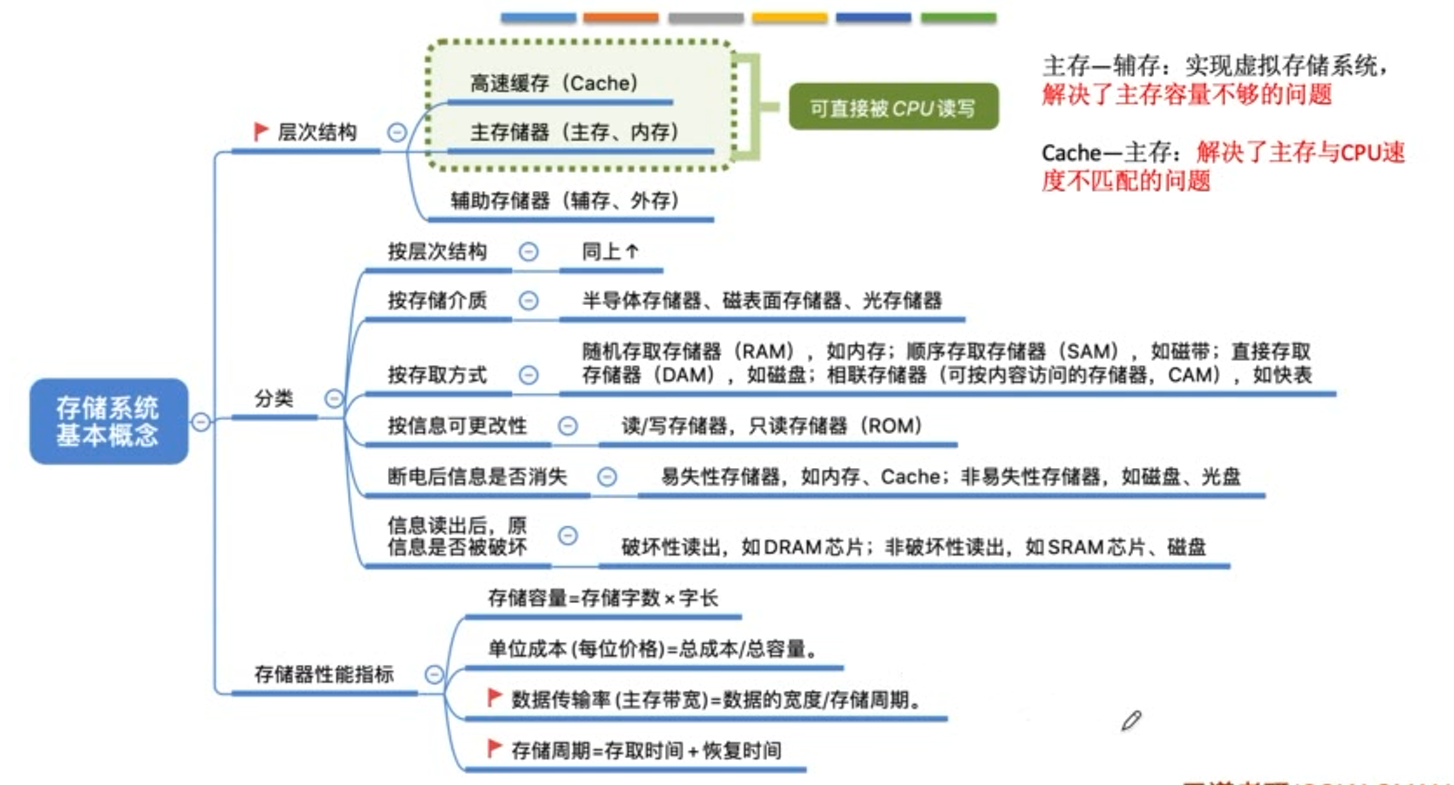
存储系统
DAM补充:光盘
顺序存取存储器SAM的内容只能按某种顺序存取,存取的时间长短与信息的物理位置有关,存取速度慢。
直接存取存储器DAM的内容既不像RAM那样可以随机存取,又不像SAM那样完全按顺序存取,而是处于两者中间,存取时先找到某个小区域,再在其中顺序存取。
带宽(数据传输率)表示每秒从主存进出的信息的最大数量。其中 数据宽度 = 存储字长。
也有通过计算一段时间内,传输了多少位数据得出的带宽,例如计组p92页例题。
半导体:主存 cache U盘 SSD
磁表面:机械硬盘
光存储器:光盘
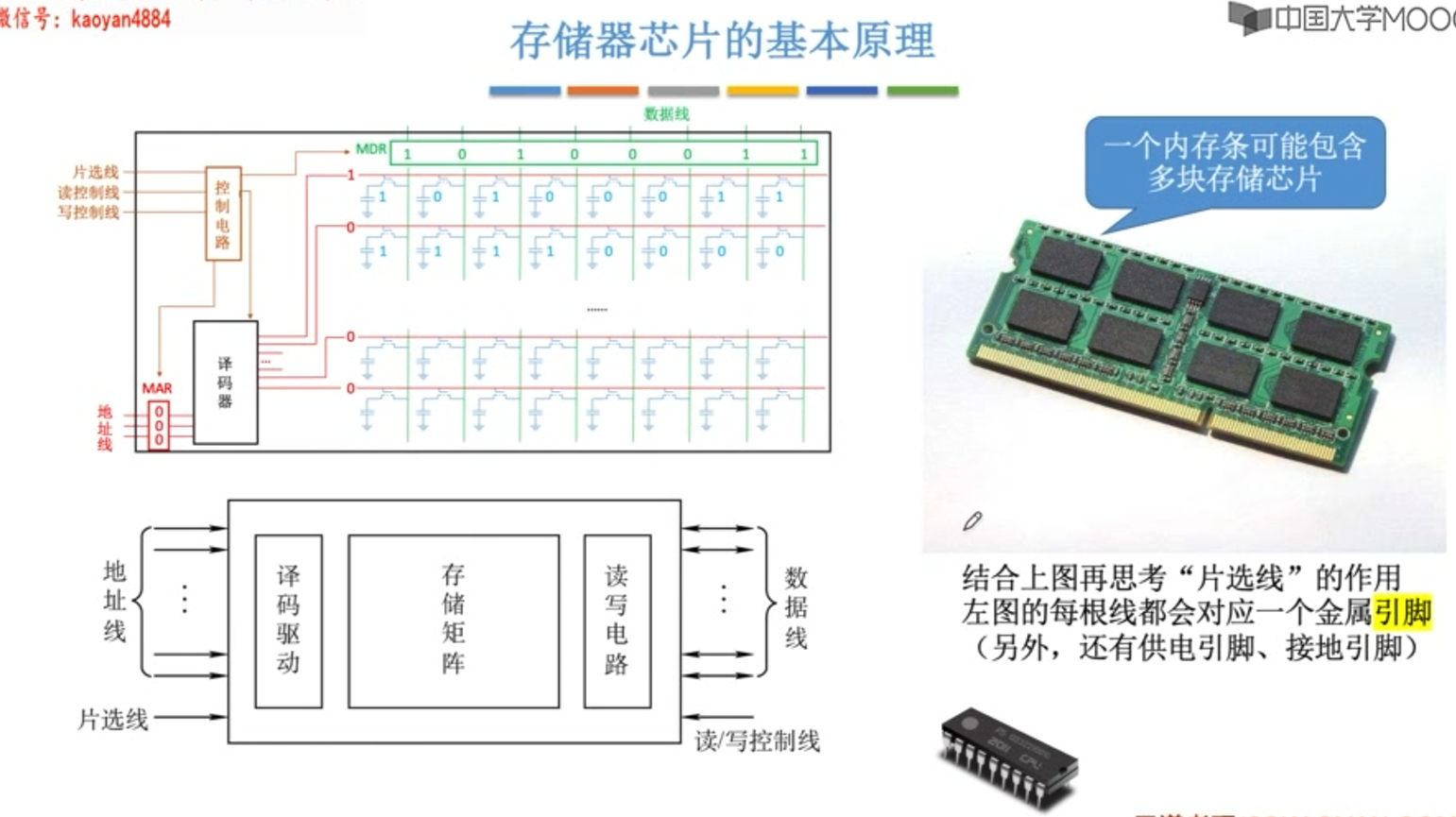
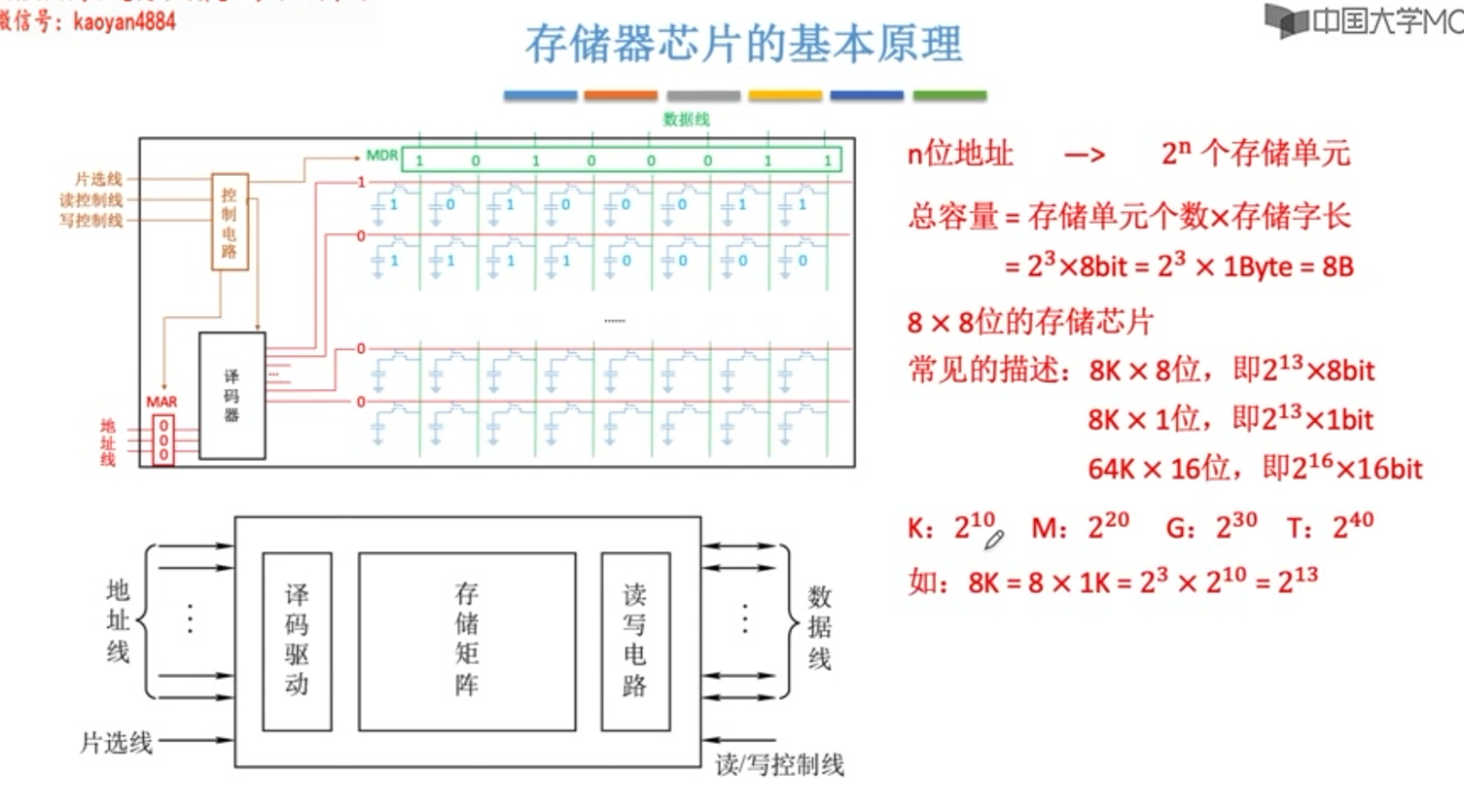
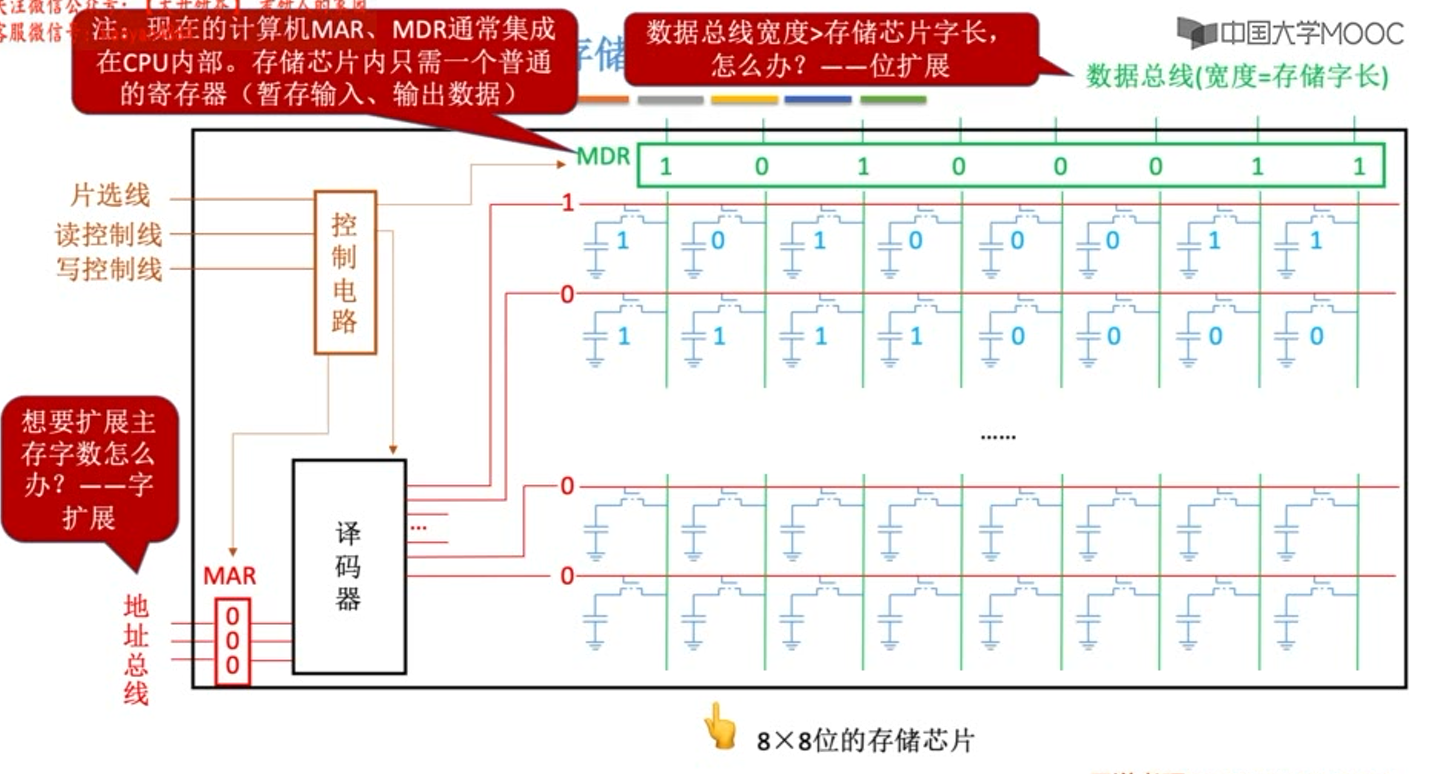
主存储体的基本构成
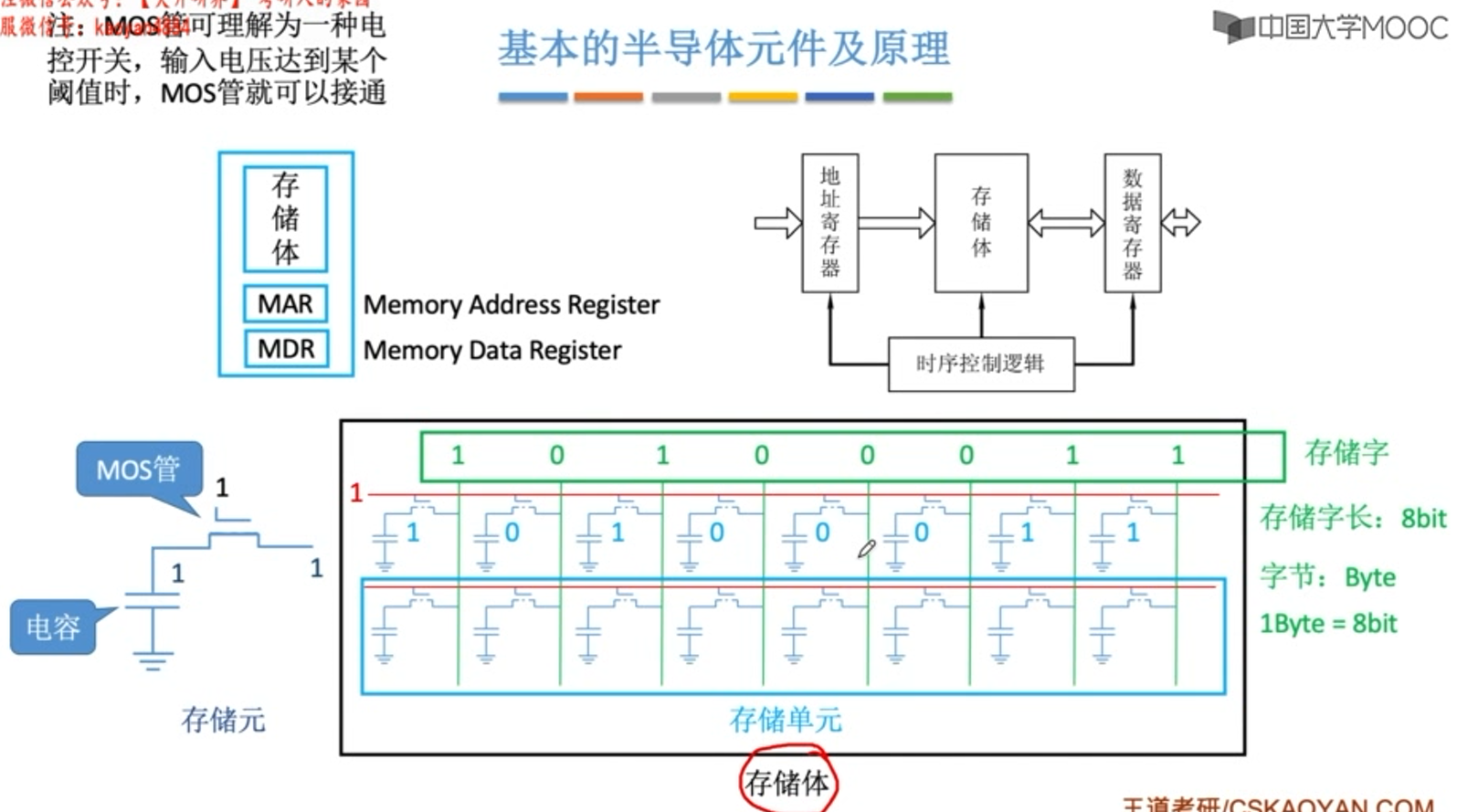
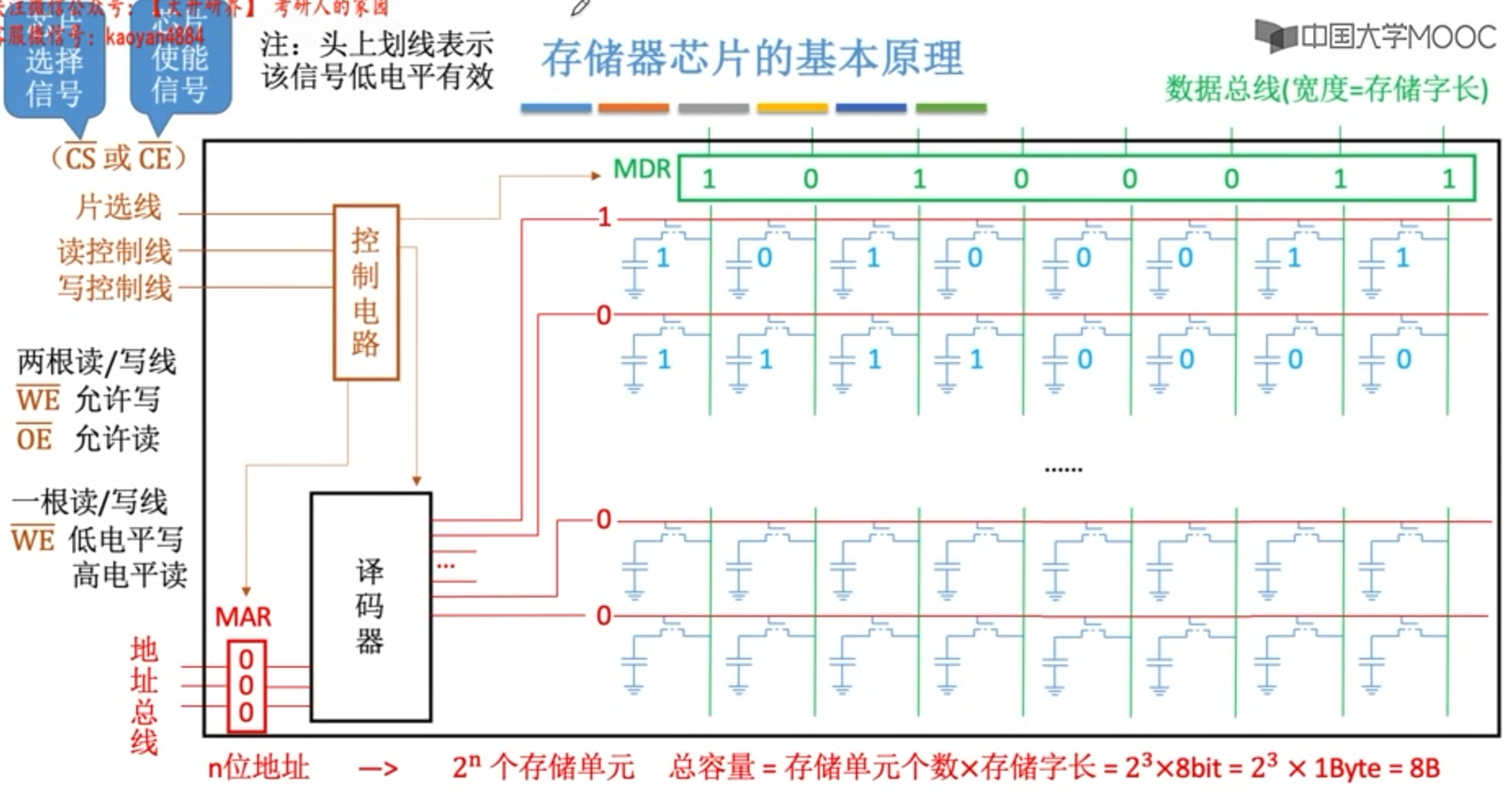
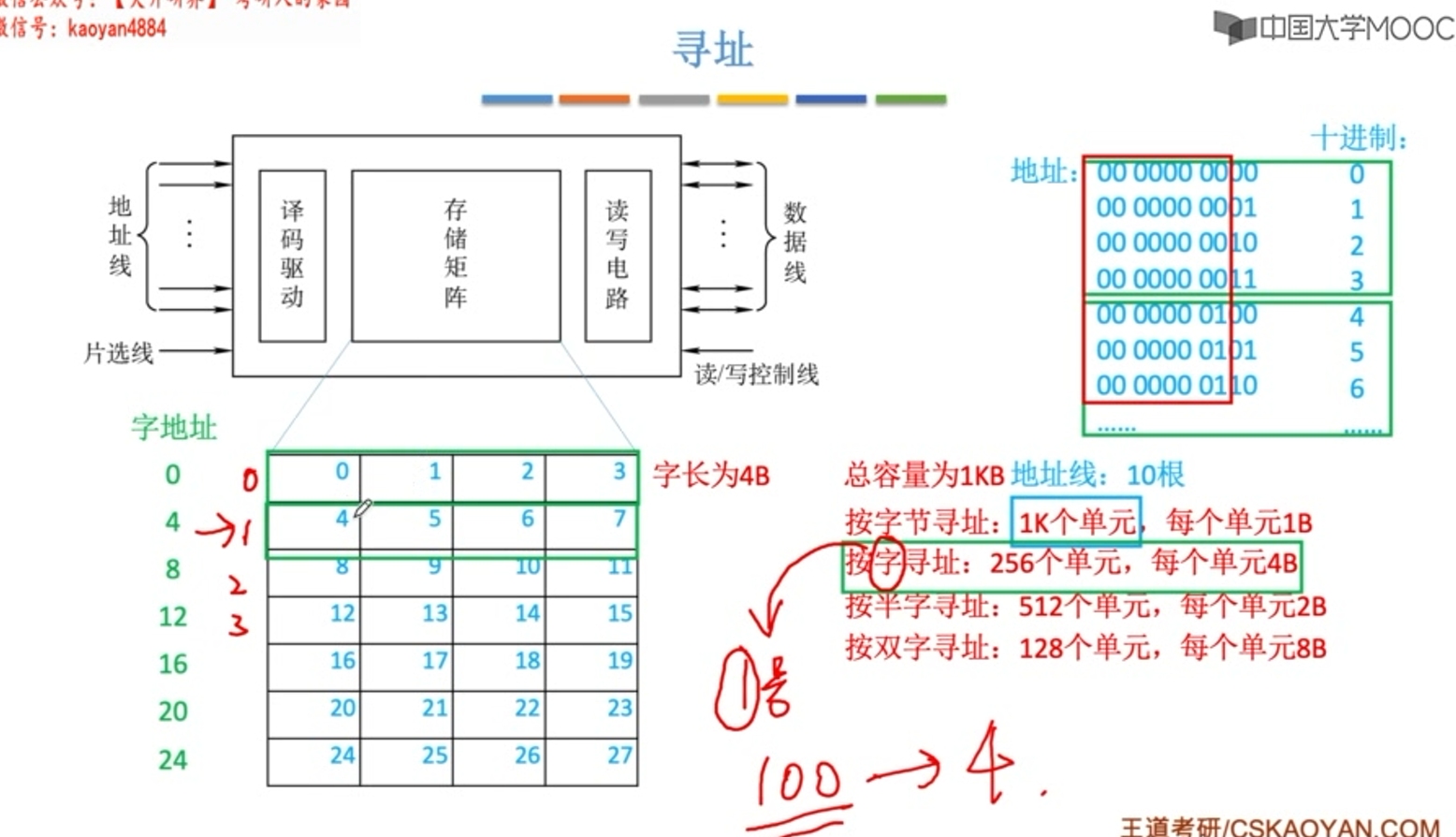
按字节寻址 转换到 按字(4个字节32位)寻址 : 地址左移两位
按字节寻址 转换到 按半子(2个字节16位)寻址: 地址左移一位
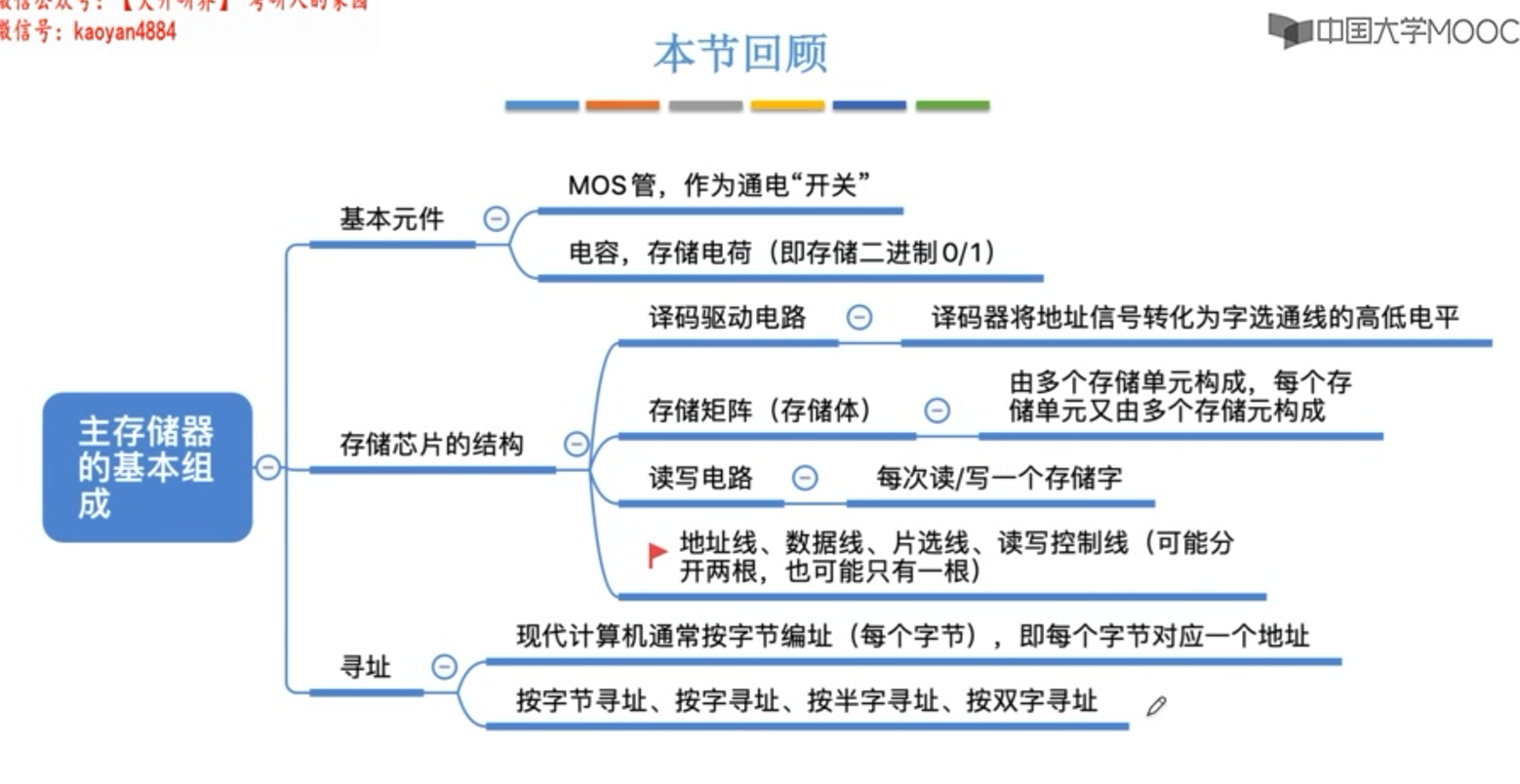
DRAM与SRAM
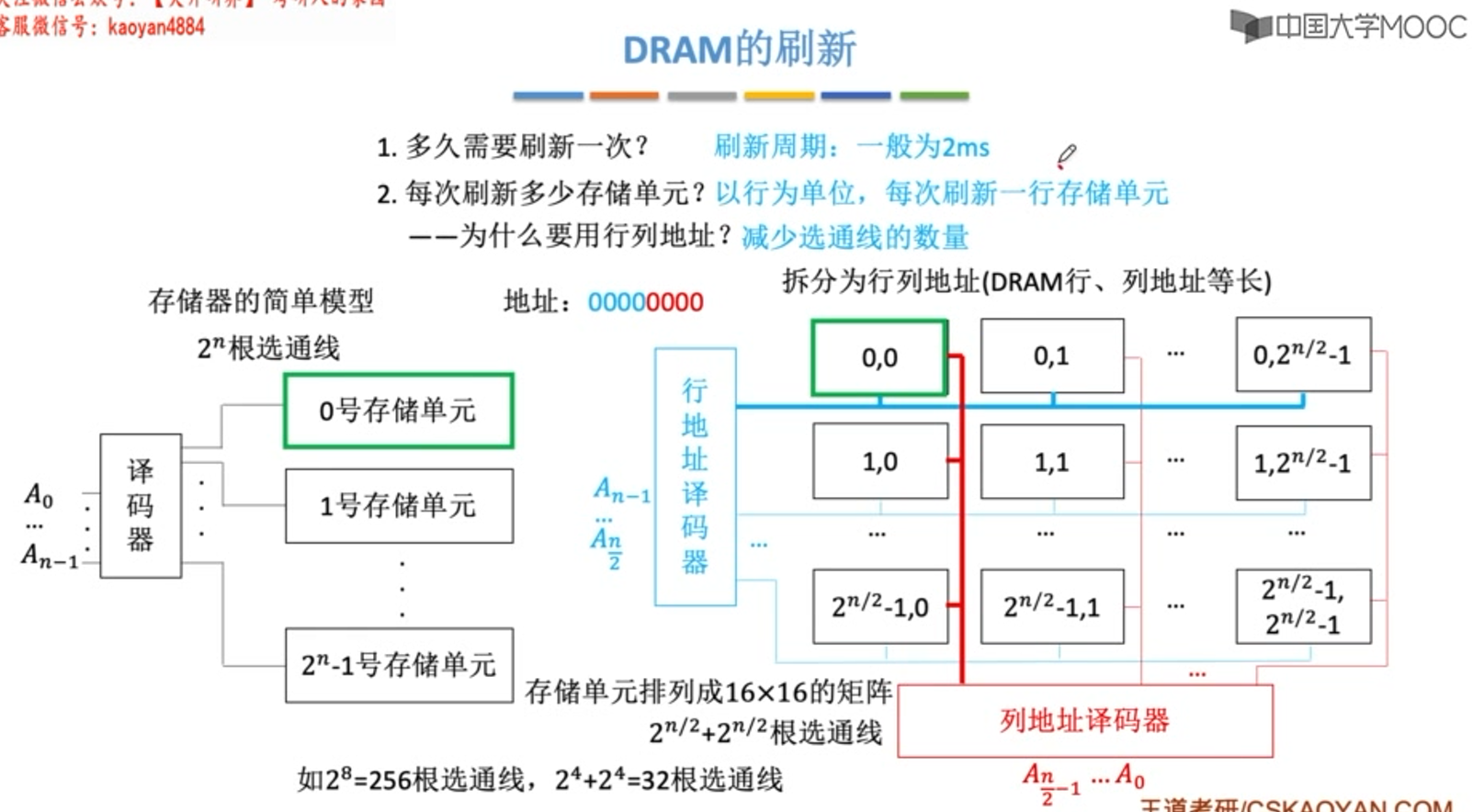
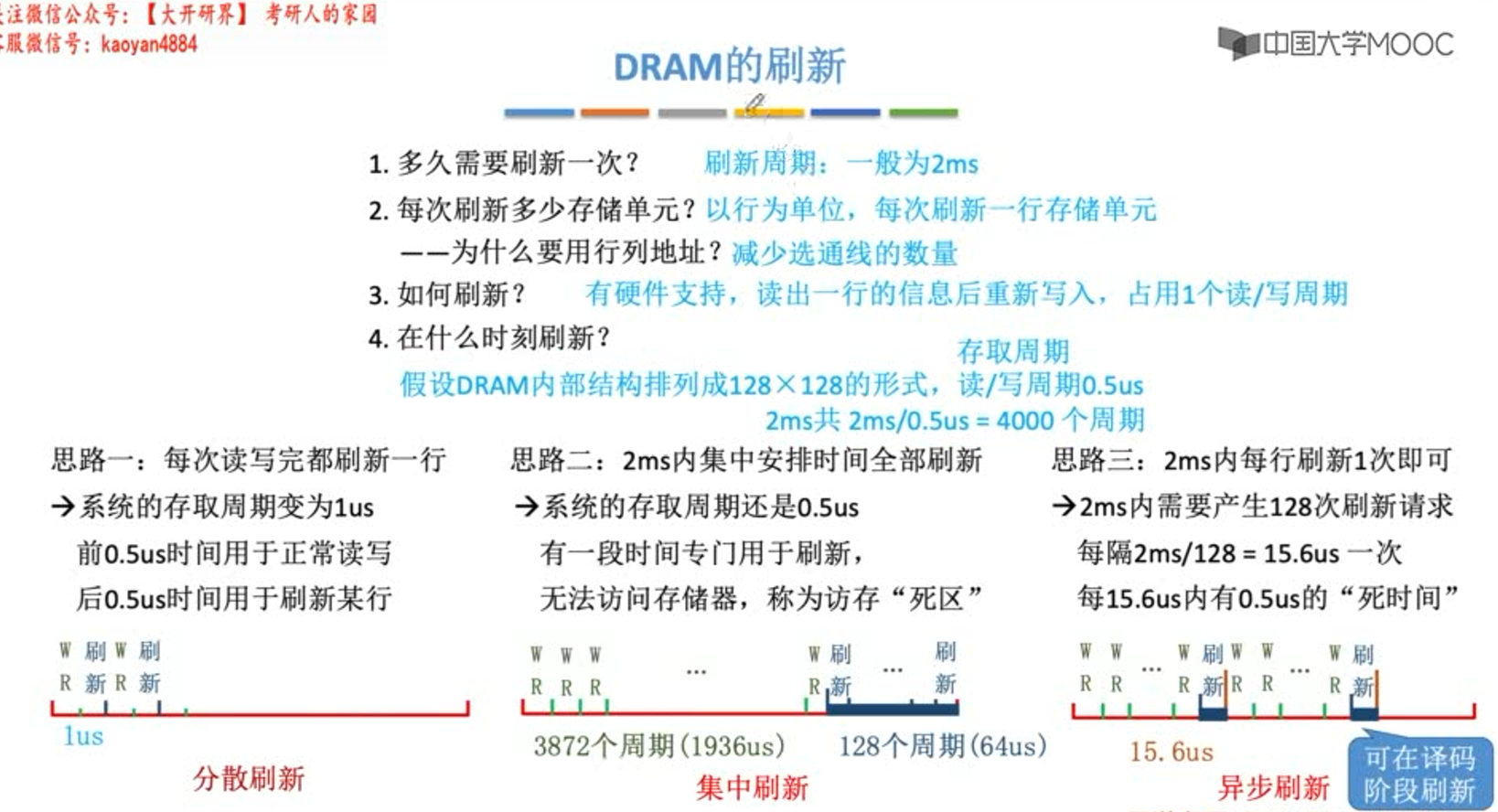
分散刷新
- 优:没有死区
- 缺:加长了系统的存取周期(存储芯片的存取周期为0.5us,则系统的存取周期为1us)。注意和存储芯片的存取周期是分开的,即系统的存取周期变成1us = (0.25us + 0.25us)+0.5us.
集中刷新
- 优:读写操作时不受刷新工作的影响
- 缺:集中刷新期间(死区)不能访问存储器
异步刷新
- 优:缩短了“死时间”(不是没有了),充分利用了刷新间隔为2ms的特点

ROM
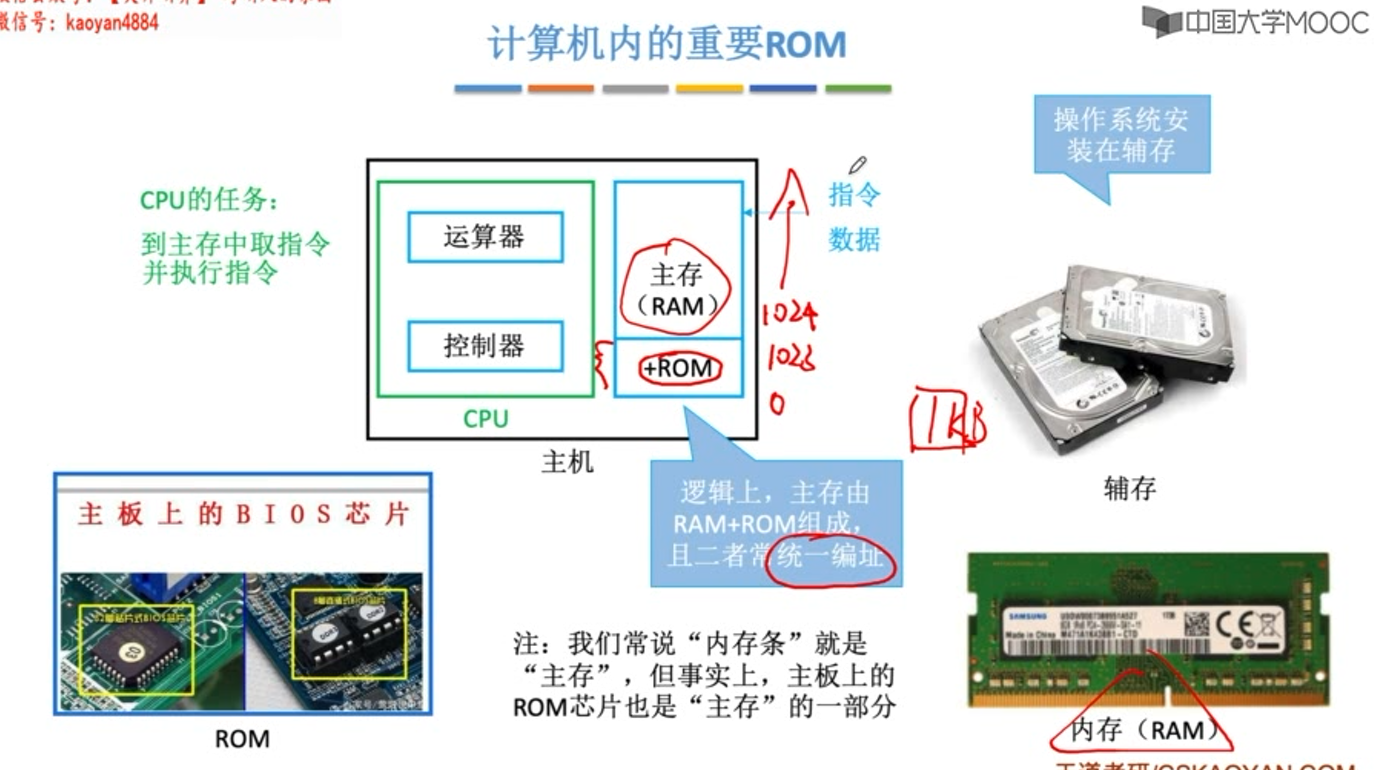
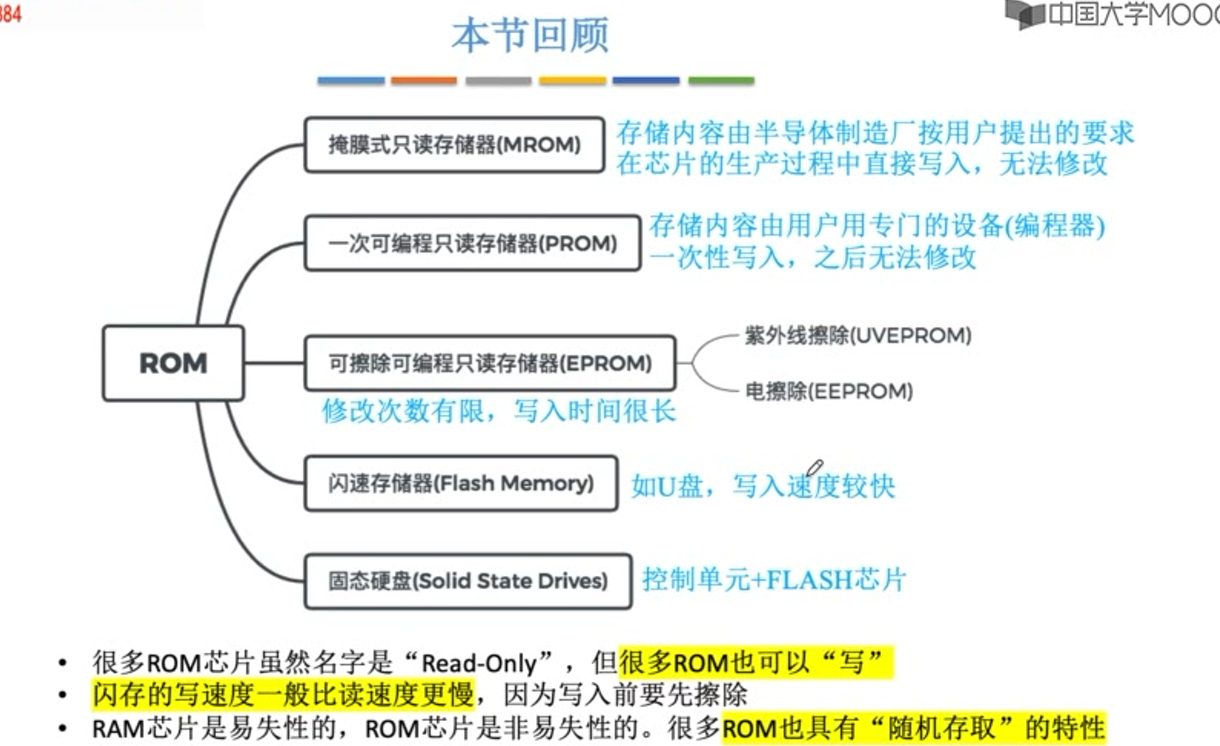
ROM芯片结构较RAM相比简单,位密度高。
光盘 CD-ROM ,但不属于ROM存储器,是只读型光盘存储器。
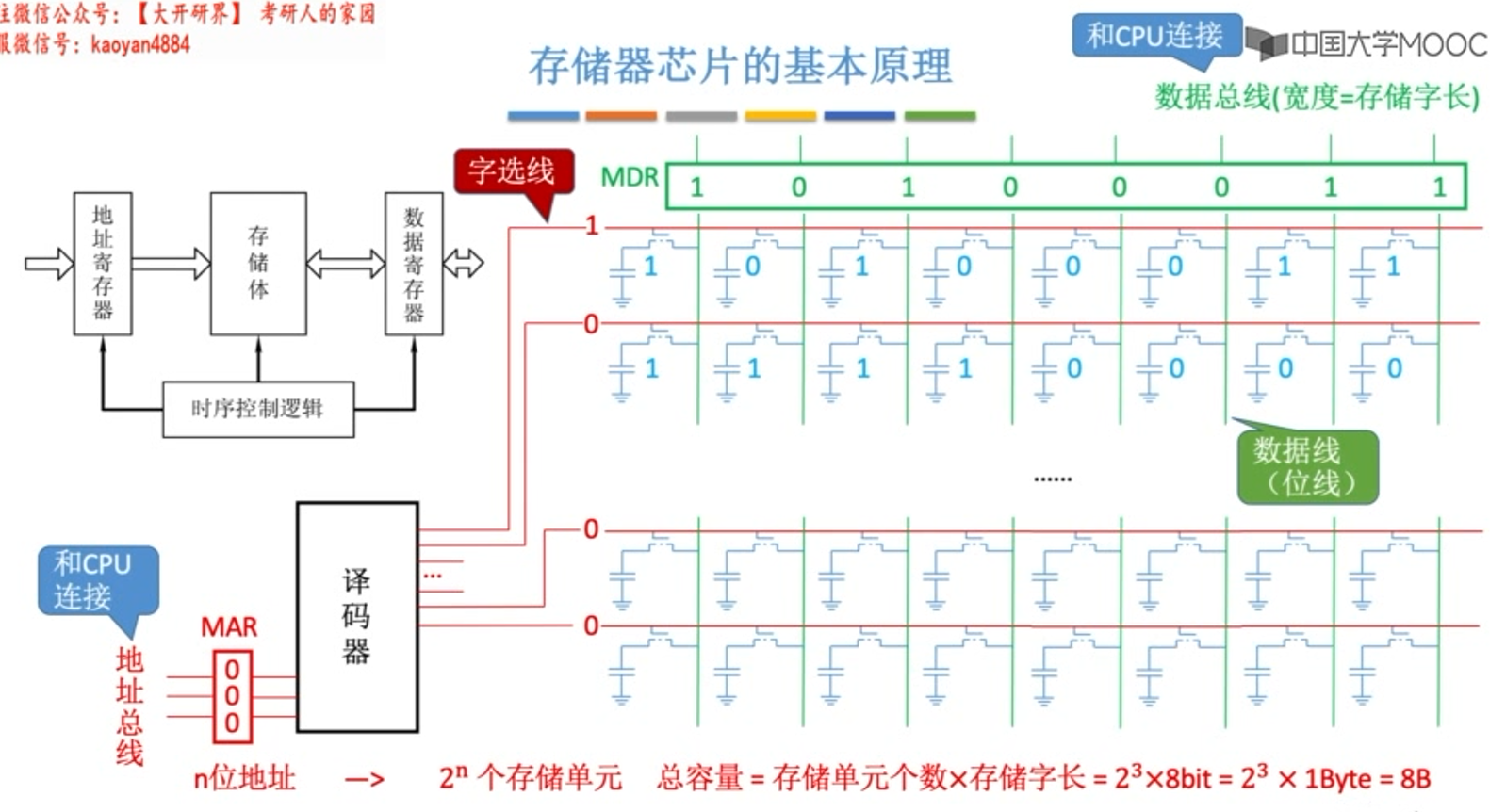
主存与CPU的连接
- 主存储器通过数据总线、地址总线和控制总线与CPU相连
- 数据总线的位数与工作频率的乘积 正比于 数据传输率
- 地址总线的位数决定了可寻址的最大内存空间
- 控制总线(读/写)指出总线周期类型和本次输入/输出操作完成的时刻
- 合理选择存储芯片
通常选用ROM存放系统程序、标准子程序和各类参数,RAM则是为用户编程而设置的。
- 地址线的连接
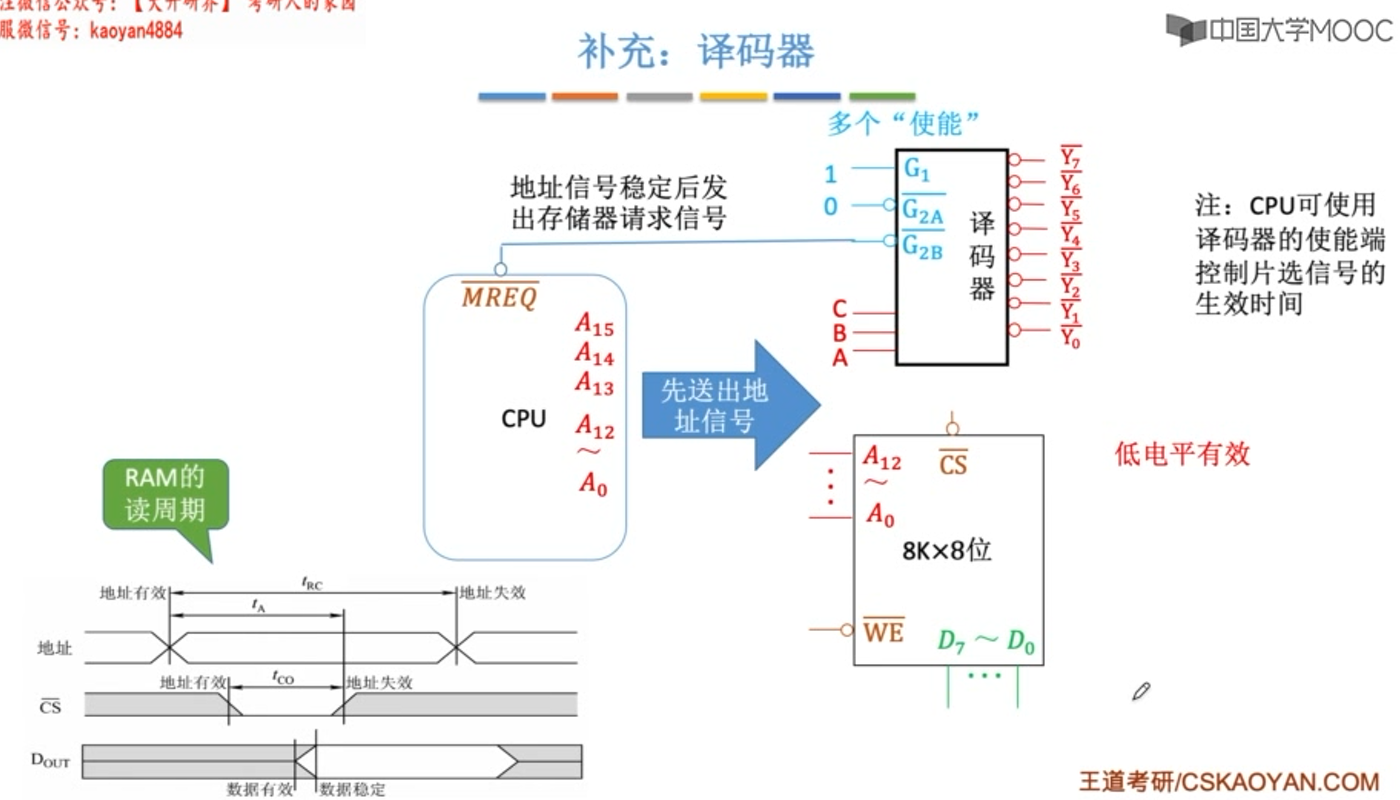
通常将CPU地址线的低位与存储芯片的地址线相连,以选择芯片的某一单元(字选)。字选的译码由芯片的片内逻辑完成。
CPU地址线的高位在扩充芯片时使用,以选择某一(组)存储芯片(片选)。片选的译码由外接译码器完成。
3. 数据线的连接
CPU的数据线与存储芯片的数据线不一定相等,相等时直接连接;不等时必须对存储芯片进行扩位,使CPU数据线数与存储芯片数据位数相等。
- 读/写命令的连接
CPU的读写命令线一般可直接与存储芯片的读写命令线相连,通常高电平读、低电平写。
有些CPU的读写线是分开的(均为低电平有效),此时应和存储芯片的读写线分别相连。
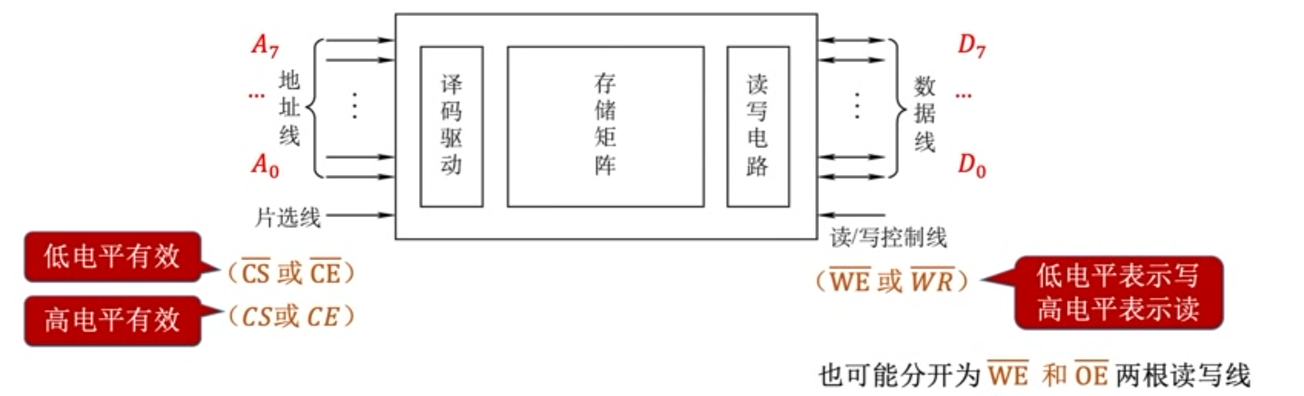
5. 片选线的连接
片选有效信号与CPU的访存控制信号(MREQ低电平有效)有关,只有当CPU要求访存时,才会要求选中芯片;若CPU访问I/O,则访存控制信号为高电平,表示不要求存储器工作。
芯片是否被选中完全取决于片选控制端(CS低电平有效)是否接收到来CPU的片选有效信号(由地址线高位或这译码器送来)。
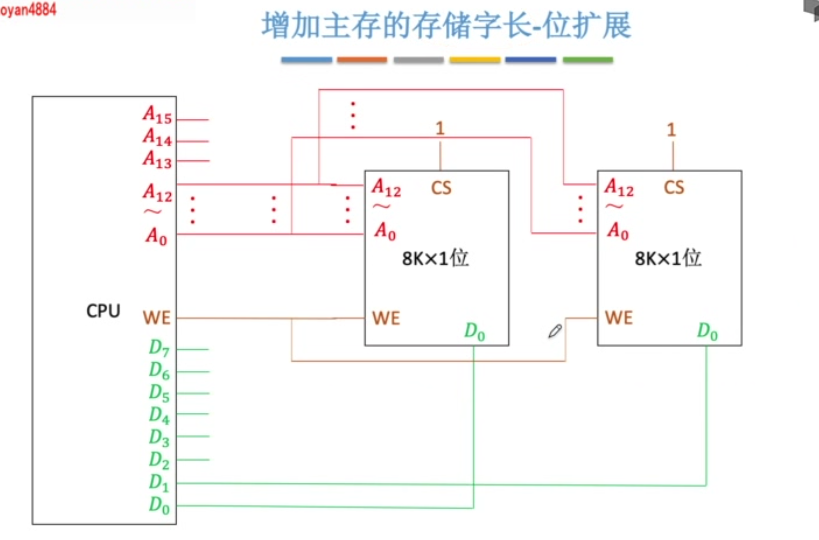
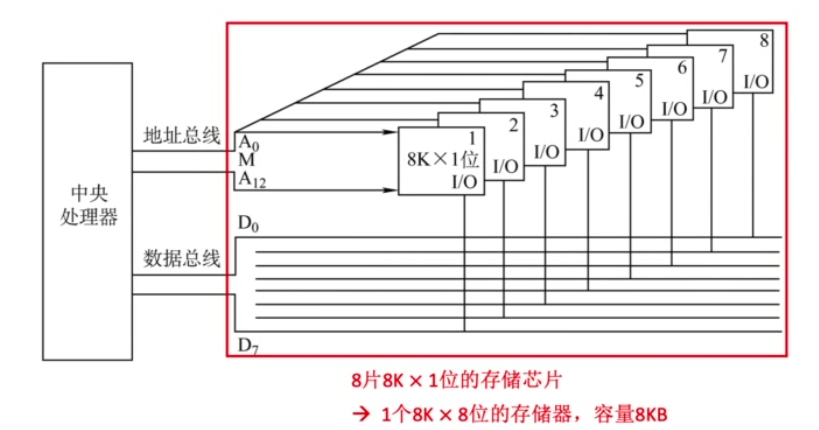
位扩展
多个存储芯片的地址线、片选线、读写控制线并联,数据线分别引出。
同一时刻选中并联的所有芯片,同时存取数据。
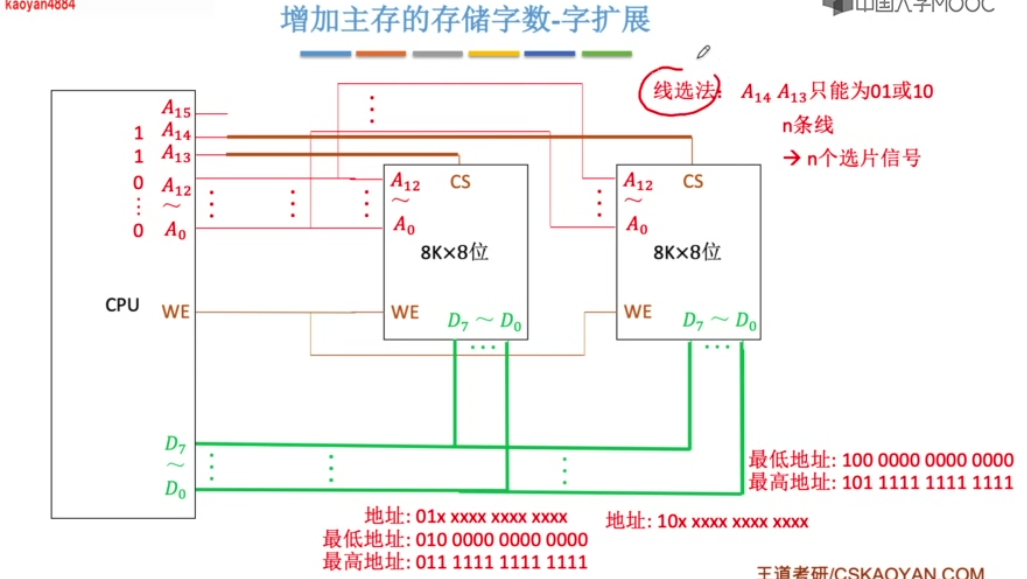
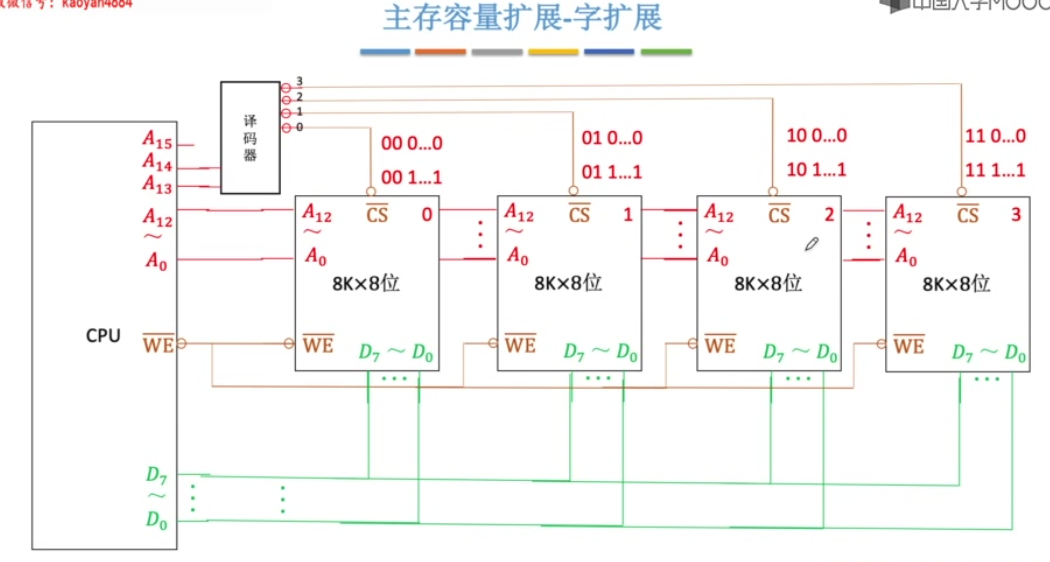
字扩展
多个芯片的地址线、数据线、读写控制线并联,片选线分别引出。
由片选线选中相同低位地址的不同芯片。
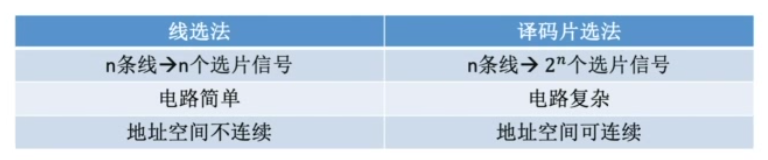
线选法
译码片选发
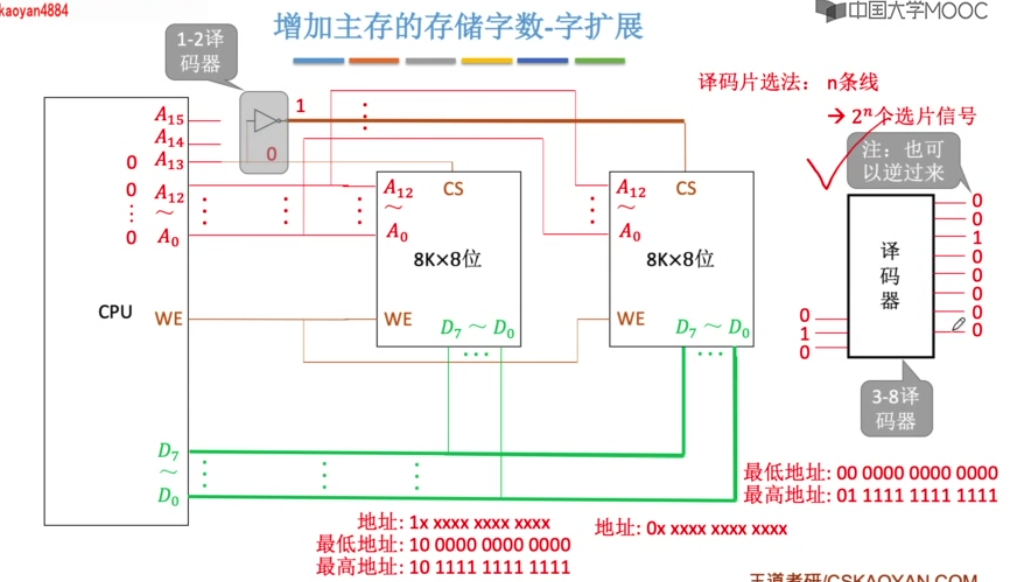
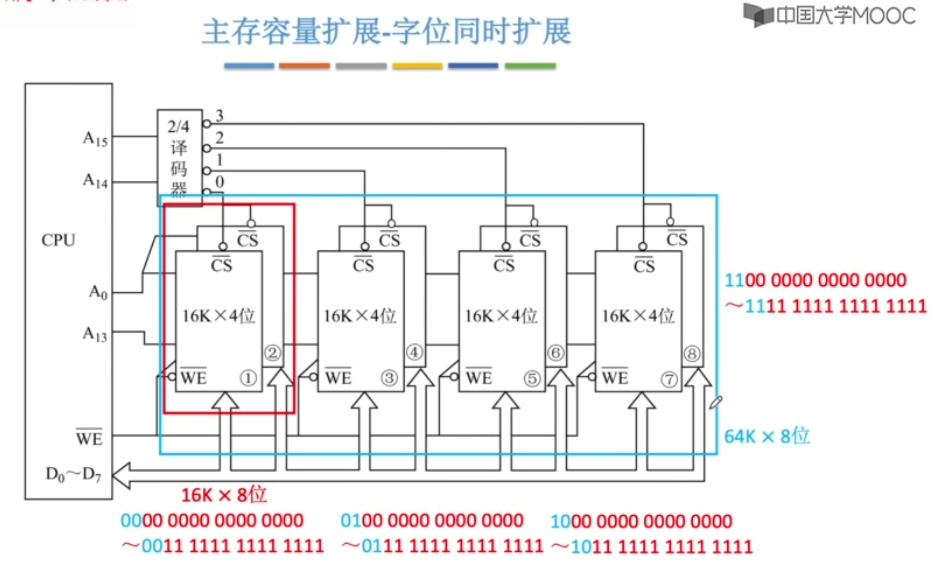
字位同时扩展
各芯片的地址线、读写控制线并联,数据线、片选线分别引出。
由片选线选中相同低位地址的一组芯片,该组芯片同时读写。
主存与多核CPU的连接
多核CPU出现后,随之而来的就是多核CPU对内存的同时读写问题。
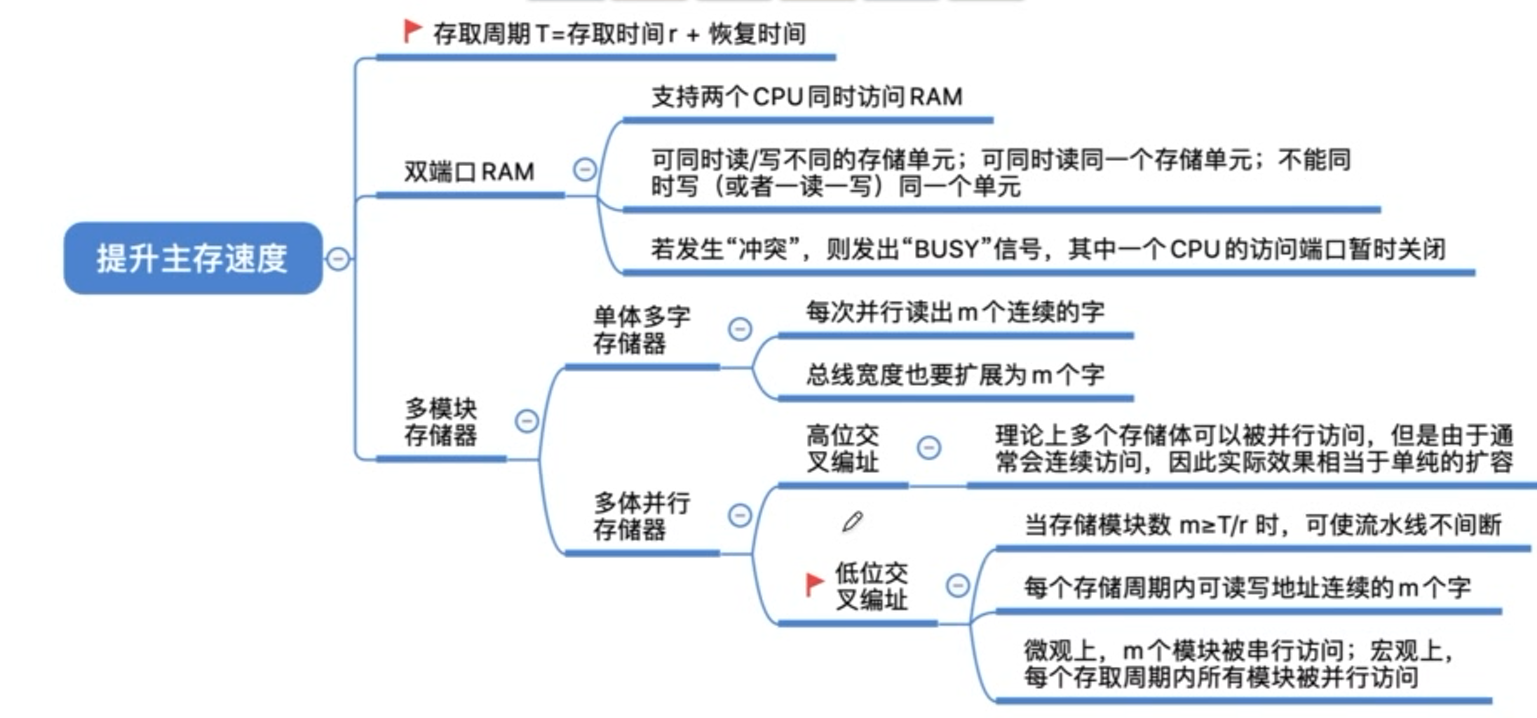
双端口RAM
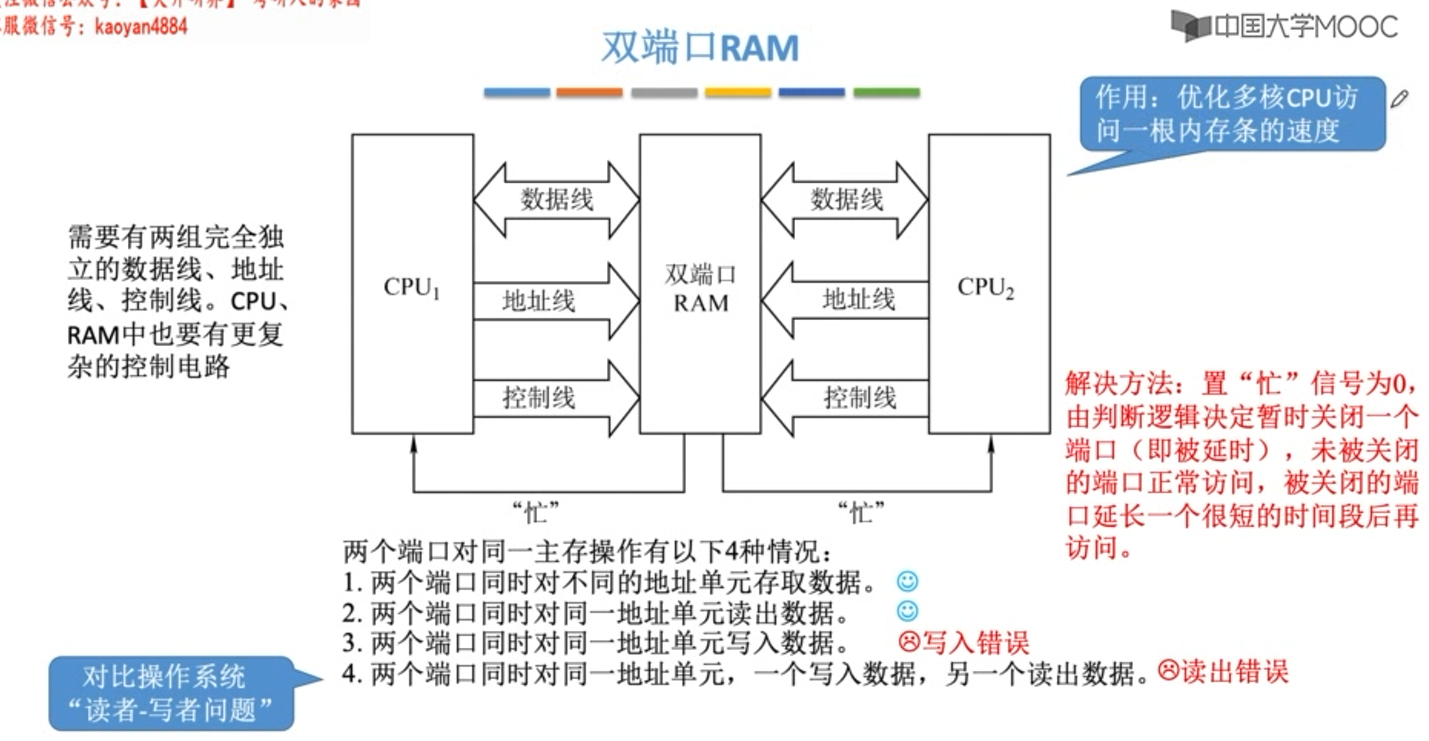
多主存与CPU的连接
多模块存储器
多模块存储器是一种空间并行技术,利用多个结构完全相同的存储模块的并行工作,来优化由读写恢复时间导致的吞吐量低下。
这里的恢复时间不是刷新时间。而是由于破坏性读出造成的恢复时间,即存取周期(Tm)=存取时间(Ta)+恢复时间。
存取周期往往比存取时间大的多,甚至可达Tm=2*Ta,因为存储器中的信息读出后需要马上再生。
高位交叉存储器,总是把低位的体内地址送到由高位体号确定的模块内进行译码,是顺序存储器。
低位交叉存储器,总是把高位的体内地址送到由低位体号确定的模块内进行译码,是交叉存储器。
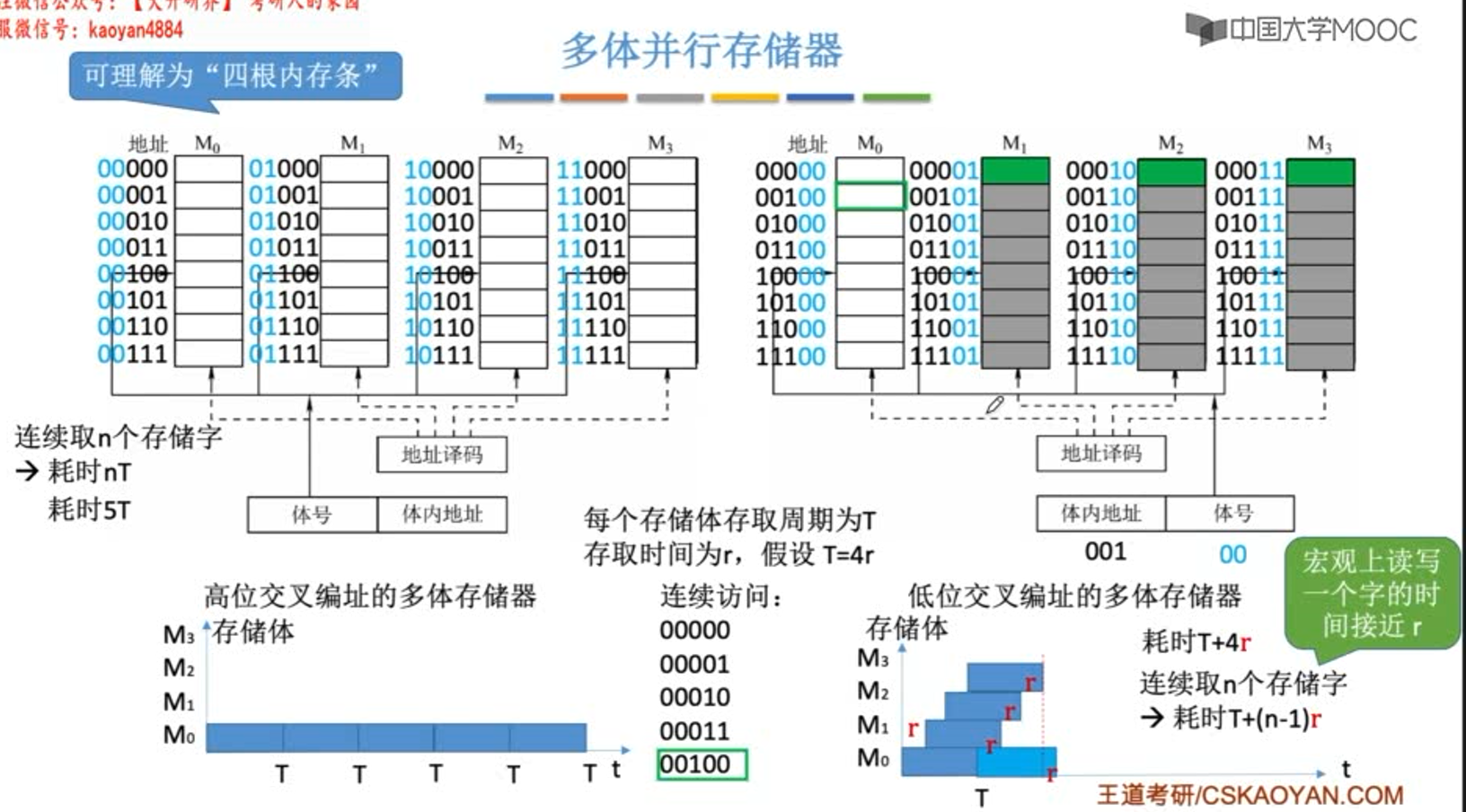
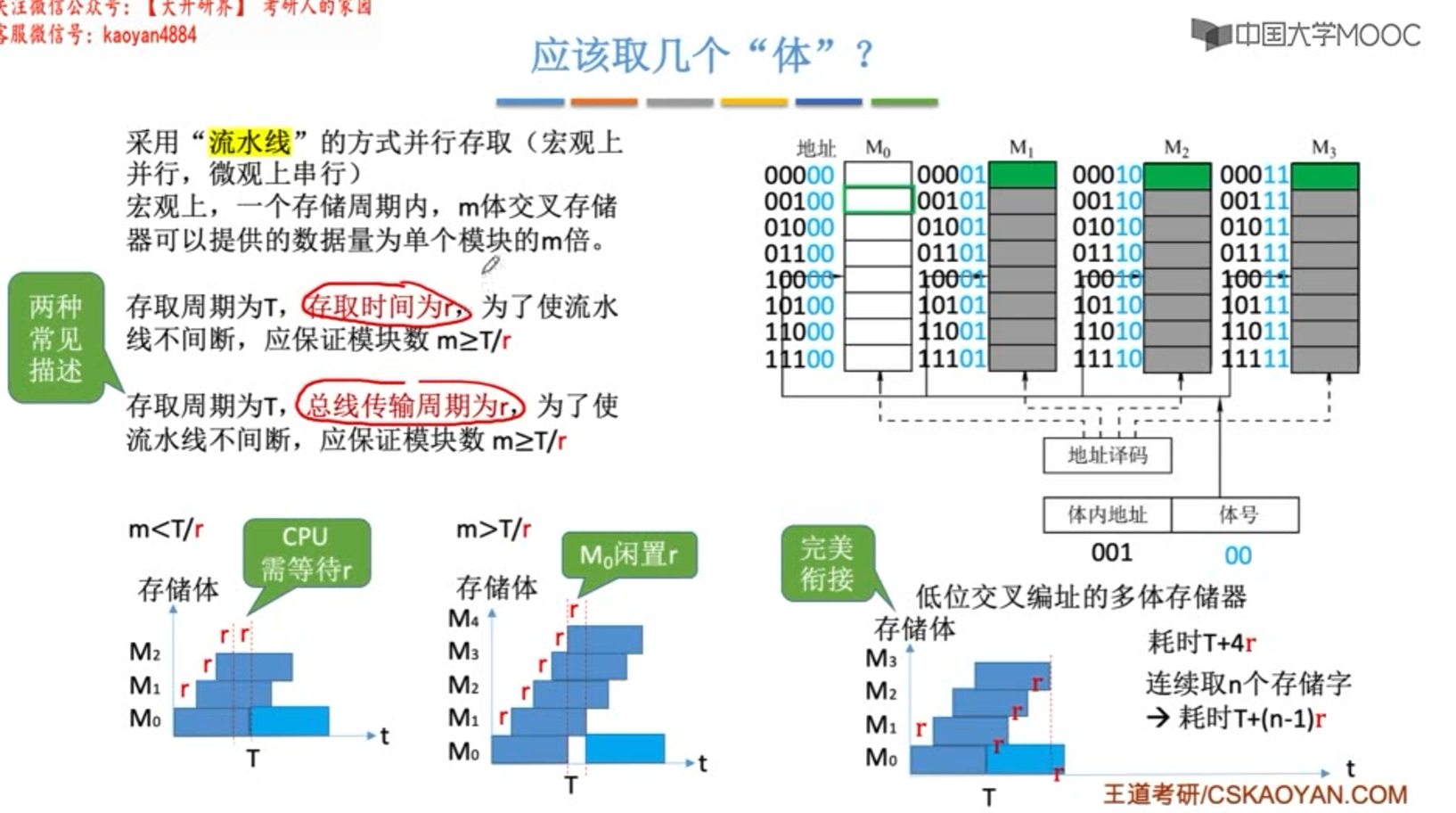
上图中T=3r,m为交叉存取度。r在这里是存取时间,有时也会说成总线传输周期。
若m = 3 , 在3r时刻(每个存储器都存取过一轮了),M0还没有恢复,需要等待r时间。
若m = 5 , 在5r时刻(每个存储器都存取过一轮了),M0已经恢复完后r时间了,无需等待可直接存取。
低位交叉编址的优势也是建立在程序一般都是顺序存放在内存中,并且顺序执行的。
问:地址x存放在第几号存储体?
若x为二进制,可直接通过低位的体号判断。若x为十进制,x%m = 存放的体号
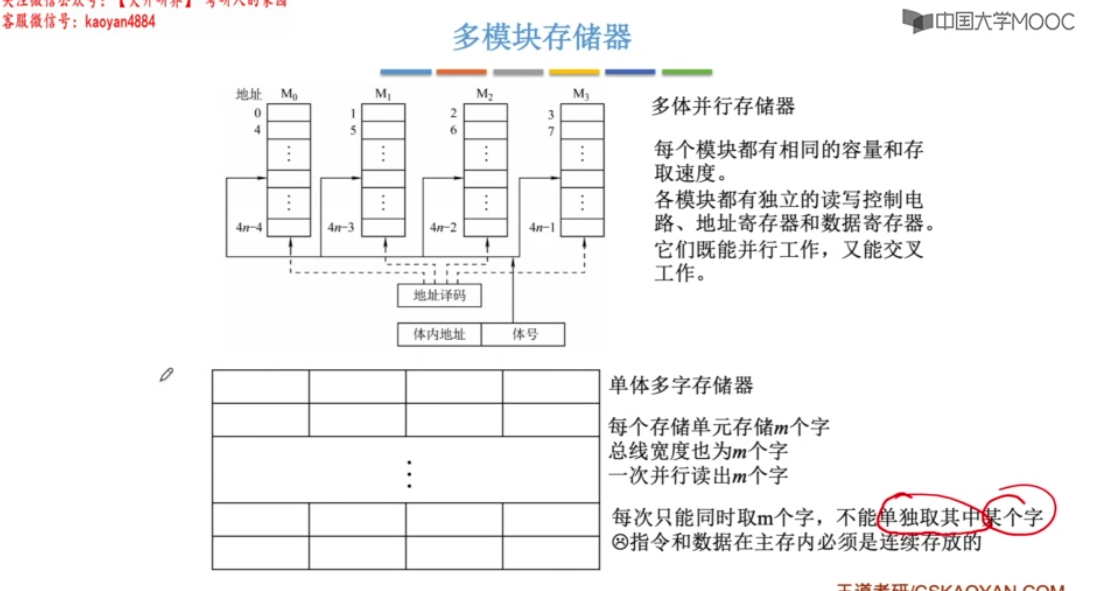
对 单体多字存储器 ,一旦遇到转移指令,或者操作数不能连续存放,效果就不好。
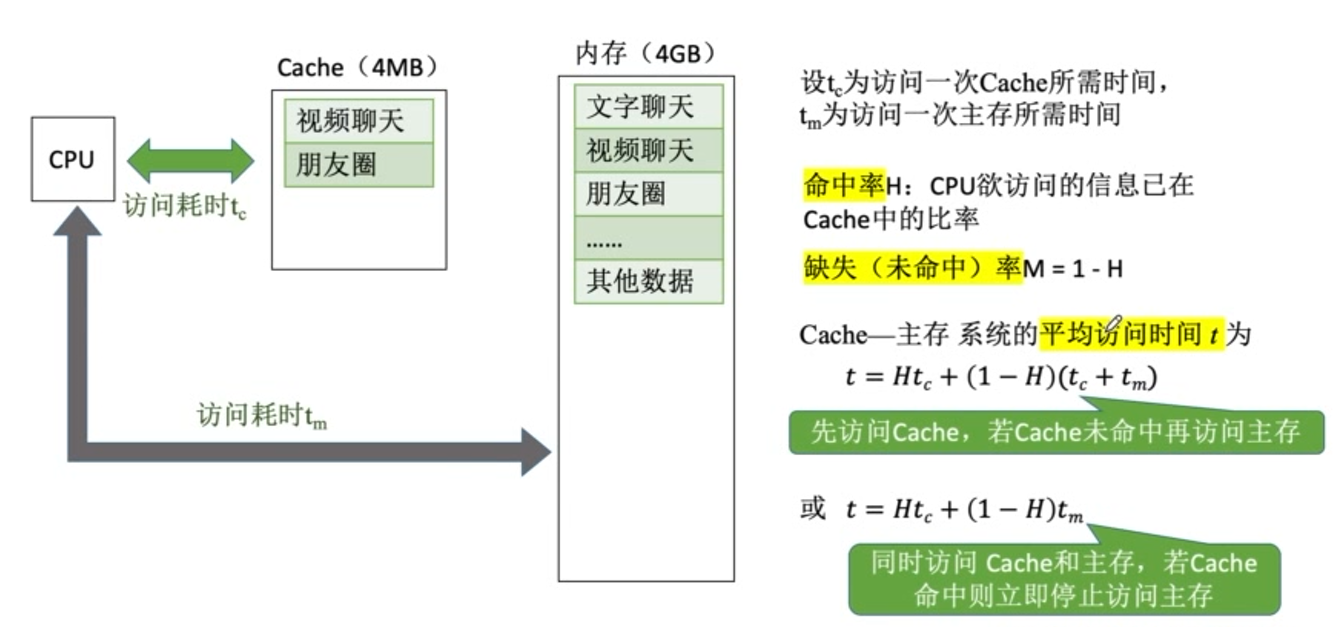
Cache的基本概念
在cache机制中,以块为单位利用了空间局部性,相当于预取机制。
cache机制本身利用了时间局部性。
cache按照某种策略,预测CPU在未来一段时间内欲访问的数据,将其装入cache。
cache机制全部由硬件实现。
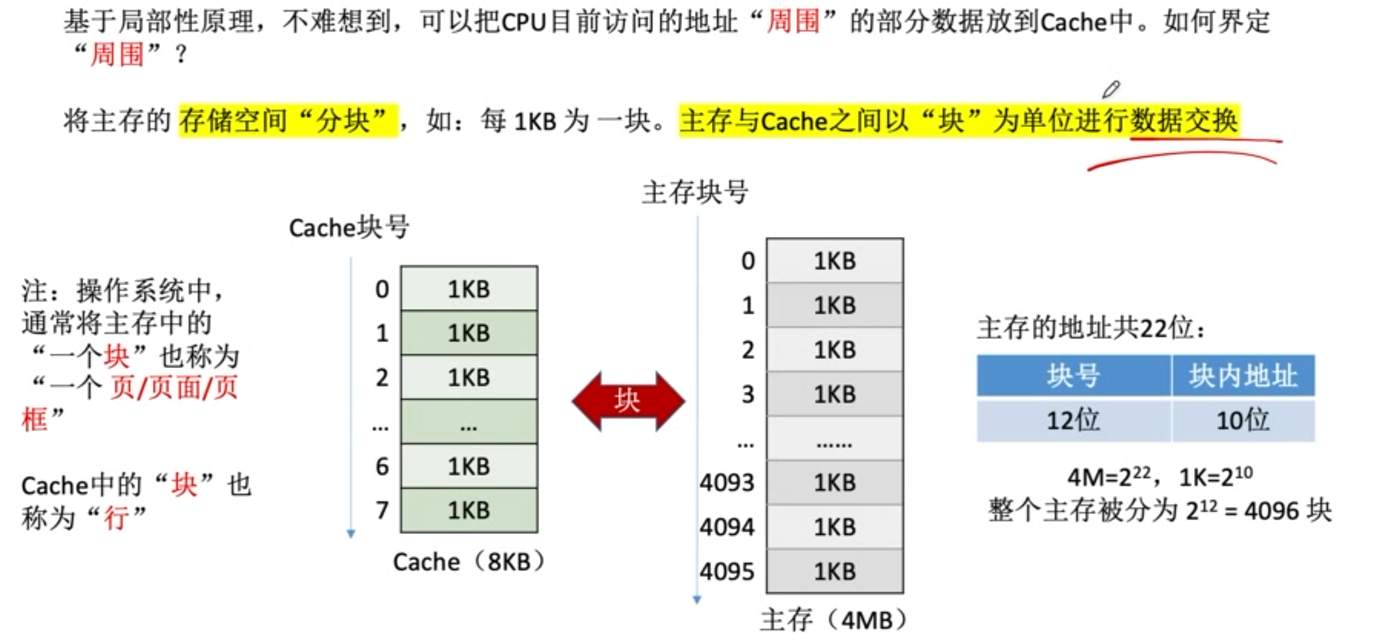
类似使用局部性原理,利用整体中的部分作为单独一层来缓解速度不匹配问题的时候。
主要要考虑以下问题:
- 部分与整体的映射关系
- 部分的替换算法
- 部分与整体的一致性问题
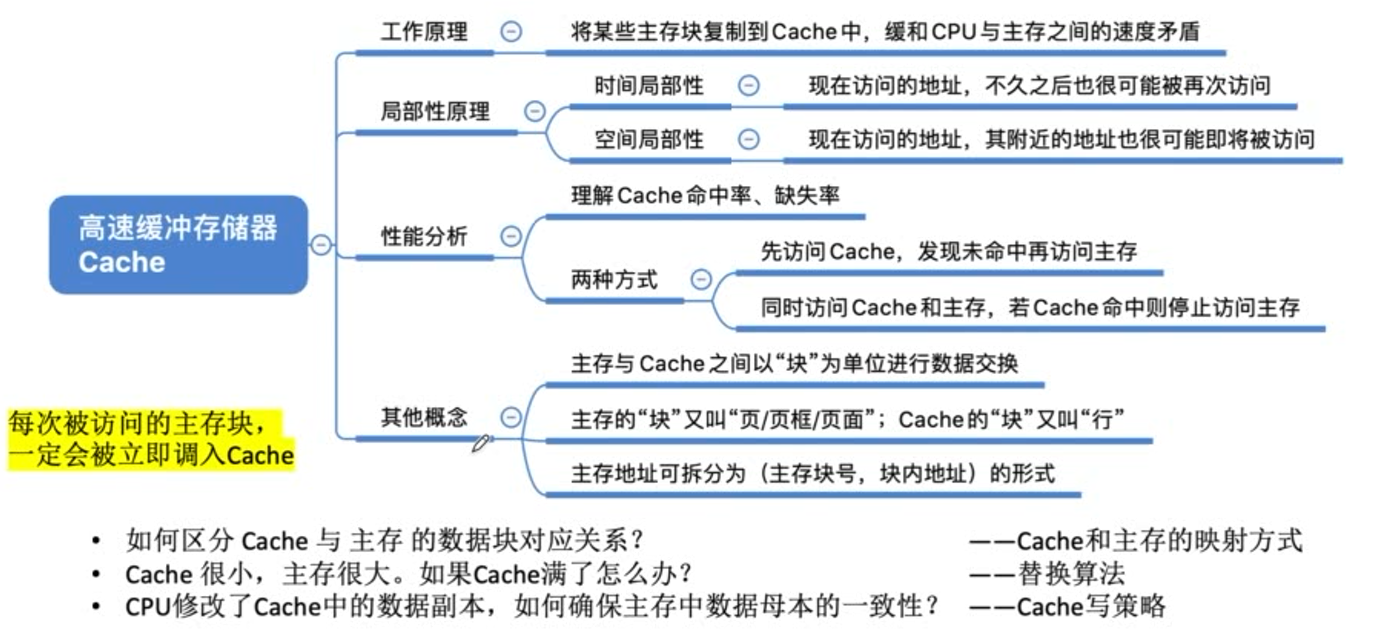
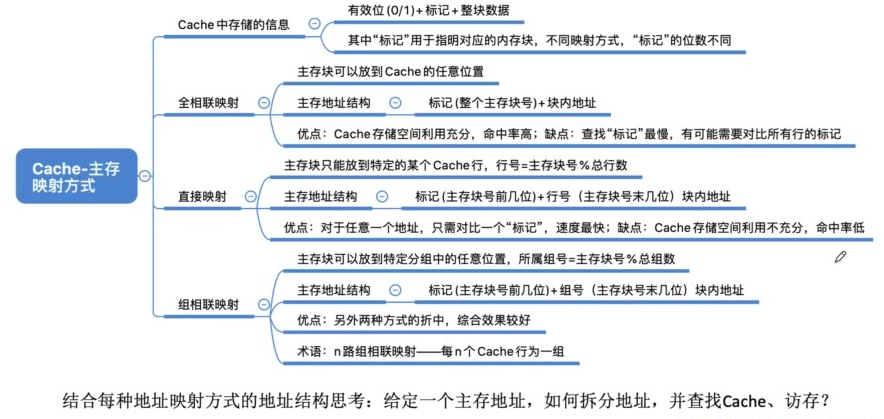
Cache的映射方式
标记位指示内存中的块号。
有效位指示cache中的信息是否有效。
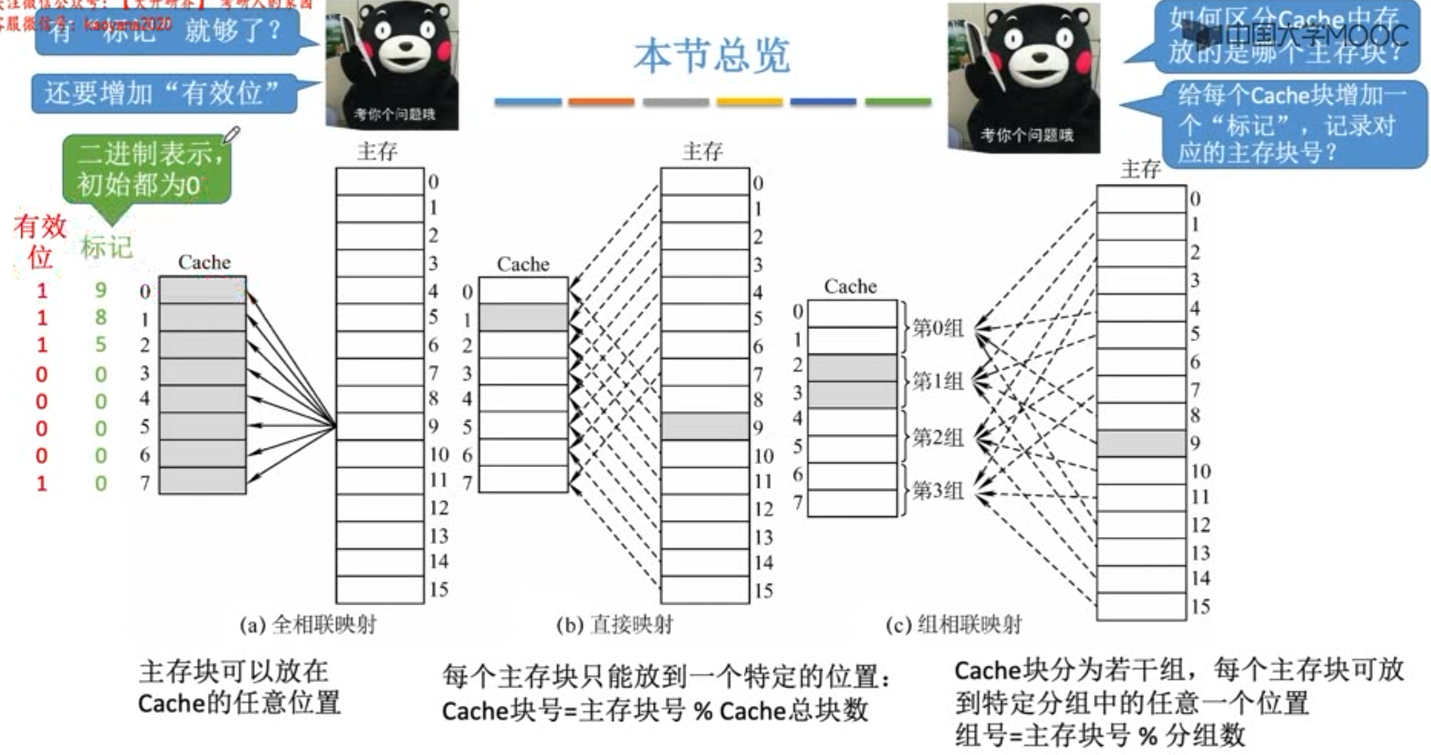
全相联映射
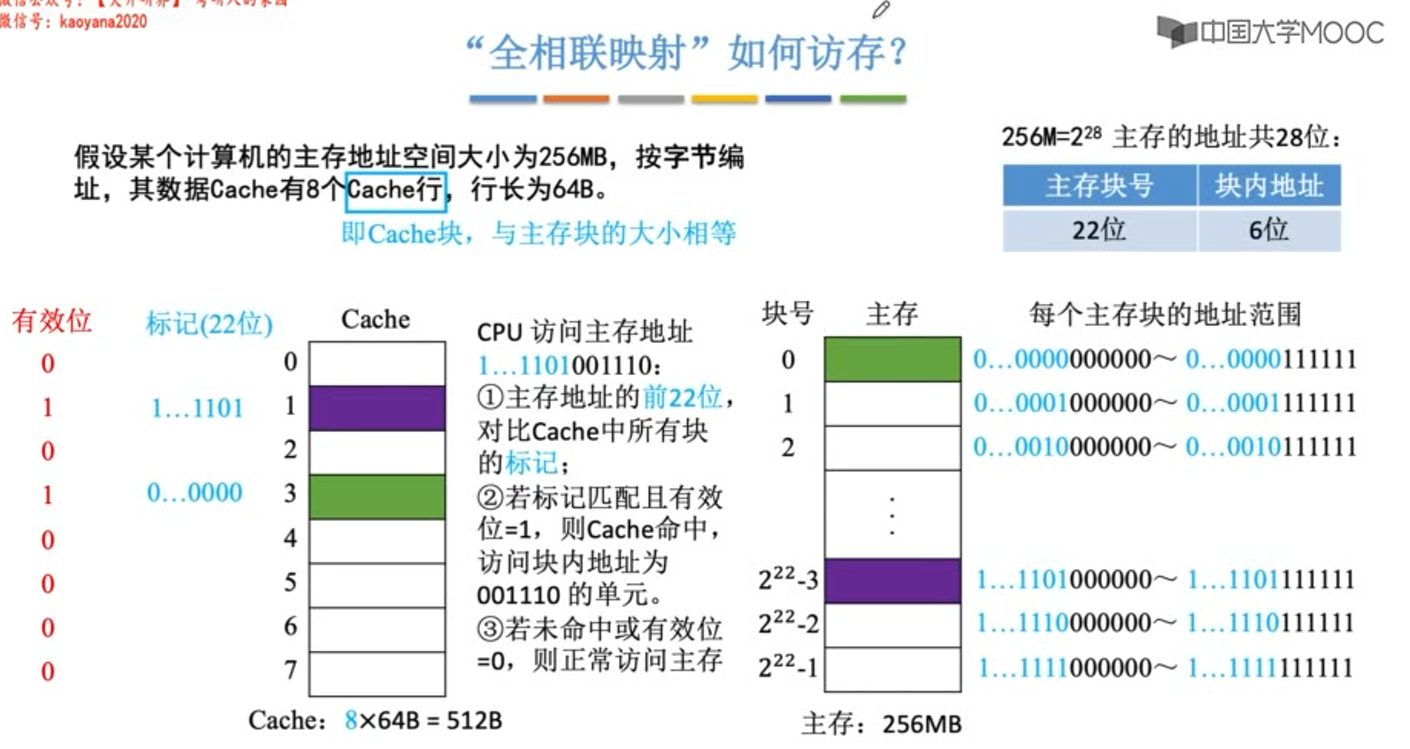
直接映射
直接映射,主存块在cache中的位置=主存块号%cache总块数。
若cache总块数(行数)为2n,则主存块号的末尾n位直接反应它在cache中的位置,其余主存块号作为标记位即可。
**下图中cache块中的内容并不是cache块内的数据,只是代表由主存块号后三位确定的cache块。
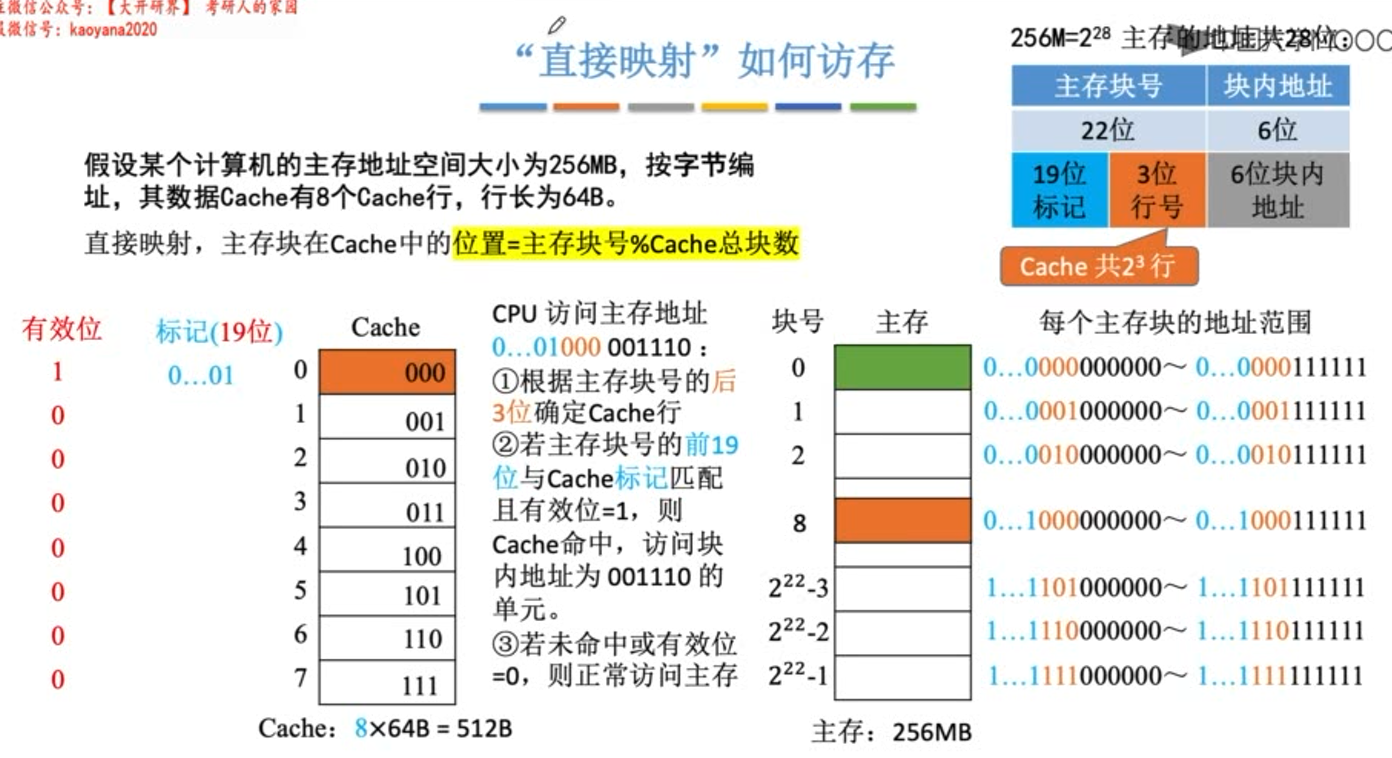
组相联映射
组相联映射,所属分组=主存块号%分组数。
若cache总共分成2n组,则主存块号的末尾n位直接反应它在哪一个cache组中,其余主存块号作为标记即可。
路数越大,即每组cache行越多,发生块冲突的概率就越低,相联比较的电路成本就越复杂。所以选择适当的组数Q,可以使组相联映射的成本接近直接映射,且性能上接近全相联映射。
**下图中cache块中的内容并不是cache块内的数据,只是代表由主存块号后2位确定的cache组号。
**二路组相联,实际上就是将cache行两两合并。外部采用直接映射由2位组号(或者看成合并后的行号)确定,内部采用全相联方式(在两个cache行内随意放)。

多看几遍计组p120页例题
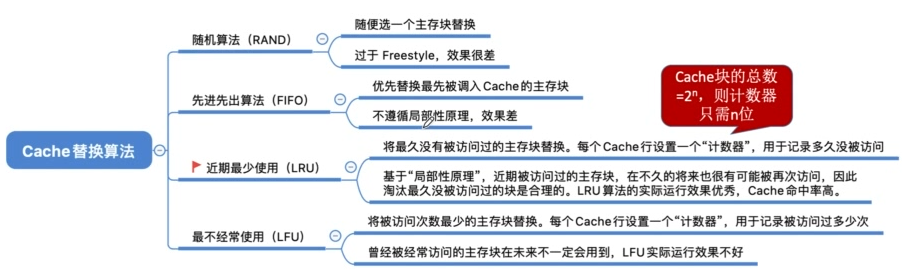
Cache的替换算法
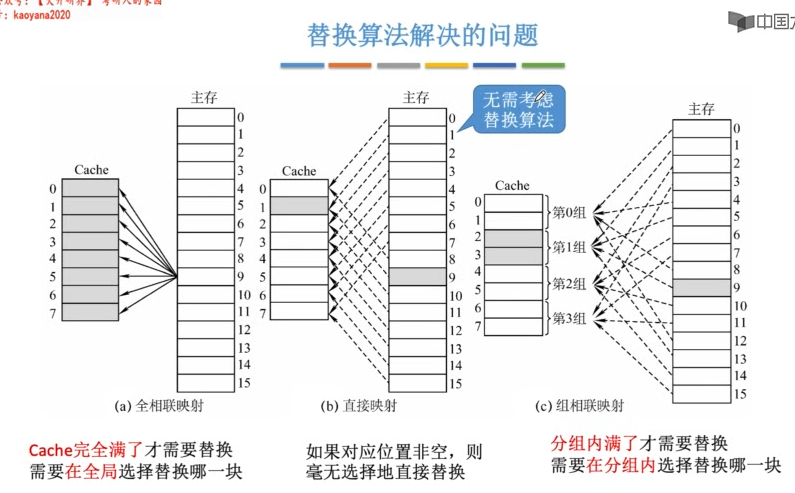
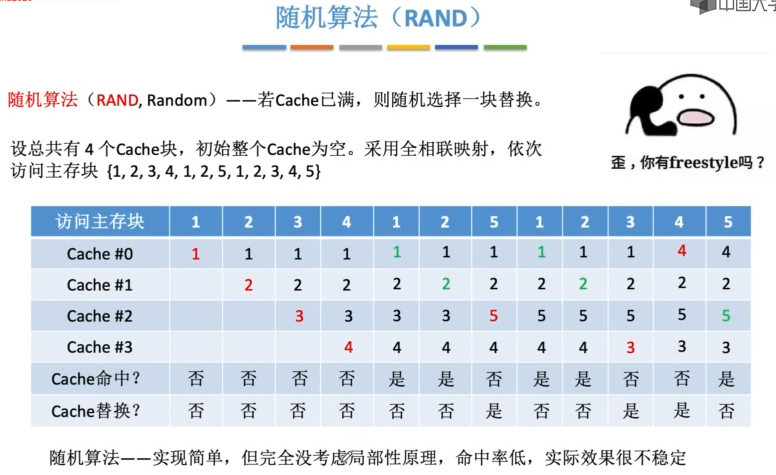
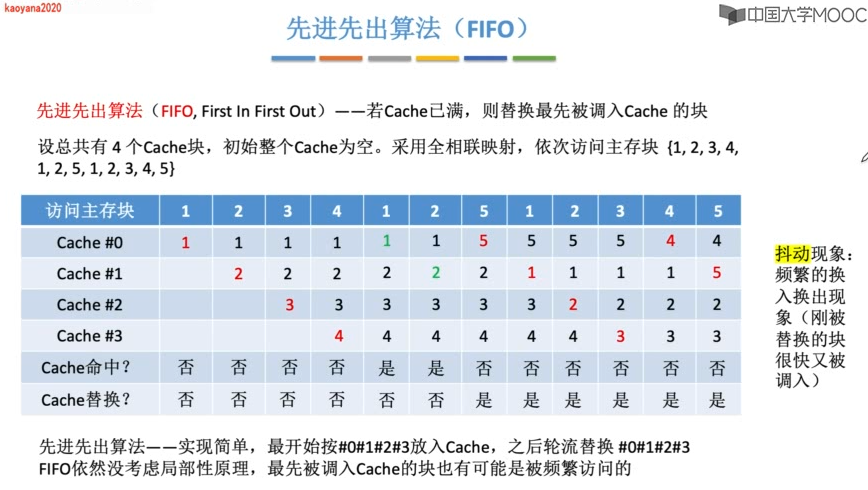
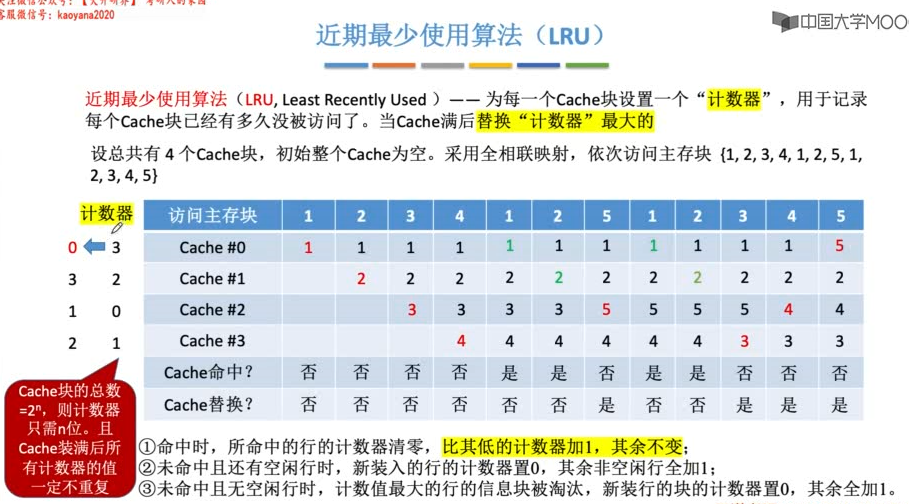
若是组相联映射,则计数器的位数由组大小决定,2路时一位LRU位,4路时两位LRU位。每组的LRU互不干扰。
当集中访问的存储区大小(但仍会映射到该组内)>cache组大小时,可能会发生抖动,如{1,2,3,4,5,1,2,3,4,5,1......},命中率为0。

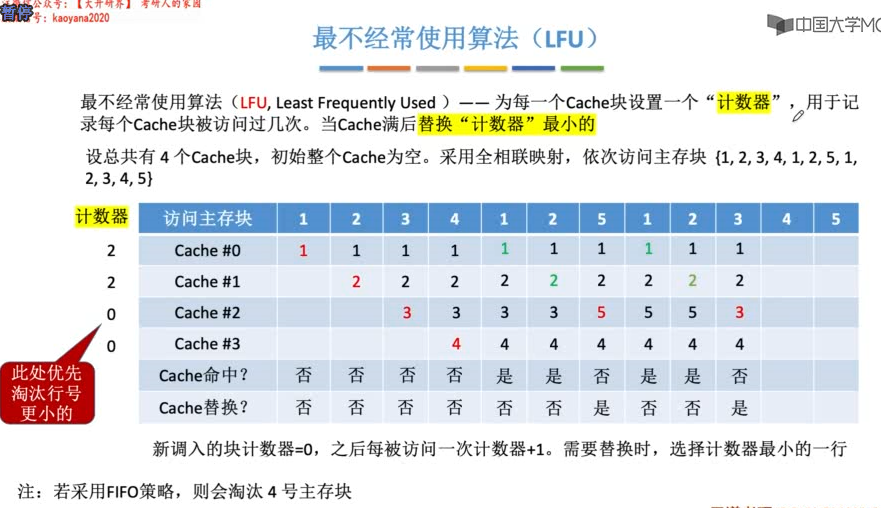
计数器的值可能会很大,需要更多的比特位来表示。

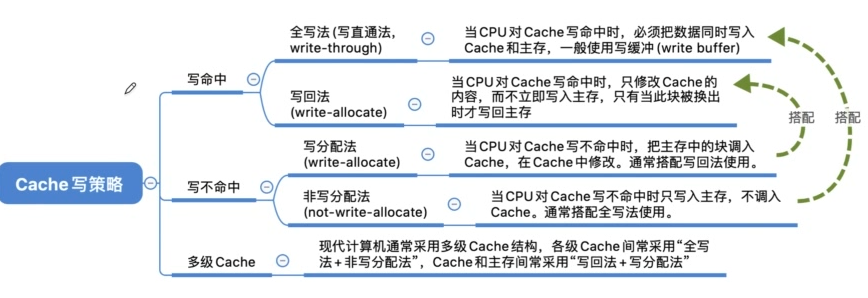
Cache写操作
写命中
回写法
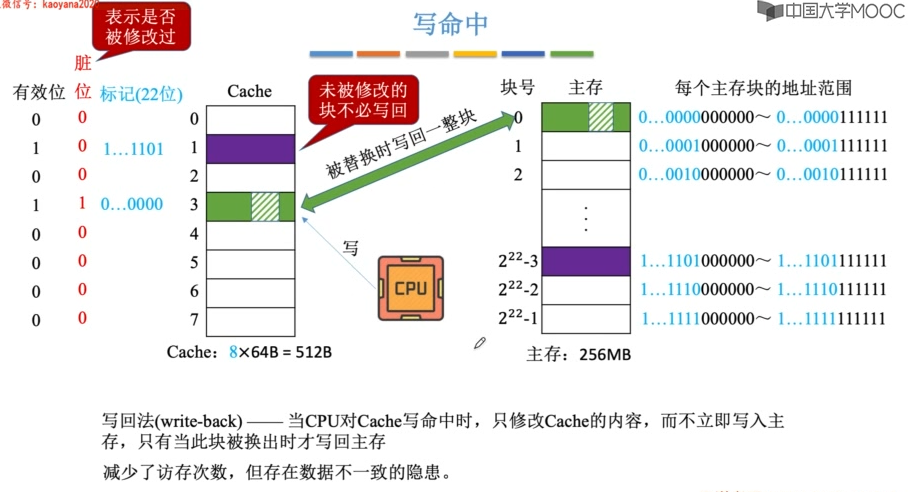
cache行需要设置一个修改位(脏位),修改位=1说明被修改过,替换时需要写回内存
全写法
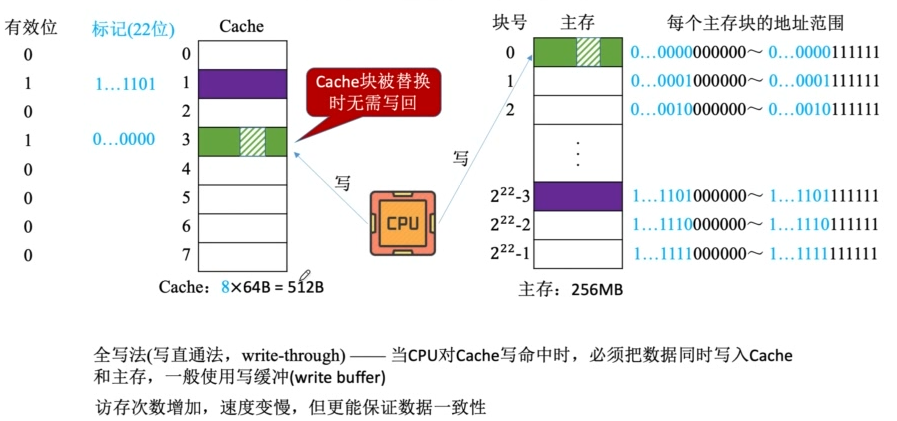
为了减少全写法直接写入内存的时间消耗,在cache和内存之间加一个写缓冲(write buffer)
写缓冲是一个SRAM实现的FIFO队列,CPU同时写数据到cache和写缓冲中,写缓存再控制将内容写入主存。
虽然write buffer可以解决速度不匹配的问题,但若出现频繁写时,write buffer会饱和溢出。
写不命中
写分配法
写分配法试图利用程序的局部性原理。
缺点是每次不命中都需要从主存中读取一块。

非写分配法

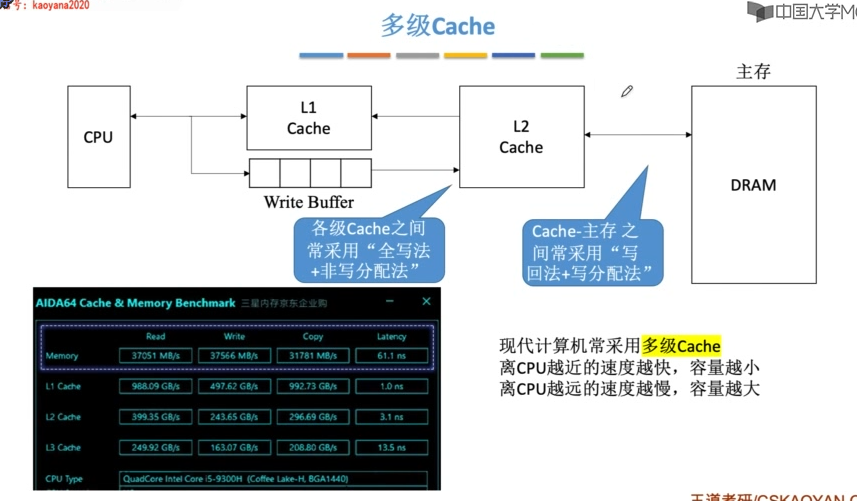
多级Cache
随着新技术的发展(如指令预取),需要将指令cache和数据cache分开设计,于是就有了分离式的cache结构。
统一cache(相对于分离cache)的优点是设计和实现相对简单。缺点是由于执行部件存取数据时,指令预取部件要从同一个cache读指令,会引发冲突。
分离cache可以解决冲突问题,减少指令流水线的冲突,并且分离的指令和数据cache还可以充分利用指令和数据的不同局部性来优化性能。
现代计算机通常设多级cache,按离cpu的远近可各自命名为L1 cache、L2 cache、L3 cache....
离cpu越远,访问速度越慢,容量越大。
指令cache和数据cache的分离一般在L1级,此时通常为回写法+写分配法。
L1对L2使用全写法+非写分配法,L2对内存使用回写法+写分配法(由于L2的访问速度大于内存,所以避免了频繁写导致的write buffer饱和溢出问题)。
虚拟存储器
主存+辅存构成了虚拟存储器,虚拟存储器具有主存的速度和辅存的容量。
虚拟存储器将主存和辅存的地址空间统一编址,形成一个供用户编程的庞大地址空间。
实地址(物理地址)= 主存页号+页内偏移
虚地址(逻辑地址)= 虚存页号+页内偏移
辅存地址 = 磁盘号+盘面号+磁道号+扇区号
虚拟存储器也采用和cache类似的技术,将辅存中经常访问的数据副本存放在内存中。
缺页的代价很大,所以提高命中率是关键,因此虚拟存储机制采用全相联映射,每个虚页面可以存放在对应主存区域的任何一个空闲页位置。此外,在处理一致性问题时,采用回写法(全写法会增加访问辅存次数,访问辅存代价很大)。
页式虚拟存储器
虚存空间和主存空间都被划分成同样大小的页,主存的页称为实页、页框,虚存的页称为虚页。
由页表来实现虚页号到实页号的转换。
- 有效位(装入位):虚页对应的页面是否在主存
- 1:在主存,页表项中存放的是主存页号(物理页号)
- 0:不在,页表项可以存放对应的磁盘地址
- 脏位(修改位):回写法的参照位
- 引用位(使用位):替换策略的参照位
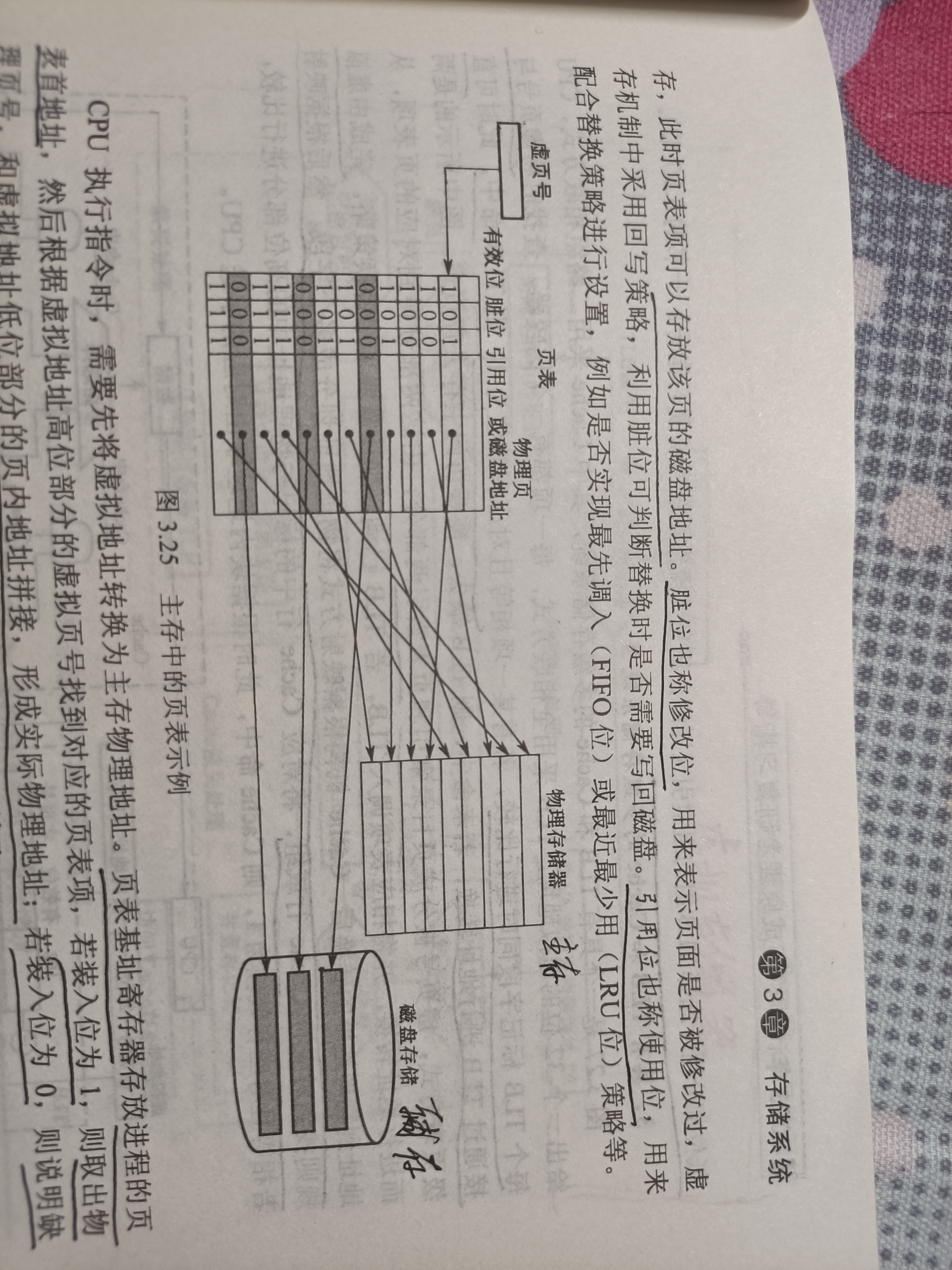
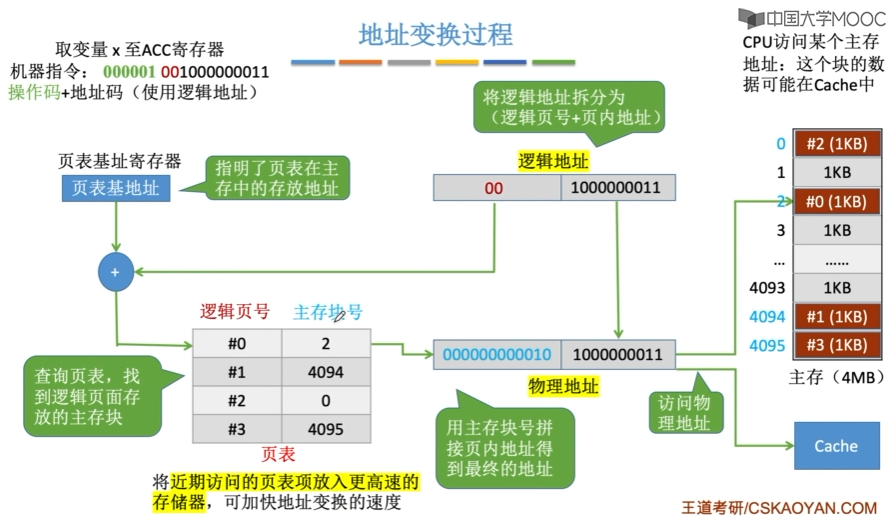
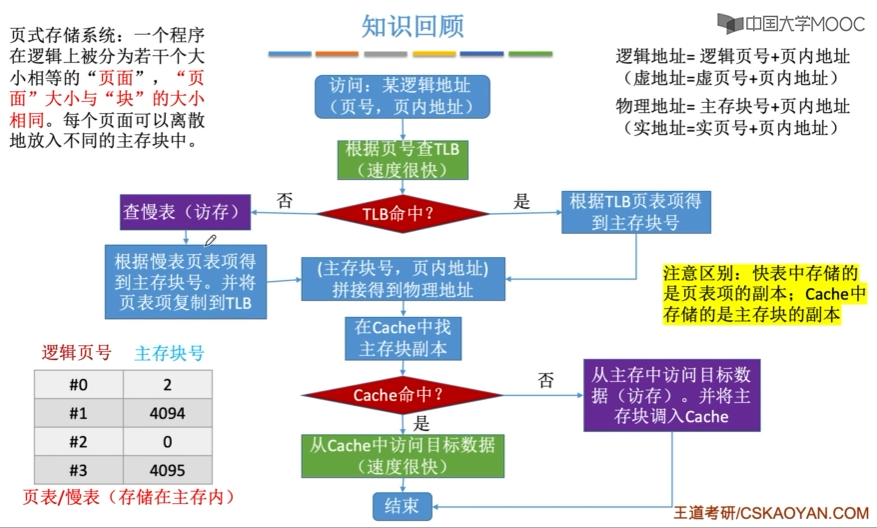
地址变换过程
- CPU给出虚地址
- 用虚地址中的虚拟页号查页表(访存),若缺页,则进入缺页中断
- 获得物理页号,与虚地址中页内偏移拼接形成实地址
- 用实地址去访问内存或cache
虚拟内存技术使得访存之前需要多访问一次或几次内存(多级页表),使得访存效率下降。
因此引入了快表(TLB)。相应地把内存中页表称为慢表(Page)
快表通常采用全相联或组相联方式(命中率高一些)。每个TLB项由页表项内容+TLB标记字段组成。
TLB标记来表示该TLB表项取自于页表中哪个虚页号对应的页表项。因此,TLB标记在全相联方式下就是该页表项对应的虚页号;组相联方式下就是对应虚页号的高位部分(除去组号部分)。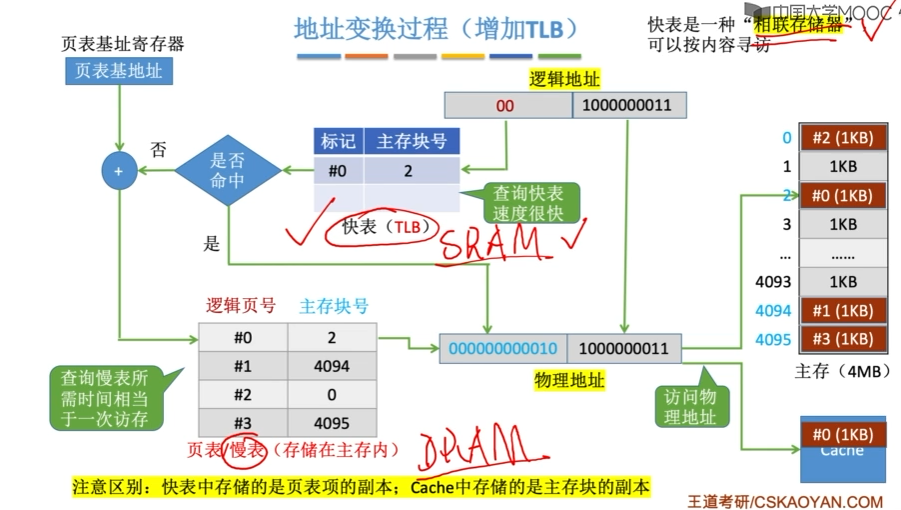
| TLB | Page | Cache | 说明 |
|---|---|---|---|
| 命中 | 命中 | 命中 | TLB命中,Page一定命中,信息就一定在主存,就可能在cache |
| 命中 | 命中 | 缺失 | --------------------------------,信息就一定在主存,也可能不在cache中 |
| 缺失 | 命中 | 命中 | TLB缺失,但Page可能命中,信息一定在主存,就可能在cache |
| 缺失 | 命中 | 缺失 | -----------------------------------,信息一定在主存,也可能不在cache |
| 缺失 | 缺失 | 缺失 | TLB缺失,Page也可能缺失,信息不在主存,就一定不在cache |
TLB缺失由硬件或软件处理;Page缺失由软件处理;Cache缺失由硬件处理。
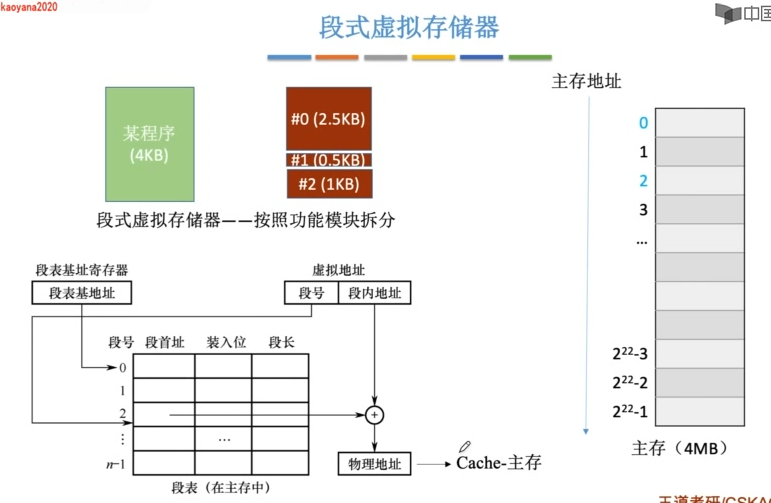
段式虚拟存储器
地址转换过程:
- CPU给出虚地址
- 用虚地址中的虚拟段号查段表(访存),若缺段,则进行缺段中断
- 获得该段在内存中的起始地址,与段内偏移拼接形成实地址
- 用实地址去访问CPU或cache
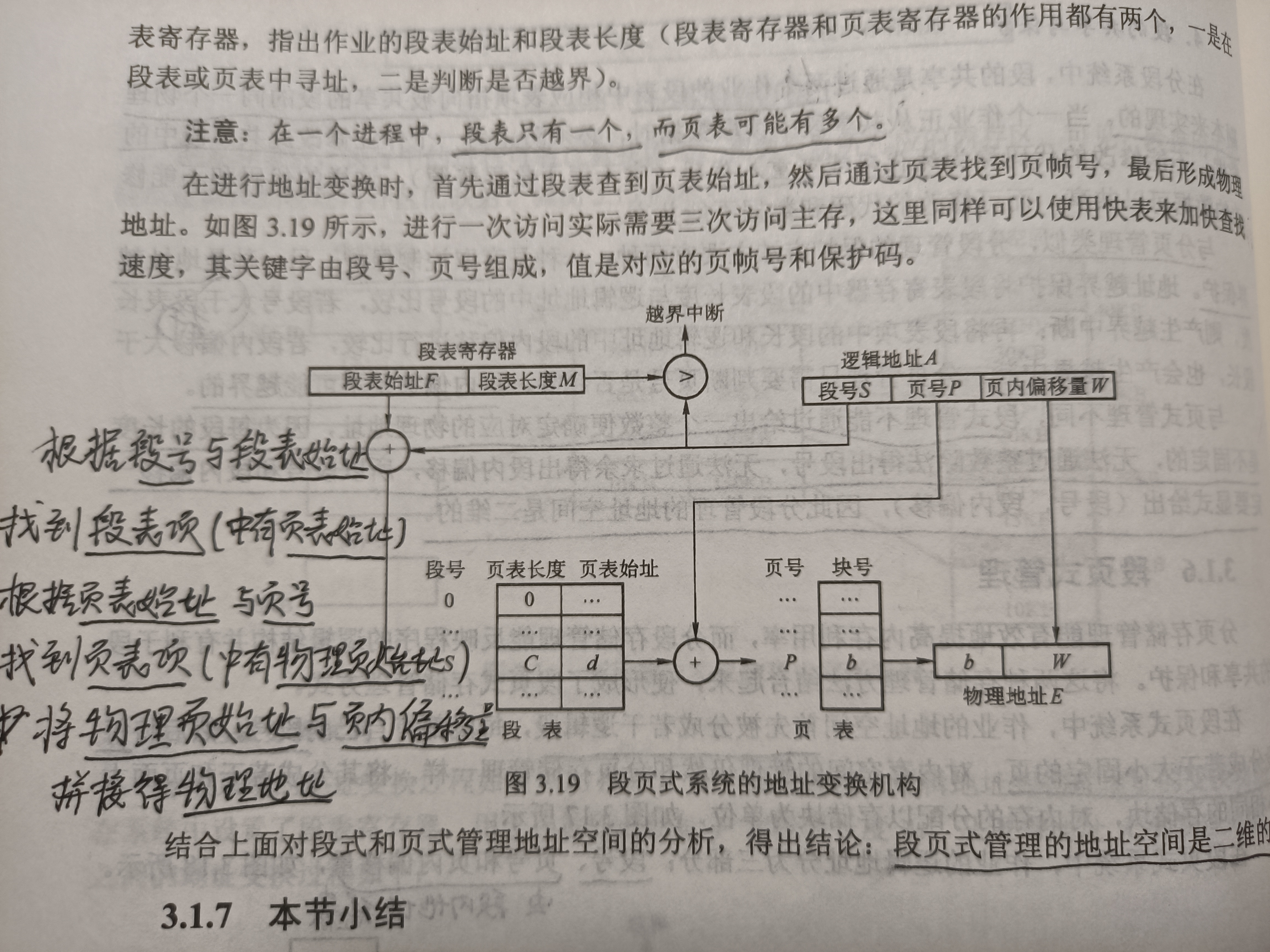
段页式虚拟存储器
虚拟地址分为(段号,段内页号,页内偏移)。其中,(段内页号,页内偏移)又叫做线性地址。
地址转换过程:
- 根据段号查找段表,取得该段的页表的起始地址(段表项代替了页表基址寄存器的功能)。
- 根据页表的起始地址与段内页号查询页表,得到对应的实页号。
- 实页号与页内偏移拼接,得到物理地址。
- 物理地址去访问主存或cache。
虚拟存储器与cache比较
- 相同处
- 最终都是为了提高系统性能,两者都有容量、速度、价格的梯度。
- 都把数据划分为小块,并作为基本的传递单位,虚存系统的信息块更大。
- 都有地址的映射、替换算法、一致性策略等问题。
- 都根据局部性原理,将活跃的数据放在相对高速的部件中。
- 不同处
- cache主要解决系统速度;虚拟存储器主要解决主存容量。
- cache都是由硬件实现,是硬件存储器,对所有程序员透明;虚拟存储器由OS和硬件共同实现,是逻辑存储器,对系统程序员不透明,对应用程序员透明。
- CPU速度约为cache的10倍;主存速度约为辅存的100倍。所以虚拟存储器不命中时代价更大。
- cache不命中时,CPU可以直接访问主存;虚拟存储器不命中时,只能先从辅存调入主存,再由CPU访问。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号