Kubernetes简介
Kubernetes是Google开源的一款容器编排工具,它是诞生在Google内部运行N多年的博格系统之上的产物,因此其成熟度从其诞生初期就广泛受到业界的关注,并且迅速成为编排工具市场的主流,其社区活跃度非常高,版本迭代速度也很惊人,它的主要作用是对Docker容器做编排工作,当然,Docker只是容器工具的一种引擎,K8s可支持多种容器引擎,但从目前来说Docker容器引擎是具有绝对优势的,容器需要编排,也很容易理解,因为我们最核心要跑到业务通常都是LNMT/P的不同形式的扩展,但NMT/P他们的运行是有先后顺序的,也就是说MySQL要先启动,然后是Tomcat或PHP,最后是Nginx,而控制这种顺序就需要有容器编排工具来帮我们实现,另外,我们的业务希望7x24小时在线,如何保障?靠人是很难做到实时的,但编排工具可以,K8s帮我们实现了很多控制器,这控制器可以帮我们监控容器运行的状态,并自动帮我们重建(在容器时代重启就是重建)容器,并且还可以在容器处理能力不足时,自动根据我们定义的扩展规则,自动创建新Pod(k8s中最小单元,每个Pod中可有一个或多个容器),并且在压力下去后,自动删除Pod等等功能。
另外这里是K8s的中文官方文档zh站点:
https://k8smeetup.github.io/docs/
Kubernetes:
它至少需要3个Master节点
Master节点的主要组件:
API Server: 主要用来接收其它组件发来的请求,并作出相应的处理.
Scheduler: 主要负责挑选出一个最佳node节点来运行pod,它挑选合适的node,通常分两个阶段,
第一个阶段:是先通过初步筛选, 根据运行pod的最大要求,如: 4G内存, 6颗CPU等需求,来做
初步筛选,假如从20台中选出了3台, 则进入第二阶段,在从这3台中选出一台最符合的节点,
这时就需要综合考量各种因素,最后将选出了一台最佳运行节点告诉给API Server,在由
Master节点负责调度Pod在该node节点上运行起来。
Controller:它是负责监控Node上运行的Pod是否正常工作,若它发现自己监控的某个Pod故障了,
它会向API Server发出通告,并要求Master在其它节点上再重新启动一个相同的Pod,
然后将故障的Pod Kill掉。
Controller-Manager:它是负责监控所有Controller是否正常工作的,在Kubernetes集群中,有很多
个功能各异的Controller, 监控Pod健康状态的Controller只是其中之一,Controller-Manager
它用于监控这些Controller工作状态的,一旦Controller故障,它将重启一个新的Controller来
代替它工作。
但是若Controller-Manager故障怎么办? 其实Master在创建时,要求最少要有3个节点,每个节点都会启动一个Controller-Manager,启动一个为主Controller-Manager,其它两个或多个为备用的Controller-Manager,一旦主Controller-Manager故障,则备用的Controller-Manager将代替它继续工作。
Node0:
Pod:它是Kubernetes中最基本的单元,一个Pod其实是一个容器的抽象,或叫容器的壳,它内部
其实就是一个或多个容器。一个容器中只能运行一个应用程序,所以有时一个应用程序需要
强依赖另一个应用程序一起工作,如:ELK中要收集每个应用的日志,它就需要在每个应用
节点上部署自己的日志收集器,如Logstash, 那么对于Nginx,它的日志要放入ELK中,它就需要
和Logstash放到一起,但一个容器中只能运行一个应用程序,所以就需要在一个Pod中运行
两个容器,来完成这个需求,所以在K8s系统中,将一个Pod做为一个整体,一个基本原子来管理。
Label Selector:在一个Kubernetes集群中,需要管理的Pod有很多,它们被调度到不同的Node节点上
运行,这么多Pod运行在不同的Node节点上,怎么对它们做管理? 通过字符串名称?那么一个
Pod运行过程中故障,又被重启到其它Node上,那么它的字符串名称必然要改变,那么这又怎么
能唯一标示一个Pod? 所以这就需要用到Label Selector(标签选择器),实际上,Pod在K8s系统
中它们都有一类标签,如:将运行Nginx的Pod都打一个App=Nginx的标签,将运行HAProxy的Pod
都打上App=HAProxy,等等...那么在查找所有运行Nginx的Pod时,就可以通过标签选择器,通过
条件App, 并且其值为Nginx来查询,就可以将所有是App=Nginx的Pod都标记出来,进行管理操作了。
Kubelet:它运行在Node上,接受APIServer发来的启动,停止或删除Pod请求,并按照请求,在Node实际执行
操作的守护进程。
Docker: 是实际Pod的运行环境提供者.
Pod:
自主式Pod: 它也是向API Server发请求,APIServer再通过Scheduler选择最佳Node节点,最后有kubelet在
docker环境中创建Pod,但是一旦Node节点宕机,则该Pod将消失。因此不建议实行这种方式。
控制器管理的Pod:
控制器又分为以下几个:
1. ReplicationController(副本控制器): 它是早期的Pod管理器,它负责接收用户请求,来创建精确指定数量的Pod,
如用户请求创建2个Nginx Pod,它会自动向API Server发请求,API Server在让Scheduler选择
最佳创建的Node节点,来创建两个Pod,假如当前创建的一个Pod在Node3上, 结果Node3运行
一段时间后宕机了,这时ReplicationController会发现副本数量不够了,它会再次请求API Server
由它控制这Scheduler重新选择一个最佳Node节点,来重新创建一个Pod,这样就能保证Pod 的
数量始终能够达到用户期望的个数。
它还支持滚动更新:简单说就是假如现在我们的镜像升级了,需要用新版镜像来启动Pod,
这时副本控制器会请求API Server使用新的镜像来创建Pod, API依然是调度Scheduler,
选择最佳节点,kubelet根据最新镜像创建新Pod,这时Pod有三个,副本控制器此时会将
旧的Pod 删除,然后再请求API Server创建新Pod,最后,再将旧Pod删除,这样就完成滚动
更新了,当然它还支持回滚操作。
以下为新版本的控制器:
2.ReplicaSet:副本集控制器
Deployment: ReplicaSet不直接使用,一般使用Deployment来管理无状态的应用。
HPA(HorizontalPodAutoscaler: 水平Pod自动伸缩控制器):
在实际工作中当我们定义了一组Pod, 假如说为2个Pod,平时它们都能应付用户较小规模的访问量,但
某一时刻用户访问量突然增加, 2个Pod不足以应付,这时HPA控制,还能自己根据定义,如两个Pod的CPU使用
率要控制在60%左右,HPA经过计算,若有满足CPU利用率高于60%,需要再增加2个Pod,则它将自动再创建
两个Pod来承载用户访问流量,当访问量下去了,4个Pod的CPU使用率都很低,则HPA将自动销毁多余的2个Pod.
3. StatefulSet:有状态副本集控制器
4. DaemonSet: 若需要在一个特定的Node节点上运行一个Pod时,需要使用它。
5. Job:它用于定义一个仅需要运行一次作业的Pod, 如: 我们需要启动一个Pod来负责清理垃圾,就可以定义一个
job,若job执行完成Pod退出,这是正常期望,若Pod运行过程中故障退出,但清理工作没有完成,则Job将会再
次请求创建新的Pod来完成剩余的清理工作。
Ctonjob: 运行周期性作业.
这些控制器都是为了完成用户期望的运行方式,而产生的。
服务自动发现:
问题: 作为容器的Pod是为客户端提供某种服务的,如Nginx等, 但是Pod在运行过程中不可避免的会出问题,因此
就需要将有问题的Pod销毁,在创建新的Pod,而新Pod的主机名和IP都将改变,那前端的客户端要如何正常
访问到这些提供服务的Pod?
K8s中的解决方案:
提供一个自动发现服务,它对于前端的客户端来说,它是一个代理,对于后端Pod来说,它是调度器,自动发现服务是怎么工作的? 它实际上是借助于Label Selector,自动发现服务先将自己管理的Pod标签,交给Label Selector,它会找到所有包含此标签的Pod,然后自动发现服务,再去探测找到的每个Pod的IP和端口,并将它们作为自己可调度的服务Pod。
那自动发现服务其本质是什么? 它实际上是一个ipvs规则, 早期使用的是iptables的目标端口映射规则,但其负载均衡能力太差,在新版的k8s中就改用ipvs的NAT规则了。但需要注意 无论是iptables的DNAT规则,还是ipvs的NAT规则,它们面向客户端都有一个地址, 即客户端访问这个地址时,iptables会将去往这个地址的流量做DNAT,转换为其后端的Pod的IP和端口, ipvs也一样,它也是将访问该地址的流量转换为后端Pod的IP和端口, 那么这个地址就是前端客户端需要明确知道的,而且它是固定的;但是这些地址是ping不通的!但它们可被解析,因为这些地址仅作为规则使用,没有配置在任何接口上,也就意味者它们没有TCP/IP协议栈的支持。
另外,客户端访问这些Service(即自动发现服务)是通过名称访问的,而解析这些名称的DNS是K8s中的基础服务!这些DNS被称为AddOns(附件)类组件。
K8s系统的主要组件示意图:
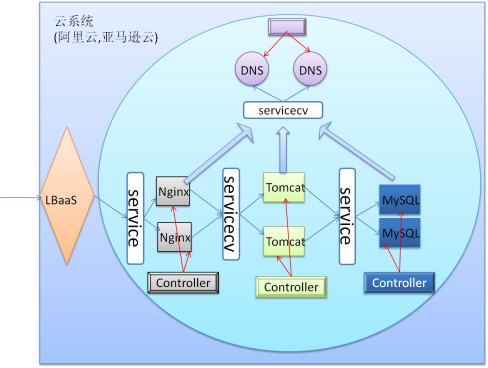
注:
Service: 就是自动发现服务
Controller:是用于控制Pod的生存周期的,每个Controller只负责控制一部分Pod,一旦Pod出故障,它将自动请求APIServer在创建新的Pod替换故障Pod.
Pod: 如Nginx、Tomcat等Pod,它们要访问其它Pod,都需要知道该Pod的前端代理(Service)是谁,所以在配置时,需要明确告诉它们,如:Nginx要代理用户请求至Tomcat,它需要知道Tomcat的前端Service的域名,而这个域名是事先告知Nginx的,这是固定的,Nginx会先去访问DNS的Serivce,获取域名的解析地址后,在去访问Tomcat的前端Service。Tomcat访问后端MySQL也一样。因此DNS服务是K8s中的基础服务,必须要有。
注: 若service的域名和IP若发生改变,DNS会自动触发修改相应的A记录。
在K8s系统中:
需要手动创建的组件有: serivce, controller
另外: K8s系统若部署在机房中,那么它就必须有一组边缘物理主机上配置公网IP,以便能接入外部流量进来。
当然,也可以在K8s外部单独部署调度器,由调度器将流量发到K8s内网中。但这时调度器将不在K8s的可管理范围了,所以图中给出的是,K8s运行在云系统上的情况,使用这些云系统中的LBaaS,来创建虚拟调度器,这样K8s就可以调用底层云的API来管理这些虚拟调度器了。
K8s的三种网络模型:
1. 一个Pod内多个容器时,它们之间的通信,靠本地环回(lo)
2. Pod间通信要通过service来完成.
在Docker中,容器之间通信要借助两次NAT转换才行,即NodeA上的容器要访问NodeB上的容器,它们是先将请求发给网关(通常是docker0桥),然后docker0在将流量转发出去前,要先做一次SNAT,接着到达NodeB后,还需要做DNAT,才能进入NodeB中的容器中,实现容器间通信。但在K8s中,这就太麻烦了,而且也会让通信变动更混乱,因为NodeA上的容器根本不知道访问的NodeB上的容器节点是谁,所以就变成这样:Pod将请求发给网关(docker0),docker0与物理网卡是桥接,当docker0要向目标发请求时,它通过查询本地的iptables规则 或 ipvs规则得知目标的地址,因此将流量转发给目标,目标收到请求后,做出响应,返回给它的前端service,service在将请求代理给本地Pod.简单示意图:
NodeA【Pod--->docker0-->Service--->】-------------->NodeB【--->docker0--->Pod】
3. Service成为访问的关键了,但service它只是规则,它怎么能自动监控Pod的改变? 它怎么会出现在所有Node上?所以这里还有一个在Node上的守护进程,kube-proxy
kube-proxy: 它是用于管理Service的,用户手动创建service后,后续的管理都有kube-proxy来完成。
它会自动监控着service后端的Pod是否发生改变,若发生改变,它会立即通知API Server,
API Server收到通知后,它会将这个消息通告给所有关联的订阅者,如 kube-proxy, 每个Node上
的kube-proxy收到这个通告消息后,它们会自动将这个消息反映在本地的iptables 或 ipvs规则中。
API Server: 它会接收K8s集群中所有动态变化的信息,所有变化都要先通知API Server,那API Server的数据存储在哪里?为了避免API Server故障导致数据丢失,这些数据又需要存放在一个共享存储中.这个共享存储就是etcd.
注:etcd: 它是一个Key-Value存储的数据库,类似于Redis,但它功能更强大,它支持更多协调机制.
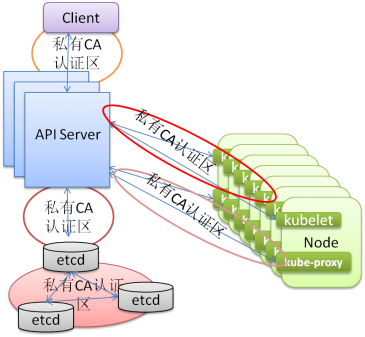
注:
API Server和etcd直接使用HTTP协议通信
API Server和其Client也是HTTP协议通信
API Server与kubelet 和 kube-proxy的通信也是HTTP协议.
为了避免数据被盗取,必须在它们之间都启用CA认证机制,即使用HTTPS协议.
基于以上所有基础,现在将其简略如下图:
这就是K8s的三种网络模型.

注:
此图中显示的三种网络:
节点网络: 是构建K8s集群时,我们自行需要构建的物理网络.
Service网络 和 Pod网络则需要通过CNI(容器网络接口)来引入第三方网络插件来实现.
因为K8s并没有提供网络支持功能.
在K8s的CNI规范中, 它要求网络插件需要实现:网络管理 和 网络策略.
网络管理: 即给Pod配置IP地址等.
网络策略: 它是用来实现K8s的网络名称空间之间是否能够互相通信,在一个k8s网络名称空间中,是否允许Pod和Pod之间互相通信等.这些控制策略都是由iptables规则实现的,实际上。
k8s的网络名称空间:
这个网络名称空间是K8s提供的管理边界,即 我们可以定义多个网络名称空间,每个网络名称空间可做为不同的项目 或 不同的租户使用, 比如: A公司 申请了两个网络名称
空间,一个做为开发环境,一个作为生产环境, 当我们不需要当前这个生产环境了,要使用升级后的生产环境,我们只需要删除现有生产环境的这个网络名称空间即可,所以
说k8s的网络名称空间实际上提供了一个管理边界。但这两个网络名称空间中的Pod是在同一个网络中的,它们是可以互相通信的,所以,网络策略是用来决定它们之间是否能通信的。
CNI:
目前实行CNI规范的产品有很多,以下为比较知名的产品:
flannel: 它是一个比较简单的CNI实现,它仅实现了网络配置.
calico: 它是一个非常复杂的CNI实现,它实现了网络配置 和 网络策略, 并且它内部实现了三层网络隧道进行路由通信,其路由协议为BGP.
canel: 它是flannel 和 calico的组合体项目,它使用了flannel网络配置的简单,又整合了calico的网络策略.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号