pandas基础(附思维导图)
- 2016-6-7:第一次学习。
- 2016-8-24:第二次学习,添加思维导图。

pandas 两个主要数据结构:Series 和 DataFrame。(建议引入本地)
- 类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成
- 通过Series 的 values 和 index 属性获取其数组表示形式和索引对象
- 可以为数据指定索引,通过索引的方式选取Series中的单个或一组值
- NumPy数组运算(如根据布尔型数组进行过滤、标量乘法、应用数学函数等)都会保留索引和值之间的链接
- 可以将Series看成是一个定长的有序字典,因为它是索引值到数据值的一个映射
- 可以直接通过字典来创建Series
- Series的索引可以通过赋值的方式(列表)就地修改
- Series对象本身及其索引都有一个name属性,可直接赋值修改
DataFrame:
- 表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)。
- 构建DataFrame,最常用的一种是直接传入一个由等长列表或NumPy数组组成的字典。
- DataFrame会自动加上索引(跟Series一样),且全部列会被有序排列。(如果指定了列序列,则DataFrame的列就会按照指定顺序进行排列)
- 跟Series一样,如果传入的列在数据中找不到,就会产生NA值。
- 通过类似字典标记的方式或属性的方式获取列
- 赋值给列:将列表或数组赋值给某个列时,其长度必须跟DataFrame的长度相匹配。如果赋值的是一个Series,就会精确匹配DataFrame的索引,所有的空位都将被填上缺失值
- 为不存在的列赋值会创建出一个新列。
- 关键字del用于删除列。
- 通过索引方式返回的列只是相应数据的视图而已,并不是副本。(通过Series的copy方法即可显式地复制列)
- 传入嵌套字典:外层字典的键作为列,内层键则作为行索引
- 可以设置DataFrame的 index 和 columns 的 name 属性

pandas的索引对象:
- 轴标签和其他元数据(比如轴名称等)
- Index对象是不可修改的,这样才能使Index对象在多个数据结构之间安全共享
- 本质是一个由Python对象组成的Numpy数组

Series 和 DataFrame 中的数据的基本功能:
- 重新索引(reindex):
- 创建一个适应新索引的新对象,将会根据新索引进行重排。如果某个索引值当前不存在,就引入缺失值
- 对于时间序列这样的有序数据,重新索引时可能需要做一些插值处理。method选项:ffill / pad可以实现前向值填充;bfill / backfill 实现后向填充
- 对于DataFrame,reindex可以修改(行)索引、列,或两个都修改。(如果仅传入一个序列,则会重新索引行;使用columns关键字即可重新索引列)
- 插值则只能按行应用(即轴0
- 利用ix的标签索引功能,重新索引任务可以变得更简洁
![]()
- 丢弃指定轴上的项(drop):
- drop方法返回的是一个在指定轴上删除了指定值的新对象
- 对于DataFrame,可以删除任意轴上的索引值(轴1需加上参数:axis=1)
- 索引、选取和过滤:
- Series索引(obj[...])可以是标签或整数。
- 利用标签的切片运算其末端是包含的。(整数则不包含末端)
- 对DataFrame进行索引其实就是获取一个或多个列(用列标签) data[['three', 'one']]
- DataFrame选取行要通过切片或者布尔型数组或者索引字段ix
![]()
![]()
- 算术运算和数据对齐:
- 在将对象相加时,如果存在不同的索引对,则结果的索引就是该索引对的并集。自动的数据对齐操作在不重叠的索引处引入了NA值。缺失值会在算术运算过程中传播。
- 在算术方法中填充值:
- 在对不同索引的对象进行算术运算时,当一个对象中某个轴标签在另一个对象中找不到时填充一个特殊值(比如0)
- add,加法;sub,减法;div,除法;mul,乘法
df1 = DataFrame(np.arange(12.).reshape((3, 4)), columns=list('abcd'))df2 = DataFrame(np.arange(20.).reshape((4, 5)), columns=list('abcde'))# 使用df1的add方法,传入df2以及一个fill_value参数df1.add(df2, fill_value=0)# 重新索引时,也可以指定一个填充值- DataFrame和Series之间的运算:
- 默认情况下,DataFrame和Series之间的算术运算会将Series的索引匹配到DataFrame的列,然后沿着行一直向下广播。
- 如果某个索引值在DataFrame的列或Series的索引中找不到,则参与运算的两个对象就会被重新索引以形成并集。
- 如果你希望匹配行且在列上广播,则必须使用算术运算方法。(传入的轴号就是希望匹配的轴)
series3 = frame['d']frame.sub(series3, axis=0)
- 函数应用和映射:
- NumPy的ufuncs(元素级数组方法)可用于操作pandas对象(如np.abs)
- DataFrame的apply方法:将函数应用到由各列或行所形成的一维数组上
- 许多最为常见的数组统计功能都被实现成DataFrame的方法(如sum和mean),因此无需使用apply方法
- 除标量值外,传递给apply的函数还可以返回由多个值组成的Series
- applymap方法:对frame中各个值格式化字符串(Series有一个用于应用元素级函数的map方法)
- 排序和排名:
- sort_index方法:对行或列索引进行排序(按字典顺序);对于DataFrame,可以根据任意一个轴上的索引进行排序(axis=1);数据默认是按升序排序的,但也可以降序排序(ascending=False)
- order方法:按值对Series进行排序;在排序时,任何缺失值默认都会被放到Series的末尾
- sort_values方法:对于DataFrame,将一个或多个列的名字(组成列表)传递给by选项,可以根据一个或多个列中的值进行排序
- rank方法:适用于Series和DataFrame;
![]()
- 带有重复值的轴索引:
- is_unique属性:查看索引的值是否是唯一
- 对于带有重复值的索引,数据选取的行为将会有些不同。如果某个索引对应多个值,则返回一个Series;而对应单个值的,则返回一个标量值。
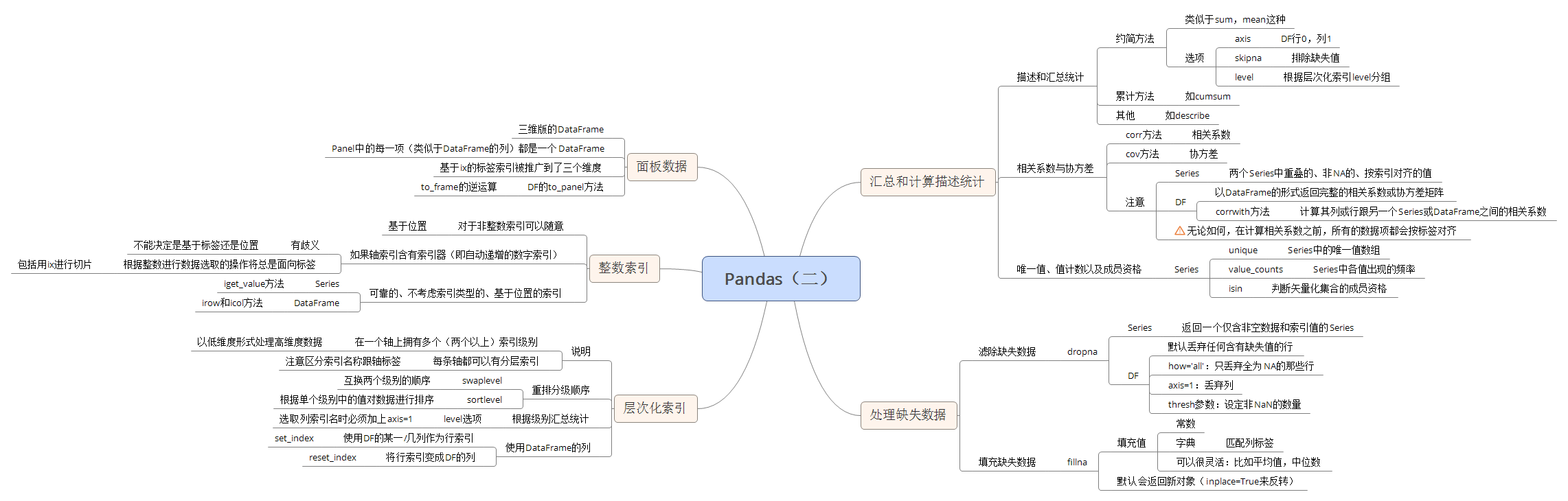
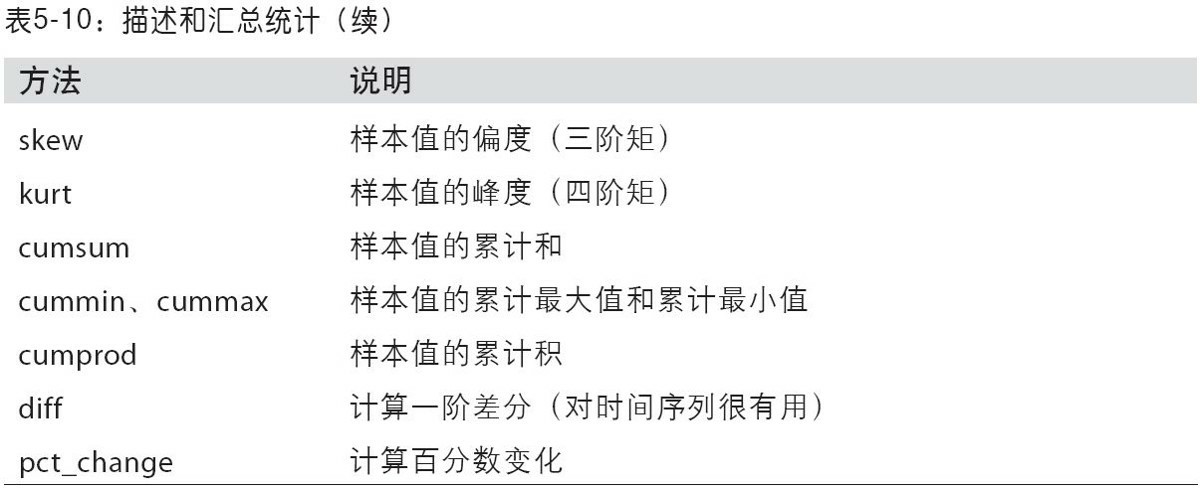
- 汇总和计算描述统计:
![]()
![]()
![]()
- 相关系数与协方差:
- Series的 corr 方法用于计算两个Series中重叠的、非NA的、按索引对齐的值的相关系数。与此类似,cov用于计算协方差。
- DataFrame的corrwith方法,可以计算其列或行跟另一个Series或DataFrame之间的相关系数:
- 传入一个Series将会返回一个相关系数值Series(针对各列进行计算)
- 传入一个DataFrame则会计算按列名配对的相关系数
- 唯一值、值计数以及成员资格:
![]()
- 处理缺失数据:
- pandas使用浮点值NaN(Not a Number)表示浮点和非浮点数组中的缺失数据。
- Python内置的None值也会被当做NA处理
![]()
- 滤除缺失数据:
- 对于一个Series:
- dropna返回一个仅含非空数据和索引值的Series
- 通过布尔型索引
- 对于DataFrame:
- dropna默认丢弃任何含有缺失值的行
- 传入how='all'将只丢弃全为NA的那些行
- 要用这种方式丢弃列,只需传入axis=1即可
- thresh参数:留下一部分观测数据,thresh为非NaN值的最少个数
- 填充缺失数据:
- fillna方法:
- 通过一个常数调用就会将缺失值替换为那个常数值
- 通过一个字典调用fillna,就可以实现对不同的列填充不同的值(键名对应列标签)
- fillna默认会返回新对象,但也可以对现有对象进行就地修改:参数 inplace=True
- 对reindex有效的那些插值方法也可用于fillna(如method='ffill')
- 通过函数调用fillna可以实现很多功能,比如说,你可以传入Series的平均值或中位数
![]()
![]()
- 层次化索引:
- 能在一个轴上拥有多个(两个以上)索引级别。抽象点说,它使你能以低维度形式处理高维度数据。
- 选取数据子集:
data = Series(np.random.randn(10),index=[['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c', 'd', 'd'],[1, 2, 3, 1, 2, 3, 1, 2, 2, 3]])data['b']data['b':'c']data.ix[['b', 'd']]# 在“内层”中进行选取,a,b,c,d各层下的'2'标签data[:, 2]
- 重排分级顺序:
- swaplevel接受两个级别编号或名称,并返回一个互换了级别的新对象(但数据不会发生变化)
- sortlevel则根据单个级别中的值对数据进行排序(稳定的)。交换级别时,常常也会用到sortlevel,这样最终结果就是有序的了。
- 在层次化索引的对象上,如果索引是按字典方式从外到内排序(即调用sortlevel(0)或sort_index()的结果),数据选取操作的性能要好很多。
- 根据级别汇总统计:
- 许多对DataFrame和Series的描述和汇总统计都有一个level选项,它用于指定在某条轴上求和的级别。
- 使用DataFrame的列:
- set_index:将DataFrame的一个或多个列转化成行索引
- reset_index:层次化索引的级别会被转移到列里面
- 整数索引:
- 如果你的轴索引含有索引器,那么根据整数进行数据选取的操作将总是面向标签的。这也包括用ix进行切片
- 如果你需要可靠的、不考虑索引类型的、基于位置的索引,可以使用iloc方法
- 面板数据:
- 三维版的DataFrame
- Panel中的每一项(类似于DataFrame的列)都是一个DataFrame










你好,这里是woaielf的博客。
我是编程爱好者,医学生,梦想职业是数据分析师,正在努力转型。
欢迎阅读,敬请批评指正。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号