

python爬虫练习——下载梨视频,带进度条
main.py
import requests import random import lib.tools as t import os def main(): try: input_url = input("请输入视频页网址:") contId = input_url.split("_")[1] mrd = random.randint(10,99)/random.randint(100,999) get_url = f"https://www.pearvideo.com/videoStatus.jsp?contId={contId}&mrd={mrd}" header = { "Referer":f"https://www.pearvideo.com/video_{contId}" } r = requests.get(get_url,headers=header) srcUrl = r.json()["videoInfo"]["videos"]["srcUrl"] systemTime = r.json()["systemTime"] srcUrl = srcUrl.replace(systemTime,f"cont-{contId}") file_name = contId + os.path.splitext(srcUrl)[-1] # 取扩展名拼接视频名 print("下载开始:") t.download_file(srcUrl,file_name) print(f"{file_name}下载结束") except Exception: pass if __name__ == "__main__": main()
tools.py
import requests import os import glob import progressbar # 取出中间文本 def getmidstring(html, start_str, end): start = html.find(start_str) if start >= 0: start += len(start_str) end = html.find(end, start) if end >= 0: return html[start:end].strip() # 下载文件 def download(down_url,save_path): reponse = requests.get(down_url) with open(save_path,'wb') as f: f.write(reponse.content) # 下载文件带进度条 def download_file(url, path): with requests.get(url, stream=True) as r: chunk_size = 1024 content_size = float(r.headers[ 'content-length' ]) # 进度条样式 widgets = [ '下载: ', progressbar.Percentage(), # 进度条标题 ' ', progressbar.Bar(marker='>', left='[', right=']', fill=' '), # 进度条填充、边缘字符 ' ', progressbar.Timer(), # 已用的时间 ' ', progressbar.ETA(), # 剩余时间 ' ', progressbar.FileTransferSpeed(),# 下载速度 ] bar = progressbar.ProgressBar(widgets=widgets, max_value=content_size) # 实例化对象 with open(path, "wb") as f: loaded = 0 bar.start() # 调用进度条start方法,在调用update方法 for chunk in r.iter_content(chunk_size=chunk_size): loaded += len(chunk) bar.update(loaded) # 更新进度条状态 f.write(chunk) bar.finish() # 结束进度条 # 读文件内容 def read_infotxt(file_name): f = open(file_name) info = f.read() f.close() return info # 把内容写入文本文件 def write_txt(file_name,txt_content): with open(file_name,"wb") as f: f.write(txt_content.encode("gbk")) # 创建文件夹 # 遇到重复文件夹命名为文件夹目录_1(2,3,4……) # 返回文件夹目录名称 def mkdir(path,root_flag=False): folder = os.path.exists(path) floder_path = path if not folder: os.makedirs(path) else: if not root_flag: num_p = 1 sub_path = glob.glob(path + '*') if sub_path: # 最后一个创建目录 last_path = sub_path[-1] floder_path = last_path + '_{}'.format(num_p) if last_path.find('_') > 0: num_str = last_path.split('_') if num_str[-1].isdigit(): num_p = int(num_str[-1]) + 1 floder_path = last_path[0:last_path.rfind( '_')] + '_{}'.format(num_p) os.makedirs(floder_path) else: os.makedirs(floder_path) else: os.makedirs(floder_path) return floder_path
结果:
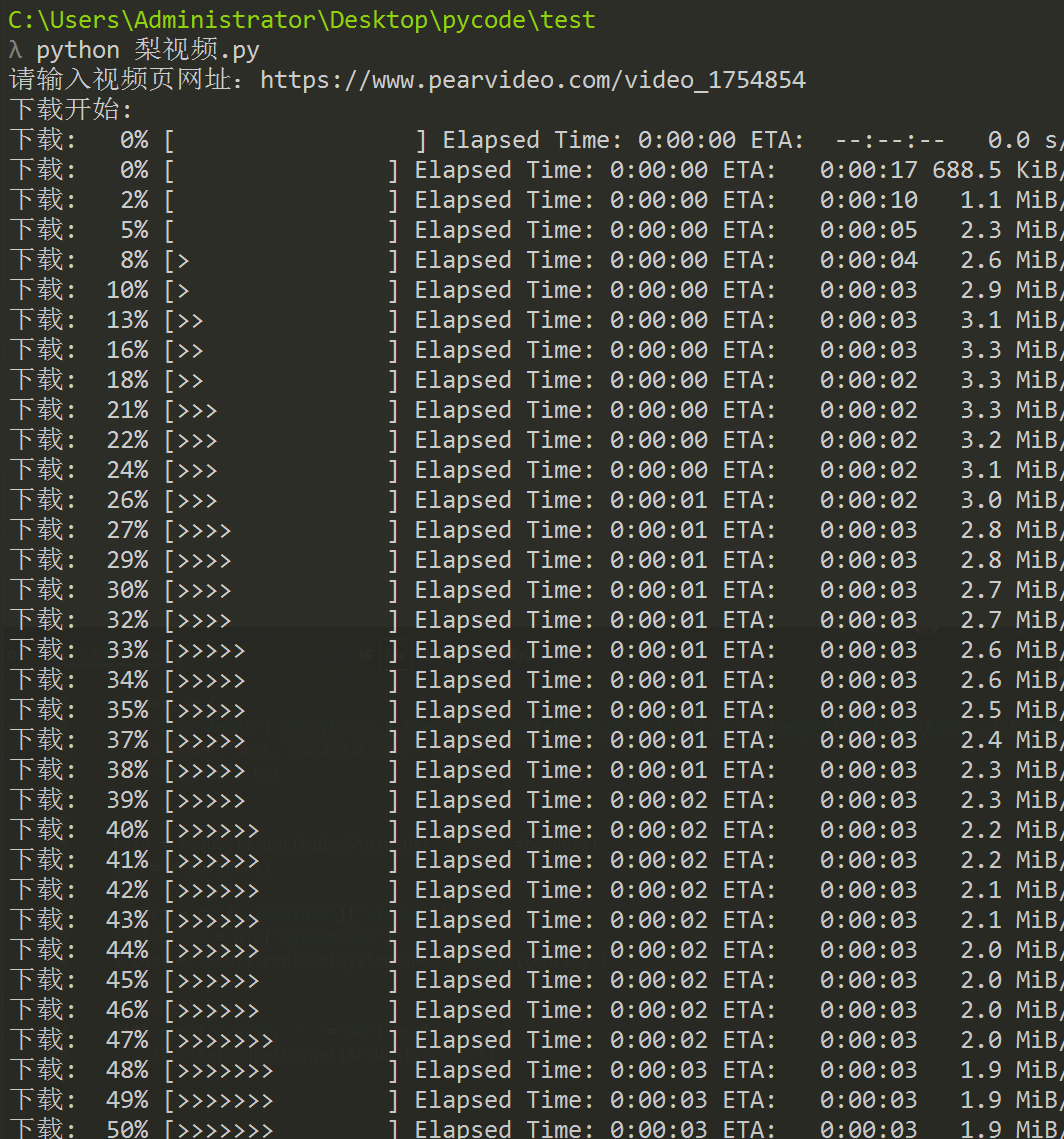
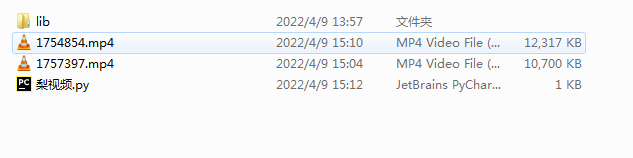

 浙公网安备 33010602011771号
浙公网安备 33010602011771号