NumPy基础(附思维导图)
- 2016-6-3:第一次学习。
- 2016-8-23:第二次学习,添加思维导图。
- 用于数据整理和清理、子集构造和过滤、转换等快速的矢量化数组运算。
- 常用的数组算法,如排序、唯一化、集合运算等。
- 高效的描述统计和数据聚合/摘要运算。
- 用于异构数据集的合并/连接运算的数据对齐和关系型数据运算。
- 将条件逻辑表述为数组表达式(而不是带有if-elif-else分支的循环)。
- 数据的分组运算(聚合、转换、函数应用等)。
由于NumPy关注的是数值计算,因此,如果没有特别指定,数据类型基本都是float64(浮点数)。
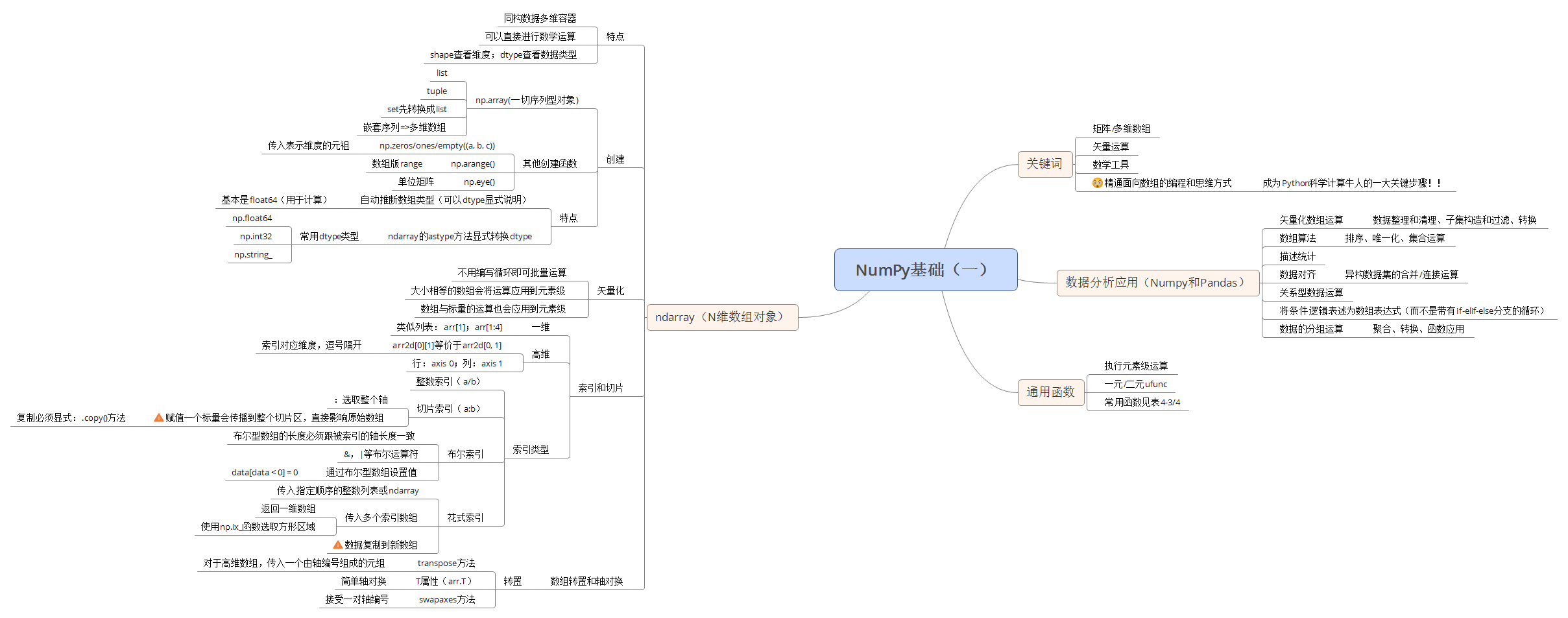
ndarray:一种多维数组对象。每个对象数组都有一个shape(一个表示各维度大小的元组)和一个dtype(一个用于说明数组数据类型的对象)。
- 同构数据多维容器(所有元素必须是相同类型的)
- 精通面向数组的编程和思维方式是成为Python科学计算牛人的一大关键步骤
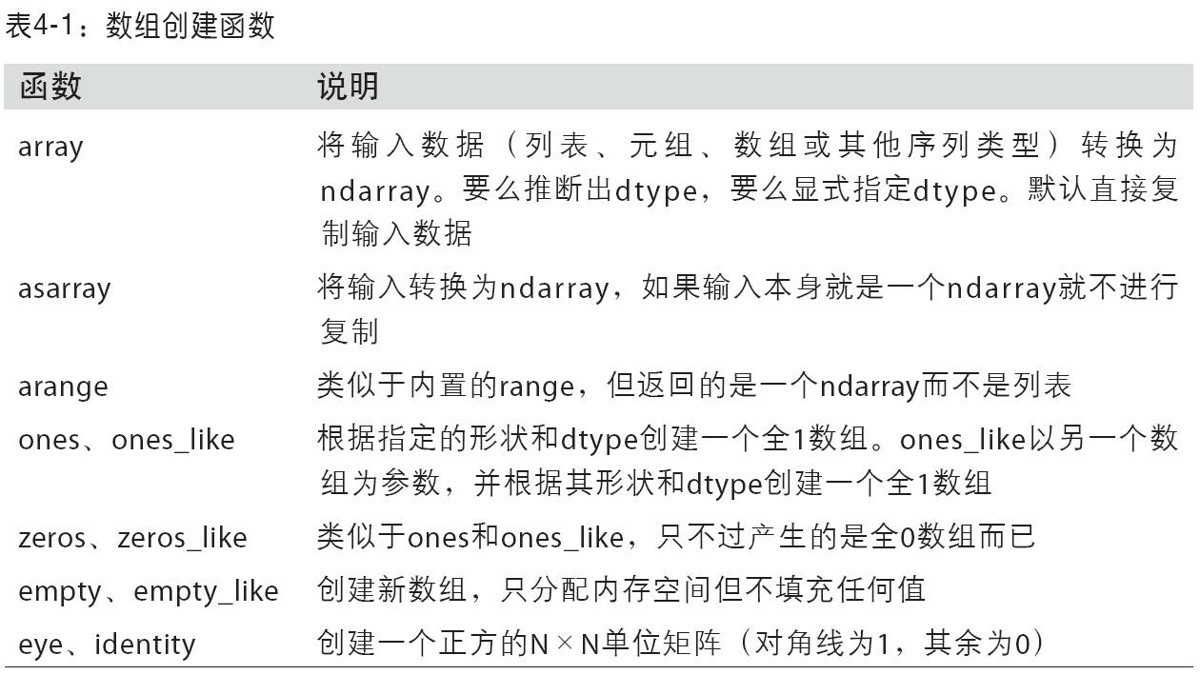
- 创建ndarray:array函数(接受一切序列型的对象);嵌套序列(比如由一组等长列表组成的列表)将会被转换为一个多维数组
- zeros,ones,empty创建数组,传入指定形状(各维度的值)即可。
- arange是Python内置函数range的数组版
- 可以通过ndarray的astype方法显式地转换其dtype。
- 矢量化:大小相等的数组之间的任何算术运算都会将运算应用到元素级。数组与标量的算术运算也会将那个标量值传播到各个元素。
索引和切片:
- 跟列表最重要的区别在于,数组切片是原始数组的视图。这意味着数据不会被复制,视图上的任何修改都会直接反映到源数组上。如果你想要得到的是ndarray切片的一份副本而非视图,就需要显式地进行复制操作,例如arr[5:8].copy()。
- 二维数组:【行索引,列索引】 array[0][2] 等价于 array[0, 2]
- 通过布尔型索引选取数组中的数据,将总是创建数据的副本,即使返回一模一样的数组也是如此。(Python关键字and和or在布尔型数组中无效,需使用&(和)、|(或)之类的布尔算术运算符)
- 花式索引:利用整数数组进行索引。花式索引跟切片不一样,它总是将数据复制到新数组中。arr[[1, 5, 7, 2], [0, 3, 1, 2]]最终选出的是元素(1,0)、(5,3)、(7,1)和(2,2);用于选取方形区域的索引器实际上是arr[[1, 5, 7, 2]][:, [0, 3, 1, 2]]或者arr[np.ix_([1, 5, 7, 2], [0, 3, 1, 2])]
数组转置和轴对换:
- 简单的转置可以使用.T,它其实就是进行轴对换而已。
- 对于高维数组,transpose需要得到一个由轴编号组成的元组才能对这些轴进行转置。(按照元祖给出的顺序重新排维度)
- swapaxes方法接受一对轴编号:此两个维度调转





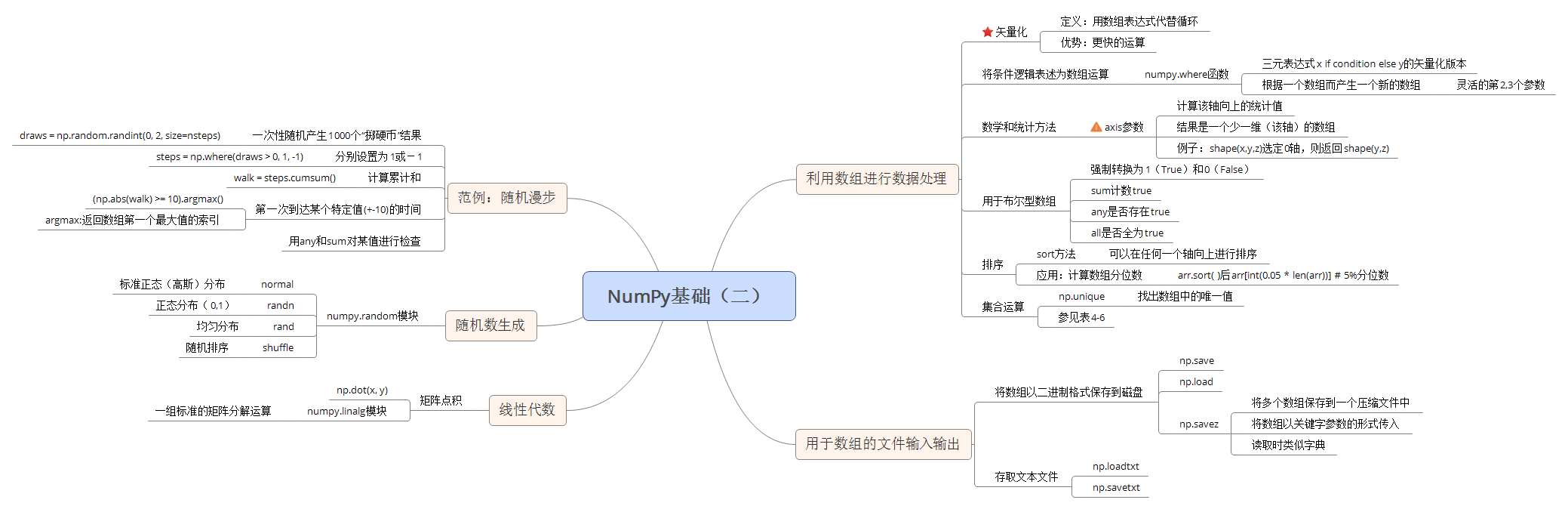
NumPy数组使你可以将许多种数据处理任务表述为简洁的数组表达式(否则需要编写循环)。用数组表达式代替循环的做法,通常被称为矢量化。
将条件逻辑表述为数组运算:
- np.where
# python版本:result = []for i in range(n):if cond1[i] and cond2[i]:result.append(0)elif cond1[i]:result.append(1)elif cond2[i]:result.append(2)else:result.append(3)# np.where版本:np.where(cond1 & cond2, 0,np.where(cond1, 1,np.where(cond2, 2, 3)))# 算数版本:result = 1 * cond1 + 2 * cond2 + 3 * -(cond1 | cond2)
数学和统计方法:
可以通过数组上的一组数学函数对整个数组或某个轴向的数据进行统计计算。


用于布尔型数组的方法:
sum 经常被用来对布尔型数组中的True值计数;
any 用于测试数组中是否存在一个或多个True;
all 则检查数组中所有值是否都是True:
arr = randn(100)(arr > 0).sum() # Number of positive valuesbools = np.array([False, False, True, False])bools.any()bools.all()
排序:
- 通过sort方法
- 多维数组可以在任何一个轴向上进行排序,只需将轴编号传给sort即可
- 顶级方法np.sort返回的是数组的已排序副本,而就地排序则会修改数组本身。
arr = randn(5, 3)# 就地排序arr.sort(1)arr.sort(0)# 顶级排序sorted_arr = np.sort(arr)
- 计算数组分位数最简单的办法是对其进行排序,然后选取特定位置的值:
large_arr = randn(1000)large_arr.sort()large_arr[int(0.05 * len(large_arr))] # 5% quantile
唯一化以及其他的集合逻辑:
- np.unique 用于找出数组中的唯一值并返回已排序的结果
- np.in1d用于测试一个数组中的值在另一个数组中的成员资格,返回一个布尔型数组:
values = np.array([6, 0, 0, 3, 2, 5, 6])np.in1d(values, [2, 3, 6])

将数组以二进制格式保存到磁盘:
- np.save和np.load是读写磁盘数组数据的两个主要函数。(扩展名为.npy)
- np.savez可以将多个数组保存到一个压缩文件中。(扩展名为.npz)
存取文本文件:(更关注pandas中的read_csv和read_table函数)
- np.loadtxt 或更为专门化的 np.genfromtxt (面向的是结构化数组和缺失数据处理)将数据加载到普通的NumPy数组中。
- np.savetxt
线性代数(如矩阵乘法、矩阵分解、行列式以及其他方阵数学等):
- dot 函数:矩阵乘法
x = np.array([[1., 2., 3.], [4., 5., 6.]])y = np.array([[6., 23.], [-1, 7], [8, 9]])x.dot(y) # equivalently np.dot(x, y)

随机数生成:
numpy.random模块:更高效。


你好,这里是woaielf的博客。
我是编程爱好者,医学生,梦想职业是数据分析师,正在努力转型。
欢迎阅读,敬请批评指正。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号