Grounded Segment Anything环境配置及学习心得
一、文件下载
https://github.com/IDEA-Research/Grounded-Segment-Anything
二、环境安装
1. 环境要求
python>=3.8, pytorch>=1.7, torchvision>=0.8
我的环境:python=3.11, pytorch=1.12.0, torchvision=0.13.1,cuda=10.0
2. pip安装
2.1 安装segment_anything
终端输入
python -m pip install -e segment_anything
2.2 安装GroundingDINO
终端输入
python -m pip install -e GroundingDINO
安装依赖项,进入到GroundingDINO,依次执行如下命令
cd GroundingDINO
python setup.py build
python setup.py install
2.3 安装diffusers
终端输入
pip install --upgrade diffusers[torch]
2.4 安装grounded-sam-osx
输入以下两个命令安装grounded-sam-osx
cd grounded-sam-osx
bash install.sh
如无bash:
则可以打开install.sh,依次执行各行
2.5 安装其他依赖
终端输入
pip install opencv-python pycocotools matplotlib onnxruntime onnx ipykernel
2.6 安装包
终端输入
pip install -r requirements.txt
3. 权重文件下载
权重文件2:
https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth
下载好的权重文件放在Grounded-Segment-Anything根目录下
如无法下载,可访问
整合包下载地址:https://www.123pan.com/s/R43eVv-hGHKd.html
(权重文件内容较大,上述两个权重共约3G,下载之后找到上述两个权重文件,放到自己项目根目录)
4.运行
以此demo为例

直接运行,会有报错。这部分我先给隐藏了
点击查看代码
if __name__ == "__main__":
# parser = argparse.ArgumentParser("Grounded-Segment-Anything Demo", add_help=True)
# parser.add_argument("--config", type=str, required=True, help="path to config file")
# parser.add_argument(
# "--grounded_checkpoint", type=str, required=True, help="path to checkpoint file"
# )
# parser.add_argument(
# "--sam_version", type=str, default="vit_h", required=False, help="SAM ViT version: vit_b / vit_l / vit_h"
# )
# parser.add_argument(
# "--sam_checkpoint", type=str, required=False, help="path to sam checkpoint file"
# )
# parser.add_argument(
# "--sam_hq_checkpoint", type=str, default=None, help="path to sam-hq checkpoint file"
# )
# parser.add_argument(
# "--use_sam_hq", action="store_true", help="using sam-hq for prediction"
# )
# parser.add_argument("--input_image", type=str, required=True, help="path to image file")
# parser.add_argument("--text_prompt", type=str, required=True, help="text prompt")
# parser.add_argument(
# "--output_dir", "-o", type=str, default="outputs", required=True, help="output directory"
# )
#
# parser.add_argument("--box_threshold", type=float, default=0.3, help="box threshold")
# parser.add_argument("--text_threshold", type=float, default=0.25, help="text threshold")
#
# parser.add_argument("--device", type=str, default="cpu", help="running on cpu only!, default=False")
# parser.add_argument("--bert_base_uncased_path", type=str, required=False, help="bert_base_uncased model path, default=False")
# args = parser.parse_args()
点击查看代码
# cfg
config_file = "./GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py" # change the path of the model config file
grounded_checkpoint = "groundingdino_swint_ogc.pth" # change the path of the model
sam_version = "vit_h"
sam_checkpoint = "sam_vit_h_4b8939.pth"
sam_hq_checkpoint = ""
use_sam_hq = ""
image_path ="./assets/demo7.jpg"
text_prompt = "Horse. Clouds. Grasses. Sky. Hill."
output_dir = "outputs"
box_threshold = 0.3
text_threshold = 0.25
device = "cpu"
bert_base_uncased_path = ""
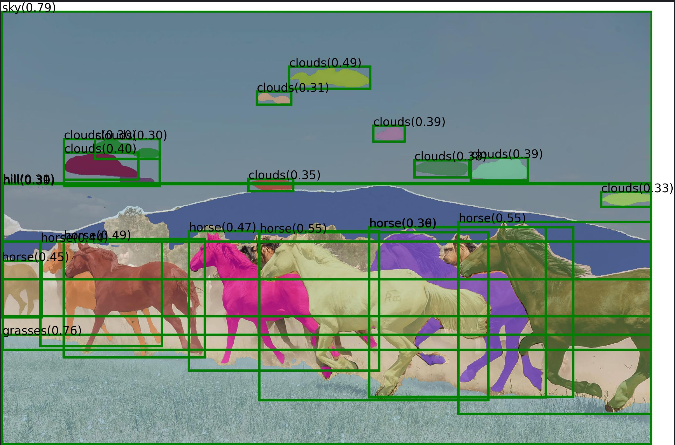
三、学习心得
3.1方法概述
Grounded Segment Anything(GSA)模型结合了两个先进的模型——Grounding DINO 和 Segment Anything Model (SAM),实现了基于文本提示的图像分割。这种方法允许用户通过简单的文本描述来指导模型识别并分割出感兴趣的区域,这为图像处理带来了极大的灵活性和易用性。
3.2原理探究
目标检测与定位
首先,Grounding DINO 作为基础模型,使用 Transformer 架构进行训练,它能够理解自然语言提示,并将其转化为对图像中对象的精确位置预测。这一过程依赖于强大的特征提取能力和跨模态理解能力,使得模型可以从文本提示中提取语义信息,并在图像中找到相应的物体位置。
像素级分割
在确定了感兴趣的对象位置后,SAM 接管了后续的工作,执行像素级别的精细分割。SAM 使用了一种新颖的设计,能够在无需额外标注的情况下,高效地完成各种图像分割任务。其核心在于一种灵活的编码器-解码器架构,其中编码器负责提取全局特征,而解码器则专注于生成高质量的掩码。
3.3结构解析
GSA 的实现代码清晰地展示了上述两个模型是如何结合在一起工作的:
数据预处理:
首先对输入图像进行了必要的预处理操作,包括尺寸调整、格式转换和归一化等步骤,确保输入数据符合模型的要求。
模型加载与配置:
接着,通过加载预先训练好的 Grounding DINO 和 SAM 模型权重,设置好运行环境(如选择 CPU 或 GPU),准备就绪进行推理。
推理过程:
利用 Grounding DINO 获取初步的目标框,然后通过 SAM 进行细化的像素级分割。整个过程中,还涉及到一些辅助函数用于可视化结果和保存输出数据。
3.4学习收获
通过这次学习,我不仅掌握了 GSA 的基本工作流程和技术细节,更重要的是理解了多模态学习在实际应用中的巨大潜力。同时,我也认识到了工程实践的重要性,比如如何有效地组织代码结构、管理依赖关系以及调试技巧等。
此外,在学习的过程中遇到一些问题:
1.方法不知道什么作用
2.应该传递哪些参数
3.语法问题
#如
checkpoint = torch.load(model_checkpoint_path, map_location="cpu")
load_res = model.load_state_dict(clean_state_dict(checkpoint["model"]), strict=False)
print(load_res)
_ = model.eval()
#详解:
1.torch.load(model_checkpoint_path, map_location="cpu")
model_checkpoint_path:字符串,表示模型权重文件的路径
例如:"groundingdino_swint_ogc.pth" 或 "./weights/dino.pth"
map_location="cpu":告诉 PyTorch 把模型参数加载到 CPU 上
小知识:.pth 文件本质是一个 Python 字典(dict),可以用 torch.load() 读出来。
2. model.load_state_dict(clean_state_dict(checkpoint["model"]), strict=False)
model.load_state_dict(...)
这是 PyTorch 模型的标准方法。作用:把权重字典“填充”到 model 的每一层中,类似于“安装操作系统”
参数 strict=False
strict=True:要求权重字典和模型结构 完全匹配strict=False:允许有部分参数不匹配(比如新增或缺失层)
load_res 是一个命名元组(NamedTuple),包含两个字段:
missing_keys:模型中找不到对应权重的层
unexpected_keys:权重中有但模型中没有的层
3._ = model.eval()
作用:将模型切换到 推理模式(evaluation mode)
_ = model.eval() 中的 _ 是“占位符”,表示你不关心返回值
总之,总结经验,找到不足之处,后续加以改进。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号