运行caffe自带的mnist实例教程
本文结合几篇博文总结下来的,附上其中一篇原博文链接以供参考:http://blog.sina.com.cn/s/blog_168effc7e0102xjr1.html
1、先进入caffe文件目录,(指令:cd ./caffe),再用data/mnist下的get_mnist.sh下載MNIST数据集,代码如下:
sudo sh ./data/mnist/get_mnist.sh
打开下载目录caffe/data/mnist查看如下图:
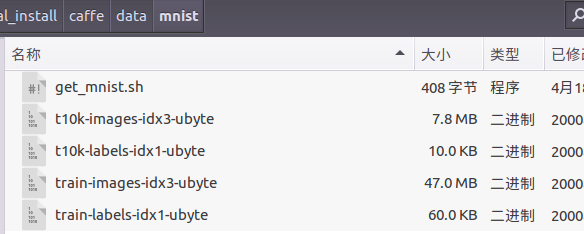
2、转换格式,代码如下:
./examples/mnist/create_mnist.sh(若出错:./examples/mnist/create_mnist.sh: 17: ./examples/mnist/create_mnist.sh: build/examples/mnist/convert_mnist_data.bin: not found。则应先执行编译:make all -j4,然后再执行命令:./examples/mnist/create_mnist.sh)
完成后在examples/mnist生成了两个目录:mnist_test_lmdb和mnist_train_lmdb:
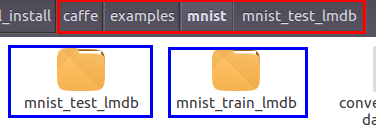
每个目录下有两个文件:data.mdb和lock.mdb:
网络结构定义在./examples/mnist/lenet_train_test.prototxt中。
训练参数配置在./examples/mnist/lenet_solver.prototxt中。
如果电脑有GPU,则不需要修改配置文件;如果没有GPU则需要修改lenet_solver.prototxt,在训练之前需要修改
./examples/mnist/lenet_solver.prototxt最后的(solver_mode: GPU)修改为:solver_mode: CPU
这样保证整个训练过程在CPU上进行。
3、训练超参数,有两种方式:
(1)通过命令行执行训练,代码如下:(这是书上的例子,可以参考网址上的例子,在后面。不同之处:网址上的例子在此处新建一个文件夹保存训练的模型)
cd ./caffe
./build/tools/caffe train --solver=examples/mnist/lenet_solver.prototxt
(2)将以上训练的命令行代码写成训练脚本并命名为train_lenet.sh,放到mnist目录下。运行train_lenet.sh脚本进行训练。
cd caffe
./examples/mnist/train_lenet.sh(若出错:Check failed: mdb_status == 0 (13 vs. 0) Permission denied *** Check failure stack trace: ***则记到caffe目录下,先清除:sudo make clean(删掉了原有build文件)后,并重新编译:sudo make all -j4(重新生成build文件),再重新训练。
部分训练过程截图如下:等待几分钟,训练好后截图如下,准确率99.08%:
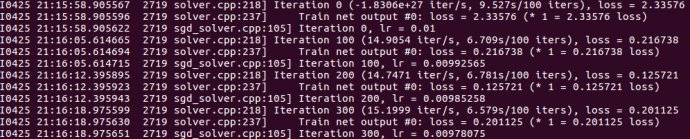

最终训练的模型保存在caffe/examples/mnist/lenet_iter_10000.caffemodel文件中,训练状态保存在caffe/examples/mnist/lenet_iter_10000.solverstate文件中。

5、用训练好的模型对数据进行预测。
利用训练好的Lenet-5模型权值文件(examples/mnist/lenet_iter_10000.caffemodel)可以对测试数据集(或外部测试集)进行预测,代码如下:(注意caffe.bin ,prototxt ,caffemodel 等的路径一定要根据自己的写对:)
cd ./caffe
./build/tools/caffe.bin test \
-model=examples/mnist/lenet_train_test.prototxt \
-weights=examples/mnist/lenet_iter_10000.caffemodel \
-iterations=100
(\表示回车,也可以不要它,直接将这四行代码写成一行代码,注意caffe.bin ,prototxt ,caffemodel 等的路径一定要根据自己的写对:
./build/tools/caffe.bin test -model=examples/mnist/lenet_train_test.prototxt -weights=examples/mnist/lenet_iter_5000.caffemodel -iterations=100)
预测结果如下:
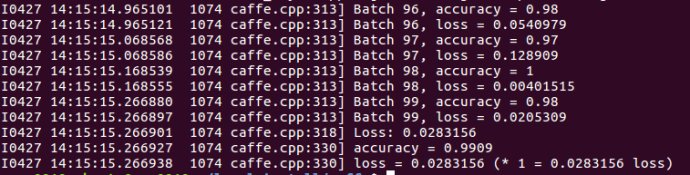
================================= 书上的例子到此结束 =======================
×××××××××××××××××××× 下面是参考网址上的例子 ××××××××××××××××××××××
网址上例子训练模型部分,从前面第三部分开始。在此处创建了一个文件夹保存模型,这方法很好。新建文件夹代码如下:
cd ./caffe/examples/mnist
mkdir model_mnist
查看一下,输入如下代码
ls
建好文件夹后需要修改caffe/examples/mnist/lenet_solver.prototxt 中的snapshot_prefix。
训练网络前先查看一下build/tools/caffe.bin 的用法。
训练网络的代码如下:
cd ./caffe
./examples/mnist/train_lenet.sh
训练完成后,在examples/mnist/model_mnist下产生了4个文件。本例设置迭代5000次输出一个模型和训练状态保存下来,故保存了迭代5000次和迭代10000次的训练模型与训练状态。
测试迭代5000次的模型,代码如下:
cd ./caffe
./build/tools/caffe.bin test -model=examples/mnist/lenet_train_test.prototxt -weights=examples/mnist/lenet_iter_5000.caffemodel
运行caffe自带的mnist实例教程测试迭代10000次的模型,代码如下:
cd ./caffe
./build/tools/caffe.bin test -model=examples/mnist/lenet_train_test.prototxt -weights=examples/mnist/lenet_iter_10000.caffemodel


 浙公网安备 33010602011771号
浙公网安备 33010602011771号