03 2021 档案
摘要:特征工程通常包括:数据清洗、特征设计、特征变换和特征选择等环节。 **数据和特征决定了机器学习的上限,而模型和算法只是不断地逼近这个上限。**模型训练的好坏,也取决于特征设计、加工的效果。 特征工程是机器学习,甚至是深度学习中最为重要的一部分,也是课本上最不愿意讲的一部分,特征工程往往是打开数据密码
阅读全文
摘要:now 返回当前系统日期+时间 SELECT NOW(); curdate 返回当前系统日期,不包含时间 SELECT CURDATE(); curtime() 返回当前时间不包含日期 SELECT CURTIME(); year() mouth() SELECT MOUTH();返回中文月份 SE
阅读全文
摘要:round 四舍五入 SELECT round(1.66,2);1.66四舍五入并保留两位 ceil 向上取整,返回>=该参数的最小整数 SELECT CEIL(1.02);结果为2 floor 向下取整,返回<=该参数的最大整数 truncate 截断 SELECT TRUNCATE(1.9999
阅读全文
摘要:字符函数 length():获取输入的字节个数 SELECT LENGTH('john') concat():拼接字符串 upper(),lower():将字符串变为大/小写 substr():裁剪字符,注意:索引从1开始 instr():返回子串在原字符串的起始索引,若找不到返回0 trim():
阅读全文
摘要:语法 SELECT 函数名(实参列表)FROM 表名 类别: 1.单行函数:输入一个值,返回一个值 2.分组函数(统计函数):输入一组值,返回一个值,作统计用
阅读全文
摘要: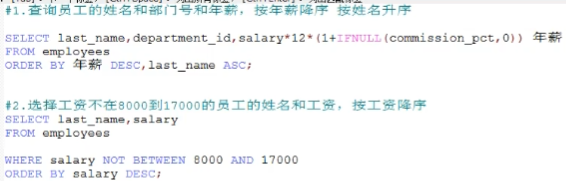 
阅读全文
摘要:语法 asc(升序),desc(降序),可以不写,默认升序。 支持单字段,多字段,表达式,函数。别名 order by子句一般放在最后面(limit子句除外)
阅读全文
摘要: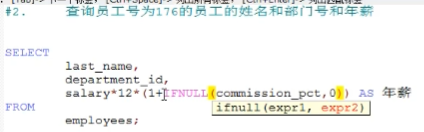 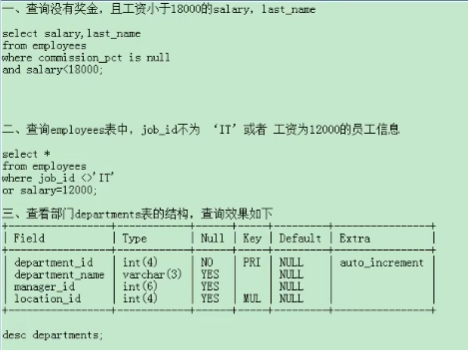 对输入的tensor数据的某一维度求和,一共两种用法 1.torch.sum(input, dtype=None) 2.torch.sum(input, list: dim, bool: keepdim=False, dtype=None) → Tensor input:输入一
阅读全文
摘要:第一遍:了解文章主要讲了什么问题 第二遍:思维导图 开头:事件,总论点 问题与危害 原因 措施:政府监管,企业(社会责任)、家庭和学校(引导) 总结 第三遍:
阅读全文
摘要:torch.unsqueeze(input, dim, out=None) 作用:扩展维度 返回一个新的张量,对输入的既定位置插入维度 1 注意: 返回张量与输入张量共享内存,所以改变其中一个的内容会改变另一个。 如果dim为负,则将会被转化dim+input.dim()+1 参数: tensor
阅读全文
摘要:hasattr(object, name) hasattr() 函数用于判断对象是否包含对应的属性。如果对象有该属性返回 True,否则返回 False。
阅读全文
摘要:主要为like,between and,in,is null,is not null 首先需要声明。通配符%为任意多个字符,包括0个;任意单个字符 like 也可以指定转义符: WHERE last_name like '$_%' ESCAPE '%' between and 区间包含临界值,可以简
阅读全文
摘要:torch.nn.init.constant(tensor, val) 用val的值填充输入的张量或变量 参数: tensor – n维的torch.Tensor或autograd.Variable val – 用来填充张量的值
阅读全文
摘要:torch.nn.init.uniform(tensor, a=0, b=1) 从均匀分布U(a, b)中生成值,填充输入的张量或变量 参数: tensor - n维的torch.Tensor a - 均匀分布的下界 b - 均匀分布的上界
阅读全文
摘要:torch.nn.init.normal(tensor, mean=0, std=1) 从给定均值和标准差的正态分布N(mean, std)中生成值,填充输入的张量或变量 参数: tensor – n维的torch.Tensor mean – 正态分布的均值 std – 正态分布的标准差
阅读全文
摘要:(1)tensor .data 返回和 x 的相同数据 tensor,而且这个新的tensor和原来的tensor是共用数据的,一者改变,另一者也会跟着改变,而且新分离得到的tensor的require s_grad = False, 即不可求导的。(这一点其实detach是一样的) (2)使用te
阅读全文
摘要:首先可以把这个函数理解为类型转换函数,将一个不可训练的类型Tensor转换成可以训练的类型parameter并将这个parameter绑定到这个module里面(net.parameter()中就有这个绑定的parameter,所以在参数优化的时候可以进行优化的),所以经过类型转换这个self.v变
阅读全文
摘要:类型转换, 将list ,numpy转化为tensor a = torch.tensor([[1, 2], [3, 4]]) print(torch.FloatTensor(a.size()))
阅读全文
摘要:np.choose(a, choices, out=None, mode='raise'):按照序号a对choices中的数进行选择。 a: index array,其中的数必须是整数 mode=‘raise’,表示a中数必须在[0,n-1]范围内 mode=‘wrap’,a中数可以是任意的整数(s
阅读全文
摘要:首先明确百分位数的概念: 第p个百分位数是这样一个值,它使得至少有p%的数据项小于或等于这个值,且至少有(100-p)%的数据项大于或等于这个值。 举个例子: 高等院校的入学考试成绩经常以百分位数的形式报告。比如,假设某个考生在入学考试中的语文部分的原始分数为54分。相对于参加同一考试的其他学生来说
阅读全文
摘要:IFNULL() IFNULL(A,x):将A中为NULL的项换成x 示例: SELECT IFNULL( commission_pct, 0 ) AS sal FROM employees 条件查询 语法: 示例: 1, SELECT * FROM employees WHERE salary >
阅读全文
摘要:concat():将若干字段连接并输出 示例 SELECT CONCAT( first_name, ' ',last_name ) AS 姓名 FROM employees NULL和任何字段拼接结果都为NULL
阅读全文
摘要:ndnarry为numpy中narry数组,tensor为TensorFlow中的张量 相同: tensor内部的数据类型为ndarray类型 区别: tensor可以有加速器内存(如GPU)支持,既可以在CPU上运行也可以在GPU上运行。ndarray只能在CPU上运行。 ndarray在CPU上
阅读全文
摘要:model.train()将模型设置为训练状态,作用:使Dropout,batchnorm知道后有不同表现(具体参考Dropout,batchnorm源码),只有这两个关心True or False。 将模型设置为测试状态有两种方法: 1.model.train(mode=False) 2.mode
阅读全文
摘要:语法 开头:USE 库名 select 查询列表 from 表名 特点 1.查询列表可以是:表中的字段,常量值,表达式,函数 2.查询的结果是一个虚拟的表格 双击想要查询的表即可,F12标准化 查询所有项: SELECT * FROM 表名 查询常量值: SELECT 100; SELECT 'jo
阅读全文
摘要:数据存在的问题:不完整,有噪声,不一致 解决方法:填充缺失值,光滑噪声并识别离群值,纠正数据中的不一致 缺失值 1.忽略元组,适用于多个属性缺失 2.人工填写 3.使用一个全局常量填写,如:“Unknown”,“-∞” 4.使用属性的中心度量填充,对称的数据分布用均值,倾斜数据分布用中位数 5.使用
阅读全文
摘要:低质量的数据导致低质量的挖掘结果。(包括准确性,完整性,一致性) 数据清理:清除数据中的噪声 数据集成:将多个数据源合并成统一的数据存储 数据归约:PCA,聚类来降低数据规模 数据变换:把数据压缩到较小的区间
阅读全文
摘要:1.不区分大小写 2.每条命令用;结尾 3.根据需要进行缩进或换行 4.注释
阅读全文
摘要:启动mysql服务:net start mysql 停止mysql服务:net stop mysql 登录数据库:mysql -uroot -p 需注意:在服务停止的状态下无法登录 退出登录:exit 查看数据库:show databases; 进入某一个数据库:use XXX; 查看有哪些表:sh
阅读全文
摘要:DB:数据库(database);保存一系列有组织的数据。 DBMS:数据库管理系统(Database Management System),创建和操作数据库的容器。 SQL:结构化查询语言(Structure Query Language),与数据库通信的语言。 SQL的优点:1.几乎所有DBMS
阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号