爬虫基础_刘益长
一、什么是爬虫
爬虫:一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息。
二、Python爬虫架构
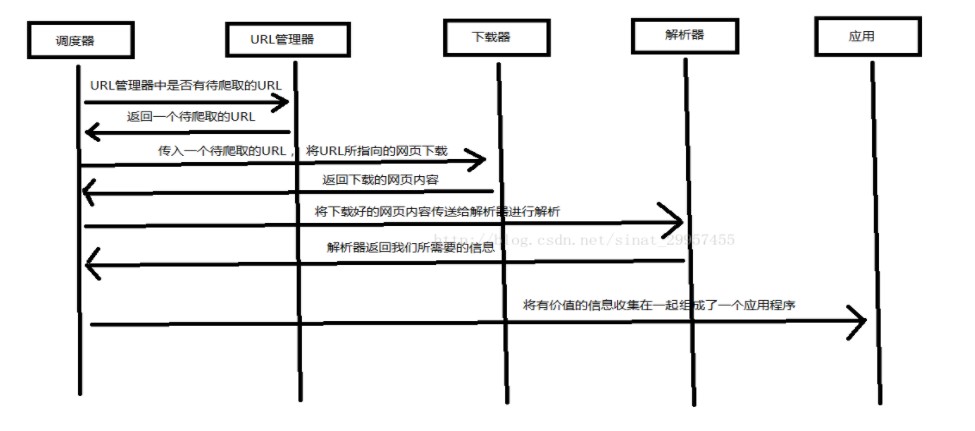
Python 爬虫架构主要由五个部分组成,分别是调度器、URL管理器、网页下载器、网页解析器、应用程序(爬取的有价值数据)。
调度器:相当于一台电脑的CPU,主要负责调度URL管理器、下载器、解析器之间的协调工作。
URL管理器:包括待爬取的URL地址和已爬取的URL地址,防止重复抓取URL和循环抓取URL,实现URL管理器主要用三种方式,通过内存、数据库、缓存数据库来实现。
网页下载器:通过传入一个URL地址来下载网页,将网页转换成一个字符串,网页下载器有urllib2(Python官方基础模块)包括需要登录、代理、和cookie,requests(第三方包)
网页解析器:将一个网页字符串进行解析,可以按照我们的要求来提取出我们有用的信息,也可以根据DOM树的解析方式来解析。
网页解析器有正则表达式(直观,将网页转成字符串通过模糊匹配的方式来提取有价值的信息,当文档比较复杂的时候,该方法提取数据的时候就会非常的困难)、html.parser(Python自带的)、beautifulsoup
(第三方插件,可以使用Python自带的html.parser进行解析,也可以使用lxml进行解析,相对于其他几种来说要强大一些)、lxml(第三方插件,可以解析 xml 和 HTML),html.parser 和 beautifulsoup 以及 lxml 都是以 DOM 树的方式进行解析的。
应用程序:就是从网页中提取的有用数据组成的一个应用。
三、爬虫的基本流程
发起请求:通过url向服务器发起request请求,请求可以包含额外的header信息。
获取响应内容:如果服务器正常响应,那我们将会收到一个response,response即为我们所请求的网页内容,或许包含HTML,Json字符串或者二进制的数据(视频、图片)等。
解析内容:如果是HTML代码,则可以使用网页解析器进行解析,如果是Json数据,则可以转换成Json对象进行解析,如果是二进制的数据,则可以保存到文件进行进一步处理。
保存数据:可以保存到本地文件,也可以保存到数据库(MySQL,Redis,Mongodb等)、
爬虫是一把双刃剑
爬虫是一把双刃剑,它给我们带来便利的同时,也给网络安全带来了隐患。有些不法分子利用爬虫在网络上非法搜集网民信息,或者利用爬虫恶意攻击他人网站,从而导致网站瘫痪的严重后果。关于爬虫的如何合法使用,推荐阅读《中华人民共和国网络安全法》。
四、第一个Python爬虫程序
import urllib.request # 定义一个url url = "http://www.baidu.com" # 指定url request = urllib.request.Request(url)# 打开网址 response2 = urllib.request.urlopen(request)# 打印下载的类容 print(response2.read())
其中 urlopen() 表示打开一个网页地址。注意:请求的 url 必须带有 http 或者 https 传输协议。
通过调用 response 响应对象的 read() 方法提取 HTML 信息,该方法返回的结果是字节串类型(bytes),因此需要使用 decode() 转换为字符串。程序完整的代码程序如下:
import urllib.request # 定义一个url url = "http://www.baidu.com" # 指定url request = urllib.request.Request(url) # 打开网址 response2 = urllib.request.urlopen(request)# 打印下载的类容 print(response2.read().decode('utf-8'))
输出结果如下,由于篇幅过长,此处只做了简单显示:
<!DOCTYPE html><!--STATUS OK--><html><head><meta http-equiv="Content-Type" content="text/html;charset=utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"><meta content="always" name="referrer">
<meta name="theme-color" content="#ffffff"><meta name="description" content="全球领先的中文搜索引擎、致力于让网民更便捷地获取信息,找到所求。
百度超过千亿的中文网页数据库,可以瞬间找到相关的搜索结果。">......</html>
五、爬虫程序添加data、header,然后post请求
5.1、添加data
import urllib from urllib import request # 制定URL url = "http://www.zhihu.com/signin?next=%2F" # 表单的请求参数 values = {'username': 'xxxxxxxx', 'password': 'xxxxxxx'} data = urllib.parse.urlencode(values).encode(encoding='UTF-8')# 构架请求 req = request.Request(url, data=data) # 打开请求 resp = request.urlopen(req) # 读取网页类容 print(resp.read())
5.2、添加header
import urllib from urllib import request # 制定URL url = "http://www.zhihu.com/signin?next=%2F" # 请求头的部分类容:制定浏览器 user_agent = "Mozilla/4.0 (compatible; MSIE 5.5; Windows NI)"# 构建请求头 headers = {'User_Agent': user_agent, 'Referer':'http://www.zhihu.com/articles' } # 构架请求 req = request.Request(url, headers=headers ) # 打开请求 resp = request.urlopen(req) # 读取网页类容 print(resp.read())
User-Agent 即用户代理,简称“UA”,它是一个特殊字符串头。网站服务器通过识别 “UA”来确定用户所使用的操作系统版本、CPU 类型、浏览器版本等信息。而网站服务器则通过判断 UA 来给客户端发送不同的页面。
参见的请求头如下:
| 系统 | 浏览器 | User-Agent字符串 |
|---|---|---|
| Mac | Chrome | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36 |
| Mac | Firefox | Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:65.0) Gecko/20100101 Firefox/65.0 |
| Mac | Safari | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0.3 Safari/605.1.15 |
| Windows | Edge | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/18.17763 |
| Windows | IE | Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko |
| Windows | Chrome | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36 |
| iOS | Chrome | Mozilla/5.0 (iPhone; CPU iPhone OS 7_0_4 like Mac OS X) AppleWebKit/537.51.1 (KHTML, like Gecko) CriOS/31.0.1650.18 Mobile/11B554a Safari/8536.25 |
| iOS | Safari | Mozilla/5.0 (iPhone; CPU iPhone OS 8_3 like Mac OS X) AppleWebKit/600.1.4 (KHTML, like Gecko) Version/8.0 Mobile/12F70 Safari/600.1.4 |
| Android | Chrome | Mozilla/5.0 (Linux; Android 4.2.1; M040 Build/JOP40D) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.59 Mobile Safari/537.36 |
| Android | Webkit | Mozilla/5.0 (Linux; U; Android 4.4.4; zh-cn; M351 Build/KTU84P) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30 |
5.3、添加post请求
import urllib from urllib import request # 制定URL url = "http://www.zhihu.com/signin?next=%2F" # 构架请求 req = request.Request(url, method='POST') # 打开请求 resp = request.urlopen(req) # 读取网页类容 print(resp.read())
六、爬虫程序添加cookie
from urllib import request from http import cookiejar # 设置文件里、路径保存cookie filename = 'cookie.txt' # 声明一个MozillaCookie对象实例来保存cookie到文件 cookie = cookiejar.MozillaCookieJar(filename) # 利用request库的HTTPCookieProcessor对象创建cookie处理器 handler = request.HTTPCookieProcessor(cookie) # 通过handler来构建opener opener = request.build_opener(handler) # 创建一个请求 response = opener.open("http://www.baidu.com") # 保存cookie文件 ignore_discard:cookie失效也要保存,ignore_expires:覆盖文件保存 cookie.save(ignore_discard=True, ignore_expires=True)
或者从已有的cook文件中获取
from http import cookiejar from urllib import request # 创建MozillaCookieJar实例对象 cookie = cookiejar.MozillaCookieJar() # 从文件中读取cookie类容到变量 cookie.load('cookie.txt',ignore_discard=True,ignore_expires=True) # 创建cookie处理器 handler = request.HTTPCookieProcessor(cookie) # 创建下载器 opener = request.build_opener(handler) # 创建请求的request req = request.Request("http://www.baidu.com") # 下载页面 resp = opener.open(req) print(resp.read())
七、正则表达式
7.1、正则表表达式元字符
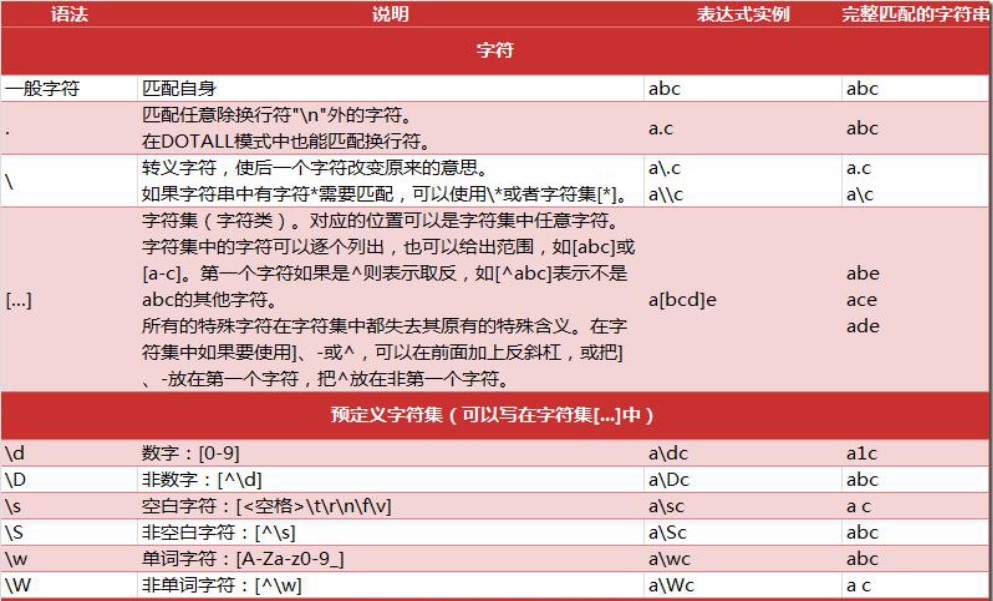
案例:
import re # 定义正则规则 pattern = re.compile(r'a.c') # 匹配 res = re.match(pattern,'abcdefg') print(res) # 匹配 . pattern2=re.compile('a\.c') res2=re.match(pattern,'a.cdefg') print(res2) # 匹配部分字符 pattern3=re.compile(r'a[a-f,A-F]c') res3 = re.match(pattern,'aFcdefc') print(res3) # 匹配数字 pattern4 = re.compile(r'a\dc') res4 = re.match(pattern4,'a5cdefg') print(res4) # 匹配空白 pattern5 = re.compile(r'a\sc') res5 = re.match(pattern5,'a casdas') print(res5)
| 量词 | 用法说明 |
|---|---|
| * | 重复零次或者更多次 |
| + | 重复一次或者更多次 |
| ? | 重复0次或者一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或者更多次 |
| {n,m} | 重复n到m次 |
# 匹配个数 pattern6 = re.compile(r'abc*') res6 = re.match(pattern6,'abccccccccc') print(res6) # 定义正则规则 # 【*】匹配0个到无限个 # 【+】 匹配1个到无限个 # 【?】 匹配0个到1个 # 【{n}】 匹配前一个字符n次 rexg = re.compile(r'\d{5,11}@qq.com') # 匹配 result = re.match(rexg, '1234578@qq.com') print(result)
贪婪模式非贪婪模式
正则表达式默认为贪婪匹配,也就是尽可能多的向后匹配字符,比如 {n,m} 表示匹配前面的内容出现 n 到 m 次(n 小于 m),在贪婪模式下,首先以匹配 m 次为目标,而在非贪婪模式是尽可能少的向后匹配内容,也就是说匹配 n 次即可。
贪婪模式转换为非贪婪模式的方法很简单,在元字符后添加“?”即可实现,如下所示:
| 元字符(贪婪模式) | 非贪婪模式 |
|---|---|
| * | *? |
| + | +? |
| ? | ?? |
| {n,m} | {n,m}? |
# 贪婪模式 rexg2 = re.compile(r'\w{5,10}') # 匹配 result2 = re.match(rexg2, 'jsadhfuioywfs564649hfigfuyaweu6r7fe7f96ew') print(result2) # 非贪婪模式 rexg2 = re.compile(r'\w{5,10}?') # 匹配 result2 = re.match(rexg2, 'jsadhfuioywfs564649hfigfuyaweu6r7fe7f96ew') print(result2)
有时也会出现各种字符组成的字符组,这在正则表达式中使用[]表示,如下所示:
| 正则 | 待匹配字符 | 匹配结果 | 说明 |
|---|---|---|---|
| [0123456789] | 8 | True | 在一个字符组里枚举所有字符,字符组里的任意一个字符 和"待匹配字符"相同都视为可以匹配。 |
| [0123456789] | a | False | 由于字符组中没有 "a" 字符,所以不能匹配。 |
| [0-9] | 7 | True | 也可以用-表示范围,[0-9] 就和 [0123456789] 是一个意思。 |
| [a-z] | s | True | 同样的如果要匹配所有的小写字母,直接用 [a-z] 就可以表示。 |
| [A-Z] | B | True | [A-Z] 就表示所有的大写字母。 |
| [0-9a-fA-F] | e | True | 可以匹配数字,大小写形式的 a~f,用来验证十六进制字符 |
# 边界匹配 # ^ 代表以什么开头,可以匹配多行 # & 代表以什么结尾,可以匹配多行 rexg3 = re.compile(r'^abcdefg$') result3 = re.search(rexg3,'abcdefg') print(result3) # \A 仅匹配字符串的开头 \Aabc # \Z 仅匹配字符串的末尾 efg\Z rexg4 = re.compile(r'efg\Z') result4 = re.search(rexg4,'abcdefgabcdefg') print(result4) rex5 = re.compile(r'a\b!bc') result5 = re.search(rex5,'a!bc') print(result5) # 逻辑,分组 # | 多个匹配 会先匹配左边的部分,如果在左边的部分没找到才会去匹配右边的部分 rexg6 = re.compile(r'abc|efg') result6 = re.search(rexg6,'abmcefgert') print(result6) # ()代表分组 rexg7 = re.compile(r'(abc)(efg)') result7 = re.search(rexg7,'abcabcefgefg') print(result7) print(result7.group(1)) print(result7.group(2)) rexg8 = re.compile(r'(?P<p1>abc)') result8 = re.search(rexg8,'abcdefgk') print(result8) # \<number> 引用编号为number的分组匹配到的字符串 rexg9 = re.compile(r'(\d)abc\1') result9 = re.search(rexg9,'1abc1') print(result9) # (?P=<id>)引用前面的别名为<id> 的分组匹配到的字符串 rexg10 = re.compile(r'(?P<tt>abc)efg(?P=tt)') result10 = re.search(rexg10,'abcefgabc') print(result10)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号